
개인스터디
통계야 놀자 6회차
통계 vs 머신러닝
| 항목 | 통계적 가설검정 | 머신러닝 |
|---|---|---|
| 목적 | 가설 검증, 통계적 특성 파악 | 예측/분류 모델 생성 |
| 데이터 | 적은 데이터로도 가능 | 데이터 많을수록 성능 ↑ |
| 결과 해석 | p-value 중심 해석 | 정확도, 정밀도 등 지표 |
| 접근 방식 | 선형, 해석 가능 | 비선형, 복잡한 패턴 학습 |
| 활용 분야 | 의학, 사회과학 등 | 산업 자동화, 추천 시스템 등 |
- 상호보완적 관계
- 통계 → 머신러닝
- 머신러닝 피처 선택
- 데이터 전처리
- 머신러닝 → 통계
- 비선형 데이터 처리
- 대규모 데이터 처리
- 통계 → 머신러닝
지도학습
정답(label)이 있는 데이터를 사용
분류
결과가 카테고리
예) 내일 날씨가 추울 것이다
회귀
결과가 연속적인 수치
예) 내일은 온도가 35.0℃일 것이다.
주요 알고리즘
- 선형 회귀, 로지스틱 회귀
- 나이브 베이즈
- KNN (k-Nearest Neighbors)
- 결정 트리, 랜덤 포레스트
- SVM (Support Vector Machine)
- 인공 신경망 (Neural Network)
RFM 분석(고객 분류기법)
- Recency: 최근 구매일
- Frequency: 구매 빈도
- Monetary: 구매 금액
→ 비즈니스 성격에 따라, 상황에 따라 알맞은 기준을 세우는 과정 필요
-
Recency, Frequency, Monetary를 각각 몇 단계로 나눌 것인가
-
Frequency, Monetary를 집계하는 기간을 어떻게 설정할 것인가
- 예) Recency: 2024-01-01 을 기준으로 한 달 이내에 구매기록이 있으면 ‘recent’ 아니면 ‘past’
- 예) Frequency: 구매횟수가 5회 이상 ‘high’ , 3~5회 ‘mid’, 나머지 ‘low’
- 예) Monetary: 누적 구매금액 500 달러 이상 ‘high’ 아니면 ‘low’
비지도학습
정답(label)이 없는 데이터에서 패턴 파악
군집화 + 차원축소
크게 두 가지로 나뉜다고 하나, 현업에서는 연결되어 하나의 프로젝트로 진행됨
프로세스
- 분석 기간 선정
- 피처 선정, 군집 수(K) 설정
2.이상치 처리 - 표준화
- 차원 축소 + 시각화 (PCA plot 등)
- 최적화 반복
- 모델링 (랜덤포레스트 등)
- 자동화
주요 알고리즘
- 군집(Clustering)
- K-means 클러스터링
- 위계적 군집분석
- 가우시안 혼합모형(Gaussian Mix Texture Model)
- 주성분 분석(PCA)
- LLE(Locally Linear Embedding)
- Isomap
- MDS(Multi Dimensional Scaling
- t-SNE(t-distributed Stochastic Neighbor Embedding)
Standard 9회차
평가 지표가 중요한 이유
단순히 정확도만 보면 안 됨
→ 불균형 데이터에서는 정확도가 의미가 없음
데이터 비율 확인이 먼저!
예시 ) 암환자 비율 1%인 데이터에서 모두 ‘건강’이라 예측해도 정확도 99%
주요 평가 지표
| 지표 | 설명 |
|---|---|
| 정확도 | 전체 중 정답 예측의 비율 |
| 정밀도 | Positive 예측 중 실제로 Positive인 비율 |
| 재현율 | 실제 Positive 중 맞춘 비율 |
| F1-score | 정밀도와 재현율의 조화 평균 |
| AUC-ROC | 다양한 임계값에서 모델의 분류 능력 요약 |
✅ 정밀도 vs 재현율 Trade-off 이해 필요!
