팀스터디
아티클스터디
선정 아티클
양질의 데이터를 판별하는 5가지방법 : ⑤ 목적에 적합한 데이터인가?
개인 요약
분석 목적 설정은 양질의 데이터 판별을 위한 이정표 역할을 한다
- 데이터에 원하는 정보가 담겨 있는가?
- DIKW 피라미드의 관점
데이터를 정보와 지식, 지혜로 발전시켜야 활용 가능
→ 원하는 내용이 충실이 담겨있지 않은 경우 저품질의 데이터로 판별
- 분석가의 역량에 따라 달라질 수 있음
- DIKW 피라미드의 관점
- 분석 방법에 부합하는 데이터인가?
- 머신러닝
종속 변수가 존재해야 함
- 인사이트 도출
원천 데이터보다 어느 정도 가공된 데이터가 유리
- 머신러닝
인사이트
-
지난 프로젝트에서 처음에 데이터를 가공하는 것에만 몰두하다 보니, 어느 순간 ‘이거 뭐 때문에 하고 있었지?’ 라는 생각이 들었습니다. 그래서 당시 조장님의 조언에 따라 처음으로 다시 돌아가 분석 목적을 명확히 정리한 뒤 다시 시작했었고, 그 이후에는 흐름이 명쾌해졌던 기억이 있습니다.
-
분석 목적을 설정하는 것은 목표가 되기도, 양질의 데이터를 판별하는 기준이 되기도 한다는 점에서 흥미로웠습니다.
팀원 공통 인사이트
데이터 분석 목적과 방법을 명확히 해야한다!
개인스터디
문제풀이 세션
Python - 설무아튜터님
파이썬 함수 구현 연습 문제
문제 1) 리스트 관련 함수 직접 구현
1-1. len()
def get_len(input_list) :
cnt = 0
for _ in input_list :
cnt += 1
return cnt
print(get_len([1,2,3,3])) #41-2. count() 🟢
def get_count(input_list, find_value) :
count = 0
for value in input_list:
if value == find_value:
count += 1
return count
print(get_count([1,2,3,3], 3)) #21-3. min(), max()🟢
def get_min_max(input_list) :
# 파이썬 스타일로 하는 게 좋다
if not input_list :
return None
# 예외처리
# if get_len(input_list) == 0:
# return None
min_value = input_list[0]
max_value = input_list[0]
for item in input_list:
if item < min_value:
min_value = item
if item > max_value:
max_value = item
return (min_value, max_value)
print(get_min_max([2,3,4,11,0])) #(0,11)1-4. sum()🟢
def get_sum(input_list) :
total = 0
for num in input_list:
total += num
return total
print(get_sum([1, 2, 3, 4, 5])) # 151-5. avg()🟢
def get_avg(input_list) :
if not input_list:
return None
total = get_sum(input_list)
return total / get_len(input_list)
print(get_avg([1,2,3,4,5])) #3.01-6. std() 🟢
def get_std(input_list) :
if not input_list :
return None
# 평균 구하기
avg = get_avg(input_list)
# 각 요소의 편차
diff_list = []
for val in input_list :
diff = val - avg # 편차
diff_list.append(diff ** 2)
# 컴프리헨션
# diff_list = [(val-avg)**2 for val in input_list]
# 편차 제곱의 평균
var = get_avg(diff_list)
return var ** 0.5
print(get_std([1,2,3,4,5])) # 약 1.414...1-7. median() 🟢
def get_median(input_list) :
if not input_list:
return None
sorted_list = sorted(input_list) # 원본 리스트 변경 안 됨
# input_list.sort() # 원본 리스트 변경
# 리스트 길이
length = get_len(sorted_list)
# 길이가 짝수인 경우
if length % 2 == 0 :
mid1 = sorted_list[length//2 -1]
mid2 = sorted_list[length//2]
return (mid1+mid2) /2
else:
return sorted_list[length//2]
print(get_median([1,2,3,4])) # 2.5
print(get_median([1,2,3,4,5])) # 3문제 2) 문자열 조작 함수 직접 구현
2-1. find() - 문자 한 개 입력 🟢
def get_find_ch(text, find_value) :
for i in range(get_len(text)):
if text[i] == find_value:
return i
return -1
print(get_find_ch('hello', 'l')) # 22-2. find() - 문자열 입력 🟢
def get_find_str(text, find_str, start=0) :
text_len = get_len(text)
find_str_len = get_len(find_str)
for i in range(start,text_len - find_str_len + 1) :
if text[i:i+find_str_len] == find_str :
return i
return -1
print(get_find_str('hello', 'llo')) # 2
print(get_find_str('hello world hello', 'hello', 1)) # 12
