


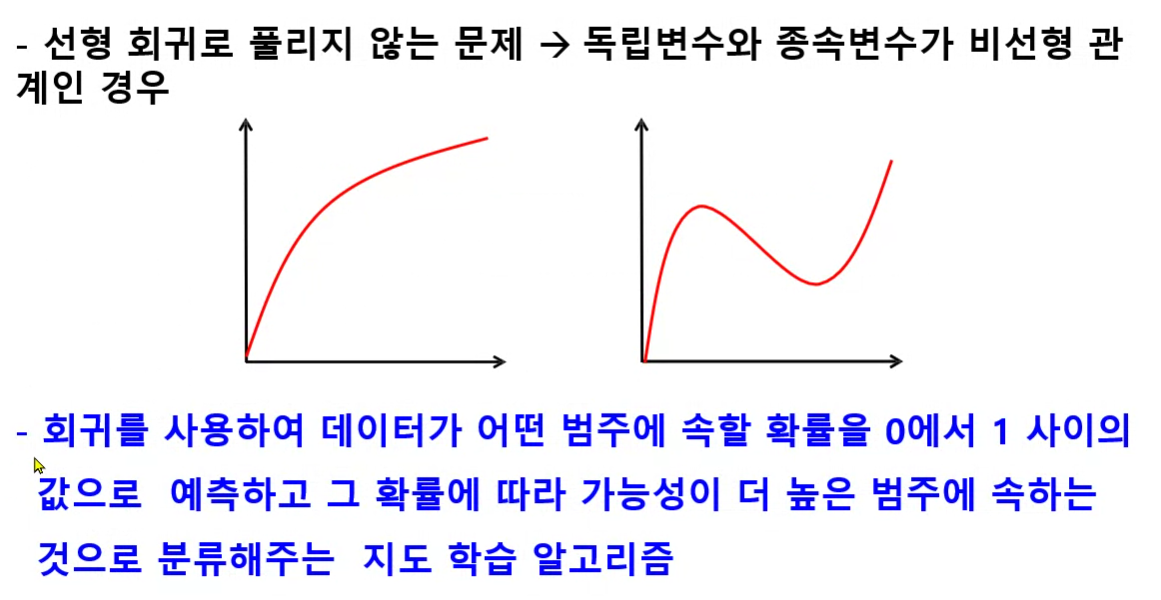
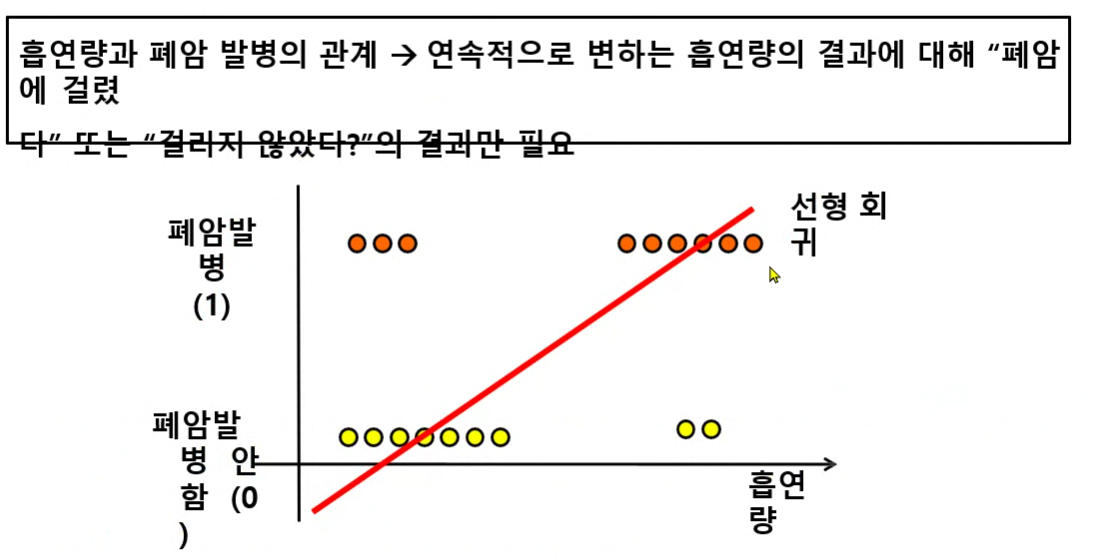
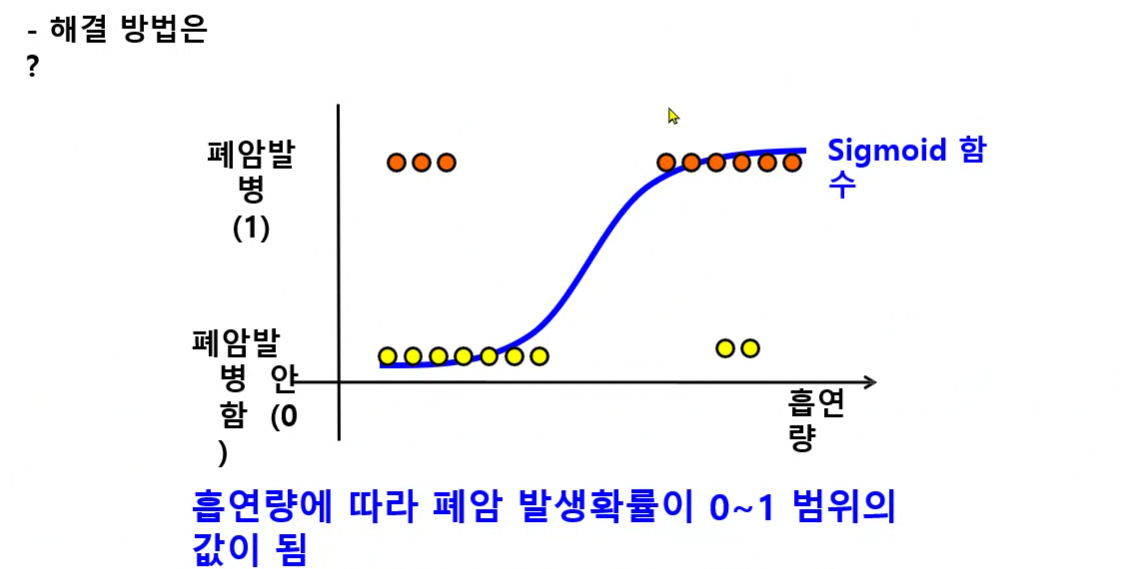
- Sigmoid 함수 : 0~1 범위
- 시그모이드 함수를 사용하면 직선을 곡선으로 바꿔준다.
- 0부터 1까지의 값으로 나오기 때문에 확률적 해석이 가능해진다
- 1 : 양성클래스가 될 확률
- 0 : 음성클래스가 될 확률
- 중간영역을 빠르게 찾을 수 있게 !



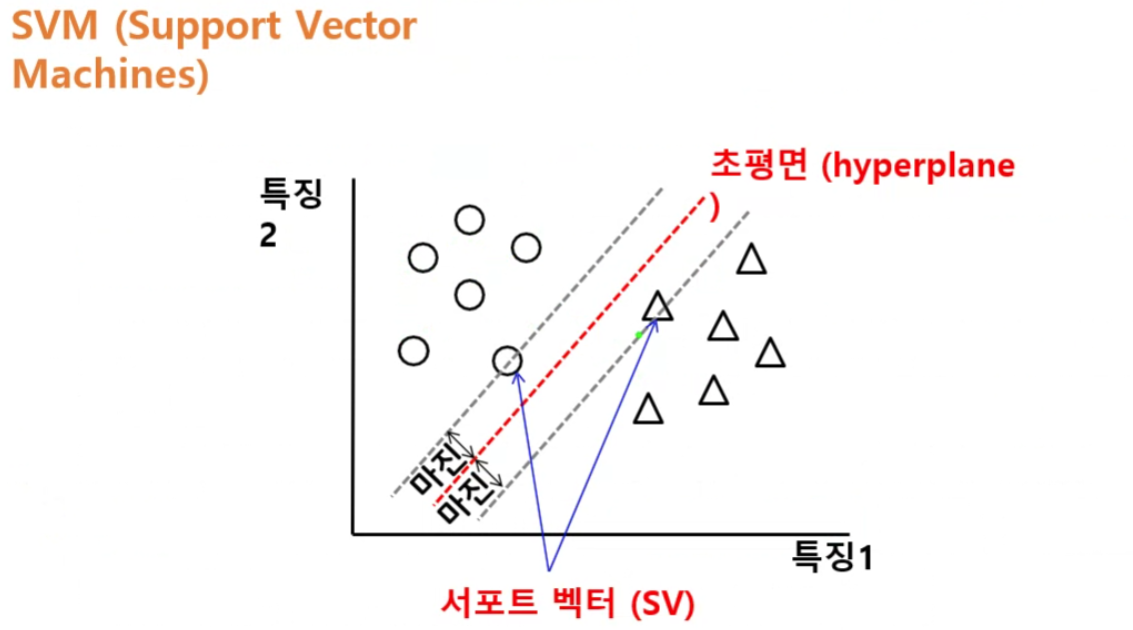
hyperplane에 가장 가까운 값을 SV(서포트벡터)라고 함
- SV(서포트 벡터) : 결정경계를 이루는 직선과 가장 가깝게 있는 데이터
- 마진 : 결정경계와 서포트벡터 사이의 거리
- 마진의 거리가 최대가 되고, 마진끼리의 거리가 비슷한 결정경계 찾기
- 초평면(결정경계)을 사용하여 데이터를 나눈다.
