
개인스터디
실무에 쓰는 머신러닝 기초 5강
* 머신러닝
├── 지도학습
│ ├── 분류 (Classification)✅ → KNN, 로지스틱 회귀, SVM
│ └── 회귀 (Regression) → 선형회귀, Lasso, Ridge
│
├── 앙상블
│ ├── 배깅 (Bagging) → Random Forest
│ └── 부스팅 (Boosting) → XGBoost, LightGBM, CatBoost
│
├── 비지도학습
│ ├── 군집 (Clustering) → K-means, DBSCAN
│ ├── 차원축소 (Dim. Reduction) → PCA, t-SNE
│ └── 이상탐지 (Anomaly Detection) → One-Class SVM, Isolation Forest
│
└── 강화학습 (Reinforcement) 🔷 분류
데이터가 어떤 클래스에 속하는지 예측
- 예시:
- 스팸 메일 여부
- 질병 진단 (양성/음성)
- 품질 검수 (불량/정상)
로지스틱 회귀 (Logistic Regression)
선형 회귀 + 시그모이드 함수 → 확률(0~1)로 출력
- 장점: 빠르고 해석 쉬움
- 단점: 복잡한 비선형 패턴은 학습 어려움
classification_report()로 정밀도, 재현율, F1-score 확인
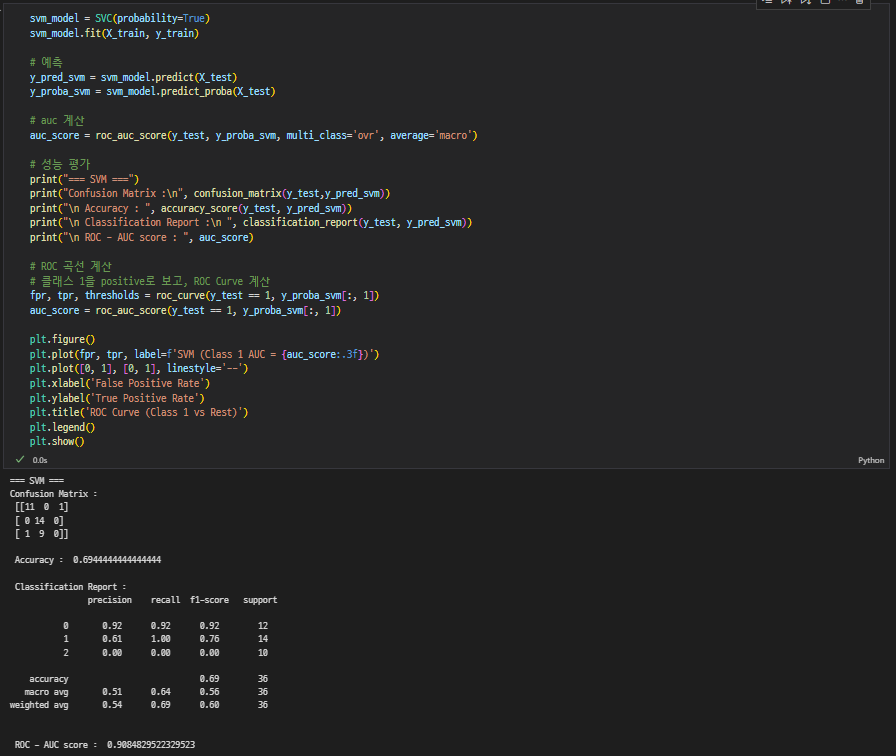
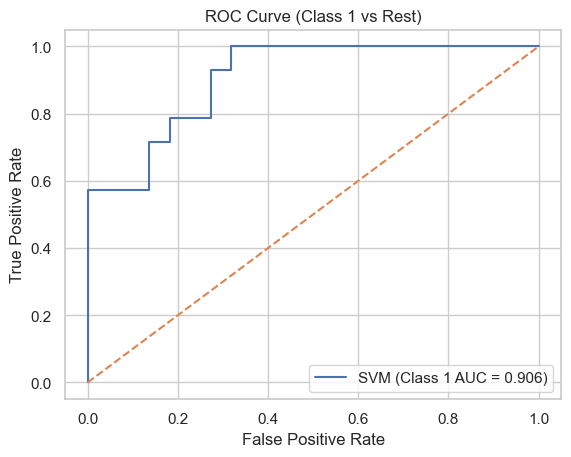
SVM (Support Vector Machine)
가장 넓은 여유공간을 가진 결정 경계를 찾는 방식
- 커널(필터)를 통해 좋은 성능을 보임
- 장점: 고차원에서도 성능 우수
- 단점: 파라미터 튜닝 필요, 느린 학습
기타 분류 알고리즘
| 모델 | 개념 | 특징 |
|---|---|---|
| KNN | 가장 가까운 이웃(K개)을 보고 다수결로 분류 | 단순하지만 계산량 큼 |
| Naive Bayes | 확률 기반 + 특성 간 독립 가정 | 빠르지만 독립성 가정 |
| MLP / 딥러닝 | 여러 층의 뉴런으로 구성된 비선형 모델 | 복잡한 패턴 학습 가능 |
🔷 분류모델 평가지표
혼동 행렬 (Confusion Matrix)
| 예측 Negative | 예측 Positive | |
|---|---|---|
| 실제 Negative | TN | FP |
| 실제 Positive | FN | TP |
