개인스터디
실습으로 익히는 Python 5,6회차
결측치 (missing value)
- 데이터 수집 과정에서 누락된 값
식별
df.isnull().sum()처리
- 제거
결측치가 있는 행/열 삭제
df.dropna()
# 같은표현
df.dropna(axis = 0, how = 'any')
# 결측치가 있는 열 제거
df.dropna(axis=1)
# 결측치 제거 후 결과 저장
df.dropna(inplace = True)
# 결측치 제거 체크
df.isnull().sum() # 0으로 나와야 함 - 대체
- 수치형 데이터 : 평균값, 중앙값
- 범주형 데이터 : 최빈값
- 다른 값 참고해서 채우기
method = ffill/bfill
df['컬럼명'].fillna('대체할값')
# 평균값
df['컬럼명'].fillna(df['컬럼명'].mean)
# 중앙값
df['컬럼명'].fillna(df['컬럼명'].median)
# 바로 위 값으로 대체
df['컬럼명'].fillna(method = 'ffill')
# 바로 아래 값으로 대체
df['컬럼명'].fillna(method = 'bfill')
이상치 (outlier)
- 데이터 범위를 벗어난 너무 크거나 작은 값
식별
-
정규분포 기반(Z-Score)
- 평균과 표준편차로 판단
StandardScaler().fit_transform()활용- ±3 이상이면 이상치
-
비정규분포 기반(IQR)
- 사분위수 이용
Q1 - 1.5*IQR,Q3 + 1.5*IQR바깥 값 제거
-
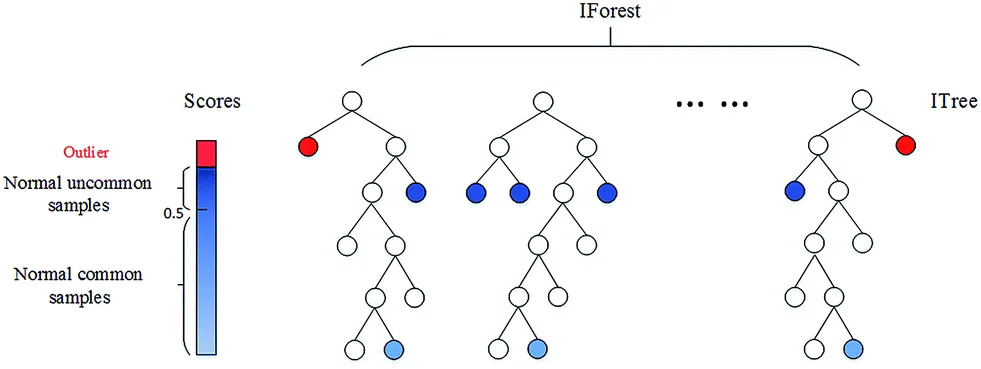
머신러닝 기반
- Isolation Forest
- 데이터셋을 결정트리 형태로 표현
- 데이터까지의 경로길이를 기준으로 판단
- 다른 관측치에 비해 짧은 경로 길이를 가진 경우
(1에 가까울 수록 이상치)
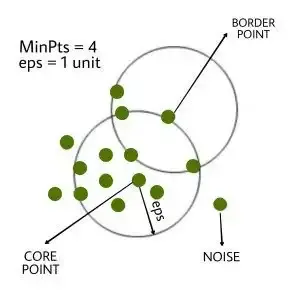
- DB SCAN
- 밀도 기반의 클러스터링 알고리즘
- 어떤 클러스터에도 포함되지 않는 데이터를 이상치로 판단
- Isolation Forest
처리
-
제거
데이터 오류나 적절하지 않은 값일 경우 제거
⚠️데이터 표본 크기 줄어들 수 있음 -
대체
- 로그 변환 > 극단값 완화
- 하한/상한 설정 : 하한값보다 적으면 하한값으로, 상한값보다 크면 상한값으로 대체
-
분리
새로운 데이터 프레임 생성하여 이상치 저장 > 별도 분석
Python 라이브러리 개인과제
🔗 참고자료
실습으로 익히는 Python 1,2회차
실습으로 익히는 Python 3,4회차
데이터 전처리&시각화 3주차
pandas 10분 완성
필수 1) 데이터 불러오기
1-1. 라이브러리 import
import pandas as pd
import numpy as np
import time
import datetime as dt 1-2. csv 파일 불러오기
나는 구글드라이브를 사용하지 않는 관계로 드라이브 마운트 코드는 주석처리로 달았다.