- 차원에 따라 결정경계가 직선이나 면이 될 수 있다.
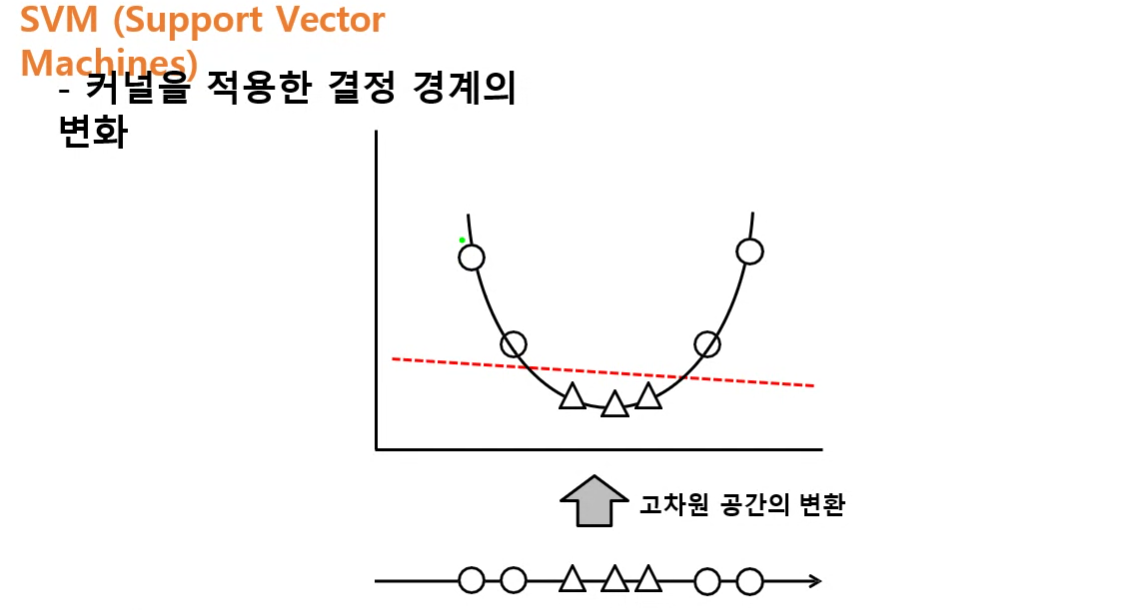
직선(1차원)을 평면(2차원)으로 옮김
2차원으로 옮기고 나서 둘을 구분하려면 1차원(직선)으로 구분 가능
2차원에서는 1차원으로 분류 가능
3차원에서는 2차원으로 분류 가능
1. 문제정의
- BX : 최근 이직 시장이 활발하게 성장함에 따라 직원들도 줄줄이 퇴사 행렬을 이어가고 있다. 경영진은 핵심인재의 유출을 최대한 줄이고 오랜시간 함께 성장할 수 있는 회사를 만들고 싶다.
- CX : 자신의 성장을 느낄 수 있는 회사, 성과에 따른 적절한 보상과 효율적인 업무를 진행 할 수 있는 회사
- DX : 데이터분석을 통해 이직률과 연관이 있는 사항들을 지속적으로 확인하고 개선, HR팀은 이직 가능성이 높은 핵심 인재를 예측하고 해당 인원을 위한 관리 프로그램을 운영
- Trigger : HR데이터를 통한 최근 퇴사 및 이직 현황 확인, 핵심인재의 유출 여부 확인
- Accelerator : 직원의 인사관련 데이터를 통해 구성원의 불만족 요소나 잠재적인 문제(보상,진급 등) 확인
- Tracker : 핵심인재의 이직률의 변화 추이, 직원들의 업무 스트레스 지수
2. 데이터 수집

# 라이브러리 불러오기
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# Warnings 제거
import warnings
warnings.filterwarnings('ignore')
# 예측 모델링을 위한 라이브러리 불러오기
from sklearn.model_selection import train_test_split # 훈련/평가 데이터 분리
from sklearn.linear_model import LogisticRegression # 로지스틱 모델
from sklearn.svm import LinearSVC # 분류용 SVM 모델
from sklearn import metrics # 평가용 모듈
from sklearn.model_selection import cross_val_score # 교차 검증 함수
# 모델 평가를 위한 라이브러리 불러오기
from sklearn.metrics import classification_report # 분류 평가지표# 데이터 불러오기
df = pd.read_csv('./data/job_transfer.csv')
df.head()3. 데이터 전처리
df.info()
# 수치형데이터는 학습을 할 수가 없다
# Dtype 확인하여 수치형데이터로 변경해주어야 한다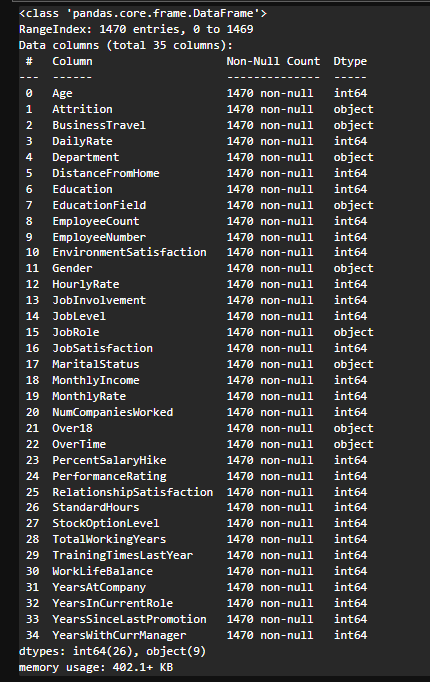
# null값 확인
df.isnull().sum() # 모두 0개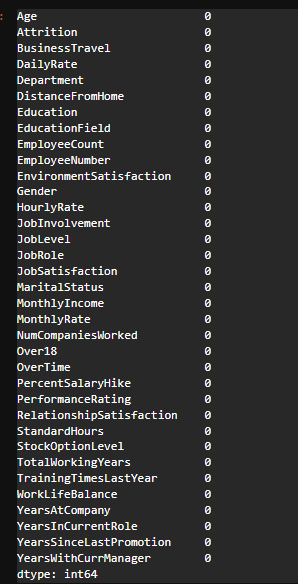
# outlier 확인
df.describe()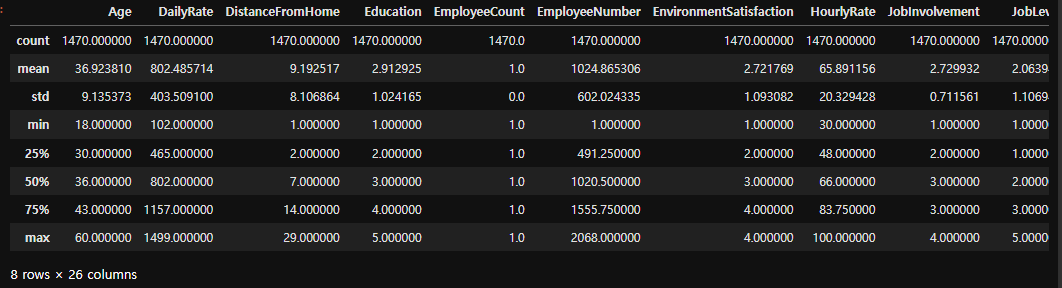
4. 탐색적 데이터 분석(EDA)
# 이직
df['Attrition'].value_counts()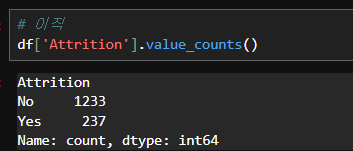
# 학습 및 집계를 위해 수치형 데이터로 변경
# 이직 = 1, 이직 안 함 = 0로 수정
# np.where(조건, 참이라면 바꿀 값, 거짓이라면 바꿀 값)
df['Attrition'] = np.where(df['Attrition']=='Yes', 1, 0)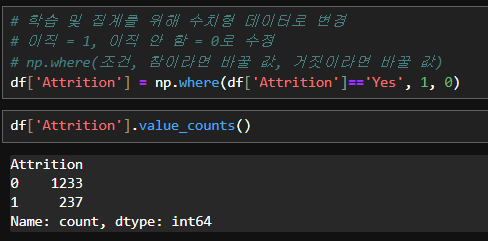
# 학습 및 집계를 위해 수치형 데이터로 변경
# 이직 = 1, 이직 안 함 = 0로 수정
# np.where(조건, 참이라면 바꿀 값, 거짓이라면 바꿀 값)
df['Attrition'] = np.where(df['Attrition']=='Yes', 1, 0)
df['Attrition'].value_counts()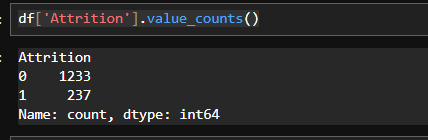
