팀스터디
1차회의
-
역할분담
- 발표 : 남동진님
- 영상 : 양현유님
- PPT 초안 : 김수희님, 허다솜님
- PPT : 김동현님 (미리캔버스 사용)
-
코드작성은 파트 나눠서 하기
- 어떤 분석이 나올 수 있을지 논의 후 결정!
개인 의견
- 티어별 게임 진행 방식 차이
- 플레이소요시간이 얼마나 차이나는지
- 레벨은 어디까지 올리는지
- 몇 라운드까지 가는지
- 챔피언 성능 분석
- cost <> 성능(체력, 공격범위 등) 비교분석
- 강한 챔피언, 약한 챔피언 > 밸런스 조정 가능성?
- 시너지(origin)별 성능 비교 > 어떤 시너지가 제일 좋은지
- class 별 강한 챔피언 > 어떤 클래스가 좋은지
- 조합 찾기
- (아이템 + 챔피언 ) > 승리와 상관관계가 있는지
- 메타 분석 (티어별 인기메타) > 밸런스 조정
- 과제에서 요청한 필수사항
- 테이블 열 행 개수 표현
- 테이블 컬럼타입, 통계량
- 테이블 결합
- 결측치 처리 (대체or제거)
- 집계함수를 사용해 비교분석 > 시각화
- 최소 1개의 인사이트
결론
방향성
- 방향성을 정하고 시작하자는 팀원의 의견이 있었음
- 유저수를 늘리기 위해?
- 수익성을 늘리기 위해?
- 다음 시즌을 어떻게 준비해야 하는지?
- 유저 체류 시간을 늘리기 위해?
나는 분석을 하는 최종적인 목적은 수익성이고, 그러려면 유저수를 늘려야하며, 유저수를 늘리려면 유저 체류시간이 길어져야하고, 또 그러려면 다음 시즌을 준비를 잘 해둬야(ex. 밸런스를 맞추고, 시너지를 변경하는 등) 그것이 가능하다 생각해서 이 중에서 한 방향으로 정하자는 게 어떤 의미가 있는 건지 의문이 들었음
