1. 인공지능 vs 머신러닝 vs 딥러닝
- 인공지능 : 사람의 모든 것을 흉내내는 기술
- 머신러닝 : 사람이 학습하는 방식을 기계에게 적용하는 기술 -> 다양한 학습 방식이 있다
- 딥러닝 : 머신러닝의 하위분야로 사람의 뇌(신경망)를 모방하여 학습하는 방식의 기술 -> 최근 보여주는 다양한 결과물의 근본이 된다
2. ML이란?
- Data를 Model에게 넣어서 스스로 학습하게 하는 방법
- 장점 : 사람이 관여하는 부분이 적다 -> 자동화가 가능
- 단점 : 기계가 어떤 방식으로 학습/예측 하는지 파악하기 어렵다 -> 평가가 중요하다
3. 인공지능 활용 프로세스
- 문제정의
- 관련 학습 데이터 수집
- 데이터 전처리
- 데이터 탐색(EDA)
- 학습모델 선택 및 하이퍼파라미터 튜닝
- 모델 평가
- 서비스화

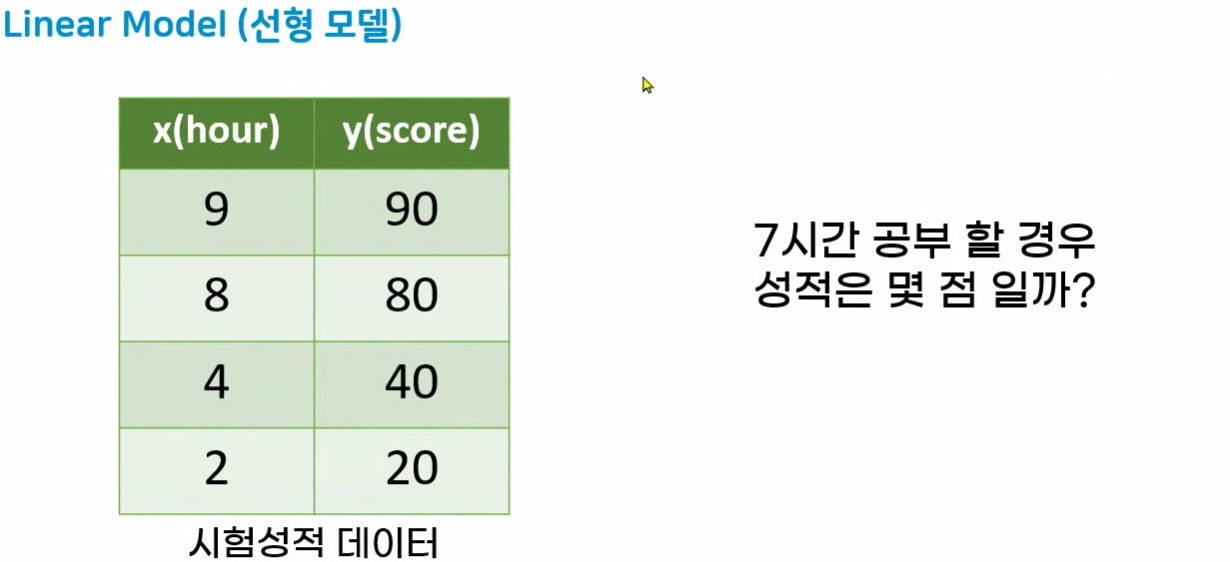
- 입력특성 1개 : x(hour)
- 정답특성 1개 : y(score)
- 데이터 샘플 4개
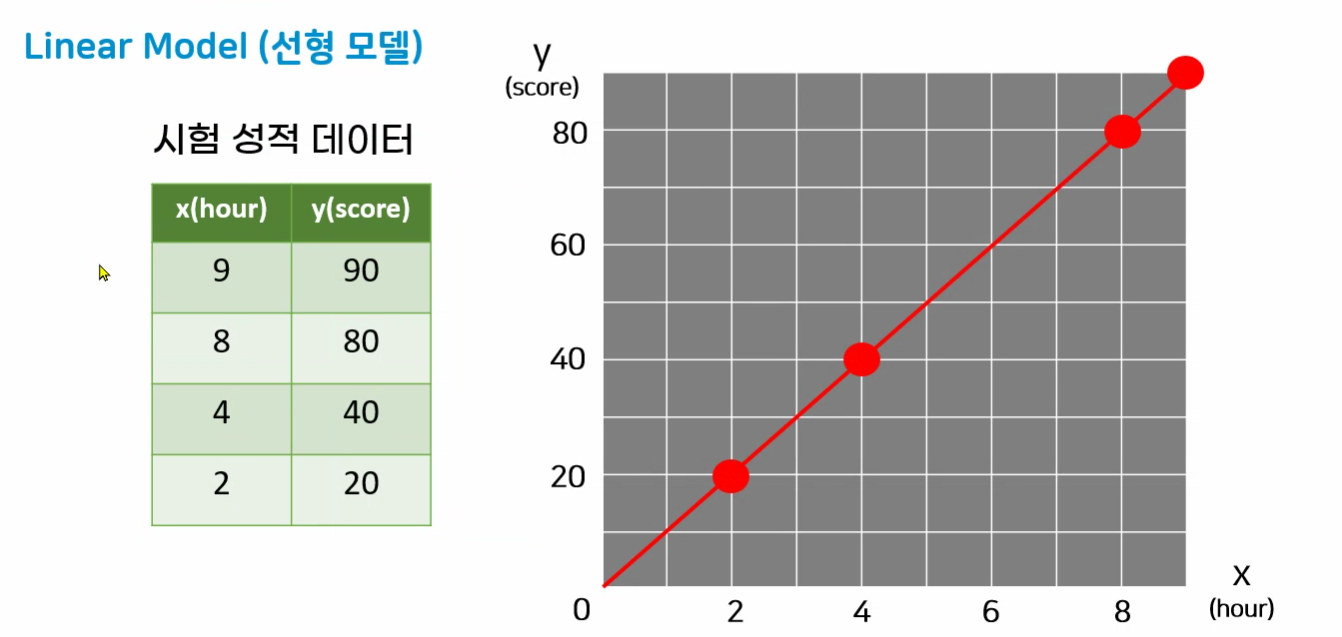
