
개인스터디
QCC 4회차
문제 1 ) 매출이 가장 높은 매장 🟢
풀이
이런 류의 문제를 코드카타에서 너무 틀렸어서 방식이 기억났따
(간단한 줄 알고 그냥 무지성 작성하다가 틀린 경우가 많음)
-- 매장 2개 이상 지역
WITH cnt_store AS(
SELECT region_name
FROM stores
GROUP BY region_name
HAVING COUNT(store_id) >= 2
),
-- rank 구하기
rnk_sales AS(
SELECT region_name,
sales,
RANK() OVER(PARTITION BY region_name ORDER BY sales DESC) as rnk
FROM stores
WHERE region_name IN (SELECT region_name FROM cnt_store)
)
SELECT region_name, sales AS highest_sales
FROM rnk_sales
WHERE rnk = 1
ORDER BY region_name ASC -- 와 이거 안 넣어서 틀릴뻔~1️⃣ 해설
select region_name, max(sales) highest_sales
from stores
group by region_name
having count(store_id) >= 2
order by region_name 아니 이렇게 쉽게 푸실줄이야 🥲
문제 2 ) 장바구니 분석 🟢

풀이
- 처음 풀이
SELECT a.name AS name_x,
b.name AS name_y,
COUNT(DISTINCT a.cart_id) AS orders
FROM cart_products a
INNER JOIN cart_products b ON a.id = b.id
GROUP BY name_x, name_y -- 🔴
이름이 같은애들을 어떻게 중복제거하는지 모르겠어서 접었다
where a.name <> b.name 하면 될 줄 알았는데 안됐다
틀린 이유
해설 보니 group by 위 on절 뒤에서 <>하면 되는듯?
a.name > b.name도 가능
처음 풀때 순서를 잘못썼나보다
- 최종 풀이
SELECT a.name AS name_x,
b.name AS name_y,
COUNT(*) AS orders
FROM
(SELECT DISTINCT cart_id, name
FROM cart_products) a
JOIN
(SELECT DISTINCT cart_id, name
FROM cart_products) b
ON a.cart_id = b.cart_id
WHERE a.name <> b.name
GROUP BY a.name, b.name
ORDER BY a.name ASC, b.name ASC여기서는 WHERE절로 가능 name_x, name_y 하나씩 뽑으려고 쿼리 하나씩 만들고 묶어줌
2️⃣ 해설
참고) 셀프조인
🔗 QCC 3회차 - 3번
- 로직 파악하기
select a.id as a_id,
a.cart_id as a_cart_id,
a.name as a_name,
b.id as b_id,
b.cart_id b_cart_id,
b.name b_name
from cart_products a
join cart_products b
on a.cart_id = b.cart_id
and a.name <> b.name
where a.cart_id = 2
- 최종
select a.name name_x,
b.name name_y,
count(distinct a.cart_id) orders
from cart_products a
join cart_products b
on a.cart_id = b.cart_id
and a.name <> b.name
group by 1,2
order by 1,2문제 3 ) 결제버그 악용 찾기 🟢
풀이
얼마 전에 union 문제를 풀어서 기억해냈따...!
각 조건별로 쿼리 하나씩 작성하고 union으로 묶어서 중복인 유저 제거한 뒤에 셌다
SELECT COUNT(DISTINCT user_id) AS cnt
FROM
(
-- 결제가 먼저 주문이 다음
-- 결제 x 주문 o
SELECT o.user_id
FROM orders o
LEFT JOIN payments p ON o.user_id = p.user_id
WHERE p.user_id IS NULL
UNION
-- 결제일 이전 상품 주문
SELECT o.user_id
FROM orders o
INNER JOIN (
SELECT user_id, MIN(pay_date) AS first_pay
FROM payments
GROUP BY user_id
)p ON o.user_id = p.user_id
WHERE o.order_date < p.first_pay
)u3️⃣ 해설
with first_payment as(
select user_id, min(pay_date) first_payment_date
from payments
group by 1
)
select count(distinct o.user_id)
from orders o
left join first_payment fp
on o.user_id = fp.user_id
where fp.user_id is null
or order_date < first_payment_dateStandard 8회차
머신러닝 모델 고를 때 고려할 것들
- 예측 정확도
- 학습 속도 / 예측 속도
- 과적합 방지 능력
- 결측치 처리 가능 여부
- 카테고리 데이터 처리 능력
🌲 트리 기반 모델
의사결정나무 (Decision Tree)
- 스무고개처럼 질문을 통해 데이터 분류
- 예시)
Q1: 이 사람은 50대 이상인가요?