print(get_find_str('hello hello hello', 'hello', 2)) # 62-3. find() - 슬라이싱 안 쓰고 풀기 🟡
def get_find_str(text, find_str, start=0) :
text_len = get_len(text)
find_str_len = get_len(find_str)
for i in range(start,text_len - find_str_len + 1) :
match = True
for j in range(find_str_len) :
if text[i+j] != find_str[j]:
match = False
break
if match:
return i
return -1
print(get_find_str('hello', 'llo')) # 2
print(get_find_str('hello world hello', 'hello', 1)) # 12
print(get_find_str('hello hello hello', 'hello', 2)) # 62-4. split() - 문자 한 개 + 구분자 🟡
def str_split(text, sep=' ') :
result = []
current = ''
text += sep
for ch in text:
if ch == sep :
result.append(current)
current = ''
else :
current += ch
# if ch != '':
# result.append(current)
return result
print(str_split('hello my name is gildong', ' ')) # ['hello', 'my', 'name', 'is', 'gildong']여기부터 좀 어려웠따 😂
2-5. split() - 문자열 + 구분자 🔴
def str_split_string(text, sep='--') :
result = []
sep_len = get_len(sep)
# 구분자가 빈 문자열인 경우 처리
if sep_len == 0:
return [text]
# 현재 위치부터 검색 시작
start_pos = 0
while True:
# 구분자 위치 찾기
pos = get_find_str(text, sep, start_pos)
if pos == -1: # 더 이상 구분자가 없음
result.append(text[start_pos:])
break
# 구분자 앞부분을 결과에 추가
result.append(text[start_pos:pos])
# 다음 검색 시작 위치 업데이트
start_pos = pos + sep_len
return result
print(str_split_string('hello my name is gildong ', ' ')) # ['hello my name is', 'gildong ']
print(str_split_string('--hello--my-name is gildong ', '--')) # ['', 'hello', 'my-name is gildong ']2-6. replace() 🔴
def str_replace(text, old, new) :
# 원본 문자열이 없거나 대체할 문자열이 없는 경우
if not text or not old:
return text
result = ''
i = 0
while i < get_len(text):
# 현재 위치에서 old가 시작되는지 확인
if text[i:i+get_len(old)] == old:
result += new
i += get_len(old)
else:
result += text[i]
i += 1
return result
print(str_replace('hello my name is gildong', 'gildong', 'hani')) # 'hello my name is hani'
print(str_replace('gildong hello my name is gildong', 'gildong', 'hani')) # hani hello my name is hani2-7. strip() 🔴
def str_strip(text, remove_ch) :
if not text:
return text
# 앞쪽 제거
start = 0
while start < get_len(text) and text[start] == remove_ch:
start += 1
# 뒤쪽 제거
end = get_len(text) - 1
while end >= 0 and text[end] == remove_ch:
end -= 1
# 잘라낸 문자열 반환
return text[start:end+1]
print(str_strip('----hello--', '-')) # 'hello'2-8. title() 🔴
def str_title(text) :
if not text:
return text
# 첫 글자의 아스키코드 확인
first_char_code = ord(text[0])
# 첫 글자가 영어 소문자인 경우 (a-z, 97-122)
if 97 <= first_char_code <= 122:
# 소문자를 대문자로 변환 (32 차이)
uppercase_char = chr(first_char_code - 32)
return uppercase_char + text[1:]
# 첫 글자가 소문자가 아니면 그대로 반환
return text
print(str_title('hello')) # 'Hello'
print(str_title('안녕하세요')) # '안녕하세요' (변화 없음)
print(str_title('123abc')) # '123abc' (변화 없음)
print(str_title('')) # '' (변화 없음)
print(str_title('HELLO')) # 'HELLO' (변화 없음)머신러닝 소프트 랜딩 세션
사람이 규칙을 짜지 않아도, 데이터를 통해 컴퓨터가 스스로 학습해 문제를 해결하게 만드는 방법이 머신러닝!
