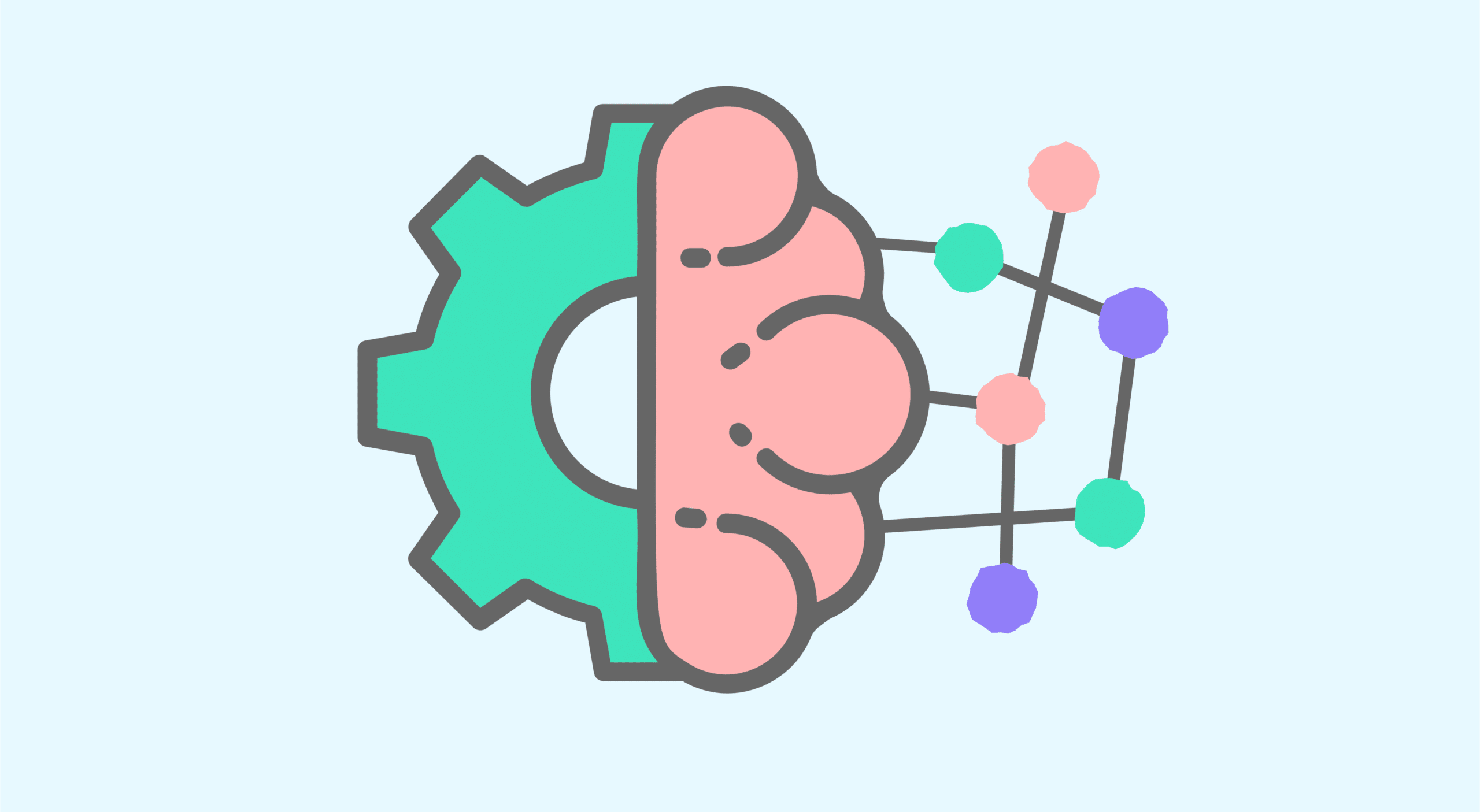
💠 Deep Learning
- 사람의 뇌구조를 모방하여 병렬적 다층 구조를 통해 학습하도록 만든 기술
- 컴퓨터 비전, 음성인식, 자연어처리, 신호처리 등의 분야에 적용
- 사람이 스스로 규칙을 찾기 어려운 복잡한 데이터에 사용
DL에서 자주 사용하는 package는 tensorflow, pytorch
Keras (코드가 간결해 진다.)