#from google.colab import drive
#drive.mount('/content/drive')
df = pd.read_csv(r"경로는비밀/flight_data_homework.csv") 1-3. 행과 열 개수 확인
df.shape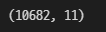
1-4. 테이블의 처음 5줄 확인
df.head()
필수 2) 결측치 처리
2-1. 각 컬럼별 결측치 개수 구하기
df.isnull().sum()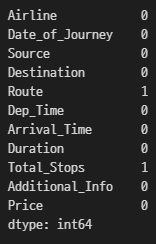
2-2. 결측치가 있는 행 모두 제거
df = df.dropna()
#결측치 제거 확인
df.isnull().sum()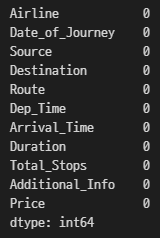
필수 3) 조건에 맞는 데이터 추출하기
3-1. Destination 컬럼 기준 price의 평균값과 중앙값 동시에 구하기
(소수점 첫번째 자리까지 표현)
이건 두 가지로 구했음
- 전처리 강의자료 기준
df[['Price', 'Destination']].groupby('Destination').agg(['mean','median']).round(1)- 세션 강의자료 기준
df.groupby('Destination')[['Price']].agg(['mean', 'median']).round(1)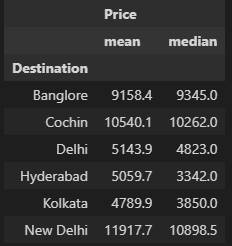
처음에는 그냥 ['Price']로 작성했었는데 Price컬럼이 전처리 강의자료 기준처럼 노출이 되지 않아서 동진님한테 여쭤보니까 대괄호를 씌워보라고 하셔서 그렇게 쓰니까 완전히 똑같아졌다
결과값은 같지만, 혹 차이가 있는걸까?😅
3-2. Airline, Total_Stops 기준 Route 컬럼을 중복값 없이 추출, 인덱스 재정렬
(df2 라는 dataframe으로 받기)
이것도 문제가 조금 헷갈렸다 구글링해보니 중복값 없이 추출하는 방법이 여러가지라서.. 일단 둘 다 제출했음
drop_duplicates()사용
df2 = df[['Airline', 'Total_Stops', 'Route']].drop_duplicates().reset_index(drop=True)
# 확인용 코드
df2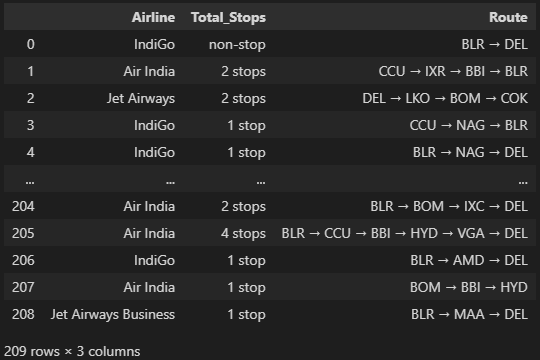
unique()사용
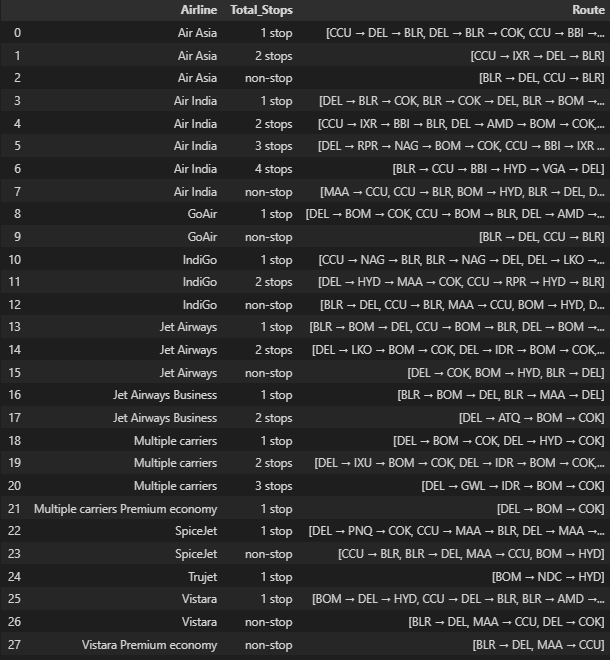
리스트로 모아서? 반환되는 것 같아서 구글링
explode()를 쓰면 리스트를 풀어서 행으로 전개해준다고함
🔗 리스트 형태의 값 전개
unique().explode() 사용
df2 = df.groupby(['Airline', 'Total_Stops'])['Route'].unique().explode().reset_index()
# 확인용 코드
df2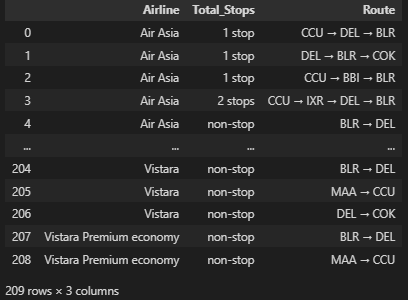
총 개수를 보면 두개가 같은 값인 것 같다
이것도 뭔 차인지 궁금해짐
필수 4) 조건에 맞는 데이터 추출하기2
4-1. 피벗테이블 구현
조건
- 출발지와 도착지 기준으로 한 Airline 카운트
- 카운트 값 기준으로 내림차순 정렬
pivot_table = df.pivot_table(index = ['Source', 'Destination'], values = 'Airline', aggfunc = 'count').sort_values(by = 'Airline', ascending = False)
# 확인용 코드
pivot_table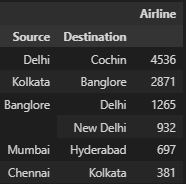
4-2. Airline 컬럼이 Air India, Price 7000 이상 데이터 필터링
filtering = df[(df['Airline'] == 'Air India') & (df['Price'] >= 7000)]
# 확인용 코드
filtering.tail()
도전 1) 조건에 맞는 데이터 추출하기3
힌트를 보고 따라감!
