
팀스터디
아티클스터디
선정아티클
개인 요약
-
요약 : 데이터 시각화를 이용한 거짓말에 주의하자
- 막대그래프
- 기준선 0인지 확인
- y축 살펴보기
- 선 그래프
- 두 개의 y축 주의
- 누적값 확인
- 파이차트
- 전체 합 확인
- 3D 주의
- 지도
- 시점 확인
- 시각화 배경(맥락) 확인
- 막대그래프
인사이트
- 지난 프로젝트때(또TFT..^^) 구간별 시너지 승률을 막대그래프로 시각화하면서 기준선을 0으로 설정해놓지 않아 막상 서로 다른 시너지들끼리의 차이가 잘 보이지 않았던 상황이 있었습니다. 이때 기준선을 무엇으로 설정하느냐가 중요하다는 것을 느꼈습니다.
- 아티클의 기준선을 0으로 설정해놓지 않아 과장될 수 있다는 사례와는 반대의 상황이긴 하나, 시각화의 의도에 따라 전하고자 하는 메시지가 달라질 수 있다는 점을 늘 염두에 두고 진행해야겠습니다.
- 어떤 상품을 셀링하는 입장에서는 저런 꼼수(?)가 중요할 것 같다는 생각도 들었습니다. 뭔가 어디까지가 허용되는 선인지가 궁금하기도 하네요. 과대 광고를 제재하는 것처럼 그런 기준도 정해져있을까요?
팀원 공통 인사이트
데이터 시각화는 쉽게 이해되고, 그 영향력이 큰 만큼 이를 비판적으로 바라보는 태도가 중요하다!
개인스터디
실무에 쓰는 머신러닝 기초 4강
* 머신러닝
├── 지도학습
│ ├── 분류 (Classification) → KNN, 로지스틱 회귀, SVM
│ └── 회귀 (Regression)✅ → 선형회귀, Lasso, Ridge
│
├── 앙상블
│ ├── 배깅 (Bagging) → Random Forest
│ └── 부스팅 (Boosting) → XGBoost, LightGBM, CatBoost
│
├── 비지도학습