Colab은 최신 버전으로 해주는데 코드가 잘 안 돌아가는 경우 keras, tensorflow의 버전을 낮추거나,
local에서 해당 코드의 keras, tensorflow 버전을 설치하여 시행한다.
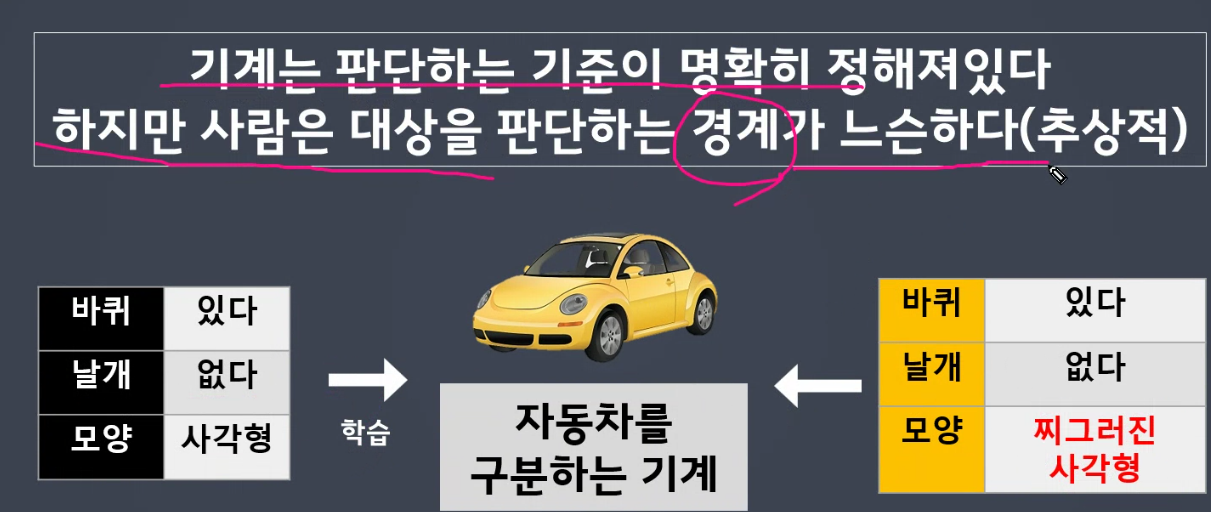
- 경계값이 뚜렷하다
- 기계는 정확한 임계치를 가지고 판단하고 있음
- 여러 개를 연결하여 사람처럼 판단을 조금 느슨하고, 수용할 수 있게 함
