Machine Learning
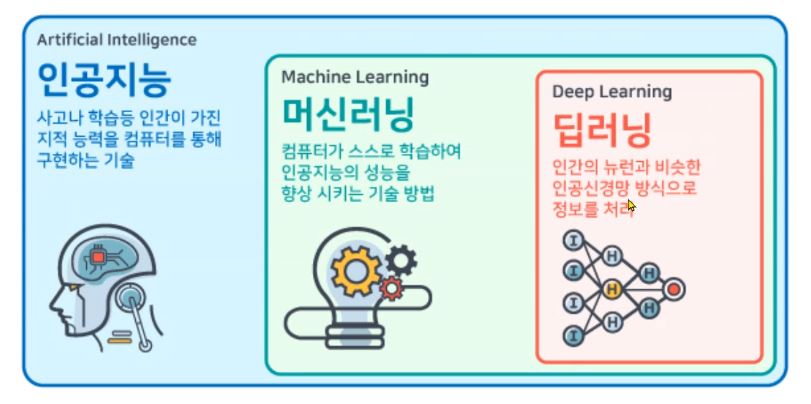
머신러닝이란?
- 컴퓨터가 스스로 학습하여 AI 성능을 향상시키는 기술 방법
- 데이터를 기반으로 '학습'시켜서 '예측'하게 만드는 기법


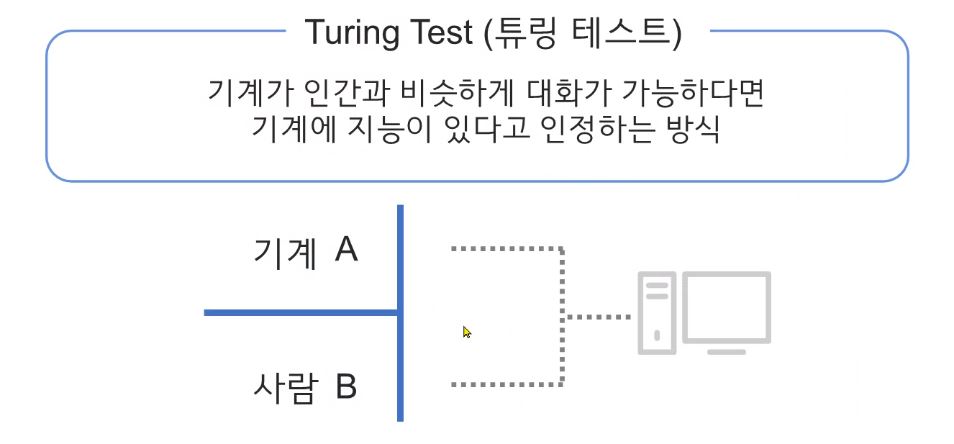
앨런튜링
1950년 논문에서 "기계는 생각할 수 있는가"에 대한 자신의 답으로 '튜링테스트'를 제안한다.
->Turing Test (1950) : 기계가 인공지능을 갖추었는지를 판별하는 실험

[인공지능의 종류 3가지]
1) 약한 인공지능
2) 강한 인공지능
3) 초인공지능

-> 현재는 강한 인공지능을 목표로 힘쓰고 있다.
