학습목표
- 감성분석 모델링을 할 수 있다
- 토큰화/수치화 방법을 이해할 수 있다.
- konlpy 사용법을 이해할 수 있다.
감성분석
- 사람의 감정/기분/태도 등을 분석하는 기법
- case 1 : 감성사전을 이용한 분석(전통적인 방식)
- case 2 : 인공지능 기술을 이용한 분석(최근 방식)
colab에서 데이터 로딩
# 데이터로딩
import pandas as pd
train_text = pd.read_csv("./train_origin_text.csv")
test_text = pd.read_csv("./test_origin_text.csv")
한국어 형태소 분리시 자주 활용하는 konlpy를 사용
1. jdk, Jype 등을 설치 - PC 상태에 따라 안 되는 경우 많음 -> colab으로 진행
2. konlpy 형태소 분석기 중에서 mecab이 있음 -> 리눅스 운영체제에서 사용 가능 -> colab으로 진행
형태소 분석기 활용
# konlpy 설치
!pip install konlpyhttps://konlpy.org/ko/latest/index.html

from konlpy.tag import Okt, Kkma, Mecabmecab 설치
https://github.com/SOMJANG/Mecab-ko-for-Google-Colab
# mecab을 위한 설치
!git clone https://github.com/SOMJANG/Mecab-ko-for-Google-Colab.git%cd Mecab-ko-for-Google-Colab!bash install_mecab-ko_on_colab_light_220429.shokt = Okt() # 트위터 기반으로 시작된 형태소 분석기 -> 비교적 신조어 분리에 강함
kkma = Kkma() # 속도는 느림, 품사태깅이 디테일하다
mecab = Mecab() # 처리 속도가 빠르다# 형태소 분리
okt.morphs("아버지가 방에 들어가신다.")kkma.morphs("아버지가 방에 들어가신다.")
# 형태소 분리 및 품사 부착
okt.pos("아버지가 방에 들어가신다.")kkma.pos("아버지가 방에 들어가신다.")
# 태그셋 확인
print(okt.tagset)
print(kkma.tagset)
# okt의 토큰 정규화 및 어근 추출
okt.pos("어제는 저녁을 맛있게 먹었닼ㅋ", norm=True, stem=True)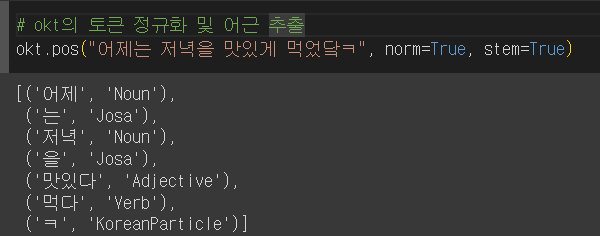
데이터 클렌징
- 이모지 제거
!pip install emojiimport emoji
from tqdm import tqdmtrain_rm_emoji = [emoji.replace_emoji(s) for s in train_text['문장']]# kkma vs mecab
train_text.dropna(inplace=True)
train_kkma_morphs = [kkma.morphs(s) for s in tqdm(train_rm_emoji)]-> kkma 시간 오래 걸린다
train_mecab_morphs = [mecab.morphs(s) for s in tqdm(train_rm_emoji)]
-> mecab이 kkma에 비해 상대적으로 시간 빠름
# 정규표현식 활용 클렌징
import re # 정규표현식을 사용할 수 있는 모듈 로딩# 클렌징할 패턴 생성
unsmile_p = re.compile('[!?,.:;0-9a-zA-zㅋㅎㄷㅇ~]+')clean_morphs_train = [] # 클렌징된 단어토큰이 들어갈 리스트
for s in train_mecab_morphs: # 형태소로 분리된 훈련용 문장 전체반복