# 성별, 연령 분석
# 나이 컬럼을 구간화 (범주형데이터)
# where 기능이 2개의 구간으로 나눠주는 함수
df['Age_gp'] = np.where(df['Age'] <= 30, '30대 이하',
np.where(df['Age'] <= 40, '30-40대', '40대 이상'))
df[['Age','Age_gp']]
# 연령별 이직률 현황
# agg 함수 : aggregate의 약자로, 하나 이상의 함수를 적용하여, 그룹별로 집계 결과를 얻음
df_gp = df.groupby('Age_gp')['Attrition'].agg(['count','sum'])
df_gp['ratio'] = round(df_gp['sum']/df_gp['count']*100, 1) # 반올림
df_gp
# 젊을수록 이직률 높음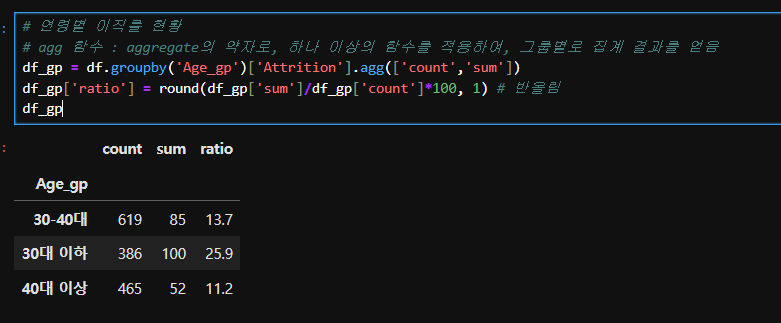
# 성별 이직률 현황
df_gp2 = df.groupby('Gender')['Attrition'].agg(['count','sum'])
df_gp2['ratio'] = round(df_gp2['sum']/df_gp2['count']*100, 1) # 반올림
df_gp2
# 남성의 이직률이 더 높음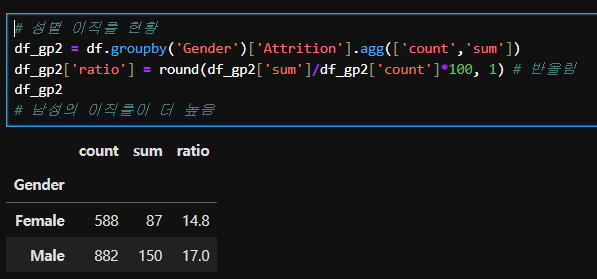
# 부서별 이직률 현황
df_gp3 = df.groupby('Department')['Attrition'].agg(['count','sum'])
df_gp3['ratio'] = round(df_gp3['sum']/df_gp3['count']*100, 1) # 반올림
df_gp3
# Sales 이직률이 더 높음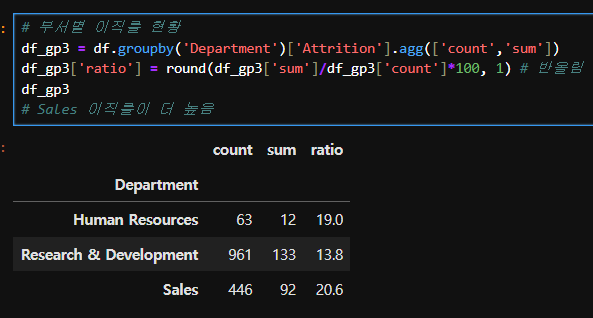
가설1) 업무만족도는 높으나 인간 관계로 인한 이직률이 높을 것이다.
- JobSatisfaction : 업무 만족도 -> 숫자가 클수록 만족 (0~4)
- RelationshipSatisfaction : 인간관계 만족도 -> 숫자가 클수록 만족 (0~4)
# 인간관계 만족도, 업무 만족도와 이직 간의 상관관계 확인
df[['JobSatisfaction', 'RelationshipSatisfaction', 'Attrition']].head()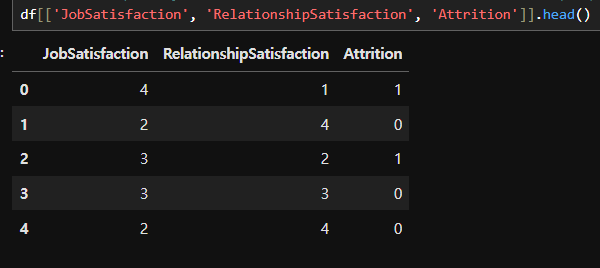
# 업무만족도별 이직률 현황
df_gp4 = df.groupby('JobSatisfaction')['Attrition'].agg(['count','sum'])
df_gp4['ratio'] = round(df_gp4['sum']/df_gp4['count']*100, 1) # 반올림
df_gp4
# 업무만족도가 낮을수록 이직률이 높음 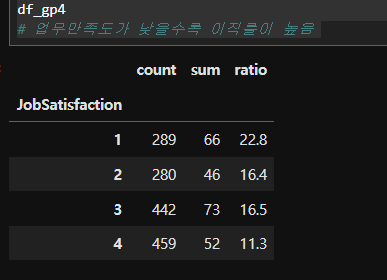
# 인간관계만족도, 만족도 / 이직간의 상관관계 확인
df_gp5 = df.groupby(['JobSatisfaction', 'RelationshipSatisfaction'])['Attrition'].agg(['count','sum'])
df_gp5['ratio'] = round(df_gp5['sum']/df_gp5['count']*100, 1) # 반올림
df_gp5
# 업무만족도가 높은 직원은 인간관계에 따라 이직률에 영향을 덜 받는다
# 업무만족도가 낮은 직원은 인간관계에 따라 이직률이 증가하는 경향을 보인다 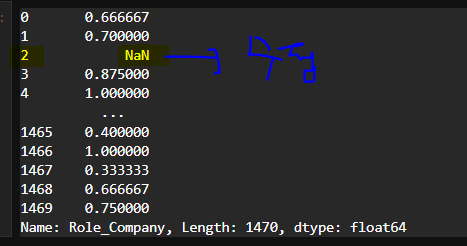
가설2) 근속년수 대비 같은 업무를 한 비중이 높다면 이직률이 높을 것이다
- YearsAtCompany : 직원이 현재 역할에서 근무한 기간
- YearsInCurrentRole : 직원이 현재까지 근무한 기간
# 근속년수 대비 한가지 이상 역할을 한 비중
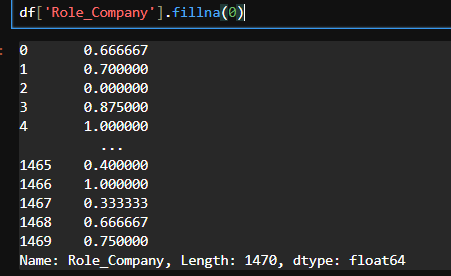
df['Role_Company'] = df['YearsInCurrentRole']/df['YearsAtCompany']
df['Role_Company'] # 0/0 Nan으로 출력되기 때문에 처리 필요