│ ├── 군집 (Clustering) → K-means, DBSCAN
│ ├── 차원축소 (Dim. Reduction) → PCA, t-SNE
│ └── 이상탐지 (Anomaly Detection) → One-Class SVM, Isolation Forest
│
└── 강화학습 (Reinforcement) 🔷 회귀 분석
Y = β0 + β1X
→ 연속형 종속변수(Y)를 독립변수(X)로 예측하는 지도학습 기법
분류 vs 회귀
| 구분 | 분류 (Classification) | 회귀 (Regression) |
|---|---|---|
| 결과값 | 이산형(클래스) | 연속형(실수) |
회귀 모델 사용 이유
1️⃣ 미래값 예측 (ex. 판매량, 온도)
2️⃣ 인과관계 해석 (통계 관점)
변수가 결과에 미치는 영향 해석
3️⃣ 데이터 기반 의사결정
추세 파악, 자원 분배 등
선형 회귀 (Linear Regression)
개념
Y = β0 + β1X1 + β2X2 + ... + βnXn
→ 독립변수와 종속변수가 선형 관계라고 가정
-
β0: 절편(intercept)
-
βi: 각 독립변수의 회귀계수(coefficient)
-
장단점
- 해석이 간단, 구현이 쉬움
- 데이터가 선형성이 아닐 경우 예측력 떨어짐
학습 과정
1️⃣ 가중치(회귀계수) 초기화
2️⃣ 손실함수 설정 (MSE)
3️⃣ 최적화
수학적인 방법(최소자승법), 경사하강법(Gradient Descent) 등을 통해 가중치 업데이트
4️⃣ 회귀계수(β) 학습
β0,β1,…를 얻어서 새로운 입력 값에 대한 예측 수행
코드
-
LinearRegression(최소자승법)
-
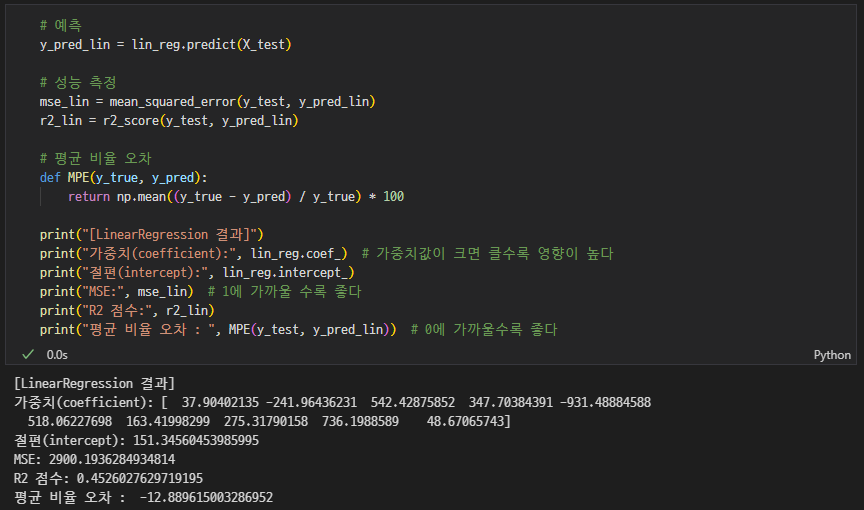
평가
-