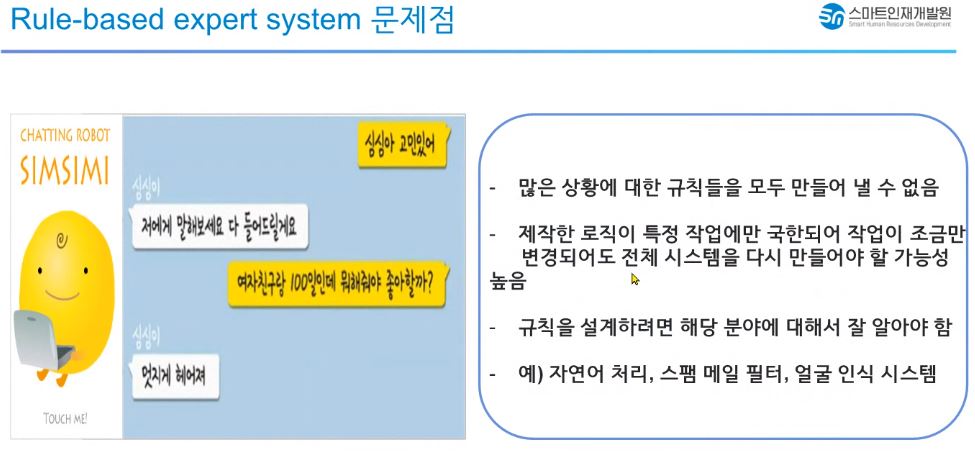
Rule-based expert system
- 많이 알려진 '심심이'는 Rule-based expert system(규칙기반전문가시스템)으로 만들어진 채팅로봇이다.
- 인공 지능의 초기 형태 중 하나로서, 많은 전통적 AI와 전문가 시스템에서 중요한 역할을 했다.
- if - else로 상황에 대한 규칙을 만들어내야 하는데 많은 상황에 대한 규칙들을 모두 만들어 낼 수 없다라는 단점이 있다.
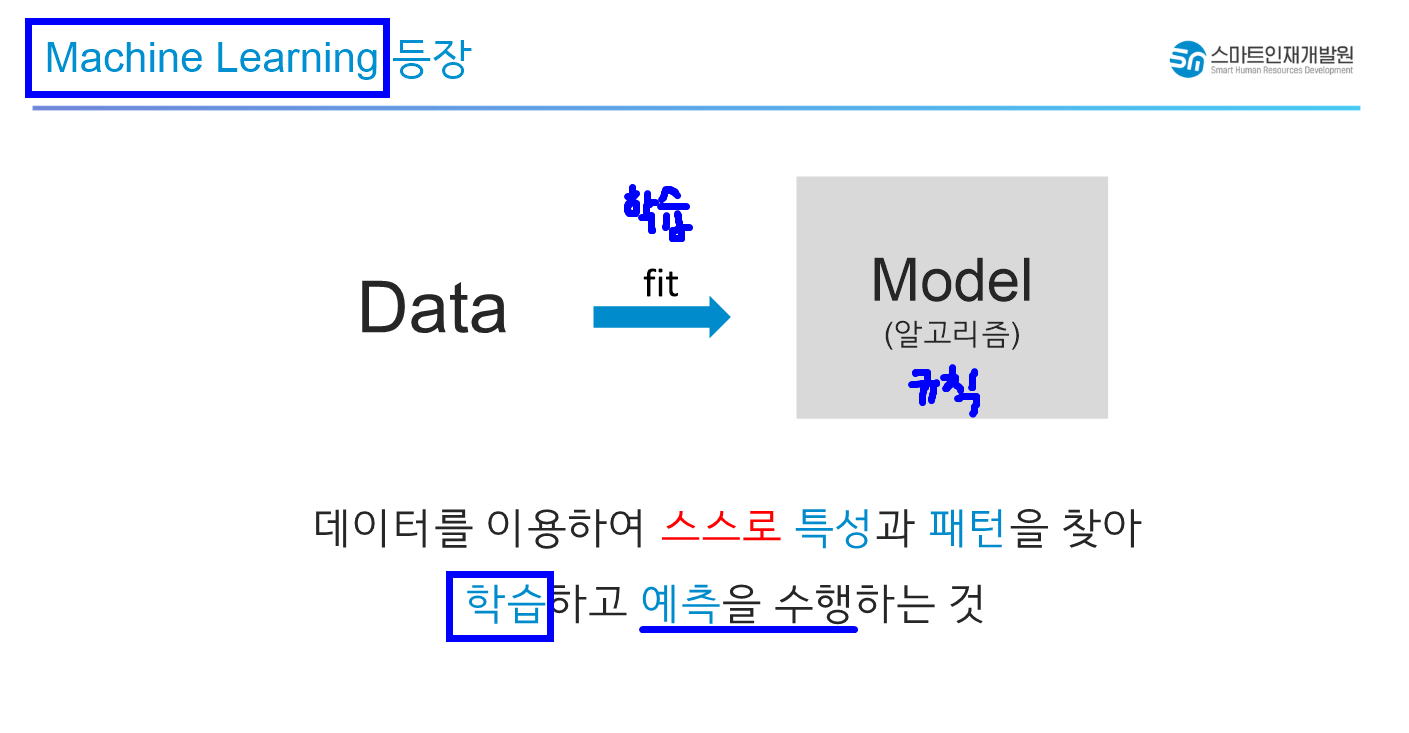
✅Machine Learning의 등장