핵심 지표
| 지표 | 정의 | 상황 |
|---|---|---|
| 정밀도 Precision | TP / (TP + FP) | 잘못 Positive 예측 줄이기 (ex: 스팸 필터) |
| 재현율 Recall | TP / (TP + FN) | 놓치지 않기 중요 (ex: 질병 진단) |
| F1-score | 조화 평균 | Precision, Recall 균형 필요할 때 |
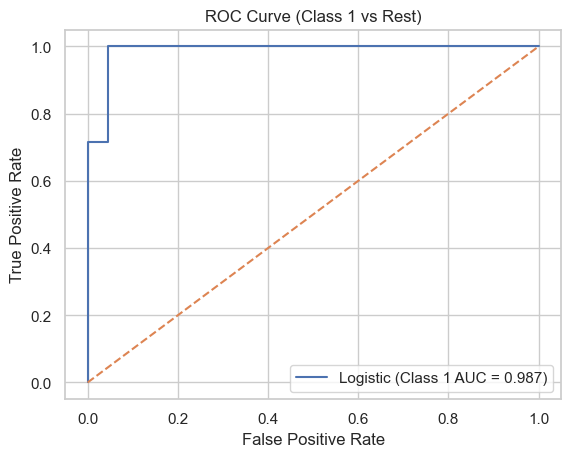
ROC-AUC
- ROC Curve: TPR(재현율) vs FPR의 관계 시각화
- AUC: ROC 곡선 아래 면적 (1에 가까울수록 좋음)
⚠️ 불균형 데이터일수록 ROC-AUC 또는 F1-score 같이 다른 지표도 꼭 함께 확인!
☑️ 요약
- 로지스틱 회귀: 확률 기반, 해석 쉬움
- SVM: 마진 기반, 성능 좋음
- 정확도 외에도 Precision, Recall, AUC 등 지표 함께 고려
☑️ Q&A
| 질문 | 요약 답변 | 설명 |
|---|---|---|
| 분류 vs 회귀 모델 차이 | 출력 형태 차이 | 회귀는 연속적인 수치 예측, 분류는 범주(class) 예측 |
| 정확도만으로 평가하면 안 되는 이유 | 불균형 데이터 문제 | 예: 정상 99%, 불량 1%면, 전부 정상이라 예측해도 정확도 99% → 실제 성능 왜곡 |
| 극단적 불균형 데이터 대응 방법 | 데이터 재구성 및 적절한 지표 활용 | SMOTE, 언더샘플링, 클래스 가중치 조정, 평가지표로는 Recall, Precision, ROC-AUC, PR곡선 사용 |
실습
다음 안내에 따라 Wine 데이터를 분류하는 실습을 진행해 보세요.
[실습안내]
- Wine 데이터셋을 로드하세요.
- 학습용/테스트용 데이터를 적절한 비율로 분할하세요.
- Logistic Regression, SVM 모델을 생성하고, 모델을 학습시키세요.
- 적절히 하이퍼파라미터(예:
max_iter등)를 설정해볼 것- 테스트 데이터를 이용해 예측을 수행하고, 다음을 구하세요.
- 정확도(Accuracy)
- 분류 보고서(Classification Report)
- 혼동행렬(Confusion_matrix) → 선택사항
- 참고!) sklearn의 confusion matrix는 아래와 같은 형태로 나온다는 점을 참고하세요!