y = 10x+0
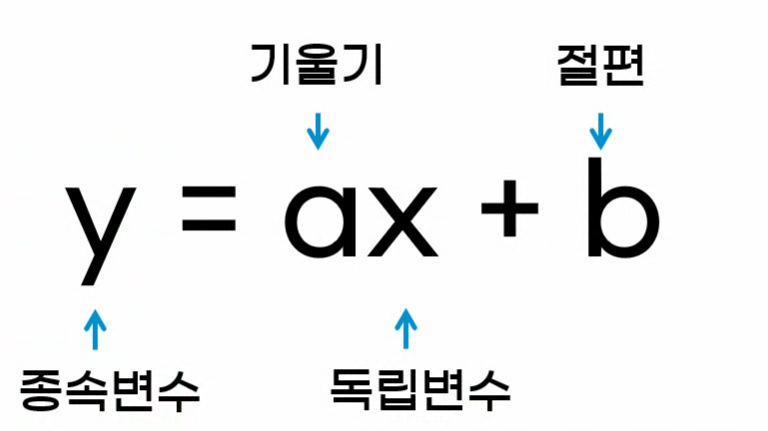
종속변수 = 예측값
독립변수 = 입력특성
기울기 = 가중치(weight)
-> y=wx+b라고 표현 많이 한다

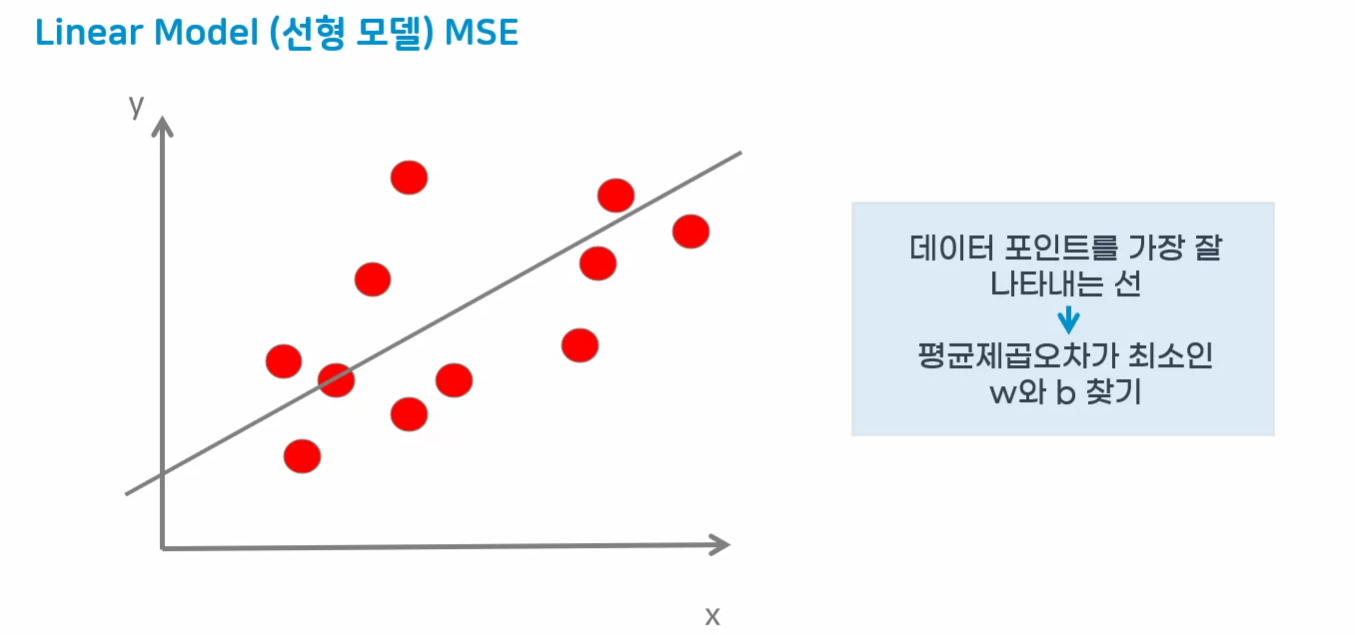
선형회귀 모델
- 입력특성에 대한 선형함수를 만들어 예측을 수행하는 모델
- 단순선형회귀 공식 : y = wx + b
- 다중선형회귀 공식 : y = w1x1 + w2x2 + b
import pandas as pd
sample_data = pd.DataFrame([[9,90],[8,80],[4,40],[2,20]],
columns=['공부시간','성적'],
index=['해도','영화','자연','병관'])
sample_data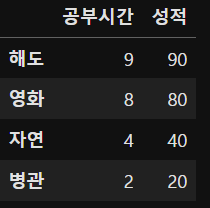
# 입력특성(문제)
x = sample_data['공부시간']
# 정답
y = sample_data['성적']모델링을 위한 sklearn 패키지 활용
- 머신러닝 학습을 위한 모델, 평가지표, 학습용 데이터셋 등을 가지고 있는 파이썬 패키지
# 전통적인 선형회귀 모델을 구현한 클래스
from sklearn.linear_model import LinearRegression모델링 순서
1. 모델객체 생성
2. 문제/정답 학습
3. 모델평가
4. 모델예측
score_model = LinearRegression() # 선현회귀모델 객체 생성# 문제와 정답 입력
score_model.fit(X.values.reshape(-1,1), # 1차원 데이터를 2차원으로 변경 # -1 넣으면 자동으로 최적화해서 계산해줌
y) score_model.predict([[7],[5]]) # 에측하고 싶은 입력데이터만 작성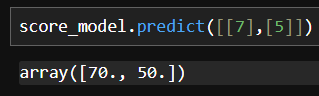
# 학습된 가중치와 절편 확인
print("가중치 : ", score_model.coef_)
print("절편 : ", score_model.intercept_)-> 실제 절편 -0.000000000000071054..