효율성 측면에서 우리가 가지고 있는 데이터셋에서 어떤 데이터를 뽑아낼 수 있을지 생각해보고, 분석된 걸 바탕으로 인사이트를 뽑아내야하는 게 아닌가? 라는 생각이 들었기 때문
여차저차 이 과정이 엄청 오래걸렸는데, 사실은 다 연결되는 같은 의견을 낸 거고, 단순히 의사결정 방식의 차이가 존재할 뿐이었다!
조원분이 큰 갈래에서부터 시작해보자고 해서 로직트리 형식으로 브레인스토밍을 해보기로 했음
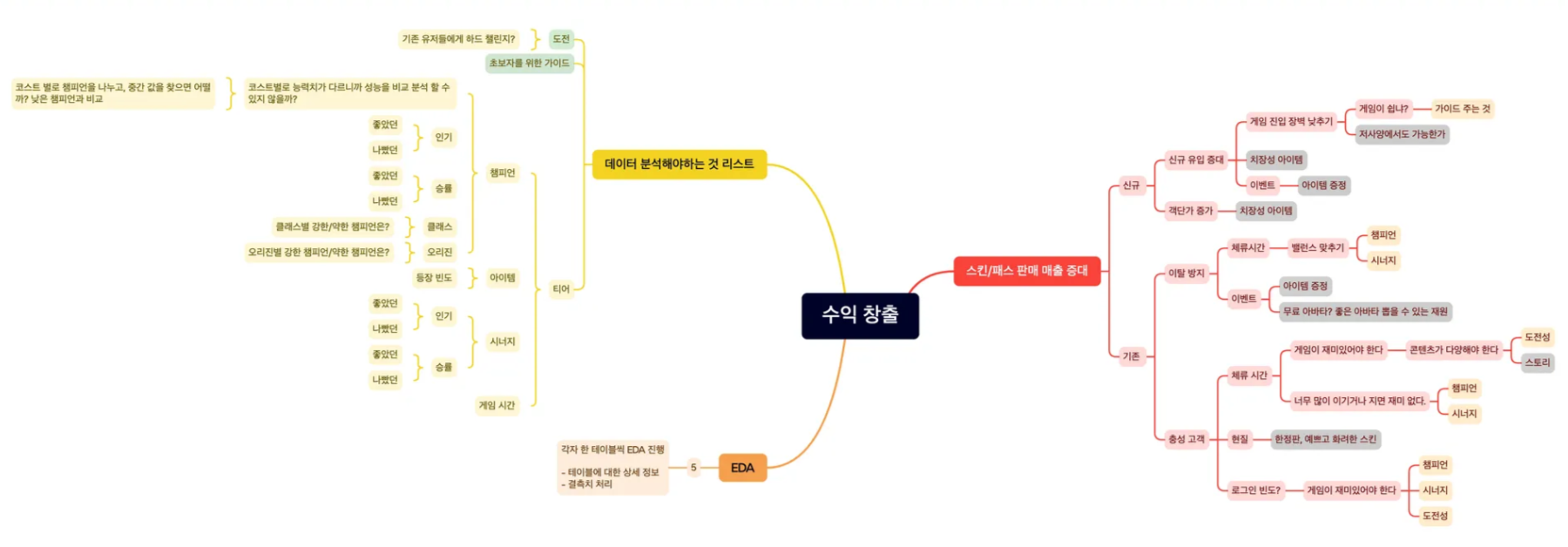
갈래들을 다 적어보고, 우리가 현재 가지고 있는 데이터셋에서 분석할 수 없는 것은 뺌
코드작성 역할분담
- 각자 테이블 하나씩 맡아서, EDA를 먼저 진행하기로 결정 땅땅🔥
- 내가 맡은 테이블은
TFT_Master_MatchData.csv
- 내가 맡은 테이블은
EDA 진행
일단 필요한 라이브러리 불러오기
행, 열 파악
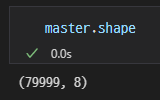
결측치 확인
0이어서 결측치는 없는 것으로 확인이 됨
이상치 확인
나는 일단 이상치 탐지 방법에서 IQR과 Z-Score 활용하는 게 떠올라서 가능한 데이터가 뭐가 있을지 생각해보다가,
비정상적으로 길거나 짧은 게임 시간을 찾아보기로 했음
코드는 다 기억하진 못해서 기본적으로 강의자료를 참고하면서 써내려갔다
*여기서 standardScalar를 쓸려면 scikit-learn이 필요해서 추가로 설치함
