Text Mining
- 비정형 텍스트 데이터에서 의미를 추출하는 작업
- 자연어처리 기술을 접목해서 최근에는 많이 활용되고 있다
- (사람의 언어를 컴퓨터가 이해할 수 있도록 연구하는 학문)
Text Mining process
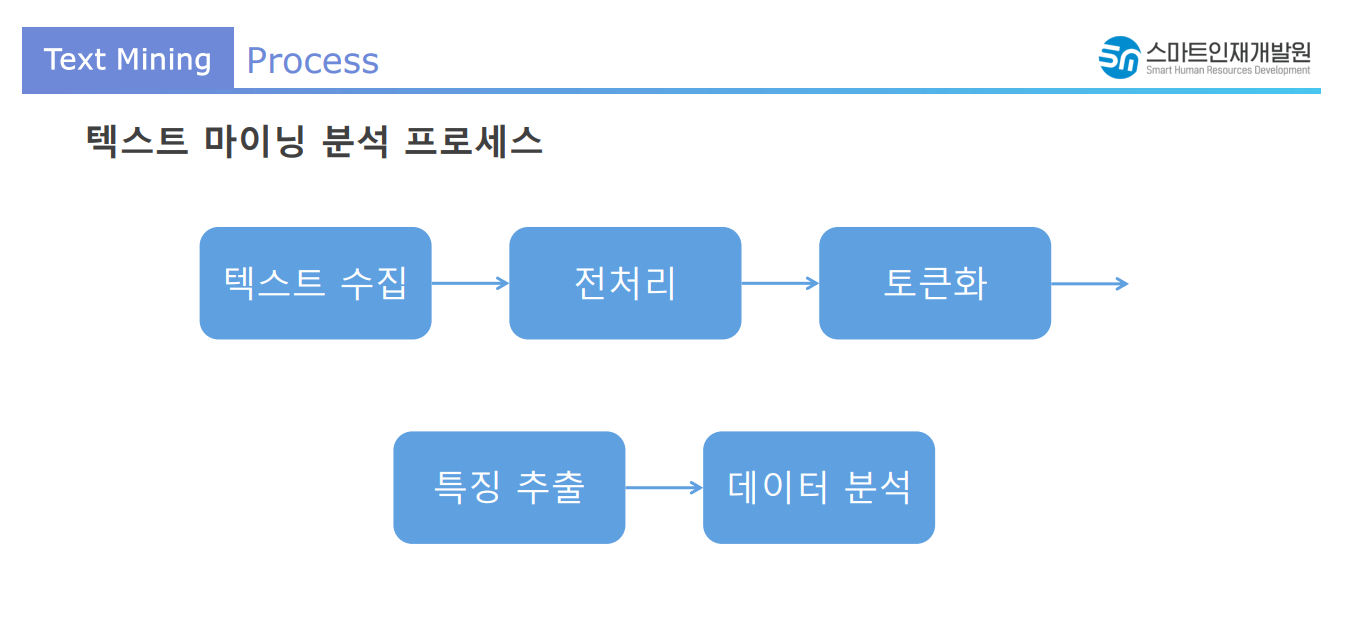
문제 정의 (분석 목적) - 텍스트 수집 - 텍스트 전처리(cleansing + 형태소 분석) - 토큰화(tokenize) - 특징 추출 - 데이터 분석
- 전처리
- 오타, 띄어쓰기 교정
- 불필요한 단어토큰 제거(문장부호,이모지,불용어)
- 형태소 분석(품사를 기준으로 명사, 형용사, 동사 등.. 분리, 어근추출)
텍스트마이닝에서 활용한 분석 종류
- 단어빈도 분석
- 감성분석 : 텍스트에서 사람의 감정/기분/의견/태도 등을 분석하는 작업
- 연관성(유사도) 분석 : text끼리 연관성이나 유사도를 비교하는 작업
1. 단어빈도 분석
데이터 수집 및 로딩
- 스마일게이트에서 실제 댓글을 모아서 정제한 데이터셋을 활용
# 현재 작업 디렉토리 및 폴더 확인
import os
print(os.getcwd()) # 현재 작업 폴더 확인
# 작업디렉토리 내부 폴더 및 파일 확인
print(os.listdir(r"C:\Users\USER\Desktop\gjaischool 2024\ML"))
# r: rawstring 특수기호 가지지 않고 진짜 문자열로 인식
print(os.listdir(os.getcwd())) import pandas as pd
# 훈련용, 평가용 데이터 로딩
train = pd.read_csv("./data/unsmile_train_v1.0.tsv", # 파일경로
delimiter='\t') # 구분자
test = pd.read_csv("./data/unsmile_valid_v1.0.tsv", # 파일경로
delimiter='\t') # 구분자# 데이터 확인
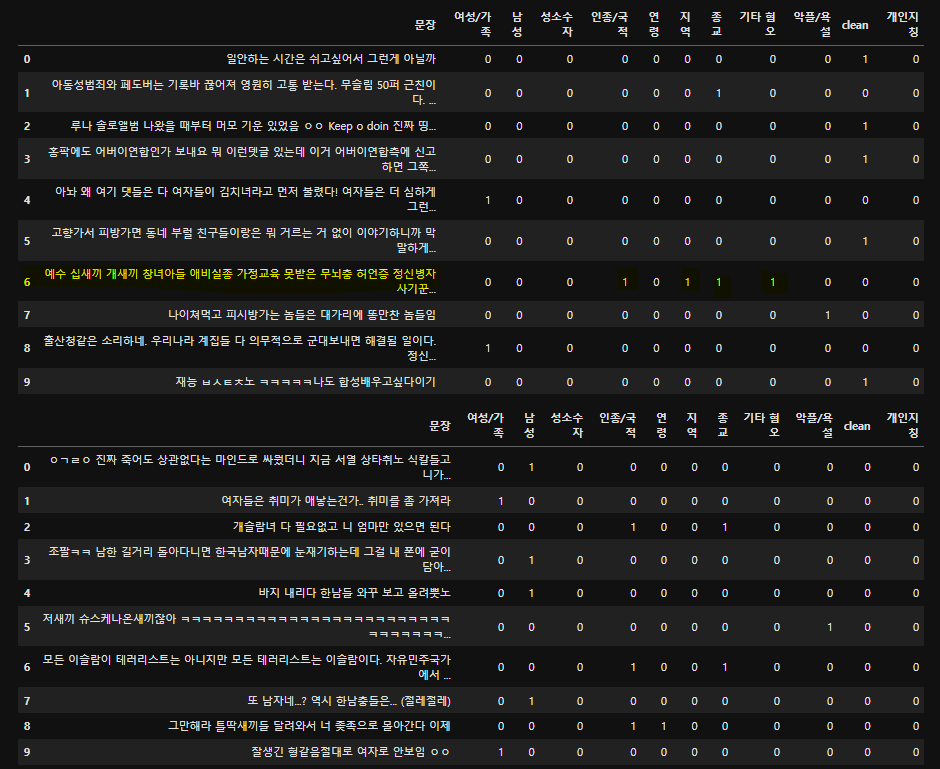
display(train.head(10))
display(test.head(10))multilabel