Q2: 혈압이 높은가요?
→ 예/아니오로 나눠가며 예측
- 예시)
앙상블(Ensemble)
- 여러 개의 의사결정나무를 결합해서 더 강한 모델을 만드는 기법
- 대표적인 모델 👉 XGBoost / CatBoost
🚀 XGBoost(eXtreme Gradient Boosting)
개념
- 부스팅(Boosting)
- 약한 모델들을 순차적으로 학습시켜 강한 모델로 만드는 방법
- 빠르고 정확
- 실무나 대회에서 자주 사용
특징
- 정형 데이터(숫자형/표 형식)에 강함
- 과적합 방지를 위한 정규화 기능 탑재
- 결측값이 있어도 자동으로 처리 가능
from xgboost import XGBClassifier
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score🐱 CatBoost(Category + Boosting)
개념
- Yandex에서 개발한 gradient boosting
- 범주형 데이터를 인코딩 없이 바로 사용 가능
특징
- 하이퍼파라미터를 많이 조정하지 않아도 좋은 성능
- 결측치도 자동 처치 가능
from catboost import CatBoostClassifier
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_scoreXGBoost VS CatBoost
| 항목 | XGBoost | CatBoost |
|---|---|---|
| 카테고리 처리 | 수동 - 인코딩 | 자동 |
| 결측치 처리 | 자동 | 자동 |
| 학습 속도 | 빠름 | 다소 느릴 수 있음 |
| 초보자 난이도 | 중간 | 쉬움 (튜닝 영향 적음) |
| 모델 해석력 | 중간(feature importance 제공) | 중간(feature importance 제공) |
XGBClassifier와CatBoostClassifier는 sklearn의fit,predict와 완벽하게 호환GridSearchCV또는RandomizedSearchCV로 하이퍼파라미터 튜닝 가능
하이퍼파라미터
모델이 학습할때 조정 가능한 설정값 / 적절한 조절 필요
공통
| 파라미터 | 의미 | 추천 범위 |
|---|---|---|
| n_estimators | 트리 개수 | 100~1000 |
| learning_rate | 학습 속도 | 0.01~0.3 |
| max_depth | 트리의 최대 깊이 | 3~10 |
XGBoost 전용
| 파라미터 | 의미 | 추천 범위 예시 |
|---|---|---|
| subsample | 각 트리마다 사용할 샘플 비율 | 0.5 ~ 1.0 |
| colsample_bytree | 각 트리마다 사용할 특성 비율 | 0.5 ~ 1.0 |
| gamma | 정보 획득이 얼마 이상일 때 분할 | 0 ~ 5 |
| reg_alpha | L1 정규화 | 0 ~ 1 |
| reg_lambda | L2 정규화 | 0 ~ 1 |
CatBoost 전용
| 파라미터 | 의미 | 추천 범위 예시 |
|---|---|---|
| depth | 트리의 깊이 | 3 ~ 10 |
| l2_leaf_reg | L2 정규화 | 1 ~ 10 |