-
game duration 이상치 z-score
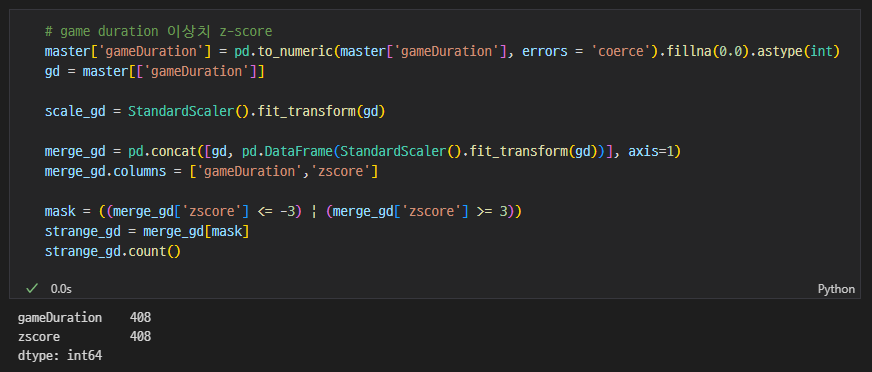
-
ingame duration 이상치 z-score
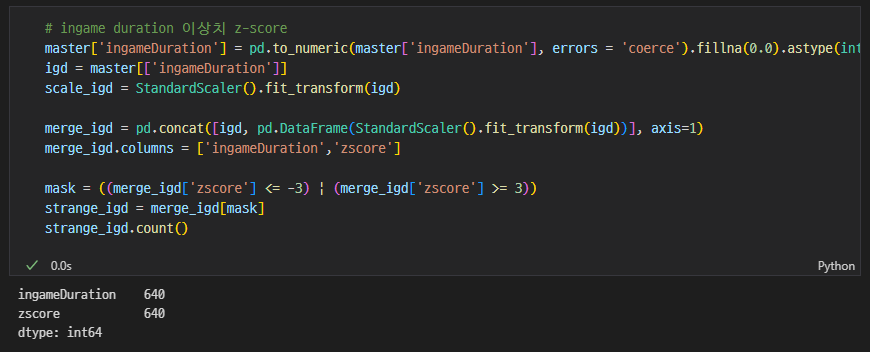
-
z-score 바탕으로 clean data와 outlier data 뽑기
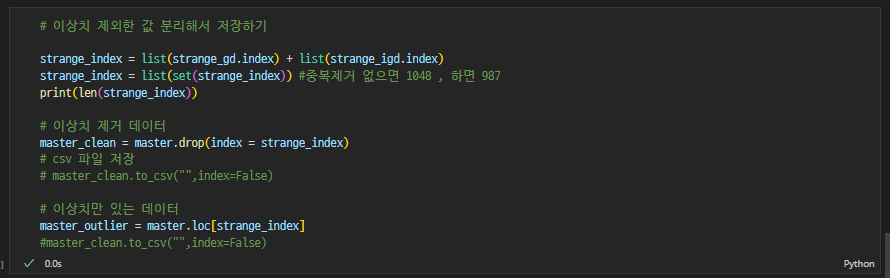
-
잘 뽑혔는지 확인
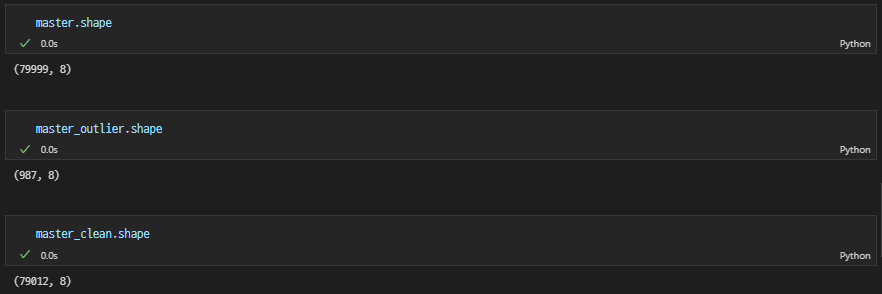
-
game duration 이상치 IQR
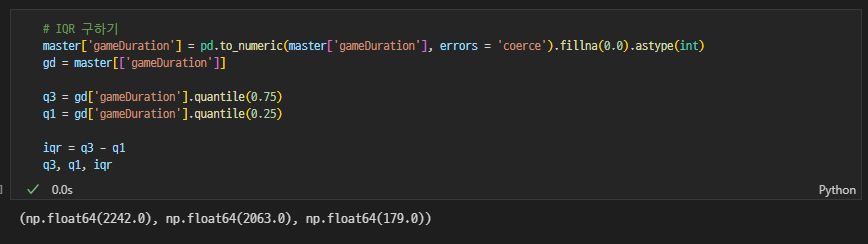
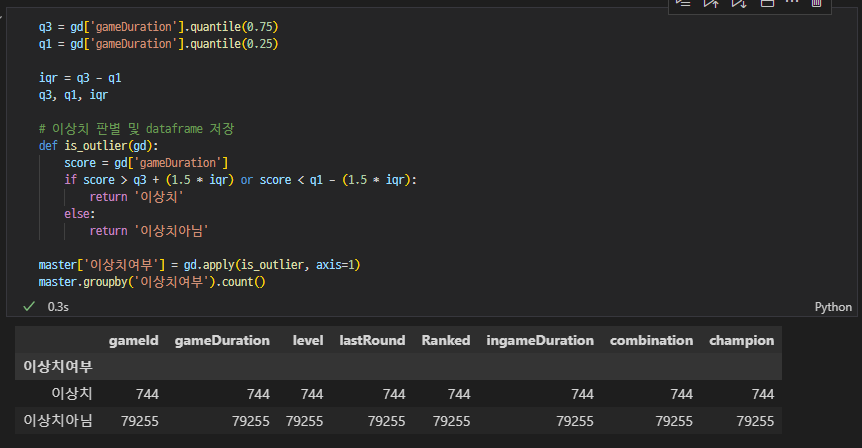
z-score로 구한 이상치랑 약 300개정도 차이가 나서, 조원들끼리 그럼 z-score만 활용해보자고 의견이 나옴
그렇게 하기로 했다 탕탕 코드 주석으로 보내버림!🗑️
- combination 컬럼 이상치
'set2_XXX', 'set3_XXX'와 같은 값들이 combination에 포함이 되어있다는 조원의 제보
시즌이 아닐지, 효과 발동 마릿수가 아닐지 등 다양한 의견이 나와서 이걸 제해야하는지 말아야하는지 다 같이 고민하던 중
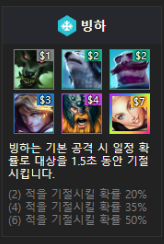
검색해보니 시즌2에 해당하는 데이터였다 혹시 몰라서 튜터님한테도 물어보려고 했는데 안 계셔서 팀장님이 질문방에 글 올리셔서 확답을 받음.