머신러닝
- 전통 프로그래밍 : 규칙(= 알고리즘)을 사람이 짜고, 데이터는 그냥 넣는 거
- 머신러닝 : 데이터만 넣으면 규칙(=모델)을 컴퓨터가 알아서 찾아냄
➡️ 복잡한 문제일 수록 머신러닝이 훨씬 효율적
예시 : 스팸필터
- 전통 방식 : "무료", "신용카드"같은 단어 직접 넣어 필터링
- 머신러닝 방식 : 스팸 메일 예시 주고 학습시키면 컴퓨터가 알아서 분류
"For you"를 "For U"로 바꿔도 머신러닝은 필터링 가능(계속 학습하니까)
예시 : 이미지 분류
- 고양이 vs 강아지 구분하려면 조건문을 수천 개 써야 함
- 머신러닝은 그냥 사진 수천 장 보여주고 "이건 고양이야~" 알려주면 됨
활용 사례
- 유튜브/넷플릭스 추천 시스템
- 지메일 스팸 필터
- Siri, 구글 어시스턴트 음성 인식
- 자율주행 차량 시스템(보행자, 신호 인식)
- 의료 진단(CT 영상에서 종양 탐지)
- 기타 : 금융 사기 탐지, 챗봇, 게임 AI 등
실습 : sklearn + numpy
한 학생의 공부 시간과 시험 점수 데이터가 몇 개 있습니다. 이 데이터를 이
용해, 새로운 공부 시간에 대한 예상 점수를 예측해보려고 합니다. 예를 들
어 지난 시험에서 각 학생이 공부한 시간 대비 얻은 점수가 다음과 같다고
합시다.
- 1시간 공부 -> 40점
- 2시간 공부 -> 45점
- 3시간 공부 -> 50점
- 4시간 공부 -> 48점 (약간의 예외 사항)
- 5시간 공부 -> 55점