| iterations | 트리 수 ( = n_estimators) | 100 ~ 1000 |
| bagging_temperature | 랜덤성 조절 | 0 ~ 1 |
| random_strength | 특성 선택 시 랜덤성 | 0 ~ 10 |
➕ 기타 설정
XGBoost
✅ use_label_encoder
- 기본값
True(구버전 호환성 유지)- 최근에는 deprecation warning이 나기 때문에 항상
False로 설정 하는 걸 추천
- 최근에는 deprecation warning이 나기 때문에 항상
XGBClassifier(use_label_encoder=False)CatBoost
-
범주형 데이터 있을 경우
fit()호출 시cat_features를 지정해야 함
= CatBoost한테 어떤 컬럼이 범주형인지 알려줘야 함 -
GPU 사용
기본적으로 CPU에서 작동
수천 개 이상의 샘플에서 GPU 사용 시 학습 속도 빨라짐
from catboost import CatBoostClassifier
model = CatBoostClassifier(task_type="GPU", devices="0", verbose=0task_type = "GPU" GPU 사용 명시
devices = "0" GPU 번호 지정 (멀티 GPU인 경우 "0:1" 가능)
☑️ 요약
XGBoost와CatBoost모두 기초 하이퍼파라미터는 비슷- CatBoost는 튜닝 없이도 성능이 괜찮은 편
- GridSearchCV는 학습시간이 길 수 있으니 범위를 좁혀서 시작
- 더 빠른 튜닝은
RandomizedSearchCV추천
어려운 개념이 나오면.. 믿음을.. 가져라..^^
왜 써야 하는지 이해하는 게 중요
만든 사람을 생각하면 토 달 수 없음
코드카타
SQL - 조건에 부합하는 중고거래 댓글 조회하기
SQL - 자동차 대여 기록 별 대여 금액 구하기
SQL - 상품을 구매한 회원 비율 구하기
SQL - Recyclable and Low Fat Products
SQL - Find Customer Referee
일기
- SQL
코드카타 75-78,72✅QCC 4회차✅ - 통계
전체 복습✅ - 머신러닝
기초강의 3강✅ - 수준별학습
스탠다드 8회차✅
오늘은 QCC가 있어서 sql 코드카타만 했고 머신러닝 기초강의가 실습이라 쭉 보기만 했따 파일 뜯어보는 건 월요일에 할 예정 ^^
이렇게 미루면 안되지만 오늘 QCC 만점 받았으니까 ㄱㅊ아 그걸로 충분해 👏 이제 주말이니까 푹 쉬어야쥐
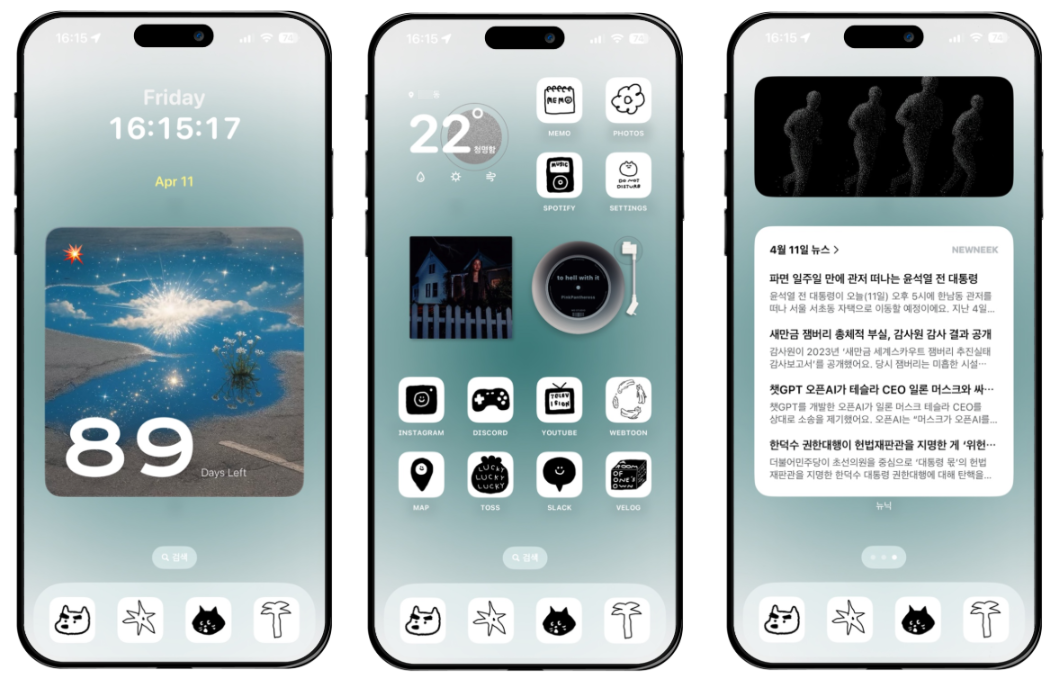
매우 귀여운 내 폰꾸 .. 자랑할 곳이 마땅치 않아 여기 풉니다 😶🌫️
공부하기 싫을때마다 뽀짝거렸더니 너무 재밌었어요..
한동안 이렇게 계속 유지할듯
💿오늘의 추천곡 The Marías - Only In My Dreams

나으 추천곡~ ~ 보컬이 몽롱하니 좋아서 한동안 빠졌었따

이런 걸로도 깔깔대는 꽃다운 나이 서른하나 ^^~~깔~!@..$깔..

폰꾸 넘 느낌있좌나!@! 아니 수2님 TIL왤케잘쓰지 웃기고 유익해 젠장 본받는다