# 결측치 확인
display(train.info())
display(test.info())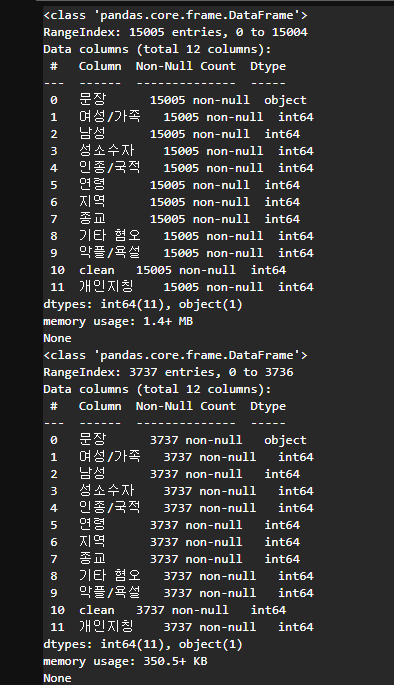
전체 데이터에서 단어들의 빈도를 측정해서 확인해보자
text_train = train['문장']
text_train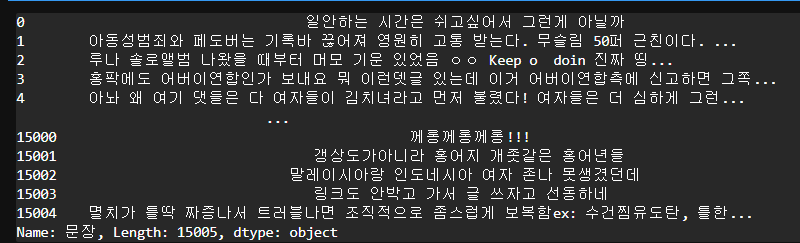
# 띄어쓰기 중심으로 토큰화 : nltk 패키지 활용
from nltk import word_tokenize # 토큰화 도와주는 함수
import nltk
nltk.download("punkt") # 문장부호 정보를 다운로드# 반복 프로세스의 정도를 시각화하는 도구
from tqdm import tqdm# 쪼개진 단어들이 들어갈 리스트
words = []
for text in tqdm(text_train):
temp = word_tokenize(text) # 한 문장씩 토큰화
words = words + temp

# 단어빈도 세기
from collections import Countercounter = Counter(words) # 같은 단어의 개수를 세준다.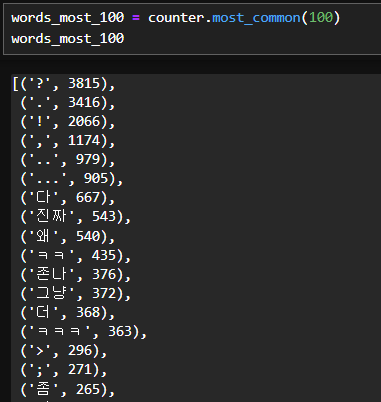
from wordcloud import WordCloud# 객체생성
wc = WordCloud(background_color="white", # 배경색 설정
random_state=821, # 난수 seed 고정
font_path=r"C:\Windows\Fonts\batang.ttc")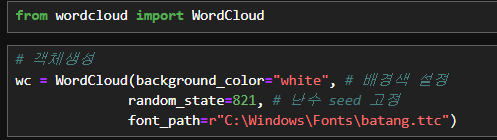
# 단어빈도가 측정된 데이터로부터 워드클라우드 생성
# 입력데이터는 딕셔너리 형태로 집어넣을 것(Key:단어, Value:빈도)
wc_rs = wc.generate_from_frequencies(dict(words_most_100))# matplotlib을 통해 시각화
import matplotlib.pyplot as plt