temp = [] # 한 문장을 담을 리스트
for w in s : # 하나의 문장에서 형태소 단위로 반복
if unsmile_p.search(w): # 단어토큰이 패턴에 매칭된다면
continue # 다음 단어 반복으로 넘어감
if len(w) < 2 : # 한글자 단어라면
continue # 다음 단어 반복으로 넘어감
temp.append(w) # 패턴에 매칭되지 않는 다면 리스트에 추가
clean_morphs_train.append(temp) # 한 문장을 전체 리스트에 추가 clean_morphs_test = [] # 클렌징된 단어토큰이 들어갈 리스트
for s in test_mecab_morphs: # 형태소로 분리된 훈련용 문장 전체반복
temp = [] # 한 문장을 담을 리스트
for w in s : # 하나의 문장에서 형태소 단위로 반복
if unsmile_p.search(w): # 단어토큰이 패턴에 매칭된다면
continue # 다음 단어 반복으로 넘어감
if len(w) < 2 : # 한글자 단어라면
continue # 다음 단어 반복으로 넘어감
temp.append(w) # 패턴에 매칭되지 않는 다면 리스트에 추가
clean_morphs_test.append(temp) # 한 문장을 전체 리스트에 추가 print(len(clean_morphs_train))
print(len(clean_morphs_test))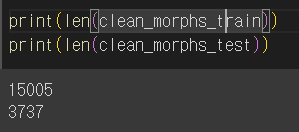
파일 저장 후 로컬 환경으로 이동
# 피클을 이용해 전처리된 파일 저장
import picklewith open("./clean_morphs_train.pkl", "wb") as f: # wb 쓰기모드
pickle.dump(clean_morphs_train, f)with open("./clean_morphs_test.pkl", "wb") as f: # wb 쓰기모드
pickle.dump(clean_morphs_test, f)
Jupyter에서 처리한 데이터 로딩
# 'ex05_2_텍스트마이닝_응용_konlpy_사용하기.ipynb' 파일에서 처리한 데이터 로딩
import picklewith open("./data/clean_morphs_train.pkl", 'rb') as f : # rb 읽기모드
clean_morphs_train = pickle.load(f)
with open("./data/clean_morphs_test.pkl", 'rb') as f : # rb 읽기모드
clean_morphs_test = pickle.load(f)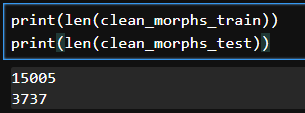
토큰화 및 수치화 (특성추출)
- 토큰화 : 일정 단위로 텍스트를 분리하는 작업
- 글자(char) : apple -> a / p / p / l / e
- 단어(word) : 보통 띄어쓰기 기준으로 분리 -> 보통 / 띄어쓰기 / 기준으로 / 분리
- 형태소 : 동사, 명사, 형용사 등 형태소 기준으로 분리
- n-gram(유니,바이,트라이 등) : 1/2/3개씩 단어를 묶어서 토큰화하는 방법
- 오늘 점심은 맛있는 카레 -> 유니그램 -> 오늘 / 점심은 / 맛있는 / 카레
- 오늘 점심은 맛있는 카레 -> 바이그램 -> 오늘 점심은 / 점심은 맛있는 / 맛있는 카레
- 오늘 점심은 맛있는 카레 -> 트라이그램 -> 오늘 점심은 맛있는 / 점심은 맛있는 카레
- 수치화(특성추출) : 의미있는 정보를 담고 있는 숫자형태로 변환하는 방법, 데이터를 정형화하는 효과가 있다.