- 6시간 공부 -> 58점
- 7시간 공부 -> 63점
- 8시간 공부 -> 68점
from sklearn.linear_model import LinearRegression
X = np.array([1,2,3,4,5,6,7,8]).reshape(-1, 1)
y = np.array([40,45,50,48,55,58,63,68])
model = LinearRegression() # 클래스 선언과 같음
model.fit(X, y)
new_X = np.array([[9]])
pred_y = model.predict(new_X)
print("공부 9시간 -> 예상 점수:", pred_y[0])
→ 대략 점수 = 5 * 시간 + 25 형태의 예측 모델 생성됨
-
과정 설명
-
데이터 준비
입력 데이터 X와 정답 레이블 y를 (대부분 NumPy 배열이나 Pandas 데이터프레임 형태로) 준비 -
모델 객체 생성
예를 들어 선형 회귀 모델을 쓰고 싶다면from sklearn.linear_model import LinearRegression한 후model LinearRegression()으로 모델 객체 생성 -
모델 학습(fit)
model.fit(X, y)호출 > 주어진 데이터에 맞춰 학습시킵니다. -
예측
학습된 모델로 새로운 데이터에 대한 예측을model.predict(new_X)로 수행
-
통계학 기초 1주차
데이터 분석에 있어 통계가 중요한 이유
- 데이터 요약 / 패턴 파악