df['Role_Company'].fillna(0, inplace=True) 
# Role_Company 분포 확인
# 데이터의 분포를 시각화 -> distplot(히스토그램과 커널밀도추정(KDE)를 함께 그려서 데이터 분포 나타내기)
sns.distplot(df['Role_Company'])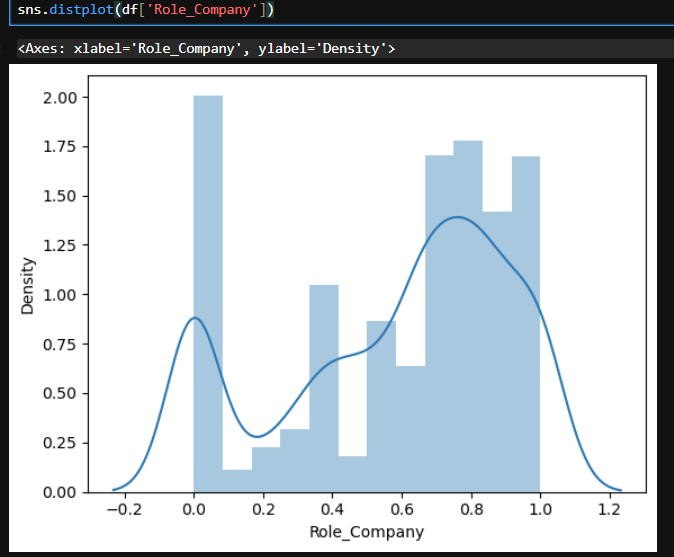
# 구간화
df['Role_Company_gp'] = np.where(df['Role_Company'] <= 0.3, '0.3 이하',
np.where(df['Role_Company'] <= 0.6, '0.3-0.6', '0.6 초과'))
df['Role_Company_gp']
df_gp6 = df.groupby('Role_Company_gp')['Attrition'].agg(['count','sum'])
df_gp6['ratio'] = round(df_gp6['sum']/df_gp6['count']*100, 1) # 반올림
df_gp6 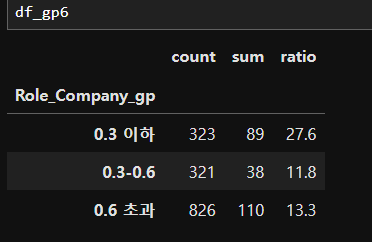
가설3) 야근을 많이 해도 급여인상률이 높다면 이직률이 낮을 것이다.
- OverTime : 초과 근무 여부
- PercentSalaryHike : 연봉 인상률
- Attrition : 이직 여부
# 야근 여부에 따른 이직률 현황
df_gp7 = df.groupby('OverTime')['Attrition'].agg(['count','sum'])
df_gp7['ratio'] = round((df_gp7['sum']/df_gp7['count'])*100, 1)
df_gp7
# 야근을 하는 사람이 이직률이 높다 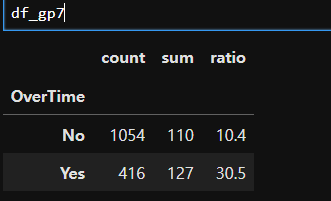
# PercentSalaryHike : 연봉 인상률
df_gp7 = df.groupby(['OverTime','PercentSalaryHike'])['Attrition'].agg(['count','sum'])
df_gp7['ratio'] = round((df_gp7['sum']/df_gp7['count'])*100, 1)
df_gp7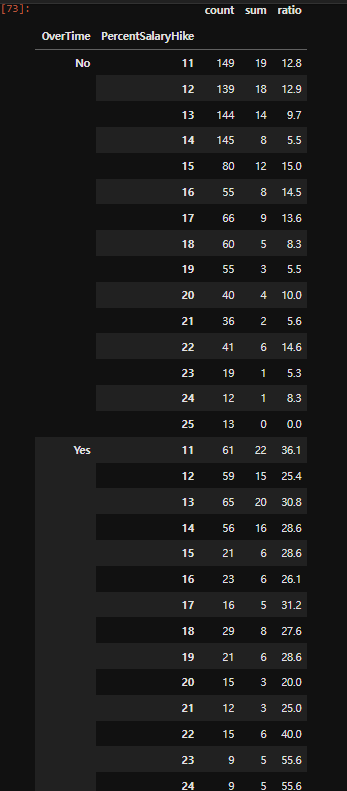
# 야근을 안하는 사람들의 연봉인상에 따른 이직률 평균계산
df_gp7.loc['No']['ratio'].mean()
# 야근을 안 하는 직원은 연봉 인상률과 관계 없이 평균(16%)보다 낮은 편이다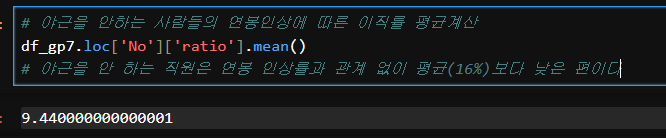
# 야근을 하는 사람들을 분석 (bar chart 시각화)
df_gp7.loc['Yes']['ratio'].plot(kind='bar', ylabel='ratio', rot=45, colormap='Pastel2')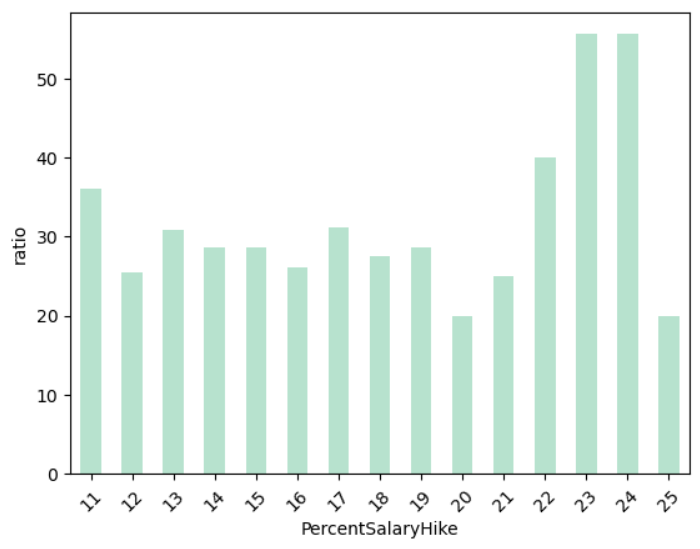
5. 모델링
- 문제와 답 분리
- 글자를 숫자로 변경하는 작업(encoding)
- 원핫인코딩
- 레이블인코딩
- 훈련용데이터와 평가용데이터 분리
- 선형분류 모델활용 학습 : LinearRegression, SVM
- 모델평가
# 문제와 답 분리
df_x = df.drop(['Attrition','Age_gp', 'Role_Company', 'Role_Company_gp'],axis=1)
y = df['Attrition']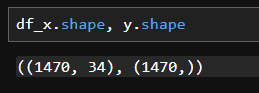
# 숫자형태의 데이터와 글자형태의 데이터 분리
x_types = df_x.dtypes == 'O' # 대문자 O(Object)
x_types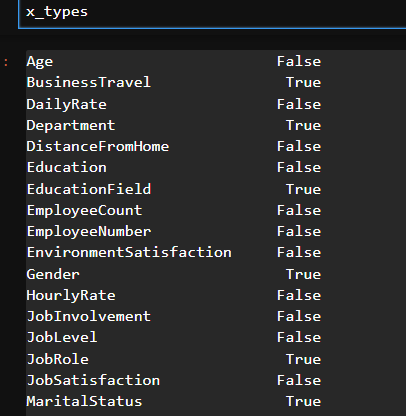

categorical_list = list(x_types[x_types == True].index) # object 형태 데이터
numeric_list = list(x_types[x_types == False].index) # 숫자 형태 데이터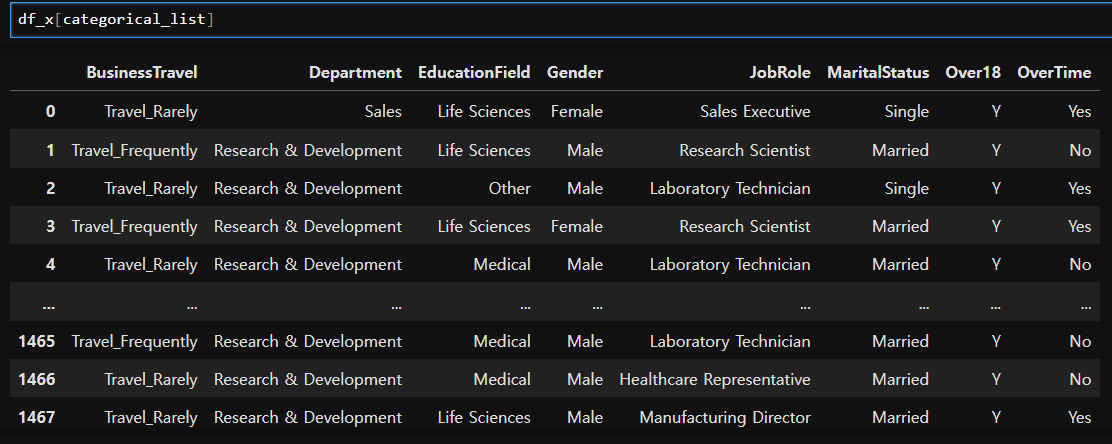