-> y = 10x + 0
다중선형회귀
sample_data['게임시간'] = [2, 5, 8, 15]
sample_data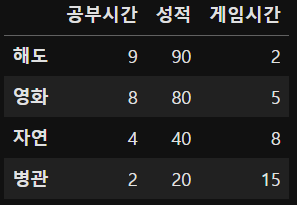
# 입력특성(문제)
X = sample_data[['공부시간','게임시간']]
# 정답
y = sample_data['성적']X 출력
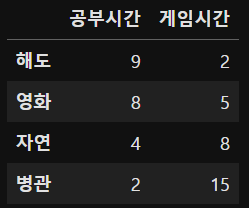
# 모델생성
score_model2 = LinearRegression()
# 모델학습
score_model2.fit(X, y) # 모델예측
score_model2.predict([[10,2],[3,5]]) print("가중치 : ", score_model2.coef_)
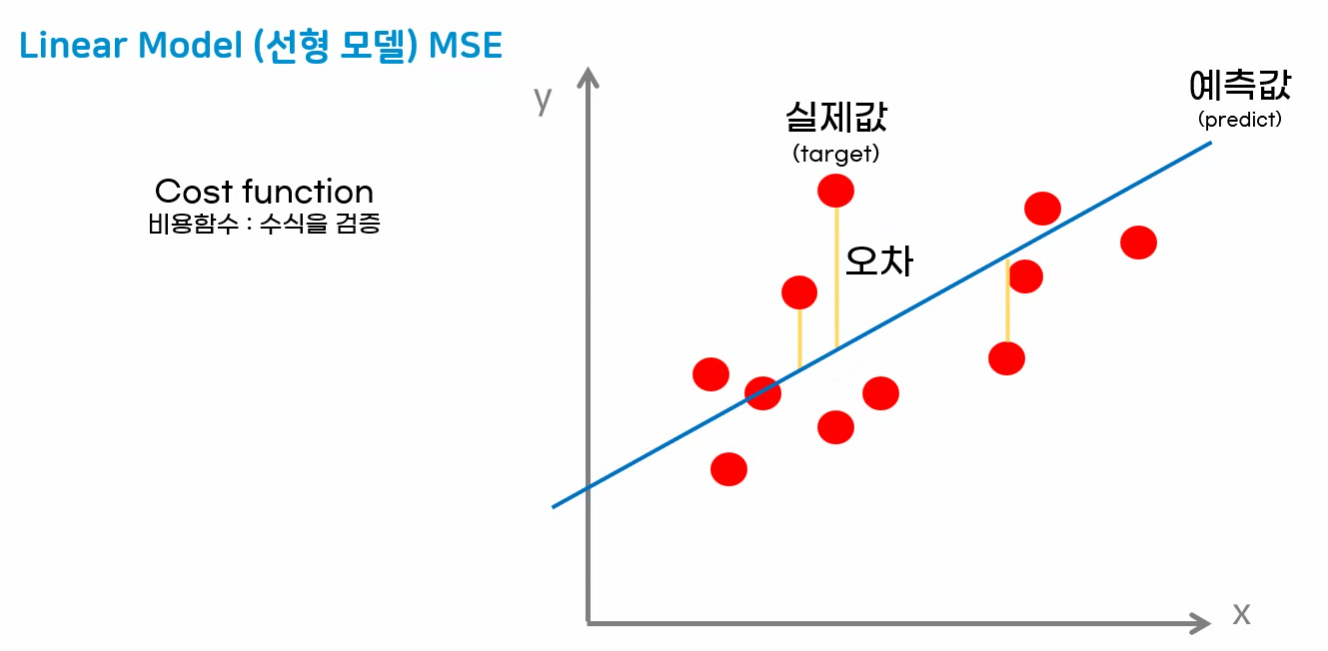
print("절편 : ", score_model2.intercept_)평균제곱오차 구현하기(Mean Squared Error)
- 선형회귀 모델이 학습하는 과정 또는 결과에 대해서 잘못되었는지 잘되었는지 파악하는 지표로 사용하는 알고리즘
- MSE같은 알고리즘을 비용함수(Cost Function)이라고 부른다
- 생성모델, 자연어처리 모델 등 각 모델에 맞는 비용함수가 구성되어 있다.