데이터를 이용하여 스스로 특성과 패턴을 찾아 학습하고 예측을 수행하는 것
ML의 종류
(1) 지도학습
(2) 비지도학습
(3) 강화학습
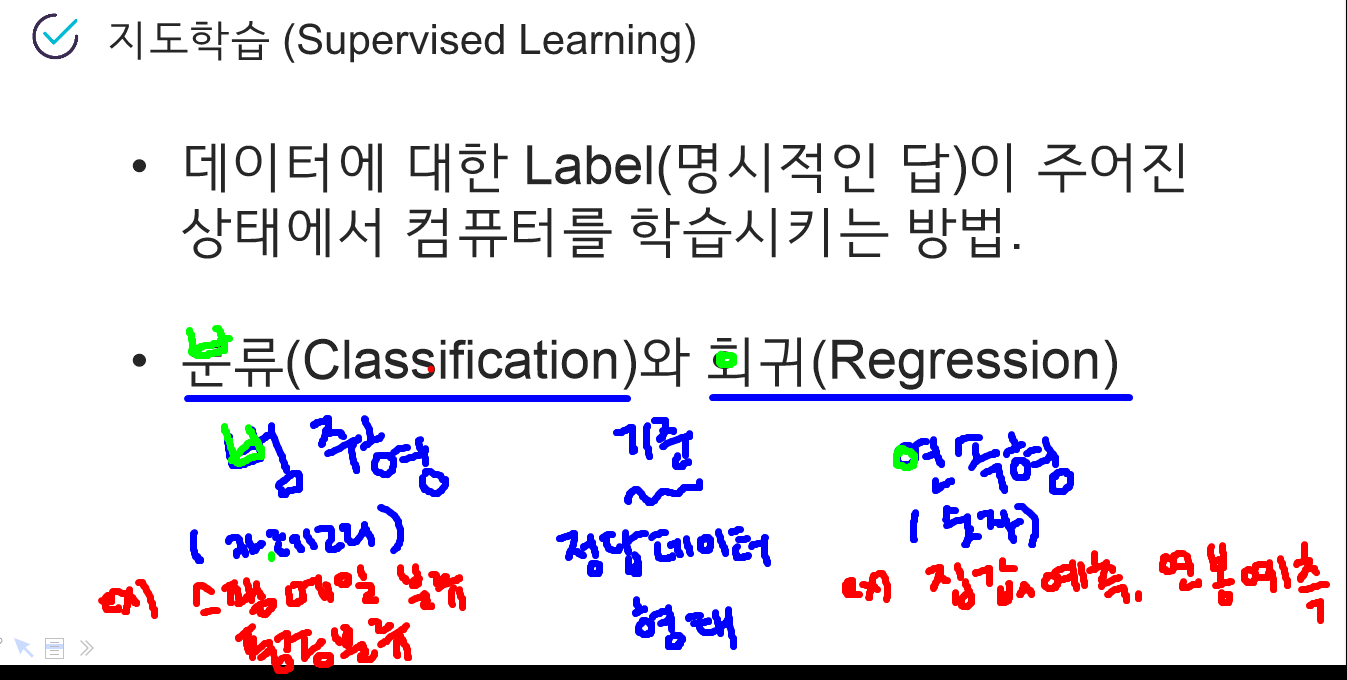
🤍 (1) 지도학습
: 데이터에 대한 ★Label(명시적인 답)이 주어진 상태에서 컴퓨터를 학습

<정답 데이터의 형태에 따라 분류>
- 분류(Classification) :
범주형 데이터 (카테고리)
: 미리 정의된 여러 클래스(정답데이터 종류) 레이블 중 하나를 예측하는 것
EX)스팸 메일 분류, 품종 분류.. ->이진분류, 다중분류.. - 회귀(Regression) :
연속형 데이터 (숫자)
EX)연봉예측, 집값예측..