# 출장의 빈도에 따라 이직률에 영향을 주지 않을까?
df_x['BusinessTravel'].unique()
# 레이블인코딩
df_x['BusinessTravel'] = df_x['BusinessTravel'].map({'Non-Travel':0, 'Travel_Rarely':1, 'Travel_Frequently':2}) 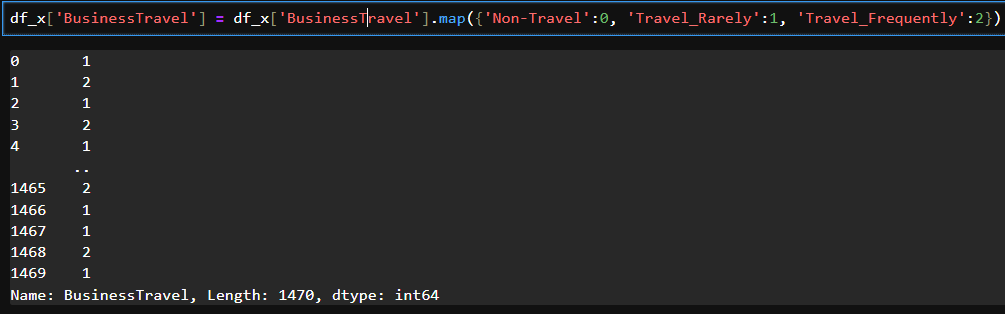
# 원핫인코딩 연습
x_one_hot = pd.get_dummies(df_x[categorical_list])
x_one_hot
# 숫자 타입 데이터는 알아서 거름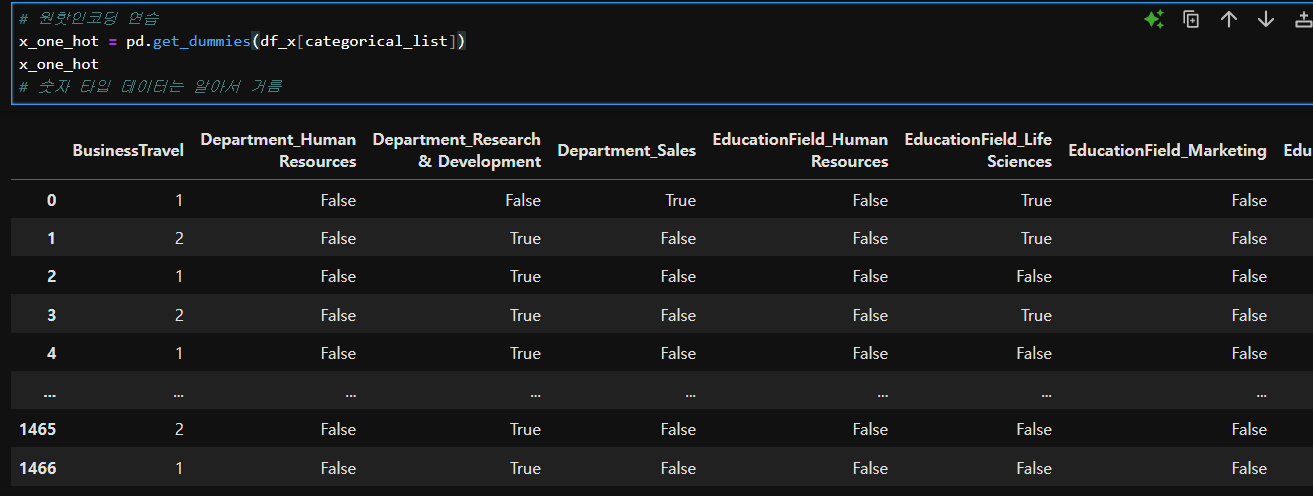
# T/F 숫자로 변경
x_one_hot = pd.get_dummies(df_x[categorical_list], dtype="int32")
x_one_hot 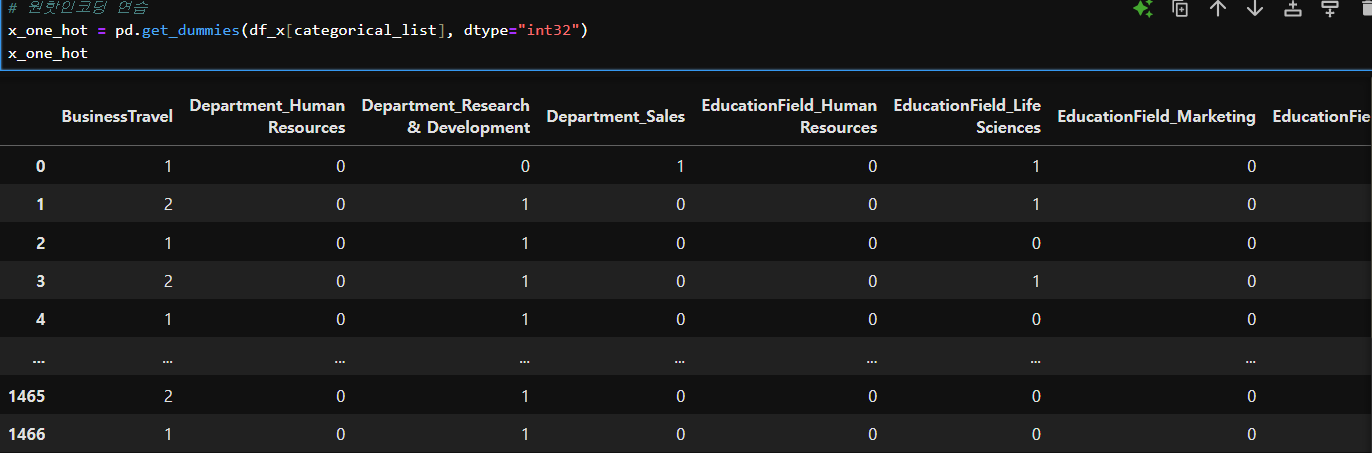
# 숫자 타입 컬럼과 인코딩된 컬럼 병합
X = pd.concat([df_x[numeric_list], x_one_hot], axis=1)
X.shape, y.shape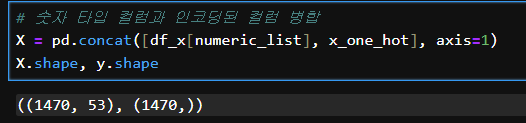
# 훈련용데이터와 평가용데이터 분리
# train_test_split(문제, 정답, 분리비율, 고정키)
X_train, X_test, y_train, y_test = train_test_split(X, y, # 문제와 정답
test_size=0.3, # 테스트데이터의 비율
random_state=819, # 같은 샘플 추출을 위한 난수 고정
stratify=y) # 훈련용과 평가용의 정답 클래스 비율유지
# stratify : 기존 데이터를 나눌 때 래스 분포 비율까지 맞춰 준다# 선형분류 모델활용 학습
# 1. 모델객체 생성
attrition_logi = LogisticRegression()
attrition_svm = LinearSVC() # random_state로 고정하고 튜닝하여 원하는 최종모델로 만들어가는 것# 2. 모델학습
attrition_logi.fit(X_train, y_train)
attrition_svm.fit(X_train, y_train)# 3. 모델 예측
logi_pre = attrition_logi.predict(X_test)
svm_pre = attrition_svm.predict(X_test)# 4. 모델 평가 (정확도)
print("Logi accuracy :", metrics.accuracy_score(y_test, logi_pre))
print("SVM accuracy :", metrics.accuracy_score(y_test, svm_pre))
💠 교차검증 (cross validation)
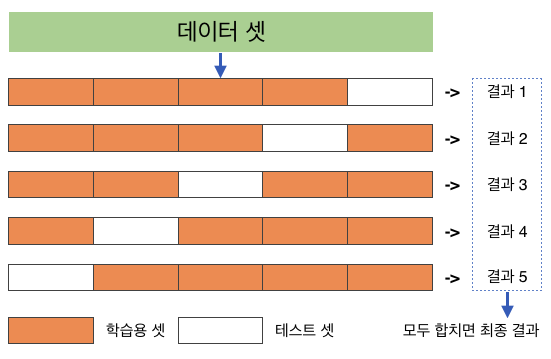
- 테스트 셋을 바꿔가며 (학습용 셋도 바뀜) 검증을 한다. 때문에 해당 결과물들이 약간 달라진다.