- ROC, AUC
- random_state를 설정해야 하는 경우가 있으면 42로 설정
- 데이터셋 로드
- EDA
-
shape

-
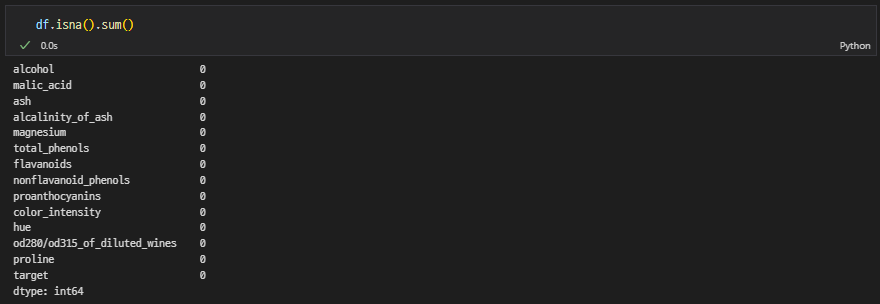
결측치 확인
-
컬럼 정보 확인
-
데이터 분할

-
로지스틱회귀
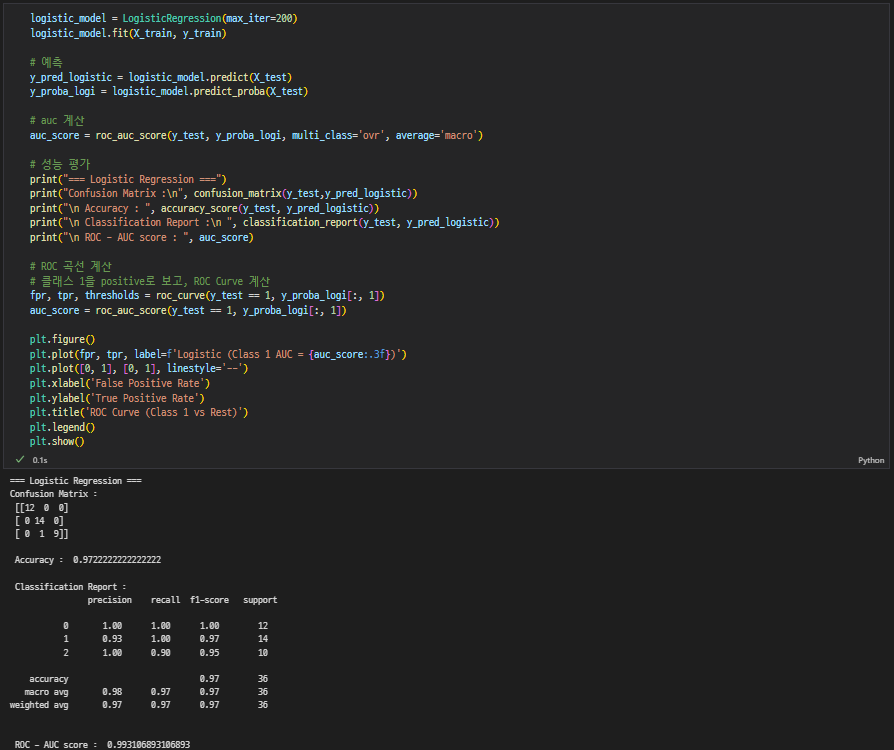
- SVM
❓ 다중분류인 경우 roc-auc score 계산
예시가 이진분류로 되어있어, 그대로 사용할 수가 없어서 이진분류로 변환을 해 준 뒤에 계산을 해야하는 건지 여쭤봤다!
# macro-average
roc_auc_score(y_true, y_score, multi_class='ovr', average='macro')auc를 계산할때 이진분류여야 하는데, 다중일때는 multi_class = 'ovr'로 계산 가능
-
ovr= one vs rest- a vs bc
- b vs ac
- c vs ab
-
ovo= one vs one- a vs b
- a vs c
- b vs c
어떤 방법을 선택하든 상관없지만, ovo방식은 하나씩 비교하는 거다 보니 시간이 더 오래 걸림!