혼동 행렬 시각화 ✅
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
y_true = [0, 1, 1, 0, 1, 0, 1]
y_pred = [0, 0, 1, 0, 1, 1, 1]
cm = confusion_matrix(y_true, y_pred)
disp = ConfusionMatrixDisplay(confusion_matrix=cm)
disp.plot()
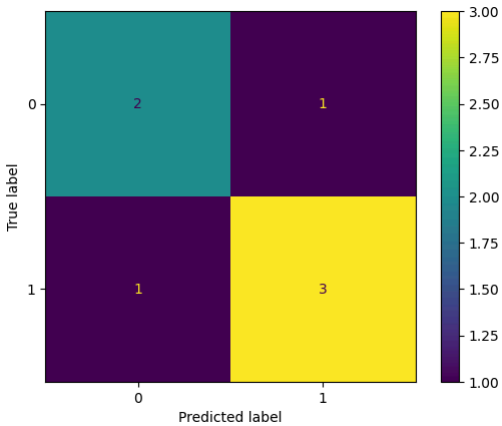
TP, FP, FN, TN
| 실제값 / 예측값 | 예측값: Positive (1) | 예측값: Negative (0) |
|---|---|---|
| 실제: Positive (1) | ✅ TP (True Positive) | ❌ FN (False Negative) |
| 실제: Negative (0) | ❌ FP (False Positive) | ✅ TN (True Negative) |
정확도(Accuracy)
(TP + TN) / 전체
전체 예측 중에서 맞춘 비율
정밀도(Precision)
TP / (TP + FP)
예측한 것 중 실제로 맞은 비율
= 얼마나 정확히 Positive 만 골랐나
재현율(Recall)
TP / (TP + FN)
실제 Positive를 얼마나 놓치지 않았나
F1-score
2 (P R) / (P + R)
정밀도와 재현율의 조화평균
ROC Curve, PR Curve 시각화
from sklearn.metrics import roc_curve, roc_auc_score
import matplotlib.pyplot as plt
y_prob = [0.1, 0.4, 0.8, 0.35, 0.9, 0.6, 0.75]
fpr, tpr, thresholds = roc_curve(y_true, y_prob)
plt.plot(fpr, tpr, label=f"AUC = {roc_auc_score(y_true, y_prob):.2f}")
plt.plot([0, 1], [0, 1], 'k--') # 기준선
plt.xlabel("False Positive Rate")
plt.ylabel("True Positive Rate")
plt.title("ROC Curve")
plt.legend()
plt.grid(True)
plt.show()
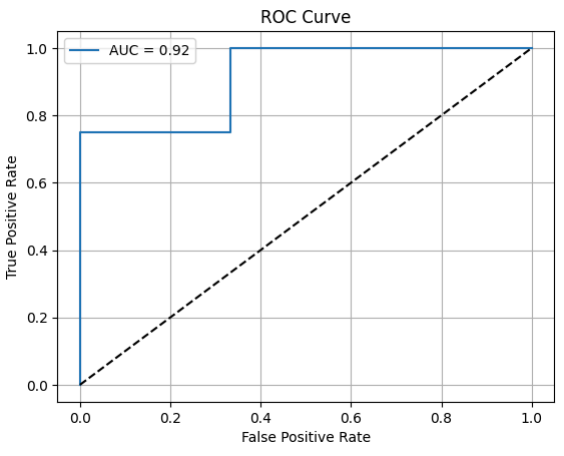
AUC
- ROC 곡선 아래 면적
- 1.0에 가까울 수록 좋다
분류 모델 평가
from sklearn.datasets import load_breast_cancer
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
X, y = load_breast_cancer(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
model = RandomForestClassifier()
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
print(classification_report(y_test, y_pred))
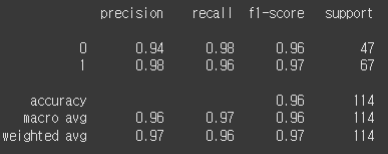
해석
| 항목 | 설명 |
|---|---|
| precision | 예측한 Positive 중 맞은 비율 (정밀도) |
| recall | 실제 Positive 중 맞춘 비율 (재현율) |
| f1-score | 정밀도와 재현율의 조화 평균 |
| support | 해당 클래스(0 또는 1)의 실제 샘플 수 |
| accuracy | 전체 정답 비율 → 0.96 (96%) |
| macro avg | 클래스별 지표 평균 (동등하게 가중치) → 불균형 클래스에서 중요 |
| weighted avg | 클래스별 지표 평균 (샘플 수로 가중 평균) → 실제 정확도 반영 |
☑️ 요약
- 정확도 외에도 정밀도/재현율/F1도 함께 확인
- 혼동 행렬, ROC/AUC를 통해 시각적으로 모델 성능 흐름 확인
- 불균형 데이터 문제를 항상 주의하자
시각화 실수 TOP 8
| ❌ 실수 | 🧨 설명 | ✅ 대처 |
|---|---|---|
| 목적 없는 시각화 | “왜 이 그래프를 그렸지?” → 목적 없이 만든 시각화는 정보 전달 불가 | 그래프 그리기 전 목적 먼저 정하기 (비교? 추세? 분포?) |
| 축을 잘못 설정 | y축을 0부터 안 시작 → 변화가 과장됨 / 이중축 남용 → 혼란 유발 | 축 범위 명확히, 가능하면 0부터 시작하고 이중축은 최소화 |
| 색상 남용 | 색이 너무 많으면 해석 어려움 / 색맹은 빨강-초록 구분 불가 | 색상 개수 최소화, 색맹 사용자 고려한 색상 팔레트 사용 |
| 차트 유형 오류 | 시간 변화에 막대그래프, 범주형 데이터에 선그래프 등 부적절한 차트 사용 | 데이터 유형에 맞는 차트 선택: 추세 → 선그래프, 분포 → 히스토그램 등 |
| 레이블, 범례, 단위 없음 | 예쁜데 x축, y축이 뭔지 모르면 의미 없음 | 제목, 축 이름, 단위, 범례는 기본 필수 요소 |
| 정보 과잉 | 한 그래프에 30개 막대, 10개 색상, 2개 축 → 해석 불가능 | 한 그래프 = 한 메시지, 복잡하면 그래프를 나눠 그리기 |
| 스케일 미고려 | 변수 간 스케일이 달라서 중요한 정보가 안 보임 | 표준화, 로그 스케일 등 적용해서 가독성 확보 |
| 해석 없는 시각화 | “이건 이렇게 나왔어요~” 하고 끝냄 → 독자 입장에서 해석 불가 | 간단한 해석 문장 꼭 추가하기 (“이 그래프는 ○○를 보여줍니다”) |
일기
- 통계
세션 6회차✅ - 수준별학습
스탠다드 8회차✅
오늘 컨디션이 그닥이라서 많은 일을 하지 못했따
일찍 자보고 내일은 다시 파이팅 해보겠습니다
💿오늘의 추천곡 Thank you - Dido

비오는 날에 어울리는 것 같다고 추천해주신 노래~~
오랜만에 듣는 것 같습니다😶🌫️