- 같은 데이터를 이용하여 테스트를 여러번하는 효과를 얻는다.
- 데이터가 적을 때는 안정적인 평가를 위해 교차검증 시행을 고려해봐야 한다.
- 딥러닝은 교차검증의 중요성이 떨어진다. 딥러닝은 데이터의 양이 많은 상태에서 시작하기 때문이다.
cross_val_score(attrition_logi, X_train, y_train, cv=5) # cv : 검증횟수
# 로지스틱 모델의 교차검증 결과
cross_val_score(attrition_logi, X_train, y_train, cv=5).mean()
# SVM 모델의 교차검증 결과
cross_val_score(attrition_svm, X_train, y_train, cv=5)
-> SVM 모델은 민감하다
-> random_state를 난수 고정하여 시행하는 게 좋다

하이퍼파라미터 튜닝
- 모델이 가지고 있는 파라미터를 최적화해서 성능을 끌어올리는 기법
- 모델의 복잡도(단순한지 복잡한지)를 바꾸어준다.
- 선형분류 모델의 하이퍼파라미터
- C : 규제 파라미터 ➡ 모델의 복잡도를 제어하는 파라미터
- C값이 작을수록 규제가 강력해진다. ➡ W가 적당하게 커지지 못하도록 하는 것 ➡ 과소적합 우려
- C값이 클수록 규제가 약해진다. ➡ W가 너무 커지는 상황 발생 ➡ 과대적합 우려

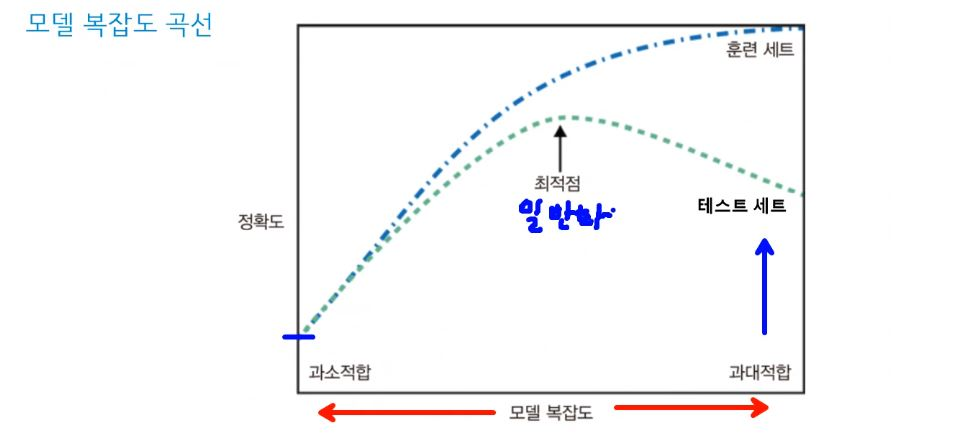
모델의 상태
1) 훈련 데이터 성능 good, 평가 데이터 성능 bad : 과대적합
2) 훈련 데이터 성능 bad, 평가 데이터 성능 bad : 과소적합
3) 훈련 데이터 성능 good, 평가 데이터 성능 good : 일반화
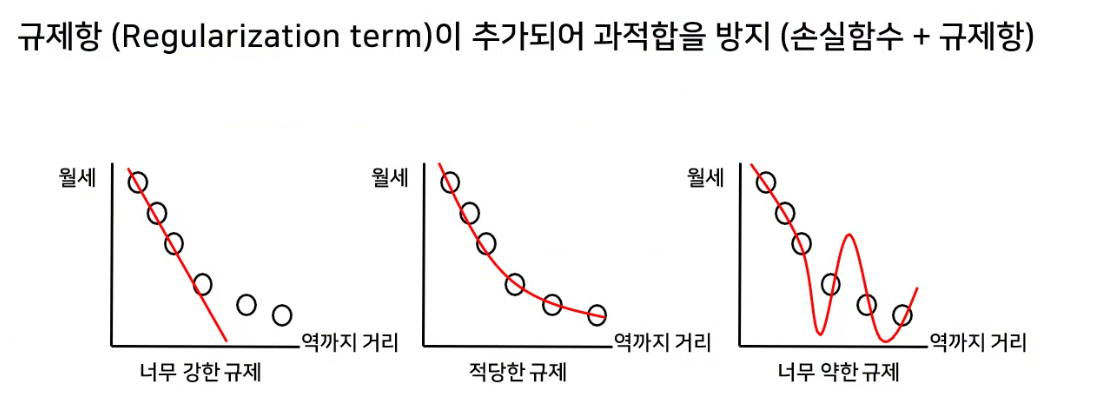
파라미터를 조정하여 복잡도를 변경함.
위의 예시사진에서 왼쪽이 가장 단순하고, 오른쪽이 가장 복잡하고, 가운데가 적당한 복잡도를 가지고 있다.
적당한 복잡도를 가진 일반화된 모델을 유도해야 한다.
모델이 너무 단순하면 과소적합에 빠질 확률이 높다. 훈련이 적어 학습능력이 떨어짐.
모델이 너무 복잡하면 훈련데이터의 케이스에 잘 예측하나 테스트데이터에 대한 정확도가 떨어져 과대적합에 빠질 확률이 높다.