실무에 쓰는 머신러닝 기초 6강
* 머신러닝
├── 지도학습
│ ├── 분류 (Classification) → KNN, 로지스틱 회귀, SVM
│ └── 회귀 (Regression) → 선형회귀, Lasso, Ridge
│
├── 앙상블✅
│ ├── 배깅 (Bagging) → Random Forest
│ └── 부스팅 (Boosting) → XGBoost, LightGBM, CatBoost
│
├── 비지도학습
│ ├── 군집 (Clustering) → K-means, DBSCAN
│ ├── 차원축소 (Dim. Reduction) → PCA, t-SNE
│ └── 이상탐지 (Anomaly Detection) → One-Class SVM, Isolation Forest
│
└── 강화학습 (Reinforcement) 앙상블 기법
여러 개의 모델 조합 → 더 좋은 예측 성능
- 서로 다른 관점(모델)을 결합함으로써 오류를 줄임
- 개별 모델의 편향과 분산 상호보완
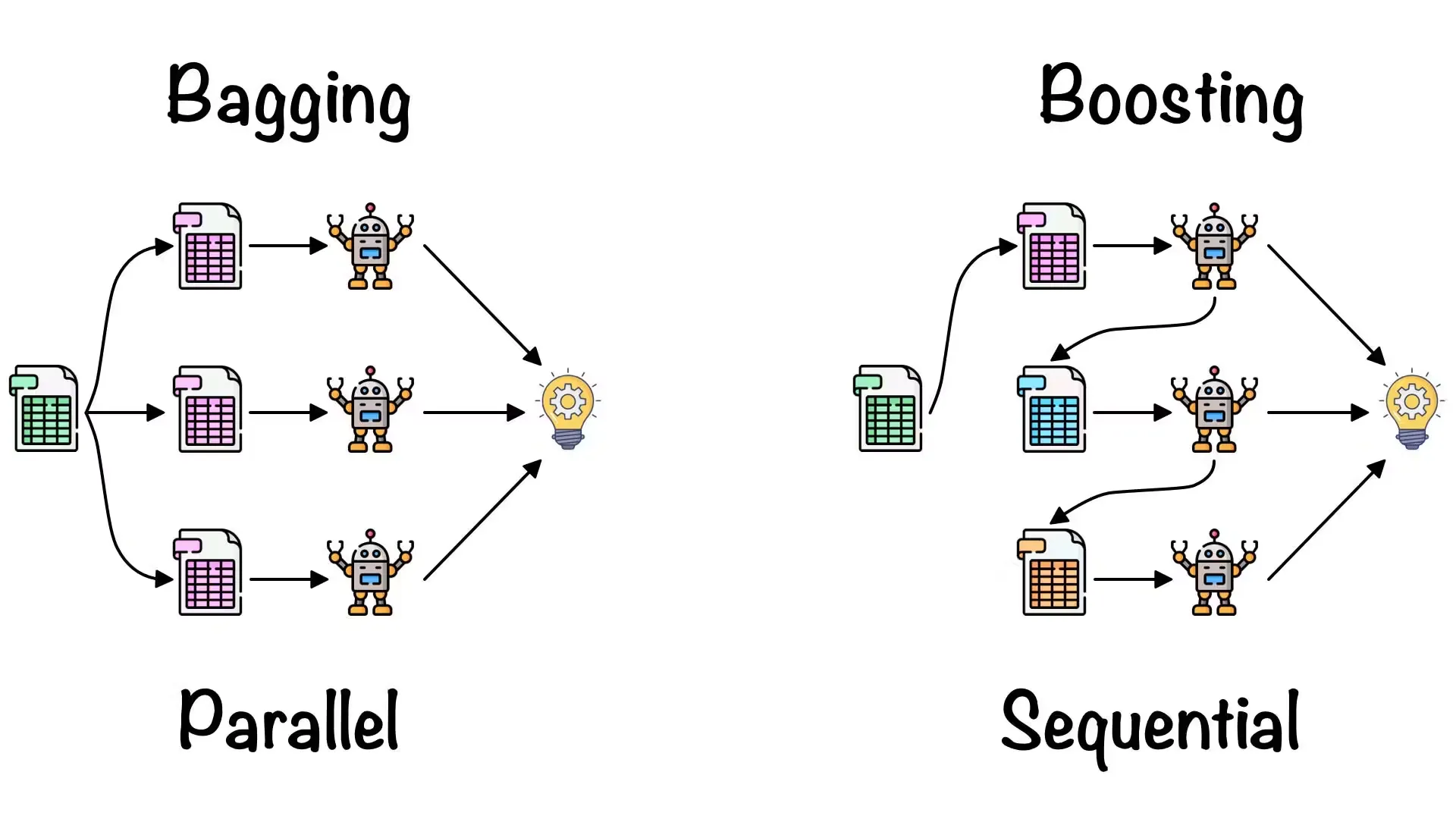
배깅 (Bagging)
병렬 학습 → 평균/다수결 예측
-
장점: 과적합 감소, 안정적, 병렬 처리 가능
단점: 메모리 사용량 증가, 해석 어려움 -
대표) 랜덤 포레스트(Random Forest) - 분류, 회귀 모두 가능
- 결정 트리 여러 개 > 무작위 피처 샘플링 + 데이터 샘플링
- 라이브러리
RandomForestClassifier
부스팅 (Boosting)
순차 학습 → 이전 오류 보정
- 장점: 높은 성능, 정교한 학습
단점: 느림, 튜닝 어렵고 과적합 위험 - 대표) XGBoost, LightGBM, CatBoost - 분류, 회귀 모두 가능
XGBClassifierLGBMClassifierCatBoostClassifier- ❗Catboost의 경우 범주형 인코딩 필요 없음
과적합 vs 과소적합
과적합 (Overfitting)
일반화가 안 됨
- 학습 데이터엔 정확하지만, 테스트 성능 낮음
- 원인
- 학습 데이터 수가 충분하지 않음
- 파라미터(자유도)가 너무 많아서 복잡도 과다
- 너무 많은 에폭(딥러닝 등)으로 학습
- 노이즈가 많은 훈련 데이터에서 패턴을 과하게 학습
- 해결방법
- 규제, 드롭아웃, 데이터 증강, 조기 종료, 앙상블
과소적합 (Underfitting)
학습이 안 됨
- 학습 데이터조차 충분히 맞추지 못함
- 해결방법