- 추론을 통한 의미있는 결론 도출
→ 기업은 더 나은 전략과 수익 창출 가능
활용 사례
-
고객 만족도 설문조사 분석 → 불만 사항 개선
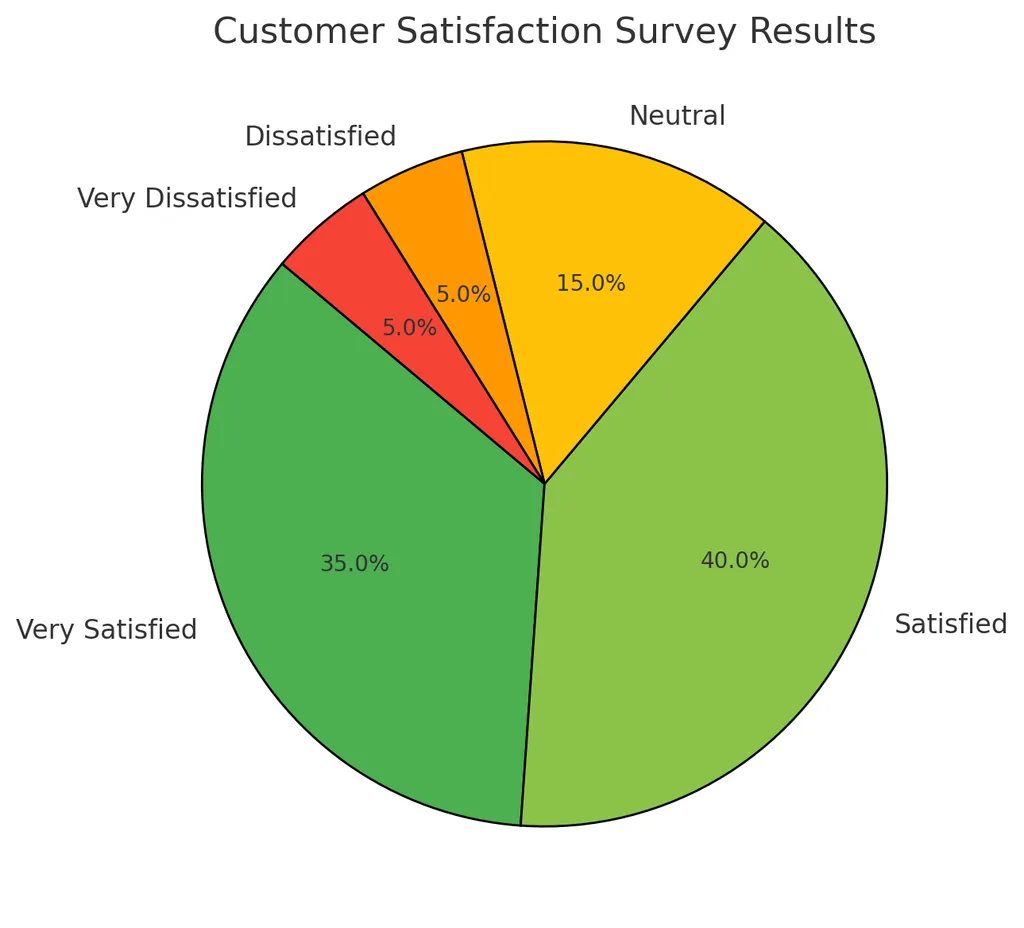
-
고객 세그먼트별 맞춤 상품 추천
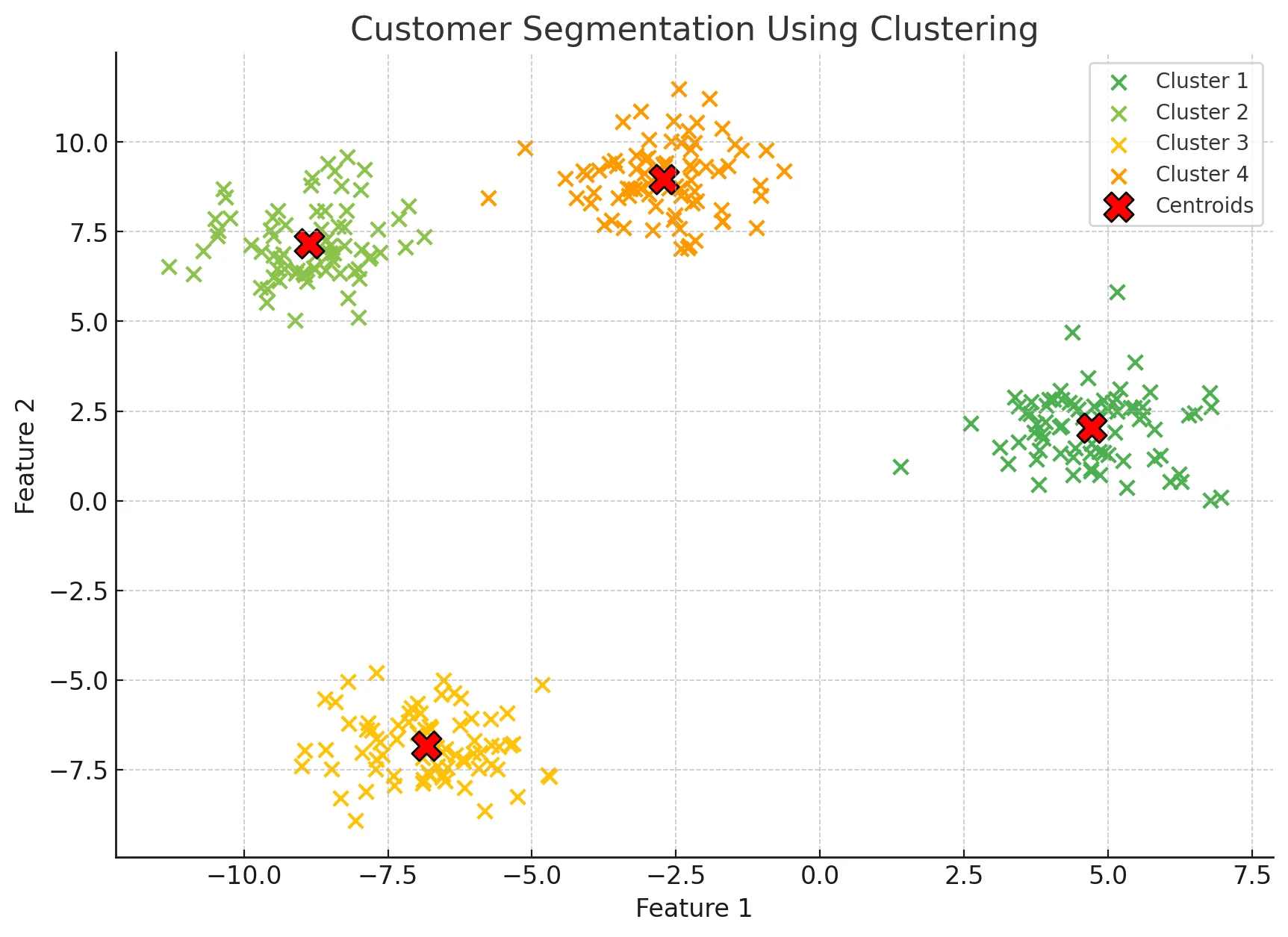
-
그 외 마케팅, 신제품 개발, 전략 수립 등 다양한 분야에 사용
기술통계와 추론통계
기술통계
-
데이터를 요약하고 설명하는 방법
- 예시) 평균매출, 표준편차로 비즈니스 요약
-
핵심개념
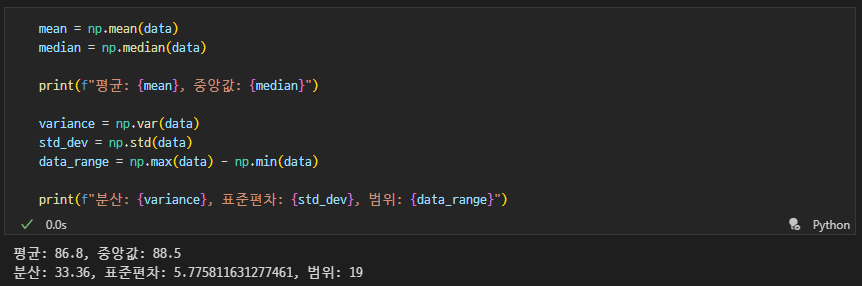
- 평균 :
(모든 값의 합) / (개수) - 중앙값 : 크기 순으로 정렬 후 가운데 값 (짝수일 땐 중간 두 값의 평균)
- 분산 : 평균에서 얼마나 퍼져 있는지
(데이터 값 - 평균) ^ 2 - 표준편차 : 퍼짐 정도를 원래 단위로 표현한 것
분산의 제곱근
- 평균 :
-
예시로 정리
데이터 : [2, 4, 4, 4, 5, 5, 7, 9]- 평균 = (2+4+4+4+5+5+7+9) / 8 = 5
- 분산 = (9+1+1+1+0+0+4+16) / 8 = 4
(2-5)^2 = 9
(4-5)^2 = 1
(7-5)^2 = 4
(9-5)^2 = 16 - 표준편차 = 4 * 0.5 = 2
추론통계
- 표본을 통해 모집단을 추정하거나 가설 검정
- 예시) 일부 고객 설문으로 전체 만족도 추정
- 핵심개념