MSE(Mean Squared Error)
1. 양수와 음수 오차 상쇄 방지
2. 오차 확대해석하여 모델 안정성 확보, 오차 큰 모델에게 패널티 줄 근거

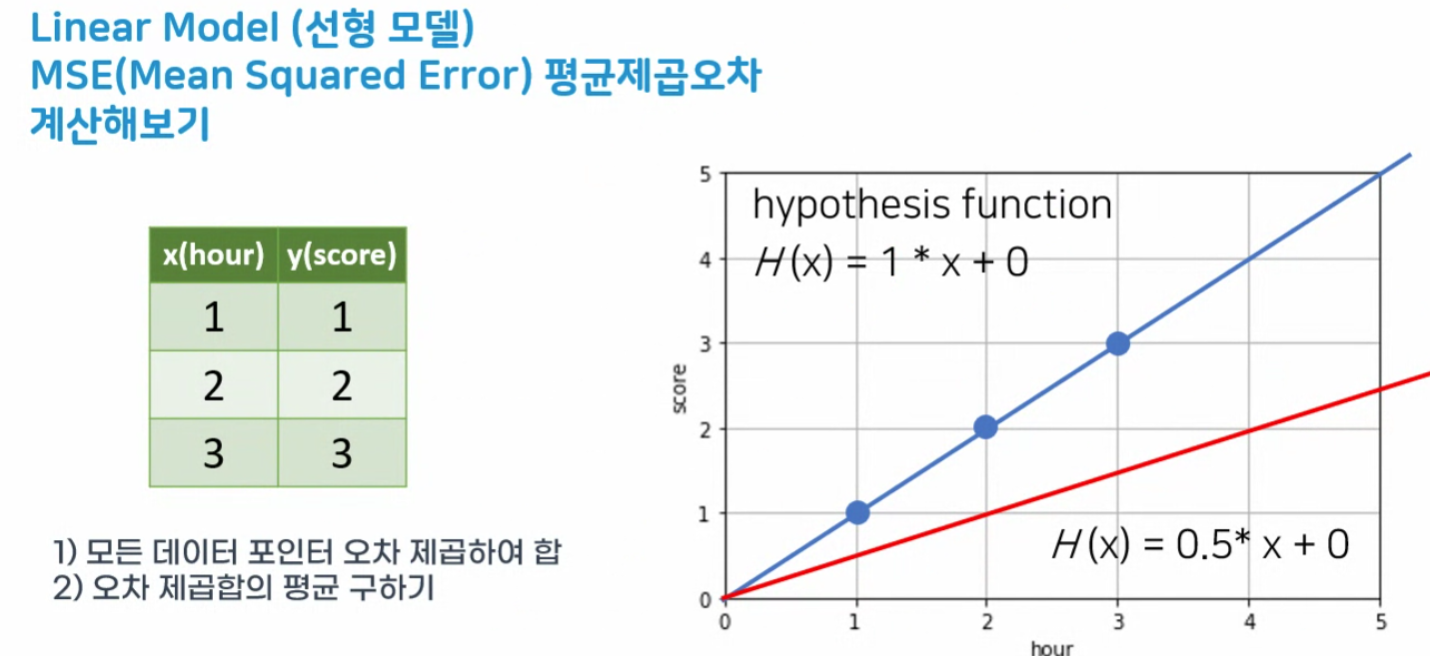
[실습] MSE 구하기
1) Blue
H(x) = 1x+0
cost = 0
2) Red
H(x) = 0.5x+0
cost = (0.25+1+2.25)/ 3
= 1.166666666666667
# 선형회귀 가설함수 만들기
def H(X, w):
'''
X : 가설함수로 입력되는 데이터(문제)
w : 가설함수에서 지정하는 가중치
return 값 : 입력데이터와 가중치의 곱셈 값
'''
return X*w y_pre = H(sample_data['공부시간'], 1)
y_pre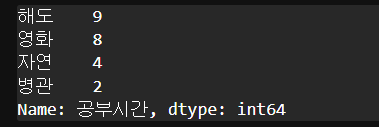
# 평균제곱 오차함수 만들기
def MSE(X,y,w):
'''
X : MSE 오차를 계산하기 위한 입력데이터(문제)
y : 실제정답 값
w : 가설함수에 적용한 가중치 값
'''
# 예측값
y_pre = H(X,w)
# 오차 구하기
error = y_pre - y
# 제곱오차
squared_error = error**2