- 모델 복잡도 증가, 더 오래 학습, 모델 구조 변경(더 깊은 신경망, 더 많은 트리 등)
하이퍼파라미터 튜닝
-
사람이 지정하는 설정값 (예: 트리 깊이, 학습률 등)
GridSearchCV: 모든 조합 시도→ 정확하지만 느림RandomizedSearchCV: 일부 조합 랜덤 → 빠름Bayesian Optimization: 효율적으로 탐색
추가개념
최적화
- 하이퍼파라미터 튜닝
- 피처 엔지니어링
- 과적합 방지
배포
- 학습 완료 모델을 운영 환경에 배포
- API 서버 구축, 클라우드(AWS, GCP) 또는 엣지 디바이스(임베디드 환경)
- 지속적 모니터링으로 모델 성능이 저하될 경우 재학습 주기 설정
MLOps(머신러닝 운영)
- Machine Learning + DevOps
- 머신러닝 모델 개발부터 배포, 모니터링, 재학습, 롤백(Rollback) 등 전 과정을 자동화하고 효율적으로 운영하는 방법론
- 프로젝트 완성
모델 해석 가능성(Explainable AI, XAI)
- 딥러닝은 블랙박스 → “왜 이런 결과 나왔는지” 설명 필요
- 의료, 금융 등 규제 산업에서 중요
- 주요기법
- Feature Importance 시각화(트리 기반 모델)
- LIME(Local Interpretable Model-agnostic Explanations)
- SHAP(Shapley Additive Explanations)
☑️ 요약
- 앙상블 배깅 / 부스팅 → 성능 향상
- 과적합 vs 과소적합 : 과적합 해결이 더 어렵다
- 과적합 : 복잡도 높음 → 정규화, 드롭아웃, 조기 종료, 데이터 증강 등으로 대응
- 과소적합 : 복잡도 낮음 → 모델 파라미터 수 늘리기, 학습 기간(에폭) 늘리기
- 하이퍼파라미터 튜닝 모델 성능 최적화
- Feature Importance 트리기반 모델 해석 가능
☑️ Q&A
| 질문 | 요약 답변 |
|---|---|
| 배깅 vs 부스팅 | 병렬 vs 순차, 분산 감소 vs 편향 보정 |
| 로지스틱 vs XGBoost | 빠르고 해석 vs 성능 좋고 복잡 |
| 앙상블 언제? | 복잡한 데이터 + 고성능 요구 시 |
| 과적합 판단? | 훈련 정확도 높고 테스트 낮으면 의심 |
| Grid vs Randomized | 후보 적으면 Grid, 많으면 Randomized |
| 학습률(learning_rate)? | 작음 → 안정적, 큼 → 빠르지만 불안정 |
실습
- 유방암 데이터셋을 사이킷런에서 불러오세요.