아무튼 그래서 set2라고 적혀있는 건 제해야하는데.. 이걸 어떻게 할거냐가 문제였음
dict 형식처럼 보이길래 key값만 가지고 오면 되는 게 아닌가 싶었는데 dict형으로 보이지만 str이었다 🤢
key값만 가지고오려면 dict형식으로 바꾸는 게 나을 것 같아서 열심히 구글링함
🔗 문자열 dict{}를 딕셔너리 type으로 만들기
쓰려면 또 ast라는 라이브러리를 설치해야해서 설치완하고 돌렸더니 dict로 변환이 되었다!
여러개 컬럼을 한꺼번에 apply 하고싶었는데 이건 안 되더라 따로따로 함
-
ast.literal_eval 사용
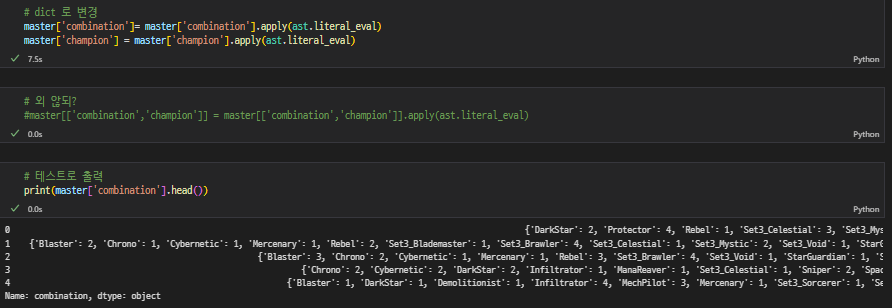
-
형 변환된 거 확인하고, key값만 불러오기
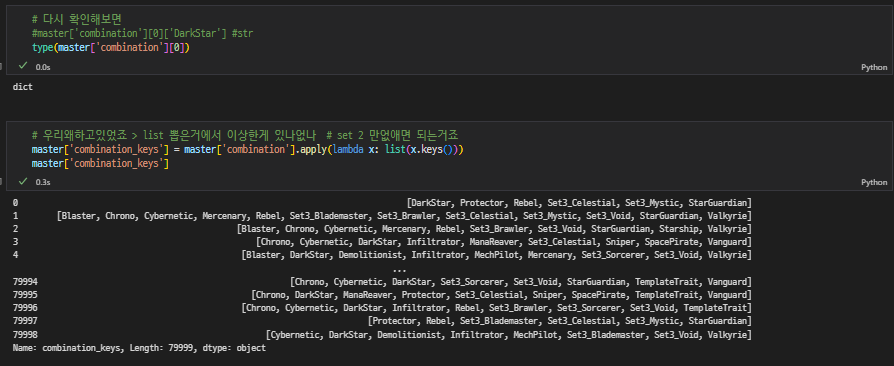
여기까지는 진행이 되었는데.. 궁금한 것은 'set2_XXX'라는 형식이다보니 SQL의 like 기능같은 기능이 있는지 모르겠어서 어렵다 내가 찾아본 자료들은 다 일치해야만 제거하는 방식이라서 어떻게 진행해야할지 도저히 모르겠음
일단 요기까지하고 다시 회의시작
2차회의
정규 수업시간이 끝나고, 각자 어디까지 진행했는지 그리고 어떤 걸 더 확인해야할지 남은 사람들끼리 얘기해보는 시간을 가졌다. 이것도 꽤나 오랜시간 토론했고 동진님이 큰 방향을 잡아주심
결론
- 컬럼별 이상치 목록
- gameDuration : 너무 짧거나, 오래 걸린 게임
- gameDuration < ingameDuration 인 경우
- ingameDuration : 상동
- lastRound : 상동
- level : 1~9레벨 밖
- ranked : 1~8 밖
- champion
- 챔피언 이름이 챔피언 테이블에 없을때
- 아이템 번호가 아이템 테이블에 없을때
- 별 레벨이 1~3을 벗어났을때
- gameDuration : 너무 짧거나, 오래 걸린 게임
각각 담당 컬럼을 두되(시간이 모자라니까) 가능한 모든 컬럼에 대해 EDA를 하기로 했다!