LinearRegression
# 규제 파라미터 값을 모은 리스트
C_list = [10000, 1000, 100, 10, 1, 0.1, 0.01, 0.001, 0.0001] # 규제가 약한 것부터 강한 것까지
# 훈련용데이터 평가점수를 담을 리스트
train_list = []
# 평가용데이터 평가점수를 담을 리스트
test_list = []
for my_C in C_list :
logi2 = LogisticRegression(C=my_C) # 선형분류 모델객제 생성 # C=1.0 (Default)
logi2.fit(X_train, y_train) # 훈련용데이터 학습
pre_train = logi2.predict(X_train) # 훈련용데이터 예측
score_train = metrics.accuracy_score(y_train, pre_train) # 정확도 계산(실제값, 예측값)
train_list.append(score_train) # 리스트에 훈련용데이터 점수 추가
pre_test = logi2.predict(X_test) # 평가용데이터 예측
score_test = metrics.accuracy_score(y_test, pre_test) # 정확도 계산(실제값, 예측값)
test_list.append(score_test) # 리스트에 평가용데이터 점수 추가# 튜닝결과 시각화
plt.figure(figsize=(10,5)) # 가로, 세로 비율
plt.plot(train_list) # 훈련용데이터 라인그래프
plt.plot(test_list) # 평가용데이터 라인그래프
plt.xticks(range(len(C_list)), C_list) # X축 눈금 지정
plt.show() # 그래프 보여주기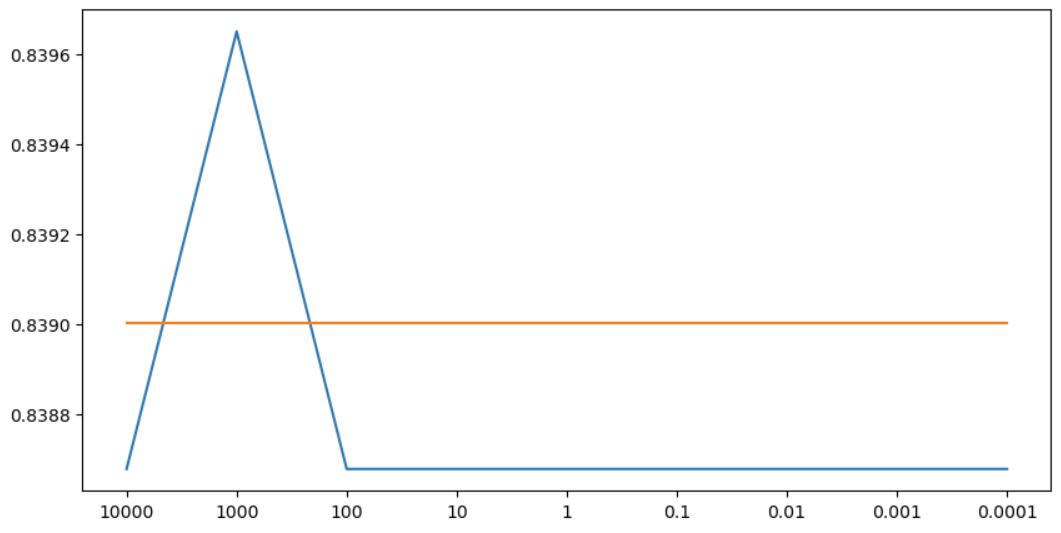
LinearSVC
# 규제 파라미터 값을 모은 리스트
C_list = [10000, 1000, 100, 10, 1, 0.1, 0.01, 0.001, 0.0001] # 규제가 약한 것부터 강한 것까지
# 훈련용데이터 평가점수를 담을 리스트
train_list = []
# 평가용데이터 평가점수를 담을 리스트
test_list = []
for my_C in C_list :
svc = LinearSVC(C=my_C, random_state=1122) # 선형분류 모델객제 생성 # C=1.0 (Default)
svc.fit(X_train, y_train) # 훈련용데이터 학습
pre_train = svc.predict(X_train) # 훈련용데이터 예측
score_train = metrics.accuracy_score(y_train, pre_train) # 정확도 계산(실제값, 예측값)
train_list.append(score_train) # 리스트에 훈련용데이터 점수 추가
pre_test = svc.predict(X_test) # 평가용데이터 예측
score_test = metrics.accuracy_score(y_test, pre_test) # 정확도 계산(실제값, 예측값)
test_list.append(score_test) # 리스트에 평가용데이터 점수 추가# 튜닝결과 시각화
plt.figure(figsize=(10,5)) # 가로, 세로 비율
plt.plot(train_list) # 훈련용데이터 라인그래프
plt.plot(test_list) # 평가용데이터 라인그래프
plt.xticks(range(len(C_list)), C_list) # X축 눈금 지정