SGDRegressor(경사하강법)
-
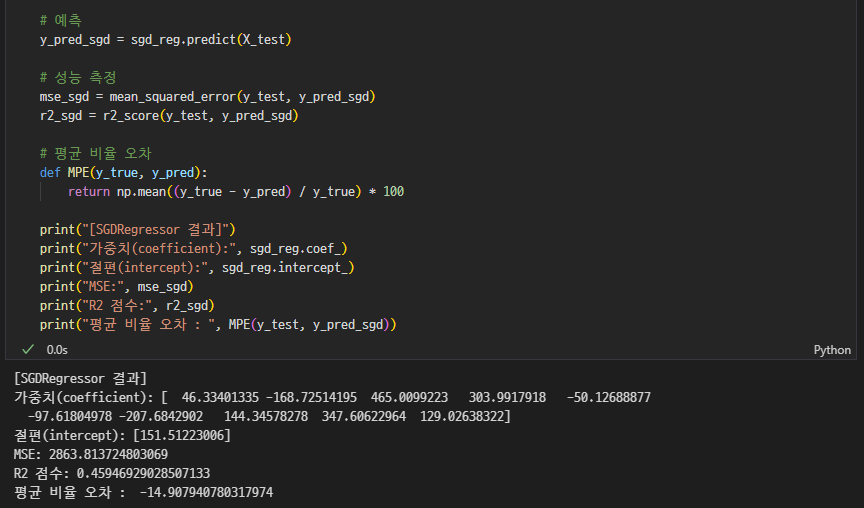
평가
다항 회귀 (Polynomial Regression)
개념
Y = β0 + β1 X + β2 X^2
선형 모델에 고차항 (X², X³ 등)을 추가해 비선형 패턴을 학습
- β0: 절편(intercept)
- βi: 각 독립변수의 회귀계수(coefficient)
- X^2 : 곡선 형태(비선형 패턴)를 만들기 위해 추가된 항
⚠️ 주의
고차항이 많을수록 과적합 위험
모델 복잡도와 일반화 성능 간 균형을 맞춰야 함
코드
-
LinearRegression(1차) + 성능평가
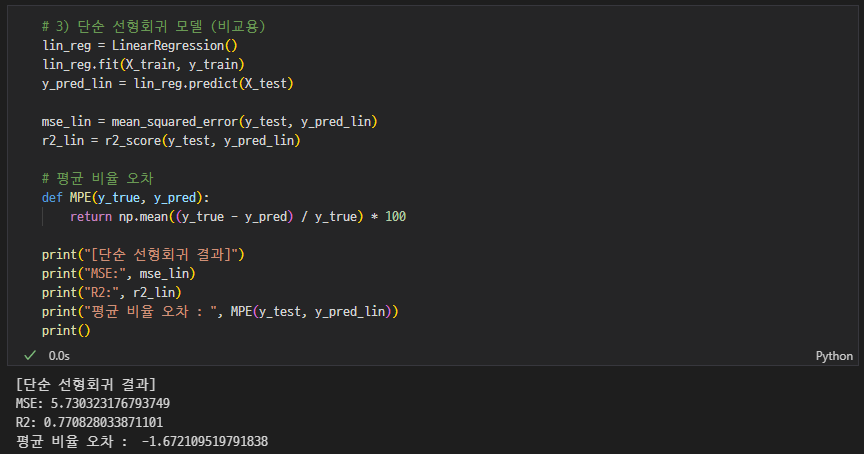
-
Polynomial Regression(2차) + 성능평가
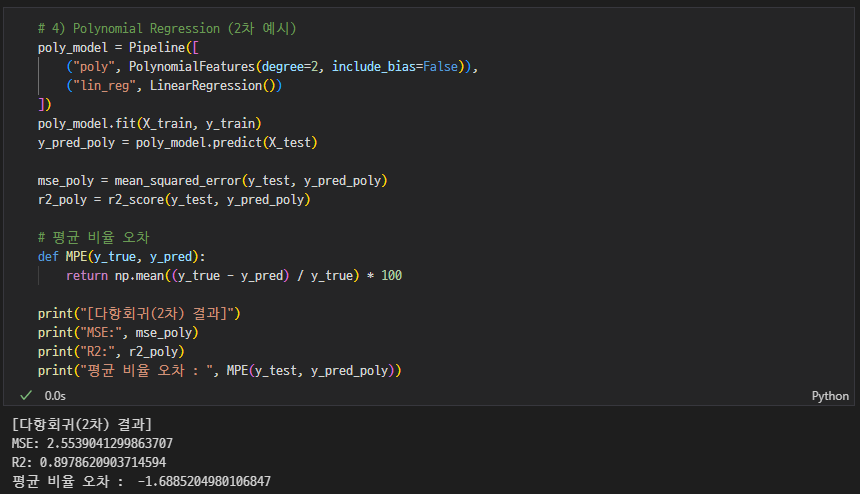
🔷 회귀모델 평가지표
| 지표 | 설명 |
|---|---|
| MSE | 평균 제곱 오차 (큰 오차에 민감) |
| MAE | 평균 절대 오차 (직관적) |
| RMSE | MSE에 루트를 씌운 값 |
| R² | 설명력 (1에 가까울수록 좋음) |
🔷 고급 회귀 (Ridge, Lasso)
선형 회귀에 규제(Regularization) 항을 추가해 과적합 방지
Ridge (릿지) 회귀
Loss = MSE(ŷ, y) + λ * Σ(βᵢ²)
L2 정규화 → 가중치 크기를 부드럽게 줄임
Lasso (라쏘) 회귀
Loss = MSE(ŷ, y) + λ * Σ(|βᵢ|)
L1 정규화 → 가중치를 0으로 만들어 변수 선택
코드
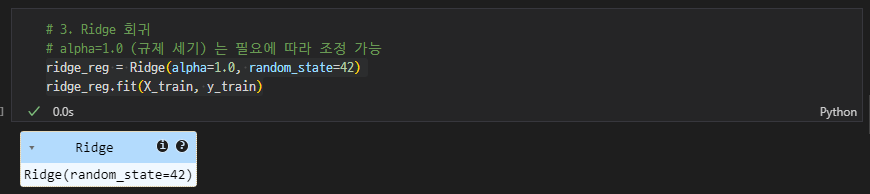
-
Ridge
-
성능평가