나는 오늘 z-score를 짰으므로 똑같이 담당하기로 함
근데 여기서 또 파생되는 의문😵💫
1. 전체 티어별 매치리스트를 합치고 z-score를 구하냐 vs 티어별로 z-score를 구하고 이상치를 제한 후 합칠거냐
-> 이건 표본이 많으면 많을수록 분포가 다양해지니 합쳐서 구하기로 함
- combination에서 set2가 있는 데이터를 행으로 다 날리냐 vs 그 데이터 하나만 날리냐
-> 이건 뭔가 어려운 문제인 것 같은데
set2라는 데이터가 껴있는 상태라면 나머지 데이터에 대한 신뢰를 가질 수 있냐 없냐로 나뉘어서 어려웠음
이건 추가로 생각해봐야 할 것 같다
아무튼 오늘은 여기까지! EDA는 주말에도 가능하면 해야할 것 같다 월요일까지 각자 결과를 내서 가지고 오기로 함
흑흑 파이팅해보자
개인스터디
실습으로 익히는 Python 7회차
시각화
- 숫자로만 보면 뭔지 모름 > 이해할 수 있도록 표나 차트로 정리
- '도구'가 아닌 '전략'
라이브러리
matplotlib seaborn altair PyGwalker plotpy
기본 그래프
- 데이터를 불러오자마자 시각화 가능!
df2.groupby('Gender')['Customer ID'].count().plot.bar()
- 색상 넣기
df2.groupby('Gender')['Customer ID'].count().plot.bar(color = ['yellow','purple']
예쁜 그래프
matplotlib
- 설치
pip install matplotlib - 제일 많이 쓰는 그래프 라이브러리
plt.title('그래프 제목', fontsize=20) # 그래프 제목 넣기
plt.xlabel('X축', fontsize=20) # X축 이름 넣기
plt.ylabel('Y축', fontsize=20) # Y축 이름 넣기
plt.xticks(rotation=90) # X축 글씨 회전
plt.yticks(rotation=30) # Y축 글씨 회전
plt.grid() # 격자선 추가
plt.legend(['Mouse', 'Cat']) # 범례 추가
plt.bar(x, y, color='blue') # 막대 그래프 색상 변경
plt.xlim(2, 3) # X축 범위 설정
plt.ylim(5, 20) # Y축 범위 설정
seaborn
- 설치
pip install seaborn matplotlib보다 더 예쁜 스타일의 그래프
인터랙티브 그래프
Altair
- 설치
pip install altair - 동적인 그래프 만들때
- 아직 호환성이 떨어짐(신상)
- 문법 쉬움
import altair as alt
chart = alt.Chart(df2).mark_bar().encode(
x='Gender',
y='count()'
).interactive() # 인터랙티브 기능 추가
chart
PyGWalker
- 설치
pip install pygwalker - 드래그 앤 드랍으로 그래프 생성
- 바로 PNG 저장 가능
import pygwalker as pyg
pyg.walk(df2) # 드래그 앤 드랍으로 그래프 만들기matplotlib 예제
예제가 너무 많아서 오늘은 matplotlib만!
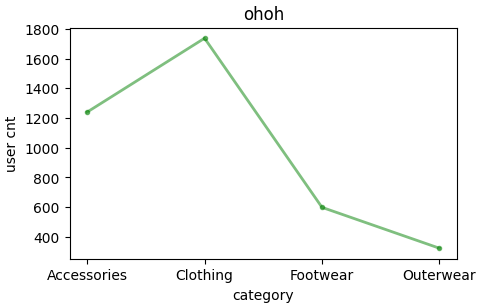
예제1 - 선그래프
df2.columns
# 카테고리별 유저수 구하기
# 인덱스 재정렬을 안 해주면 오류남!
# 내가 계산한 걸 인식을 못함 > groupby, pivot할때 reset_index 필수
d1 = df2.groupby('Category')['Customer ID'].count().reset_index()
d1
dplot1 = plt.figure(figsize = (5 , 3))
x=d1['Category']
y=d1['Customer ID']
plt.plot(x, y, color='green', marker='.', alpha=0.5, linewidth=2) #안에 거 다 바꿀 수 있음!