🤍 (2) 비지도학습
: 데이터에 대한 Label이 없는 상태에서 컴퓨터를 학습
-데이터의 숨겨진 특징, 구조, 패턴을 파악하는데 사용
-Clustering(클러스터링,군집화)
-Dimensionality Reduction (차원축소)
EX) 이미지 감색 처리, 소비자 그룹 발견을 통한 마케팅

🤍 (3) 강화학습
: 지도 학습과 비슷하지만 완전한 답(Label) 제공하지 않음
- 기계는 더 많은 ★
보상을 얻을 수 있는 방향으로 행동을 학습 - 주로 게임이나 로봇을 학습시키는데 많이 사용
EX) 알파고, 사료 자동급식기

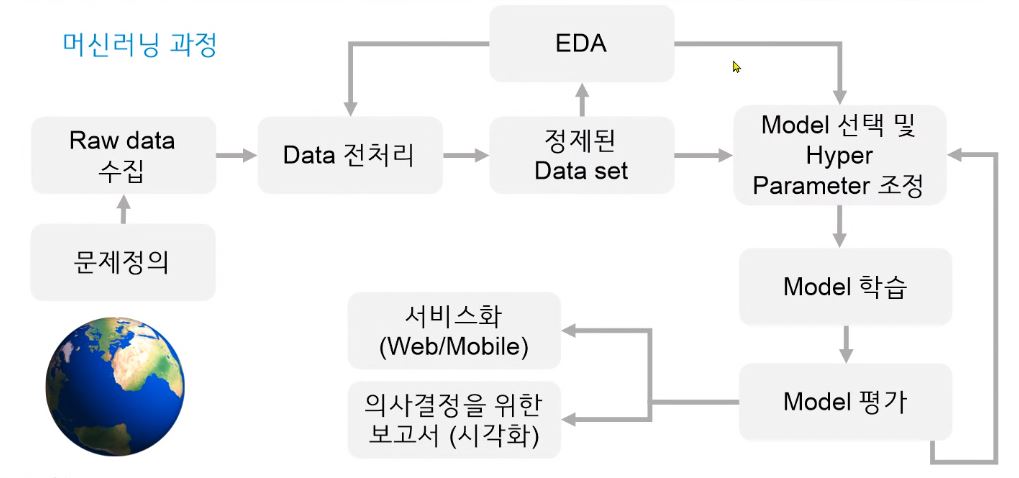
✅ML 과정








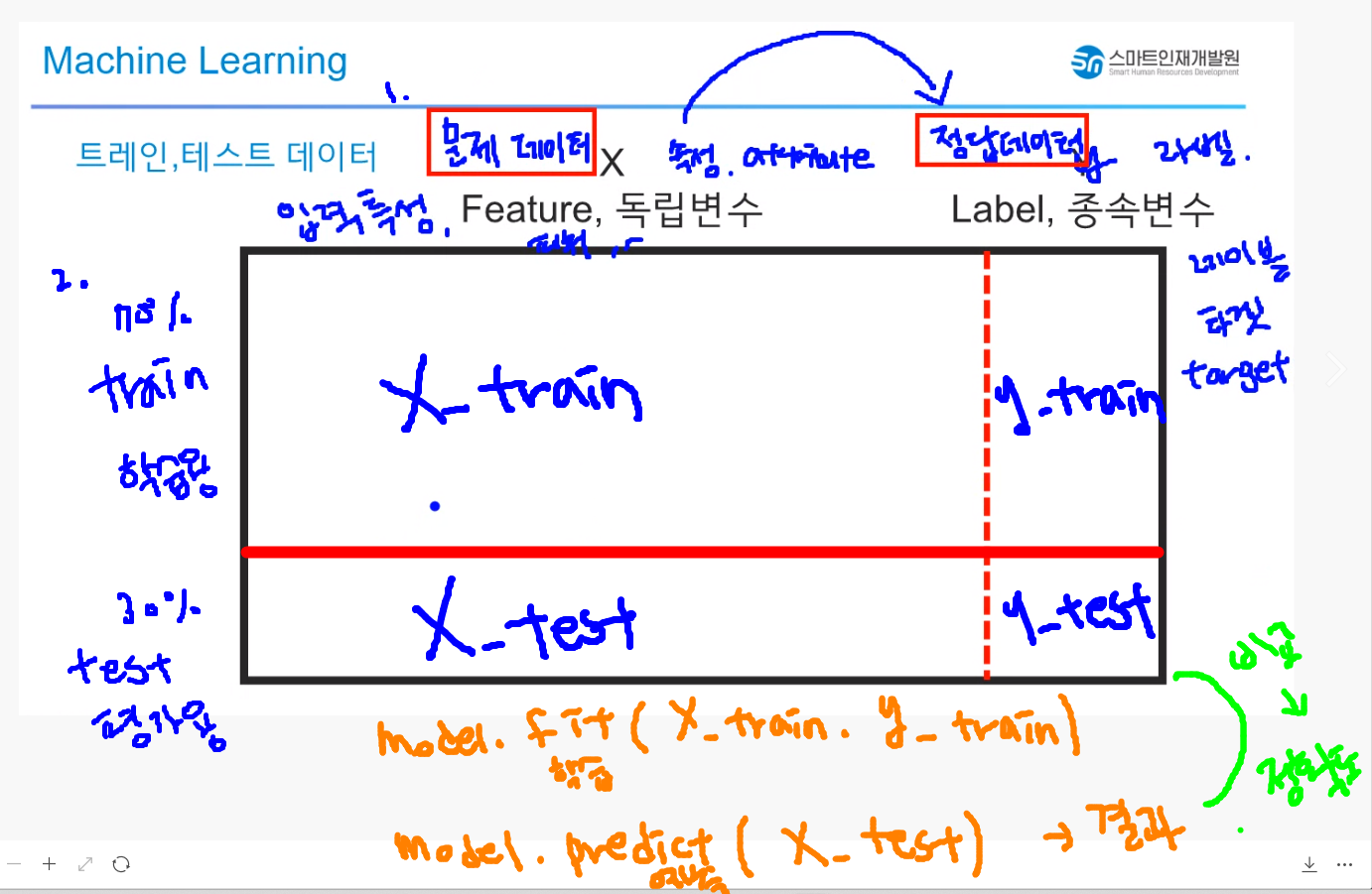
X 문제데이터 = 입력 특성 = feature = 독립변수 = 속성(attribute)
y 정답데이터 = Lable = 종속변수 = target(타겟)

[실습] bmi 예측하기
- 문제 정의
- 500명의 키와 몸무게 데이터를 활용하여 BMI 예측하기
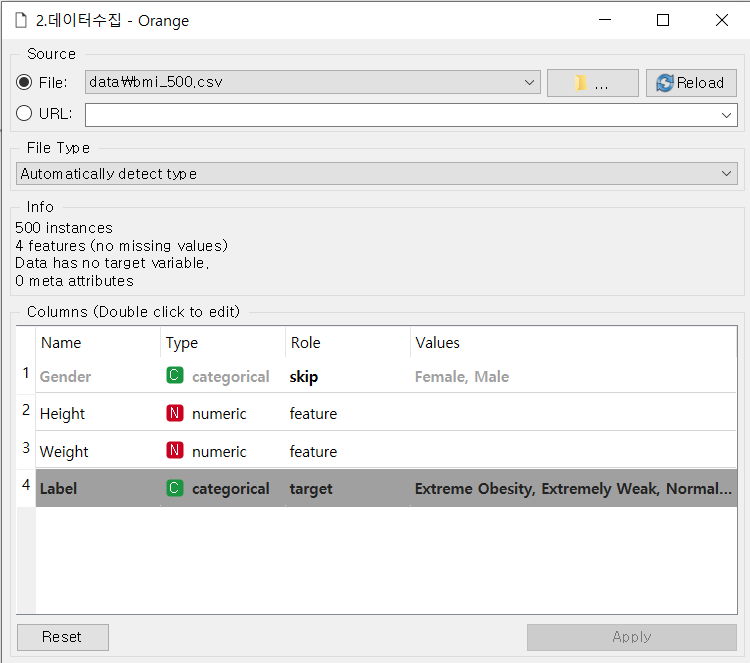
[File]
- 데이터로 사용할 파일 불러오기
- target, feature 설정해주기