- 신뢰구간 : 모집단 평균이 포함될 확률적 범위(일반적으로 95% 신뢰구간 사용)
- 가설검정
- 귀무가설 H₀ : 기본 가설
예시) 프로그램이 성적에 영향을 미치지 않는다 - 대립가설 H₁ : 반대 가설
예시) 프로그램이 성적에 영향을 미친다 - p-value로 귀무가설 기각 여부 판단
- 귀무가설 H₀ : 기본 가설
실습
import

데이터 준비

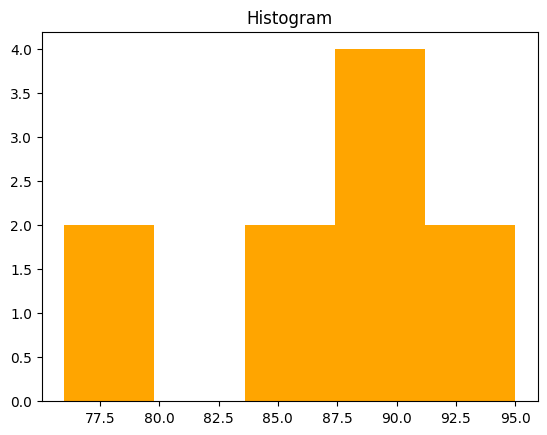
데이터 분포 탐색
-
boxplot

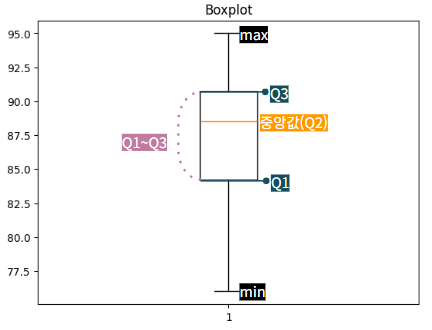
-
histogram

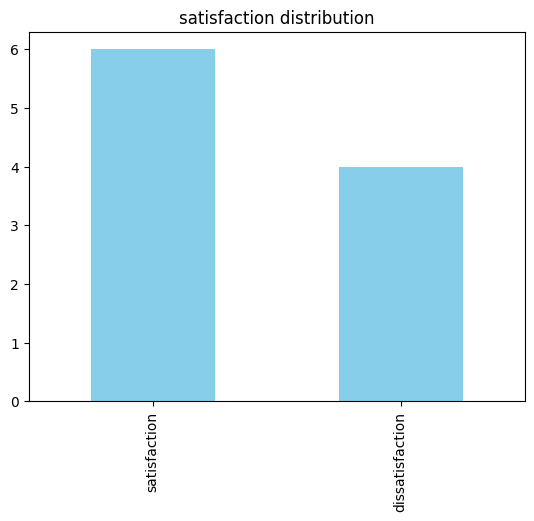
이진데이터와 범주데이터 탐색
숫자로 탐색 불가 > 최빈값(개수가 제일 많은 값)을 주로 사용
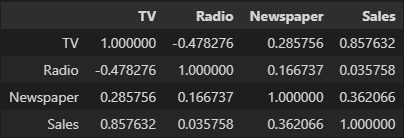
상관관계
- -1이나 1에 가까울수록 강력한 상관관계
- 0에 가까울수록 상관관계 X
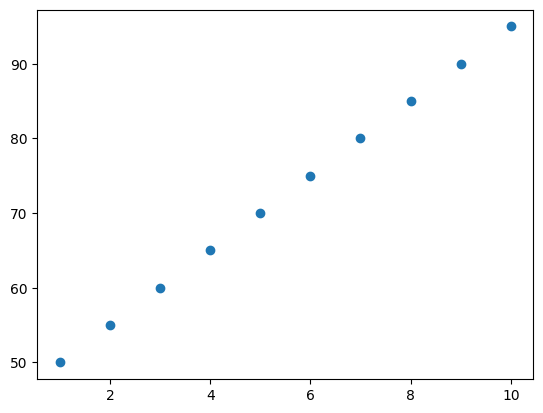
두 개 이상의 변수 탐색
-
pairplot
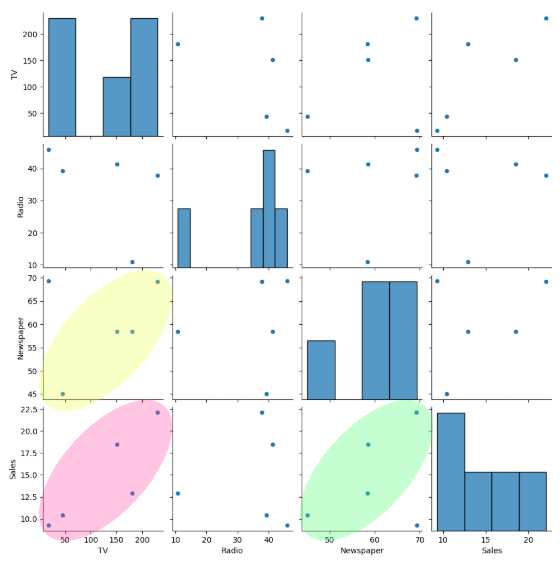
🟡<🟢<🔴순으로 상관관계 강함 -
corr
-
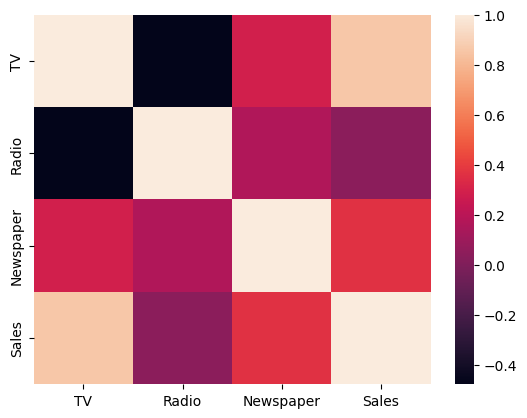
heatmap

연습문제
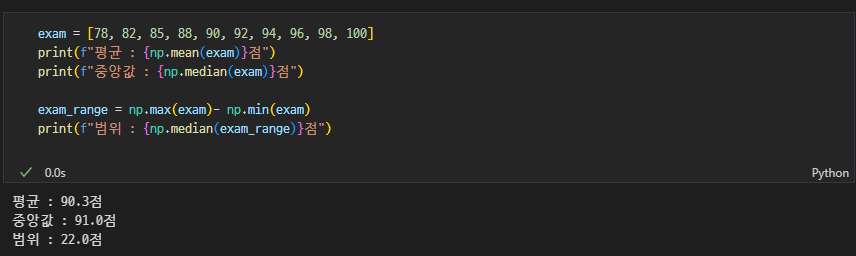