plt.rc('font',family="batang")plt.figure(figsize=(20,8)) # 가로, 세로 비율 지정 (inch 단위)
plt.imshow(wc_rs) # 그림을 시각화할 때 사용하는 함수
plt.axis('off') # x,y 눈금 숨기기
plt.savefig("./data/한국어 혐오 단어 100.jpg") # 이미지 파일로 저장
plt.show() # 시각화 결과 보여주기< 저장된 이미지 >

clean을 제외한 9가지 혐오표현 중에서 한가지를 골라 워드클라우드를 그려보자.
w_train = train[train['종교']==1]
w_text_train = w_train['문장']
w_text_train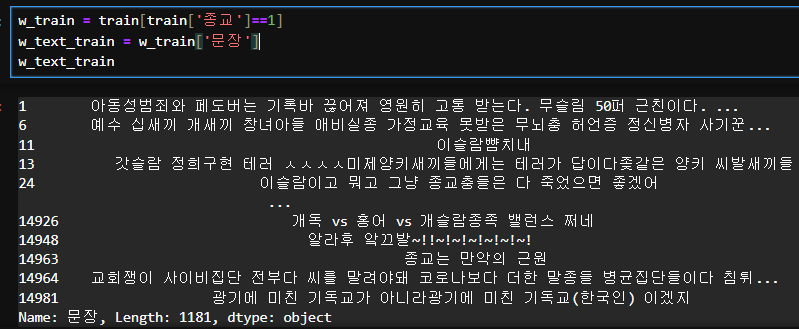
words = []
for text in tqdm(w_text_train):
temp = word_tokenize(text) # 한 문장씩 토큰화
words = words + tempcounter = Counter(words)
w_words_most_100 = counter.most_common(100)
w_words_most_100# 객체생성
wc = WordCloud(background_color="white", # 배경색 설정
random_state=821, # 난수 seed 고정
font_path=r"C:\Windows\Fonts\batang.ttc")
wc_rs = wc.generate_from_frequencies(dict(w_words_most_100))plt.rc('font',family="batang")
plt.figure(figsize=(20,8)) # 가로, 세로 비율 지정 (inch 단위)
plt.imshow(wc_rs) # 그림을 시각화할 때 사용하는 함수
plt.axis('off') # x,y 눈금 숨기기
plt.show() # 시각화 결과 보여주기
전처리 : 텍스트데이터 클렌징
- 문장부호 제거
- 특정 글자가 반복적으로 나타나는 단어토큰 제거 (ex: ㅋㅋ, ㅋㅋㅋ, ㅋㅋㅋㅋ)
- 1글자 단어토큰 제거 : 보통 한글자 단어는 의미를 가지기 어렵다.