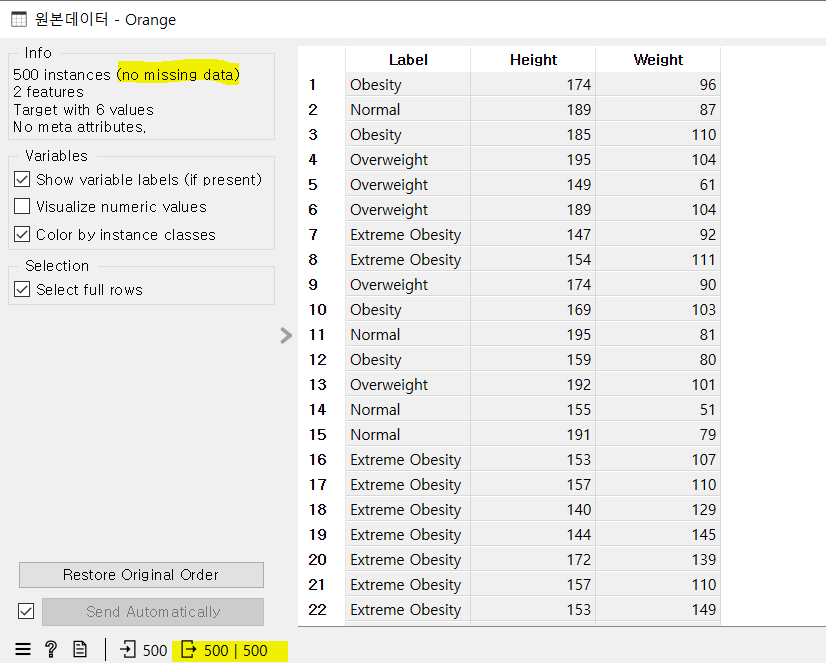
[Data Table]
- 전체 500 instances 선택 되었는지 확인하기
- feature 개수, label 확인
- missing Data : 0 -> 결측치가 없어서 전처리 필요 없다
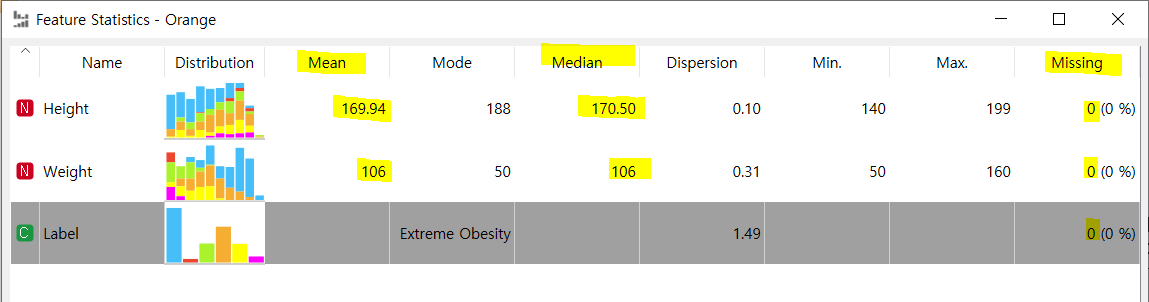
[Feature Statistics]
- mean(평균)과 median(중위값 or 중앙값)이 큰 차이가 없어 이상치가 없다고 판단
->이상치가 있다면 평균과 중위수 차이가 클 것
-> 현재 데이터는 이상치가 없음.