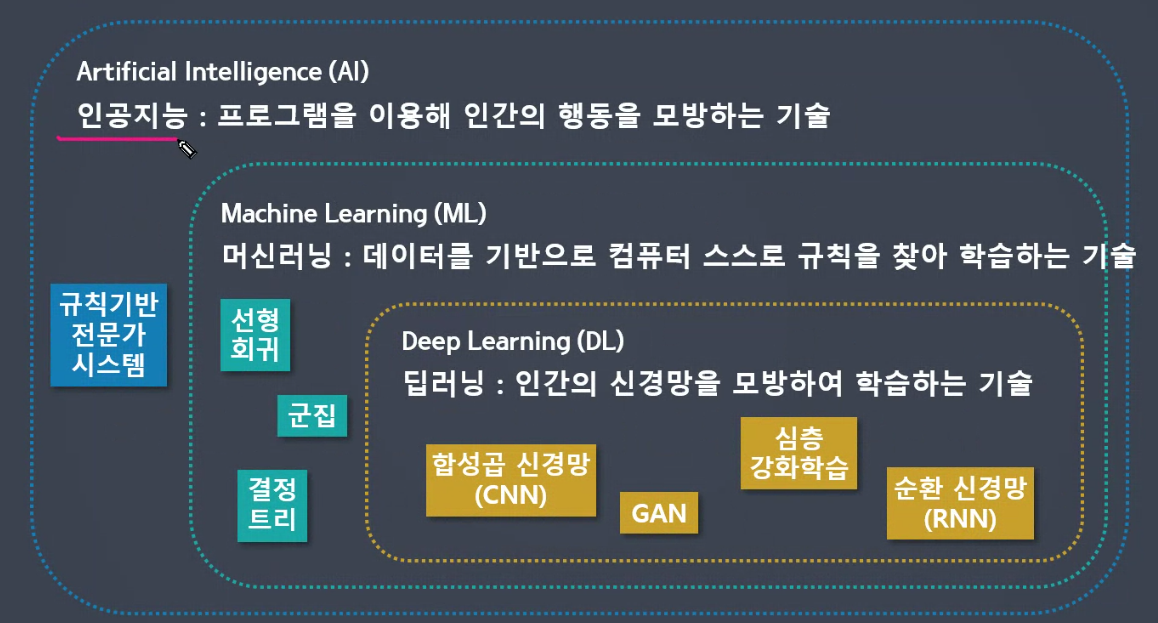
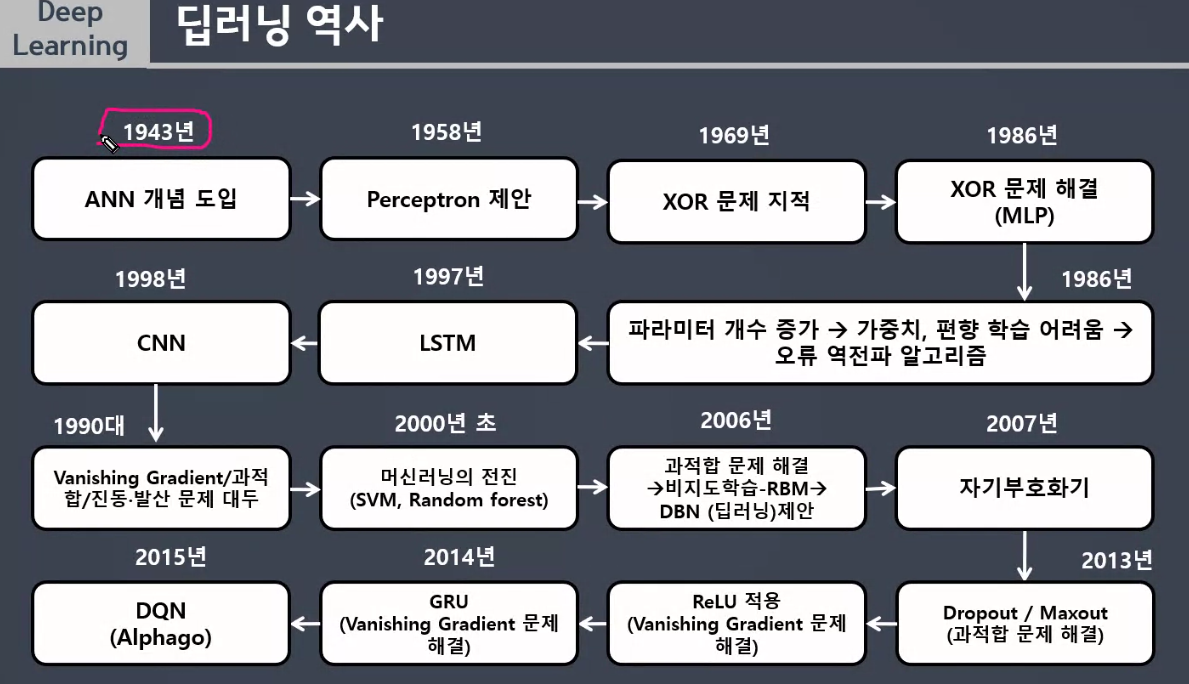
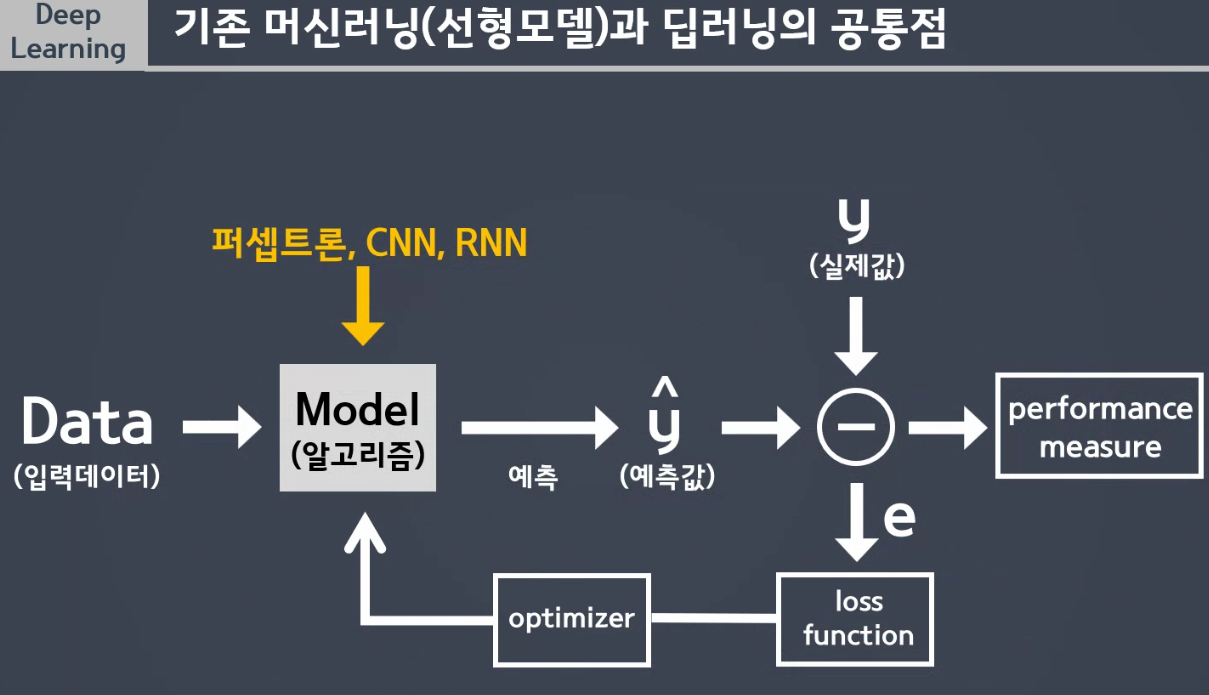
✅ 기존 머신러닝과의 비교
1) 모델을 예측하여 오차를 구하기 -> LOSS FUNCTION (MSE)
2) Optimizer(최적화 하는 도구)를 이용하여 최적화 해주기