plt.title("ohoh")
plt.xlabel("category")
plt.ylabel("user cnt")
sns.countplot(x='Gender', data=df2) # 범주형 데이터 개수 세기 (Group by 필요 없음)
sns.boxplot(x='Gender', y='Age', data=df2) # 박스플롯 (이상치 확인용)
sns.heatmap(df2.corr(), annot=True, cmap='coolwarm') # 상관관계 히트맵
예제2 - 막대그래프
# 카테고리, 성별 유저수 구하기
#stack 은 pivot 테이블과 비슷하게, 데이터프레임을 핸들링하는 데 주로 사용됩니다.
#반대로 인덱스를 컬럼으로 풀어주는 unstack 이 있습니다.
d2 = df2.groupby(['Category','Gender'])['Customer ID'].count().unstack(1)# 성별이 컬럼으로
d2
dplot8 = d2.plot(kind='bar',color=['#20B2AA','#DB7093'])
plt.title("bar plot1")
plt.xlabel("category")
plt.ylabel("usercnt")
# 기본 그래프와 다른 점은 범례를 볼 수 있다는 것
# hexcode로 색상 지정 가능 
예제3 - 누적 막대그래프
# 카테고리, 성별 유저수 구하기
#stacked=True 로 설정하면 누적그래프를 그릴 수 있습니다.
dplot9 = d2.plot(kind='bar', stacked=True, color=['#F4D13B','#9b59b6'])
plt.title("bar plot2")
plt.xlabel("category")
plt.ylabel("usercnt")
예제 4 - 파이차트
dplot7= plt.figure(figsize=(3,3))
plt.pie(
x=piedf['Customer ID'],
labels=piedf['Gender'],
# 소수점 첫째자리까지 표시
autopct='%1.1f',
colors=['#F4D13B','#9b59b6'],
startangle=90, #기본 각도는 90도
)
plt.title("pie plot", loc="center", pad=1, fontsize=8, fontweight="bold")
plt.show() # 그래프 보여줄때
예제 5 - 산점도
# 나이와 평균 결제금액 분포 나타내기
d3 = df2.groupby('Age')['Purchase Amount (USD)'].mean().reset_index()
d3 # 그래프 그리기 전에 한번 확인하기
plt.scatter(d3['Age'],d3['Purchase Amount (USD)'], c="#20B2AA")
예제 6 - 이중축 그래프
# 1. 기본 스타일 설정
plt.style.use('default')
plt.rcParams['figure.figsize'] = (4, 3)
plt.rcParams['font.size'] = 12
# 2. 데이터 준비
x = np.arange(2020, 2027)
y1 = np.array([1, 3, 7, 5, 9, 7, 14])
y2 = np.array([1, 3, 5, 7, 9, 11, 13])
# 3. 그래프 그리기
# 그래프를 두 개 그리고 합쳐줄 거라서 subplot 필요
fig, ax1 = plt.subplots()
ax1.plot(x, y1, '-s', color='#20B2AA', markersize=5, linewidth=2, alpha=0.7, label='Price')
ax1.set_ylim(0, 18)
ax1.set_xlabel('Year')
ax1.set_ylabel('Price ($)')
ax1.tick_params(axis='both', direction='in')
# x축 공유(즉, 이중축 사용 의미)
ax2 = ax1.twinx() #이건 기억하기! ax1에서 선언했던 x축을 ax2에서도 사용하겠다
ax2.bar(x, y2, color='#DB7093', label='Demand', alpha=0.7, width=0.7)
ax2.set_ylim(0, 18)
ax2.set_ylabel(r'Demand ($\times10^6$)')
ax2.tick_params(axis='y', direction='in') # 기본 옵션
#레이블 위치
# 클수록 가장 위쪽에 보여진다고 생각하면 됨.
#ax2.set_zorder(ax1.get_zorder() + 10) #와 비교해보세요!