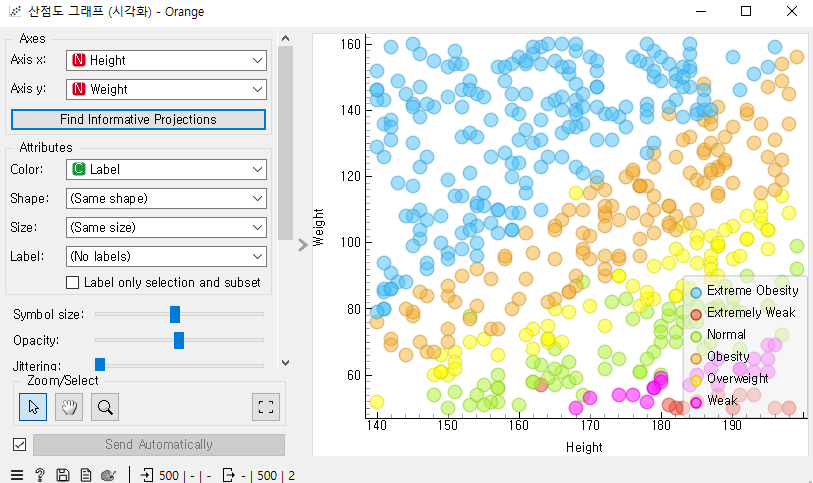
[Scatter Plot]
- 산점도 그래프를 통해 시각화한 데이터를 볼 수 있음.
골고루 분포되었는지 결측치가 없는지 확인하기. 필요시 결측치 제거해주거나 변경필요.
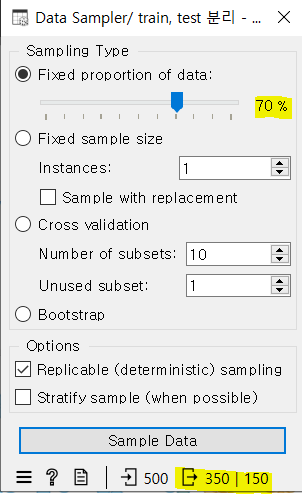
[Data Sampler]
- 데이터 샘플러를 통해 train과 test를 분리한다
보통 train:test = 7:3 비율로 분리하며, 분리된 개수 확인하기
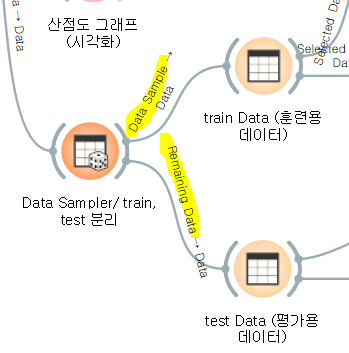
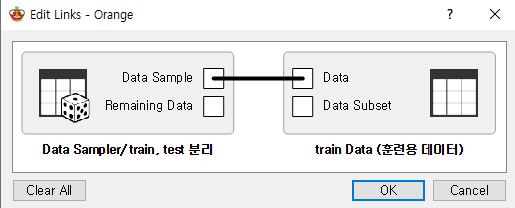
Edit Links (연결선 클릭하여 변경 가능)을 통하여 train Data로 사용할 Data Table에는 'Data Sample' 연결
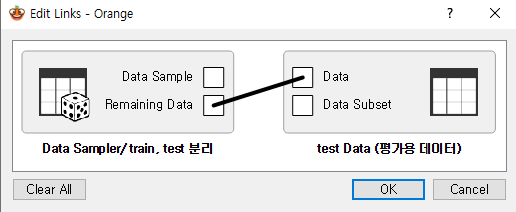