3) 오차가 많이 나면 가중치 많이 수정 필요, 오차가 적다면 가중치 조금만 수정 필요
4) 최적화된 Model 생성
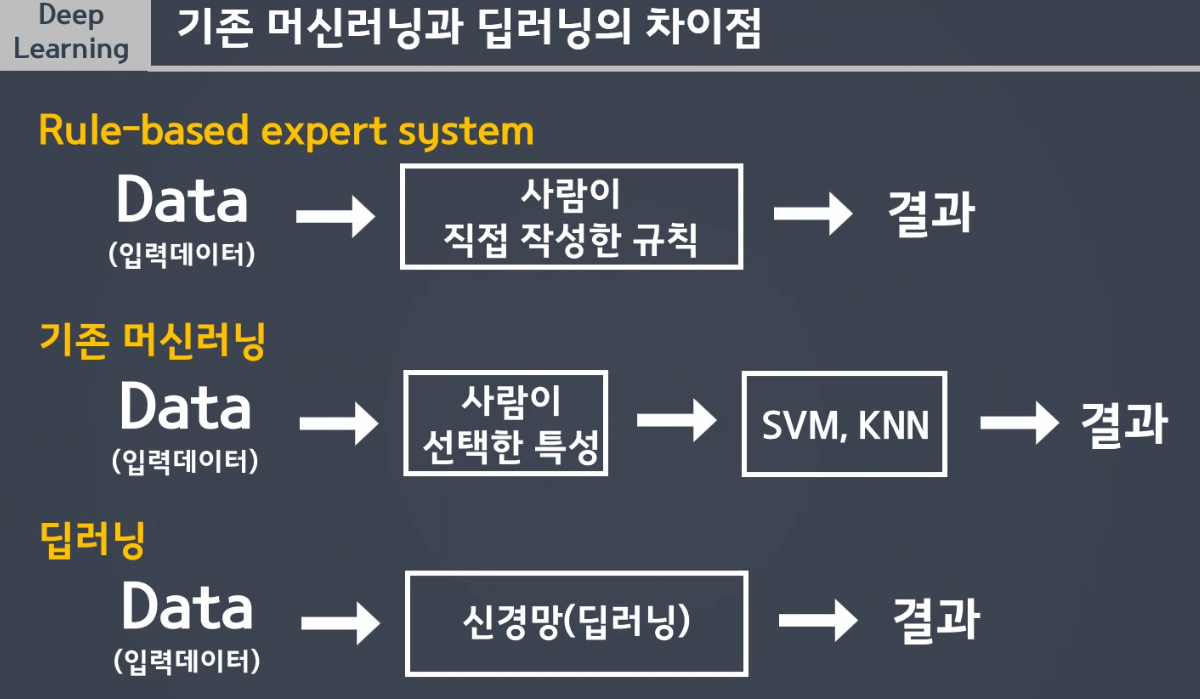
✅ 사람의 개입 정도로 비교한 차이점
1. Rule-base expert system
사람의 의존도가 높음
사람이 발견한 규칙을 통해 결과를 출력. 데이터가 많아질수록 규칙을 찾기 어려움.