- 학습용/테스트용 데이터로 분할하세요.
- XGBoost 분류 모델을 생성하여 학습하세요.
random_state를 지정해야 하는 경우 42로 지정하세요.- 테스트 세트로 예측을 수행하고, 정확도(Accuracy), 혼동 행렬(Confusion Matrix), 분류 보고서(Classification Report) 등을 구해 성능 평가를 하세요.
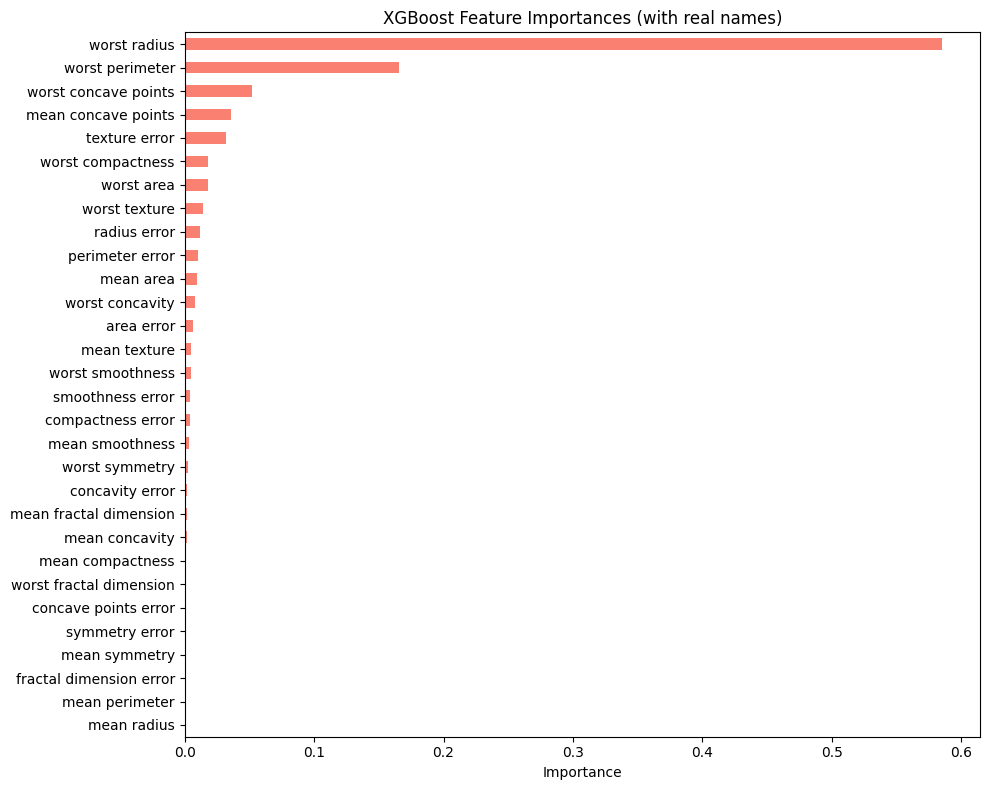
- 피처 중요도를 시각화한 뒤, 그중 가장 중요한 변수가 무엇인지 찾아 출력하십시오.