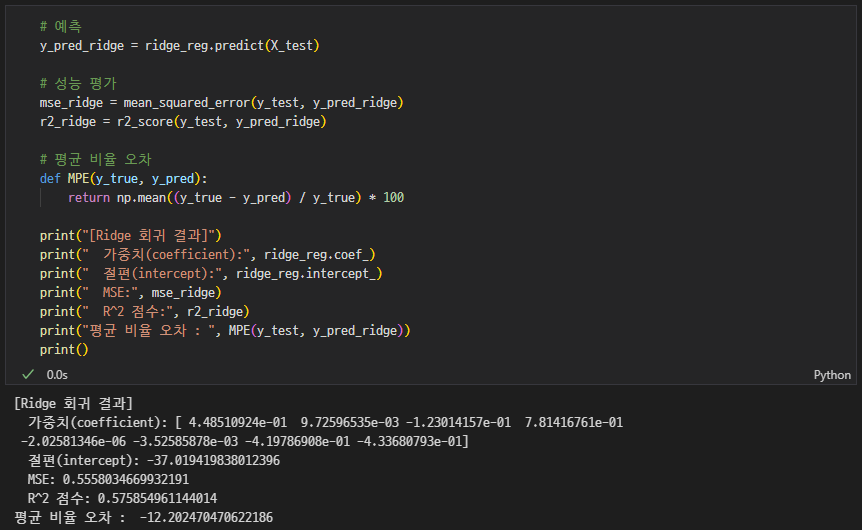
-
Lasso
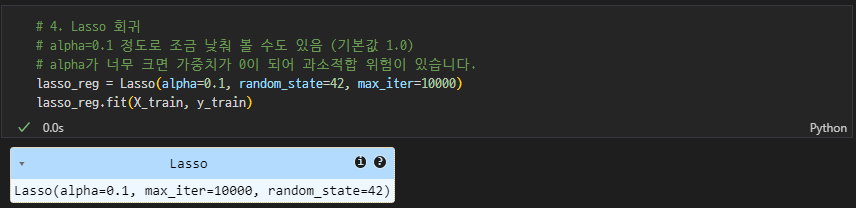
-
성능평가
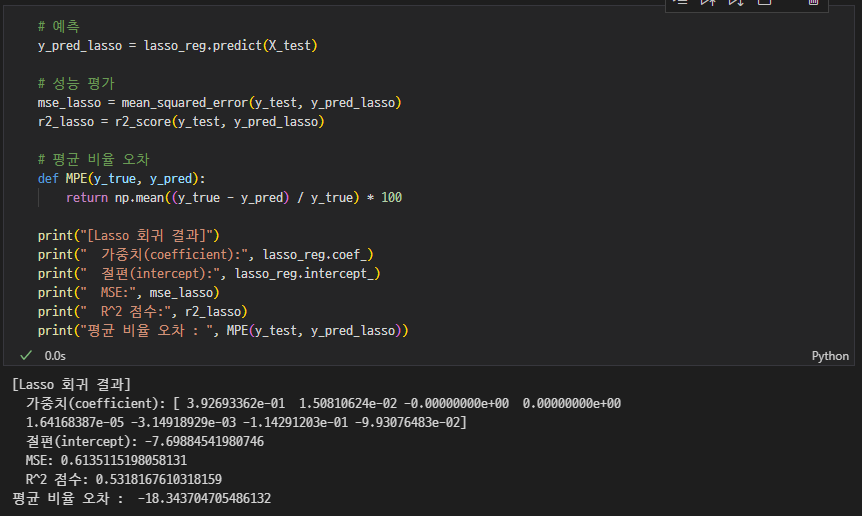
☑️ 요약
- 회귀 = 연속형 결과 변수 예측
- 비선형일 경우 다항 회귀 고려
- 규제 활용 + 과적합 방지 → Ridge / Lasso
- 성능평가 = MAE, RMSE, R² 등 다양한 평가 지표 활용
- 앙상블 기법(Gradient Boosting, XGBoost) 사용 시 성능 향상 가능(추후 학습할 내용)
☑️ Q&A
| 질문 | 요약 답변 |
|---|---|
| 선형 vs 다항? | 잔차나 분포 보고 판단 |
| Ridge vs Lasso? | 목적에 따라 선택 (안정성 vs 변수 선택) / 혼합(Elastic Net) |
| 앙상블이 더 좋은가? | 성능 좋지만 상황에 따라 선택 |
| 독립변수 많으면 성능 향상? | ❌ 과적합 주의, 변수 선택 필요 |
| 어떤 지표를 봐야 하나요? | RMSE, MAE, R² 모두 종합 판단 |
실습
아래의 당뇨병 X, y 데이터를 가지고 릿지와 라쏘 회귀를 진행하고 라쏘 회귀를 진행할 때 가중치가 0이 나오는 변수가 있다면 그 변수는 어떤 변수인지 이름을 쓰시오
- 조건
- 이미 데이터 전처리가 다 이루어진 sklearn 데이터셋이기 때문에 별도의 전처리는 필요 없음
- 다만, train데이터와 test 데이터를 나누는 과정은 필요
- 어떤 변수인지 이름을 찾는 것은 아래 데이터 프레임에서 확인
- random_state를 설정해야 하는 경우가 있으면 42로 설정
- 참고 ) s1~s6은 혈청1~혈청6을 의미합니다!