2. 기존 머신러닝
필요한 컬럼만 만들고 데이터 전처리 하는 것은 사람이 선택, 학습은 스스로하여 결과를 출력.
3. 딥러닝
사람의 개입 최소화
feature engineering이 거의 필요없음.

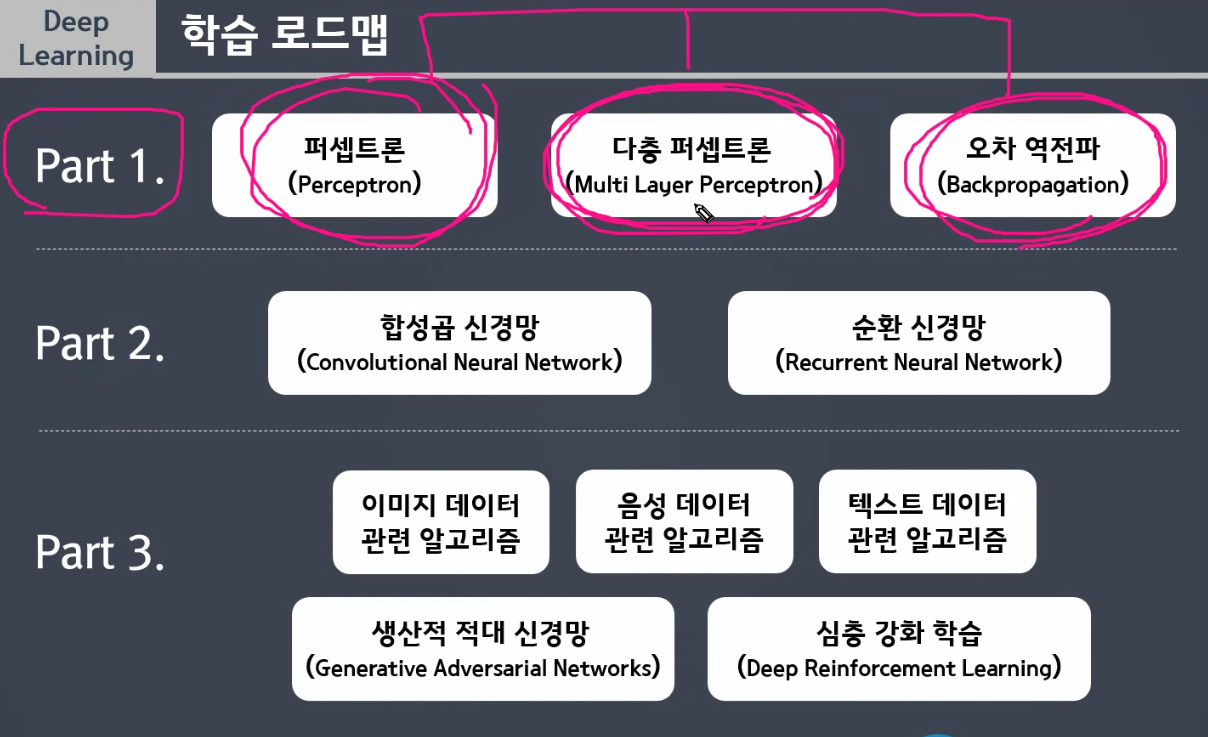
딥러닝 프레임워크 Keras

목표
- 공부 시간에 따른 학생의 성적을 예측하는 모델 만들기
- sklearn을 이용한 모델링과 Keras를 이용한 모델링
!pip install google-colab-shell
from google_colab_shell import getshell
getshell()
- ls : list, 현재 디렉토리의 파일 목록
- pwd : printing working directory, 현재 내위치
%cd "/content/drive/MyDrive/Colab Notebooks/24.08.29 딥러닝"
# changedirectory 경로변경
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt데이터 로딩
data = pd.read_csv("./data/student-mat.csv", delimiter=";")
data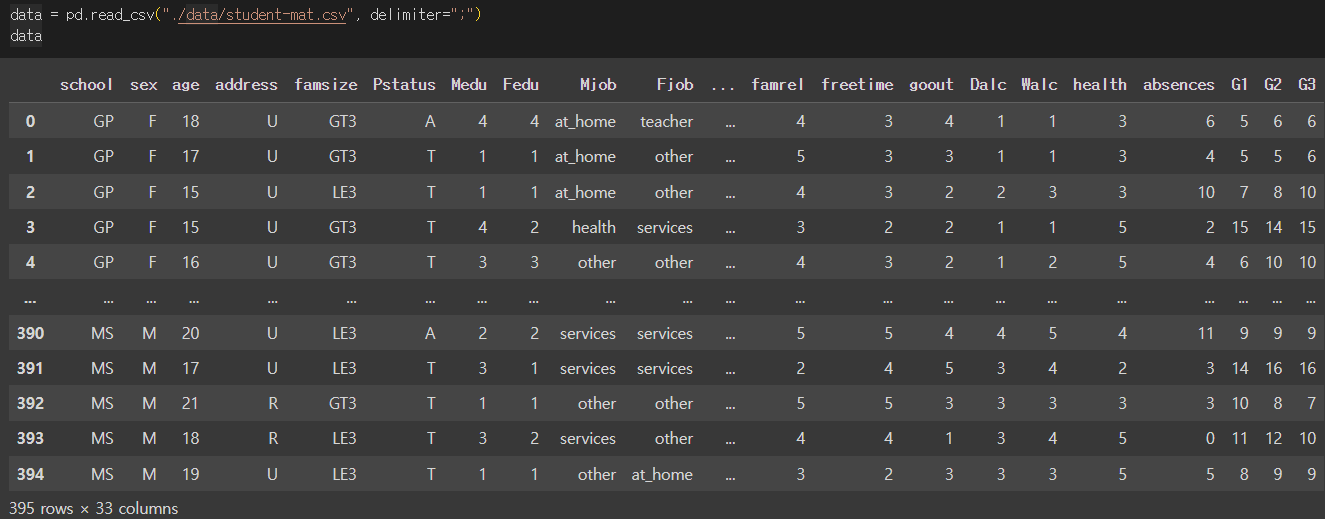
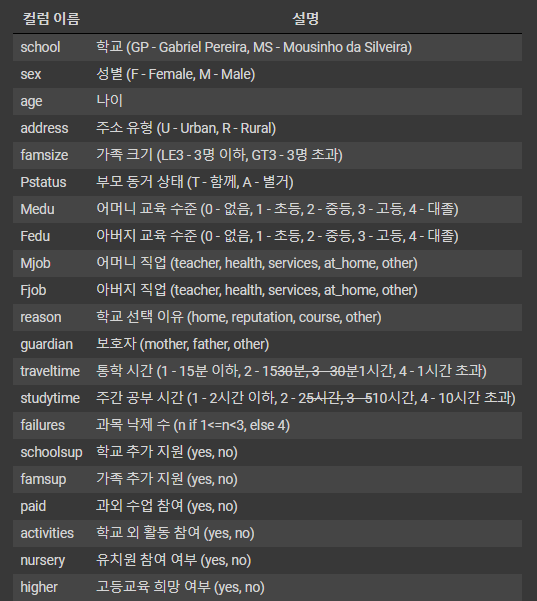
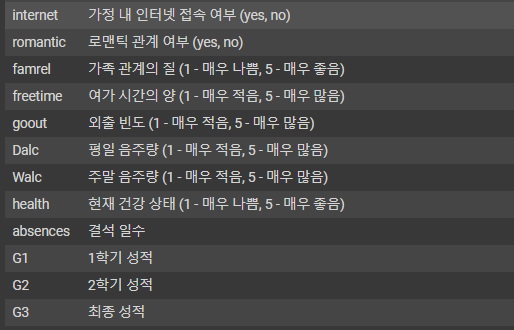
문제와 답 추출
- 공부시간 : X
- 최종성적 : y
X = data['studytime']