어느 학교의 학생들 10명의 수학 점수는 다음과 같습니다: 78, 82, 85, 88, 90, 92, 94, 96, 98, 100. 이 데이터의 평균을 구하세요.
4번 문제의 학생 수학 점수의 중앙값을 구하세요.
4번 문제의 학생 수학 점수 데이터의 범위(Range)를 구하세요.
학생들의 수학 점수와 영어 점수가 각각 다음과 같을 때, 두 변수 간의 상관관계가 양의 상관관계인지, 음의 상관관계인지, 상관관계가 없는지 설명하고 그 이유를 얘기하세요.
- 수학 점수: 78, 82, 85, 88, 90, 92, 94, 96, 98, 100.
- 영어 점수: 70, 75, 80, 85, 85, 90, 90, 95, 95, 100.
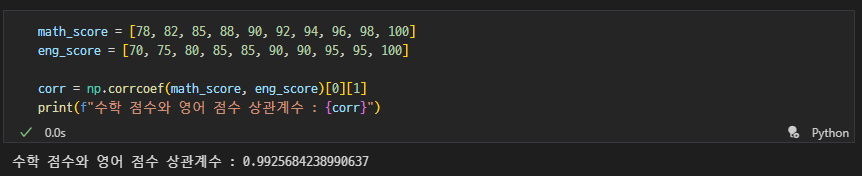
양의 상관관계
상관계수가 약 0.992로 높은 상관관계를 가짐
코드카타
SQL - 년, 월, 성별 별 상품 구매 회원 수 구하기
SQL - 서울에 위치한 식당 목록 출력하기
Python - 약수의 개수와 덧셈
Python - 문자열 내림차순으로 배치하기
일기
- SQL
코드카타 60-61✅ - Python
코드카타 33-34✅과제해설 복기✅ - 기초 통계학
1주차✅2주차❌
오늘은 하루종일 강의 들었다! 통계학 강의 2주차까지 들으려고 했는데 1주차까지밖에 못 들었다😭 내일 2주차 듣고 3주차까지 듣는 게 목표
-
만우절 기념 두더지s

-
언님의 완벽한 코스프레

-
이렇게 많은 그리드는 처음 봄 ㄷㄷ