정규표현식(Regular Expression)
- 특정한 패턴(규칙)을 가진 문자열의 집합을 표현하는 언어
- 핸드폰번호, 이메일처럼 패턴이 있는 문자열의 검색과 치환을 위해 대부분의 프로그램이 언어에서 지원
- https://wikidocs.net/21703
import re # 정규표현식을 사용할 수 있는 모듈 로딩# 핸드폰번호 검출 예시
# 1. 패턴생성
p = re.compile("010-?[0-9]{4}-?\\d{4}")
# 2. 검출
p.search("안녕하세요 저희 가게는 여기로 연락주세요. 핸드폰 번호는 010-1234-6789")p.search("전화번호 : 01012345678")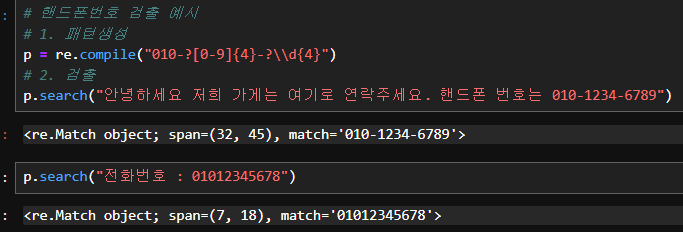
# 클렌징할 패턴 생성
unsmile_p = re.compile('[!?,.:;0-9a-zA-zㅋㅎㄷㅇ~]+')
clean_words = [] # 클렌징된 단어토큰이 들어갈 리스트
for w in words:
if unsmile_p.search(w): # 단어토큰이 패턴에 매칭된다면
continue # 다음 단어 반복으로 넘어감
if len(w) < 2 : # 한글자 단어라면
continue # 다음 단어 반복으로 넘어감
clean_words.append(w) # 패턴에 매칭되지 않는 다면 리스트에 추가 counter = Counter(clean_words)
words_most_100 = counter.most_common(100)wc_rs = wc.generate_from_frequencies(dict(words_most_100))
plt.rc('font',family="batang")
plt.figure(figsize=(20,8)) # 가로, 세로 비율 지정 (inch 단위)
plt.imshow(wc_rs) # 그림을 시각화할 때 사용하는 함수
plt.axis('off') # x,y 눈금 숨기기
plt.show() # 시각화 결과 보여주기
불용어처리(stop word)
- 데이터셋 내에서 불필요한 단어토큰을 제거하는 작업
stop_words = ['하는', '저런', '없다', '없는', '있는', '한다', '믿는', '절대', '역시', '진짜', '모든', '같은', '보면', '그냥']
# 1. 원문에서 제거
stop_clean_words = [] # 불용어가 제거된 리스트
for w in clean_words:
if w not in stop_words : # 단어토큰이 불용어 목록에 포함되지 않는 경우
stop_clean_words.append(w)# 2. 카운팅된 결과에서 제거
words_most_50_dict = dict(words_most_50)
for sw in stop_words:
del words_most_50_dict[sw]
words_most_50_dict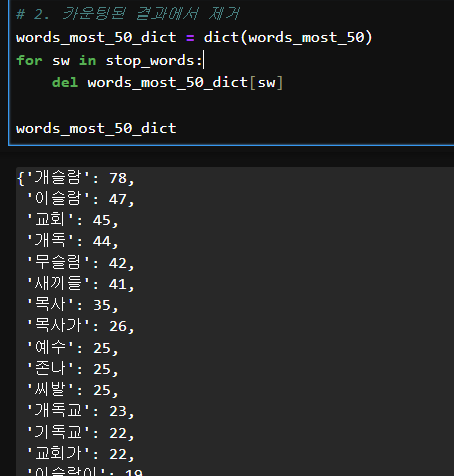
# 불용어 처리된 단어토큰 빈도세기
counter = Counter(stop_clean_words)
words_most_50 = counter.most_common(50)
# 워드 클라우드 그리기
wc_rs = wc.generate_from_frequencies(dict(words_most_50))
plt.rc('font',family="batang")
plt.figure(figsize=(20,8)) # 가로, 세로 비율 지정 (inch 단위)