-
데이터셋 로드
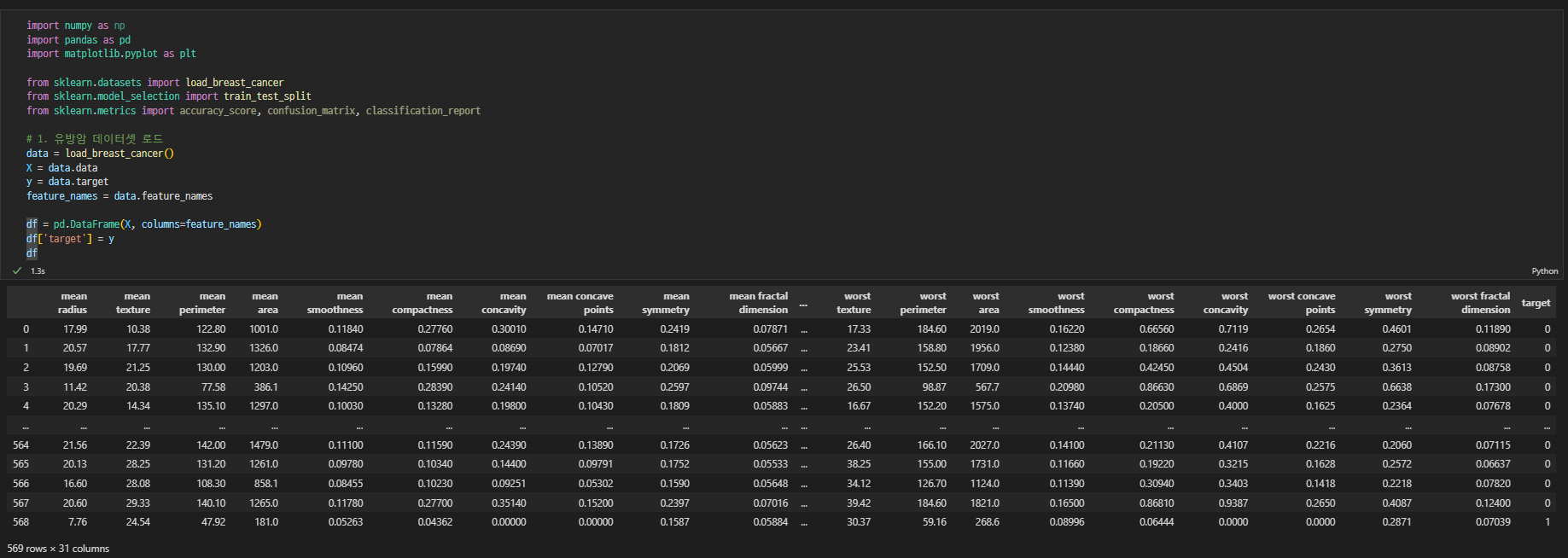
-
EDA
-
shape

-
결측치 확인
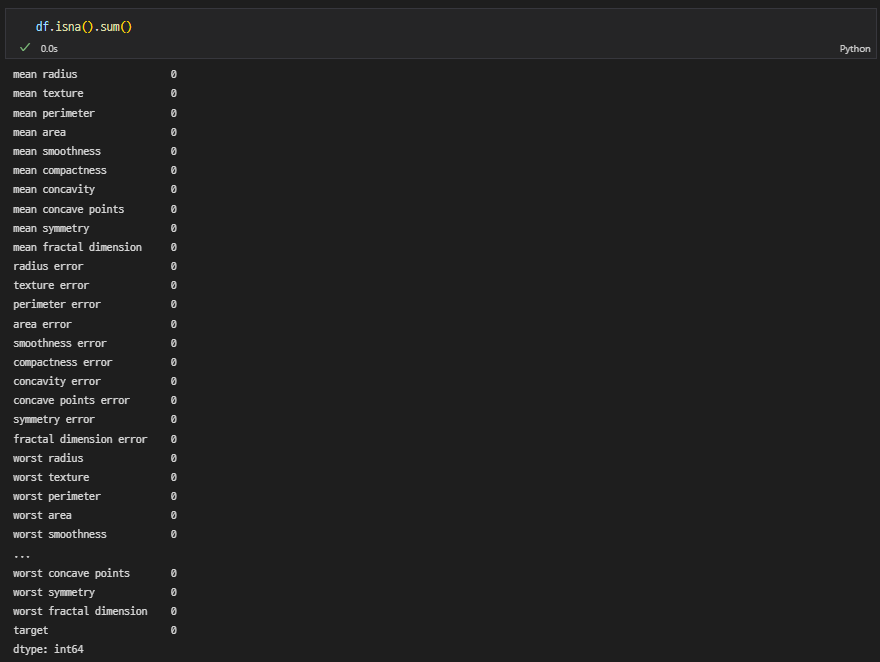
-
컬럼 정보 확인
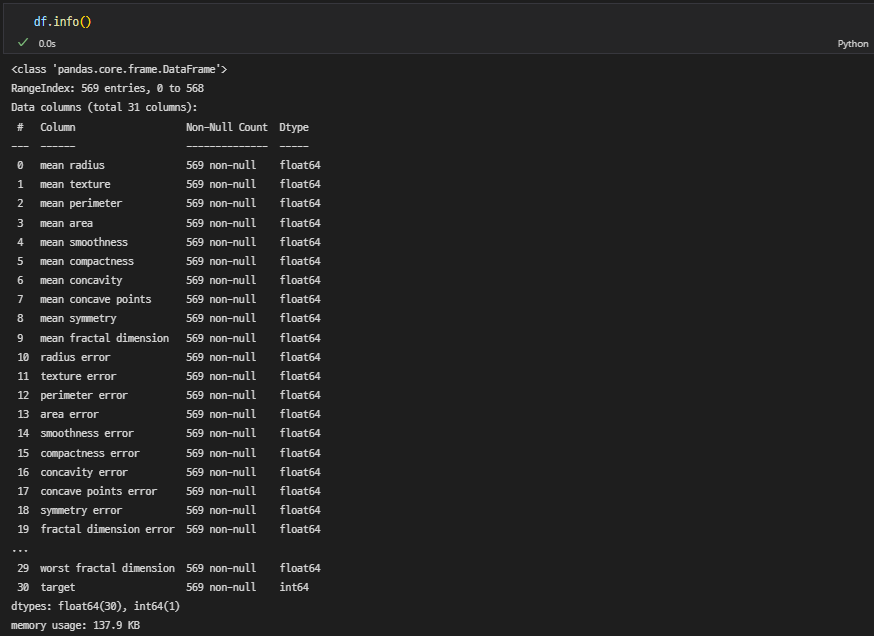