ax1.set_zorder(ax2.get_zorder() + 20)
ax1.patch.set_visible(False)
ax1.legend(loc='upper left')
ax2.legend(loc='upper right')
plt.show()
예제 7 - 피라미드 그래프 🔴
이건 좀 완전히 이해는 안 갔지만 이렇게 굴러가는듯,,
- 원래 나이를 어떻게 나눠줄지 범위를 리스트로 정하기
- cut으로 적용
- 범주를 map으로 lambda 함수 적용해서 만들어주기
# 나이대별 성별 유저수 구하기
# 피라미드 차트 그리기
#나이 구간 설정
bins2 = [10, 15, 20, 25, 30, 35, 40, 45, 50, 55, 60, 65, 70, 75, 80]
bin_labels = [15, 20, 25, 30, 35, 40, 45, 50, 55, 60, 65, 70, 75, 80]
#cut 활용 절대구간 나누기
df2["bin"] = pd.cut(df2["Age"], bins = bins2)
#map은 리스트의 요소를 지정된 함수로 처리해주는 함수
#15는 15-20 으로 반환됨
df2["age"] = df2["bin"].map(lambda x: str(x.left) + " - " + str(x.right))
df2
df7 = df2.groupby(['age','Gender'])['Customer ID'].count().reset_index()
df7 = pd.pivot_table(df7, index='age', columns='Gender', values='Customer ID').reset_index()
# 왼쪽으로 그려지는 컬럼이 '-'
df7["Female_Left"] = 0
df7["Female_Width"] = df7["Female"]
df7["Male_Left"] = -df7["Male"]
df7["Male_Width"] = df7["Male"]
dplot6 = plt.figure(figsize=(7,5))
plt.barh(y=df7["age"], width=df7["Female_Width"], color="#F4D13B", label="Female")
plt.barh(y=df7["age"], width=df7["Male_Width"], left=df7["Male_Left"],color="#9b59b6", label="Male")
plt.xlim(-300,270)
plt.ylim(-2,12)
plt.text(-200, 13, "Male", fontsize=10, fontweight = "bold")
plt.text(160, 10.7, "Female", fontsize=10, fontweight="bold")
for idx in range(len(df7)): # 막대 개수만큼 표현해야해서 len
plt.text(x=df7["Male_Left"][idx]-0.5, y=idx, s="{}".format(df7["Male"][idx]),
ha="right", va="center",
fontsize=8, color="#9b59b6")
plt.text(x=df7["Female_Width"][idx]+0.5, y=idx, s="{}".format(df7["Female"][idx]),
ha="left", va="center",
fontsize=8, color="#F4D13B")
plt.title("Pyramid plot", loc="center", pad=15, fontsize=15, fontweight="bold")
예제 8 - 여러개 그래프 그리기
#figure,ax 만들기
fig,ax=plt.subplots(2,2)
#그래프 그리기
ax[0,0].plot(np.linspace(0,100,20),np.linspace(0,100,20)**2, marker='o', markersize=2, markeredgecolor='y')
ax[0,1].hist(np.random.randn(500), bins=30, color='purple', alpha=0.5)
ax[1,0].bar([1,3,5,7],np.array([1,2,3,4]),color='r')
ax[1,1].boxplot(np.random.randn(500,5))
#그래프 사이 간격 추가
fig.subplots_adjust(hspace=0.5,wspace=0.3)
#그래프별 타이틀 추가
ax[0,0].set_title("line plot", fontsize=9)
ax[0,1].set_title("hist plot", fontsize=9)
ax[1,0].set_title("bar plot", fontsize=9)
ax[1,1].set_title("box plot", fontsize=9)
plt.show()
그래프꾸미기 잼있다 ㄷㄷ
일기
- Pandas
세션 7회차 정리🔼 - 전처리&시각화
4주차❌ - 프로젝트
방향성논의✅EDA✅
오늘도 하루종일 프로젝트 + 라이브세션 하니까 끝났다..
우리 조만 이런 건 아니겠지? 라는 생각이 자꾸 드는데 처음 OT할때 매니저님이 얘기하셨던 게 다시금 생각 남
남과 비교하지 말라고 했는데.. 나는 진짜 남이랑 비교할 거라고 생각을 못했는데 자연스럽게 이렇게 되는 것 같다
다들 잘하는 것 같고 진도 척척 나가고 있는 것처럼 느껴지기 때문
그래도 전처리하는 게 그만큼 중요하다는 뜻이니 잘 마쳐서 좋은 데이터로 좋은 결론을 낼 수 있었으면 좋겠다!
아직까지 뭔가 눈에 보이는 엄청난 성과는 없지만 파이팅해보자 잘 할 수 있따🍀
(회의는 22:49에 끝났다 다들 고생했어요❤️🔥)