plt.imshow(wc_rs) # 그림을 시각화할 때 사용하는 함수
plt.axis('off') # x,y 눈금 숨기기
plt.show() # 시각화 결과 보여주기
🥝 Kiwi 활용하기
- 형태소 분석, 불용어 처리, 기타 다양한 기능을 지원
- https://github.com/bab2min/kiwipiepy
# kiwi 설치하기
!pip install kiwipiepy띄어쓰기 교정
from kiwipiepy import Kiwi
kiwi = Kiwi() # 객체생성# 띄어쓰기 교정
kiwi.space('띄어쓰기없이작성된텍스트네이걸교정할까말까어쩔까')불용어 처리
from kiwipiepy.utils import Stopwords
stopwords = Stopwords() # 불용어 객체생성 -> 기본적인 한국어 불용어가 탑재kiwi.tokenize("분석 결과에서 불용어만 제외하고 출력할 수도 있다.", stopwords=stopwords)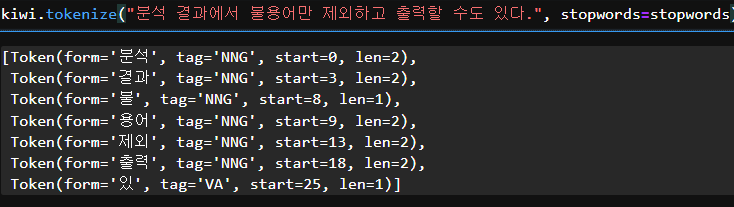
# 불용어 추가
stopwords.add(("결과", "NNG")) # 새로운 불용어 등록kiwi.tokenize("분석 결과에서 불용어만 제외하고 출력할 수도 있다.", stopwords=stopwords)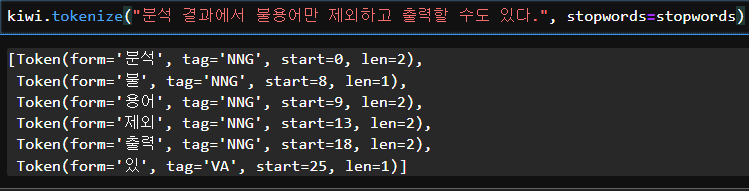
이모지 제거
# 이모지 패키지 설치
!pip install emojiimport emoji
emoji.replace_emoji("오늘 점심으로 짜장밥을 먹었는데 너무 맛있었어.🍚🐷💨")
emoji.demojize("오늘 점심으로 짜장밥을 먹었는데 너무 맛있었어.🍚🐷💨")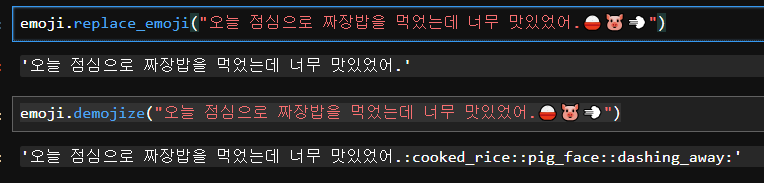
형태소 분석
- 형태소 : 의미를 가지는 가장 작은 크기의 문장단위
- 품사태깅 : 형태소 단위로 분리하고 품사를 부착하는 작업
morphs_list = []
for w in tqdm(clean_words):
morphs_rs = kiwi.tokenize(w, stopwords=stopwords) # 형태소 분리 및 불용어 처리
morphs_list = morphs_list + morphs_rs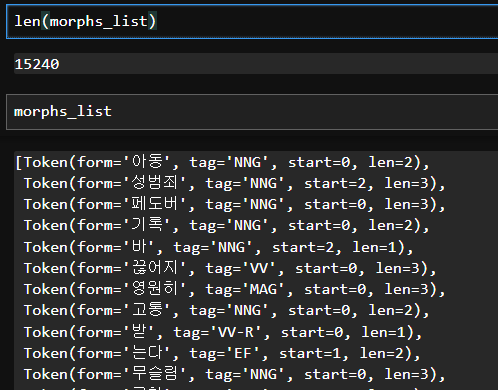
특정 품사 필터링하기
# 일반명사(NNG), 동사(VV), 형용사(VA)를 필터링 해보자
morphs_filtering_list = []
for m in morphs_list : # m에는 token이라는 class가 대입되는 것
if m.tag in ["NNG", "VV", "VA"]:
morphs_filtering_list.append(m.form)
# 불용어 처리된 단어토큰 빈도세기
counter = Counter(morphs_filtering_list)
words_most_50 = counter.most_common(50)
# 워드 클라우드 그리기
wc_rs = wc.generate_from_frequencies(dict(words_most_50))
plt.rc('font',family="batang")
plt.figure(figsize=(20,8)) # 가로, 세로 비율 지정 (inch 단위)
plt.imshow(wc_rs) # 그림을 시각화할 때 사용하는 함수
plt.axis('off') # x,y 눈금 숨기기
plt.show() # 시각화 결과 보여주기

Hello, World!