Edit Links (연결선 클릭하여 변경 가능)을 통하여 test Data로 사용할 Data Table에는 'Remaining Data' 연결
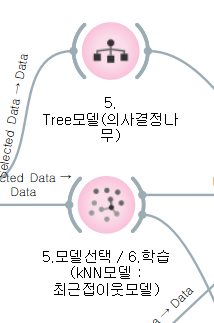
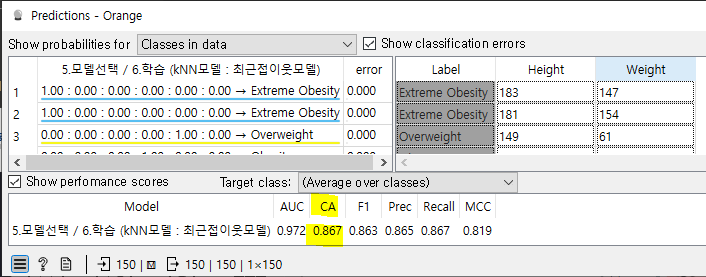
[모델 선택]
kNN모델과 Tree모델 이용해서 학습 후 test 해보기

※kNN(K-Nearest Neighbors)
: k-최근접 이웃 알고리즘
-유유상종 개념과 유사
-새 데이터 포인트와 가장 가까운 훈련 데이터셋의 데이터 포인트를 찾아 예측
-k값에 따라 '가까운 이웃의 수' (Hyper parameter)가 결정
-분류와 회귀에 모두 사용 가능
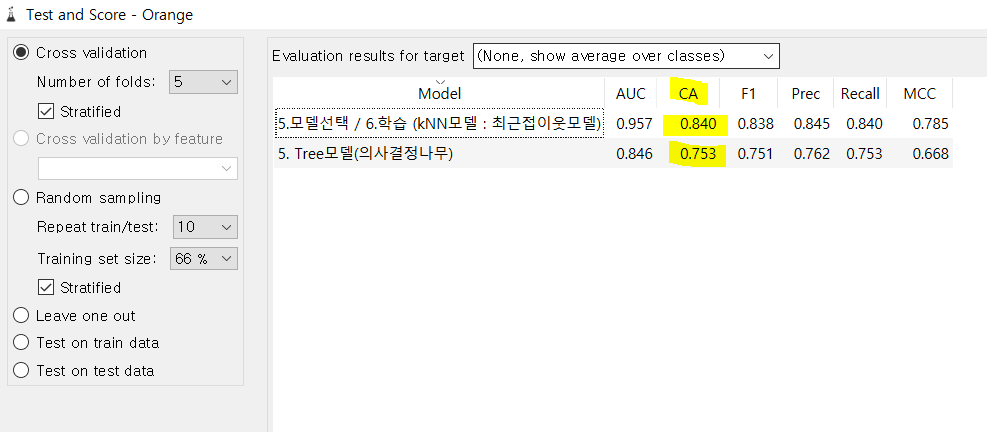
※accuracy(정확도)
: 0~1
->전체 test데이터 정답을 맞힌 비율
->1에 가까울수록 정확하다(0.9 이상이어야 정확도가 높다고 말함)
->CA(Classification Accuracy) 범주형 데이터일 때 확인하면 됩니다 !