y = data['G3']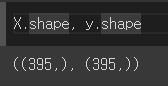
선형회귀 모델링
- 훈련/평가 데이터 분리
- 모델학습 및 평가
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error # 훈련, 평가 데이터 분리
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=829)# 데이터 크기 확인
print('훈련용 문제 : ', X_train.shape)
print('훈련용 답 : ', y_train.shape)
print('테스트용 문제 : ', X_test.shape)
print('테스트용 답 : ', y_test.shape)
# 모델생성 -> 모델학습 -> 모델예측 -> 모델 평가
lr_model = LinearRegression()
lr_model.fit(X_train.values.reshape(-1,1), y_train)
pre = lr_model.predict(X_test.values.reshape(-1,1))
score = mean_squared_error(y_test, pre)# MSE(평균제곱오차)
print("MSE : ", score)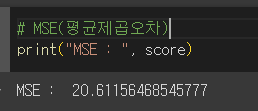
🤍 Keras를 이용한 딥러닝 모델링
- 모델의 설계를 내가 원하는대로 할 수 있다.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import InputLayer, Dense# 모델생성(모델설계)
# 뼈대 생성
deep_model = Sequential()
# 입력층
deep_model.add(InputLayer(shape=(1,)))
# 중간층(은닉층)
deep_model.add(Dense(units=8, activation='sigmoid'))
deep_model.add(Dense(units=8, activation='sigmoid'))
# 출력층
deep_model.add(Dense(units=1))
# 뉴런(unit개수)을 많이 생성할수록 시간이 오래 걸리고 정확해진다고 함
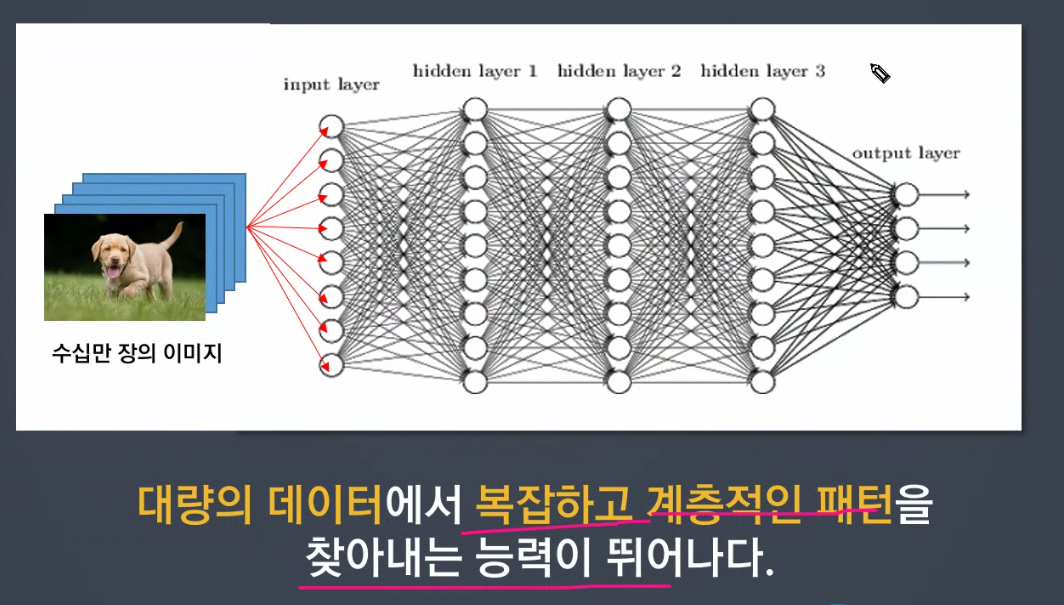
중간층에서는 많은 데이터를 주고 받는다.
입력층에서 받아온 1개의 데이터를 중간층1에서 각각의 뉴런이 값을 분해하고 만들고(8개) 다음 중간층 2의 각각의 뉴런에게 전달함.
중간층 2는 받은 값을 또 분해하여 값을 만듦
출력층은 중간층 2(마지막 중간층)에게서 총 8개를 받음
복잡한 데이터를 사고할 수 있고, 모델은 느슨한 사고력을 가질 수 있다.
# 모델학습
# 손실함수, 최적화함수 - 커스터마이징
deep_model.compile(loss="mse",
optimizer='adam')
deep_model.fit(X_train, y_train,
validation_split=0.2, # 훈련데이터에서 316개 20%를 검증용으로 활용
epochs=20) # 모델의 가중치를 업데이트 하는 황목 횟수 (epochs=>최적화를 결정하는 파라미터)# 모델 예측 및 평가
deep_model.evaluate(X_test, y_test)
Hello, World!