- 빈도 기반의 레이블인코딩 : 레이블인코딩처럼 단어마다 숫자를 부여하는 방식
- 원핫인코딩과 유사한 BOW, TF-IDF
- Word embedding : 딥러닝 학습을 이용해서 수치화하는 기법
BOW(Bag of word)
- 문장에서 등장하는 단어의 빈도를 측정해 수치화하는 방법
- 단어사전 구축 -> 단어사전 기반으로 문장 내의 단어 빈도를 측정
- 장점 : 단순한 알고리즘이라 이해하기가 편하다
- 단점 : 말뭉치에 사용되는 단어가 많으면 부피가 비례해서 커진다 / 문장에서 단어의 순서를 고려하지 않음 (문맥 파악하는 분석에는 부적합)
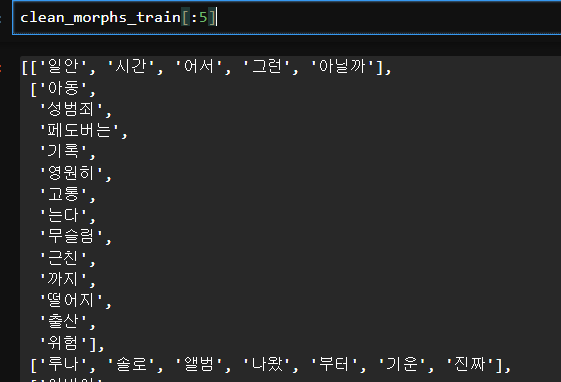
from sklearn.feature_extraction.text import CountVectorizersample_text = clean_morphs_train[:3]
sample_cv = CountVectorizer() # BOW를 해주는 객체 생성
print(sample_text[0])
print(sample_text[1])
print(sample_text[2])
# step 1 : 토큰화 및 단어사전 구축
# countvectorize에 토큰화 기능이 내장되어 있어 문장을 하나로 묶어주는 전처리 작
sample_text2 = [" ".join(s) for s in sample_text]
sample_text2
sample_cv.fit(sample_text2)# 구축된 단어사전 확인 -> 25개 단어 등장
# 빈도에 따라 수가 올라간다
sample_cv.vocabulary_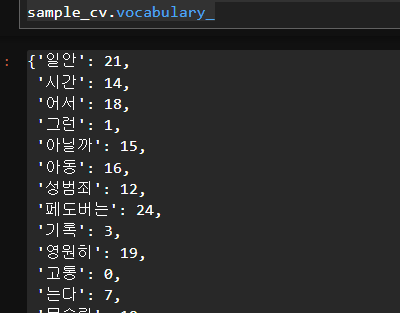
# step 2 : 단어사전을 기반으로 문장 내의 단어빈도를 측정
result = sample_cv.transform(sample_text2)
result
# 3문장(행)을 25개 단어(컬럼)로 표현되도록 변환 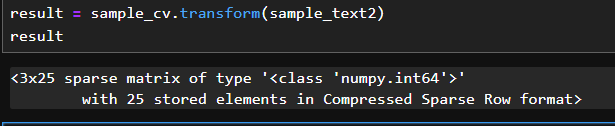
# 만약 데이터를 직접 보고 싶다면 활용
result.toarray()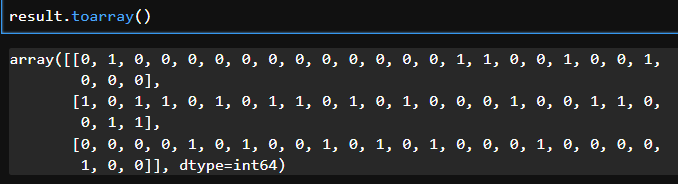
# 단어사전을 데이터 프레임을 변환
result_df = pd.DataFrame([sample_cv.vocabulary_.keys()],
columns = sample_cv.vocabulary_.values())
result_df = result_df.sort_index(axis=1) # 컬럼을 기준으로 정렬
result_df
pd.concat([result_df, pd.DataFrame(result.toarray())])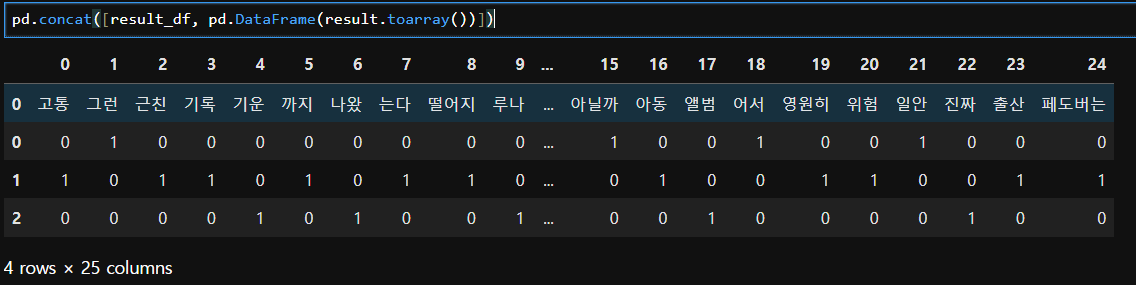

Hello, World!