# 평균값 반환
return squared_error.mean() MSE(sample_data['공부시간'], sample_data['성적'], 10)

평균제곱오차 그래프 그려보기
- 최적의 가중치를 가지면 MSE는 최솟값을 지닌다.
- 최적의 가중치를 벗어나기 시작하면 MSE는 제곱의 효과로 급격히 증가한다.
# 최적의 가중치 10을 중심으로 양쪽에 10개씩 가중치 생성
w_list = range(0,21) cost_list = [MSE(sample_data['공부시간'], sample_data['성적'], w) for w in w_list]
cost_list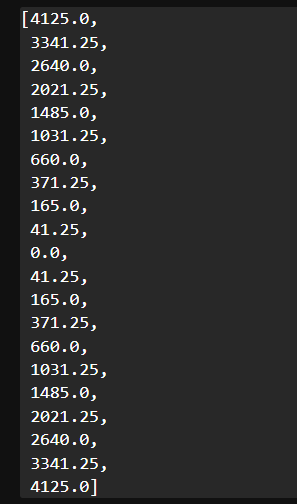
import matplotlib.pyplot as pltplt.figure(figsize=(5,5)) # 그림 사이즈 설정
plt.plot(range(0,21), # x축 데이터
cost_list, # y축 데이터
marker='^') # 라인 그래프 마커 표시
plt.xlabel('weight')
plt.ylabel('cost')
plt.show()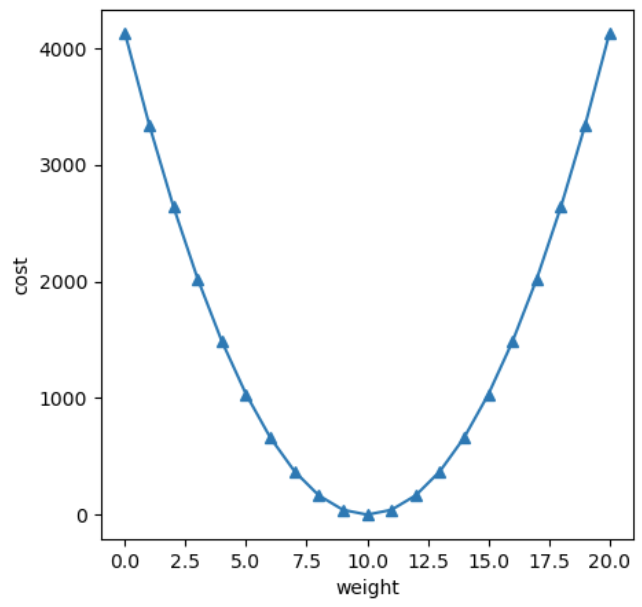

Hello, World!