5-1. datetime_format 사용
# object > datetime 변환
df['Date_of_Journey'] = pd.to_datetime(df['Date_of_Journey'])
# 확인
df.info()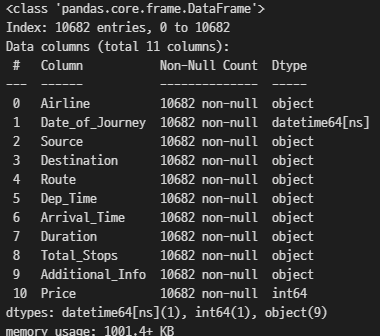
5-2. date_of_journey 기준 수요일에 예약된 경우 평균 가격 구하기
# 힌트2 참고 / dt.day_name() 사용
# 요일이름으로 컬럼 생성
df['day_name'] = df['Date_of_Journey'].dt.day_name()
# 수요일 평균가격 계산
avg_wed_price = df.loc[df['day_name'] == 'Wednesday'][['Price']].agg('mean')
# 출력
print(avg_wed_price)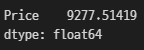
도전 2) 조건에 맞는 데이터 추출하기4
이 문제도 힌트 보고 따라갔다!
모르는 부분은 계속 구글링해야 했음..
6-1. datetime_format 사용 + 시간만 추출
df['Dep_Time'] = pd.to_datetime(df['Dep_Time'], format= '%H:%M').dt.hour
df.info()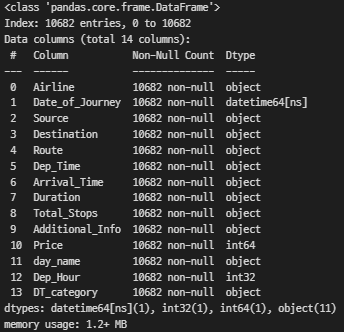
여기서 조금 멘붕이 왔는데..?
to_datetime을 써서 datetime으로 형변환 한 후 dt.hour로 시간만 추출한 것인데
1. Dep_Time은 왜 object일까?
2. Dep_Hour은 왜 int형일까?
Q&A에 물어봐놓긴 했는데 추후 해설때 다시 확인해봐야 할듯!
6-2. lambda 사용 > 카테고리 나누기
조건정리
- 카테고리
- 아침 : 5시 이상 12시 미만
- 낮 : 12시 이상 18시 미만
- 오후 : 18시 이상 24시 미만
- 밤 : 24시 이상 5시 미만 (위 세가지가 아닌것)
- inline if 절 사용
lambda 함수 적용을 어떻게 해야 하나 싶어서 또 구글링
🔗apply 알아보기
🔗value_counts 알아보기
# 카테고리 나누고 lambda 적용
df['DT_category'] = df['Dep_Time'].apply(lambda x: '아침' if 5 <= x < 12
else '낮' if 12 <= x < 18
else '오후' if 18 <= x < 24
else '밤')
# 카테고리별로 카운트
df['DT_category'].value_counts()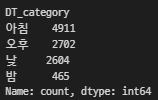
데일리퀘스트
SQL - 조건에 맞는 사용자 정보 조회하기
SQL - 특정 옵션이 포함된 자동차 리스트 구하기
Python - 수박수박수박수박수박수?
Python - 내적
일기
- SQL
코드카타 55-56✅ - Python
코드카타 31-32✅ - Pandas
개인과제 1-6✅라이브세션 5,6회차 복습+정리✅
오늘은 판다스 과제 + 라이브세션 복습했다
어제 너무 늦게 자서 진짜 하루종일 졸리고 정신 붙잡기 너무 힘들었다😅 전처리 시각화 강의도 4주차 들었어야 하는데 미룸
팀원분들이랑 남아서 과제 푼 거 확인하느라 10시에 끝났는데 역시 다른 사람들 풀이 보는 게 큰 도움이 되는 것 같음 rrule 쓰는 방법 알았다
내일은 아침에 실업인정 출석하고 발제도 들어야하고 과제해설도 들어야하고 바쁘다바빠 현대사회 그래서 내일도 강의 들을 수 있을지 모르겠지만 노쉬벨킵고잉..🍀


파이티이잉🍀