plt.show() # 그래프 보여주기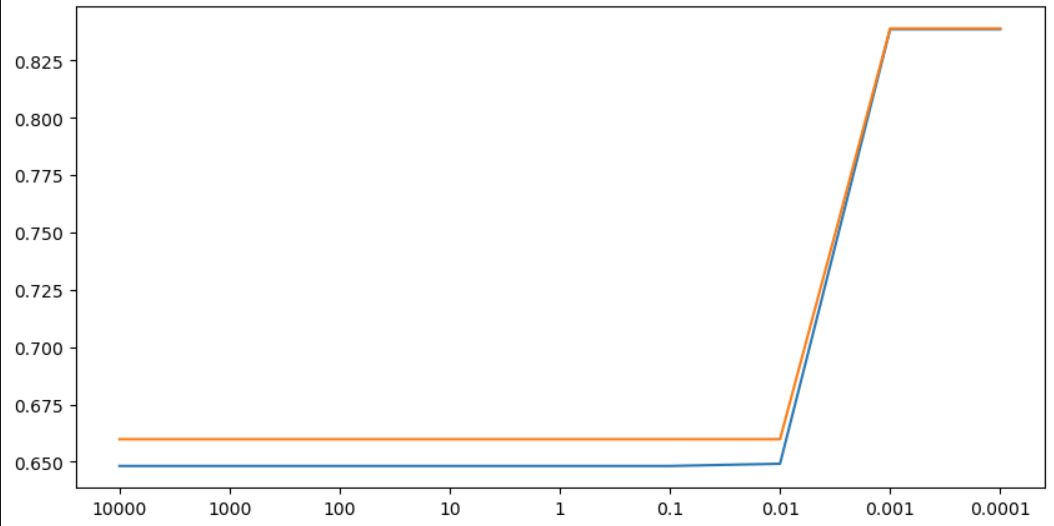
교차검증을 이용한 하이퍼파라미터 튜닝
# 규제 파라미터 값을 모은 리스트
C_list = [10000, 1000, 100, 10, 1, 0.1, 0.01, 0.001, 0.0001] # 규제가 약한 것부터 강한 것까지
# 교차검증 평가점수를 담을 리스트
cross_val_list = []
# 평가용데이터 평가점수를 담을 리스트
test_list = []
for my_C in C_list :
svc = LinearSVC(C=my_C, random_state=1122)
cv_score = cross_val_score(svc, X_train, y_train, cv=5).mean() # 교차검증 점수평균
cross_val_list.append(cv_score) # 교차검증 점수평균을 리스트에 추가
svc.fit(X_train, y_train) # 모델학습
pre_test = svc.predict(X_test) # 평가용데이터 예측
score_test = metrics.accuracy_score(y_test, pre_test) # 정확도 계산(실제값, 예측값)
test_list.append(score_test) # 리스트에 평가용데이터 점수 추가# 튜닝결과 시각화
plt.figure(figsize=(10,5)) # 가로, 세로 비율
plt.plot(cross_val_list) # 교차검증 평가점수 라인그래프 그리기
plt.plot(test_list) # 평가용데이터 라인그래프
plt.xticks(range(len(C_list)), C_list) # X축 눈금 지정
plt.show() # 그래프 보여주기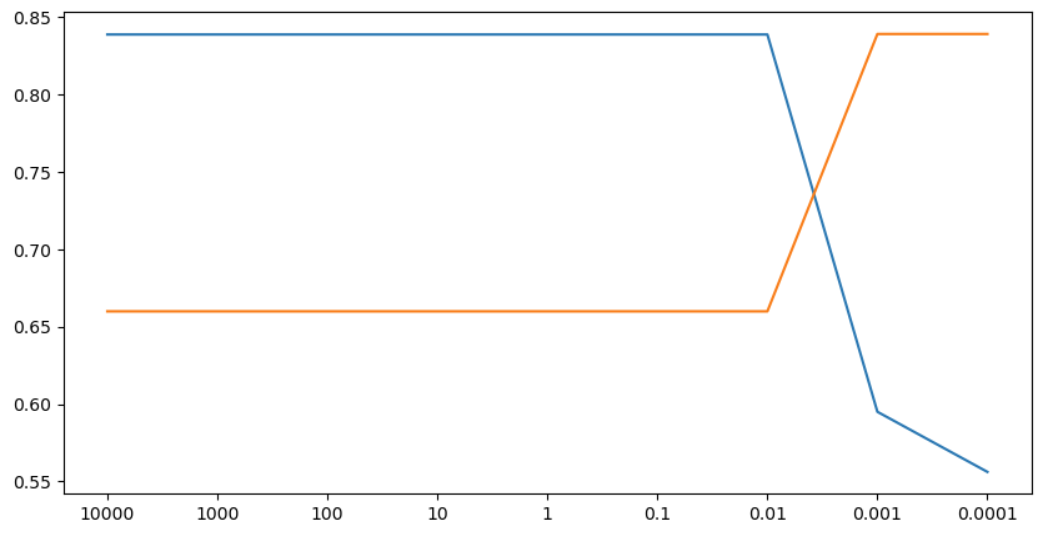
6. 모델평가
정확도
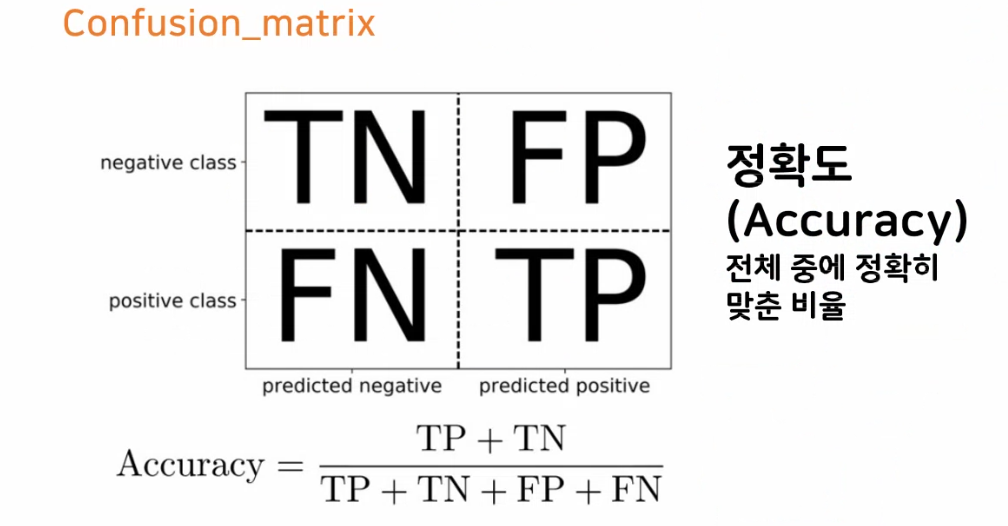
- 정확도는 높게 나오지만 TP가 없고 모델에 대해 잘못 판단할 수 있다 특히 데이터 불균형 했을 때, 특히 음성 클래스의 분포가 높을 때
- 그래서 Recall, Precision 확인

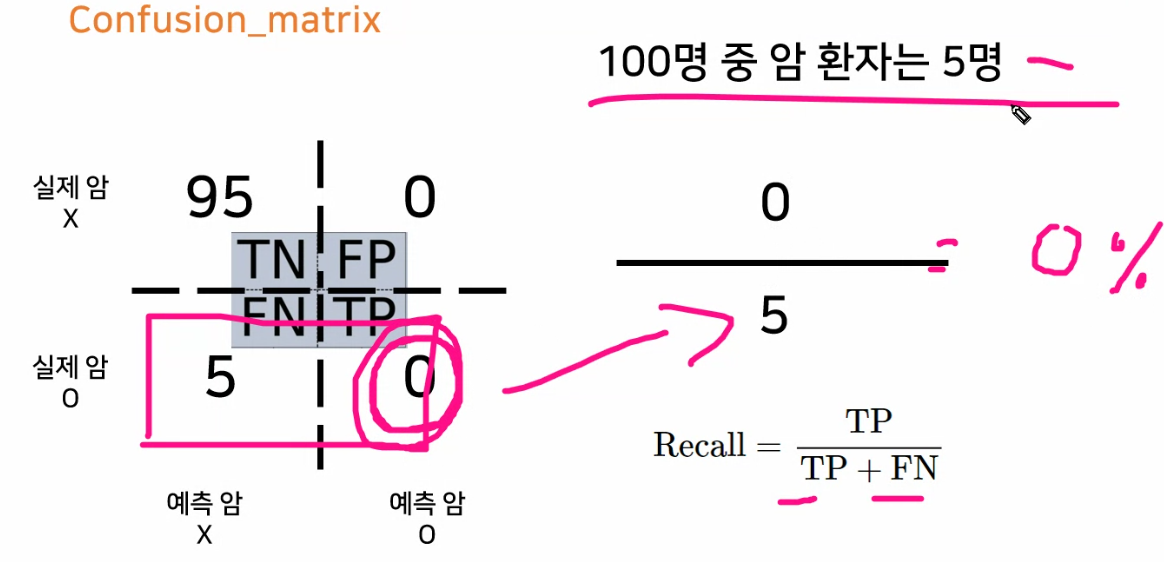
정확도는 95%이나 재현율은 5%
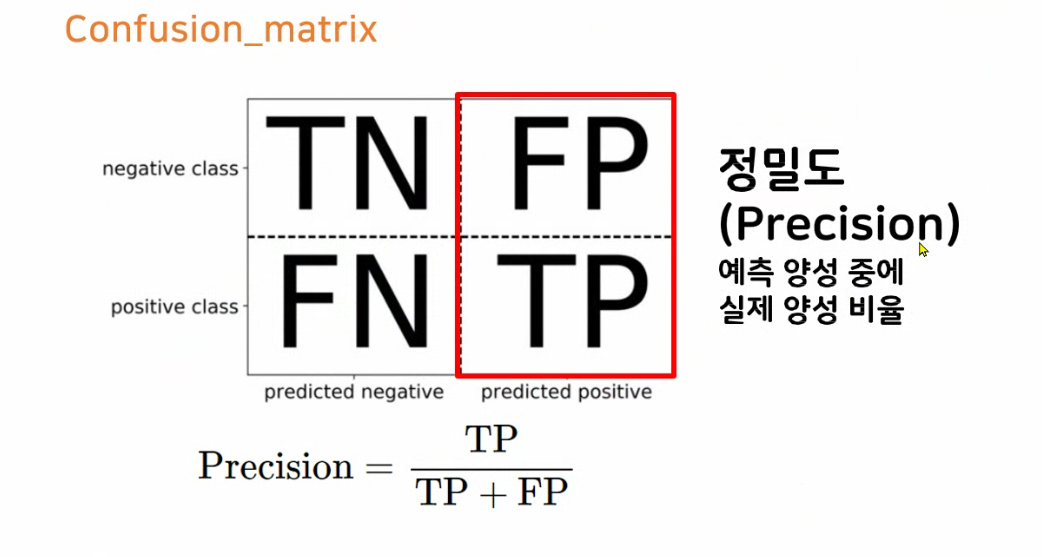
재현율은 100% (실제 양성클래스는 맞추었으나) (양성클래스라고 추측한 것 중에 실제로 맞춘 것) 정밀도 5%
- 재현율(Recall) : TP / TP+FN
- 예측해서 맞춘 것들 중에 양성클래스의 비율
- 정밀도(Precision) : TP / TP+FP
- 양성클래스라고 예측한 것 중에 맞춘 비율
# 튜닝이 끝난 모델
logi3 = LogisticRegression(C=1)
svc2 = LinearSVC(random_state=1122, C=0.01)
# 모델학습
logi3.fit(X_train, y_train)
svc2.fit(X_train, y_train)
# 모델예측
logi_pre = logi3.predict(X_test)
svc_pre = svc2.predict(X_test)# 다양한 분류평가지표로 검증
print(classification_report(y_test, logi_pre))
print(classification_report(y_test, svc_pre))- f1-score : precision과 recall의 조화평균, 두개 다 높아야 f1-score가 높음.
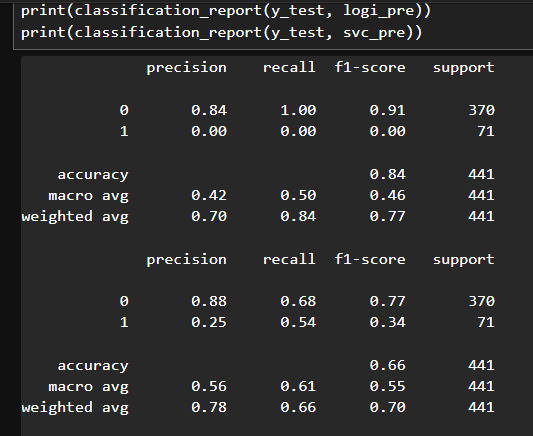

Hello, World!