import numpy as np
import pandas as pd
from sklearn.datasets import load_diabetes
from sklearn.linear_model import Ridge, Lasso
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error, r2_score
# 데이터 로드
diabetes = load_diabetes()
X, y = diabetes.data, diabetes.target
########################################################
# 아래 코드는 pandas의 데이터 프레임으로 만드는 것(시각화용)
# 특성 이름(칼럼명) 가져오기
feature_names = diabetes.feature_names
# pandas DataFrame 생성
df = pd.DataFrame(X, columns=feature_names)
df['target'] = y # 타겟 열 추가
df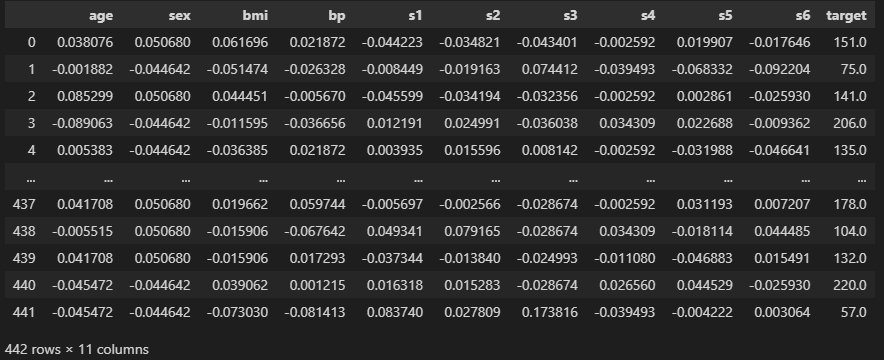
-
데이터확인

-
학습/테스트 데이터 분리
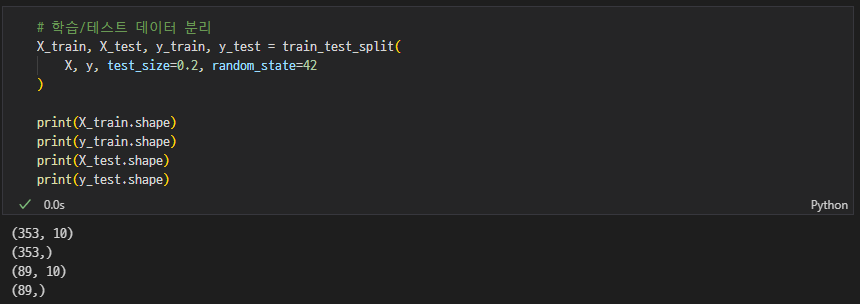
-
릿지/라쏘 학습
-
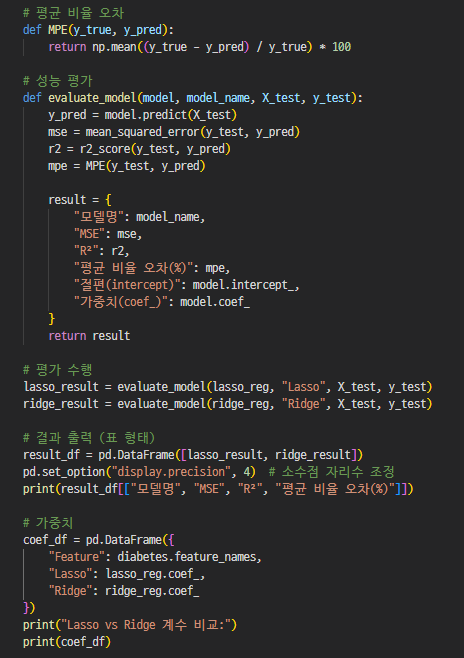
성능평가 / 회귀계수
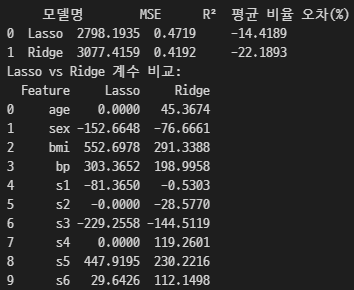
0이 나오는 변수
age, s2, s4
코드카타
SQL - Big Countries
SQL - Invalid Tweets
SQL - Article Views I
Python - 크기가 작은 부분 문자열
Python - 최소직사각형
일기
- SQL
코드카타 79-81✅ - Python
코드카타 43-44✅ - 통계
전체요약 복습✅ - 수준별학습
스탠다드 전체요약 복습✅ - 머신러닝
특강 1회차✅기초강의 4강✅기초강의 5강❌
오~ 늘은~ 코드카타를 했지만 기초강의 5강까지 들으려고 했던 계획이 물거품됨 🥲 오전에 특강 듣고 기초강의 4강 실습하다보니까 시간이 너무 모자라졌다 큰 개념들은 다 알겠는데 막상 실습하려고 보면 이게 맞나 하면서 엄청 오래 걸리게 됨
코드들을 외워서 써야하는 건지, 그냥 큰 흐름을 이해하기만 하면 되는 건지 무아 튜터님한테 여쭤봤는데 튜터님도 모르는 부분이 있으면 찾아서 쓰신다고 너무 걱정하지 말라고 하셔서 조금 안심이 됐다 넘나 스윗❤️🔥

💿오늘의 추천곡 AJR - Sober up

먼가 퇴폐? 약간 아련? 이런 노래일 거라고 생각했는데 ㅋㅋ 생각보다 씐나서 당황

아니 썸네일만 보면 그냥 개그노래같은데 아니라고요!?!?! 그게 더 놀라움