-
데이터 분할

-
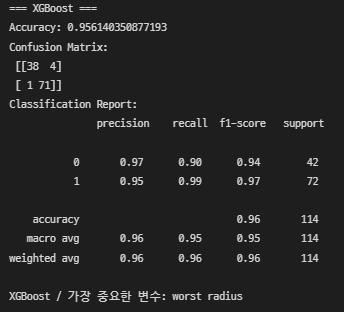
XGBoost
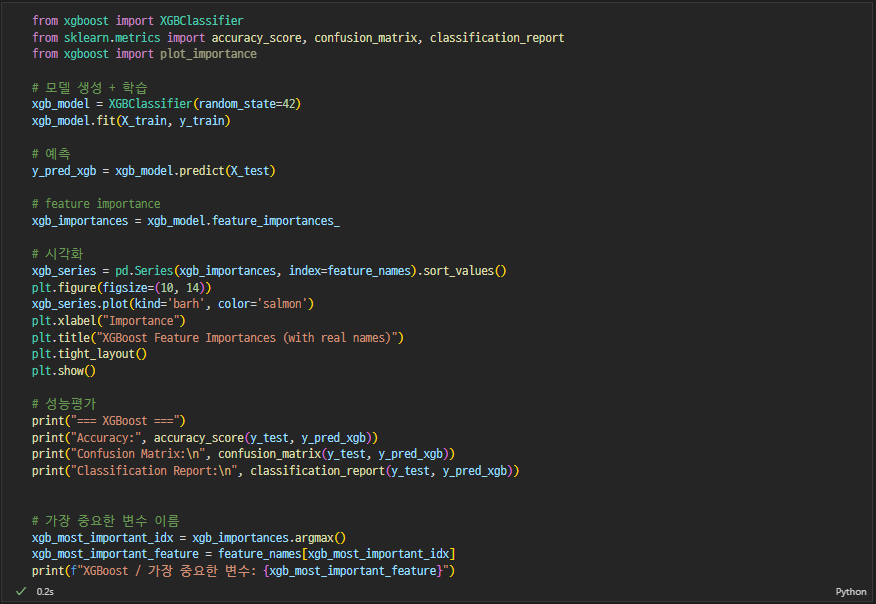
-
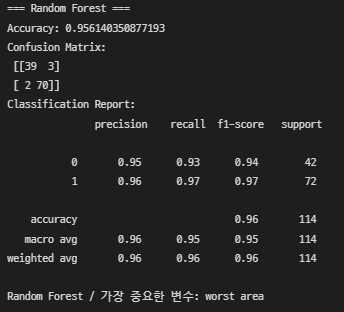
Random Forest
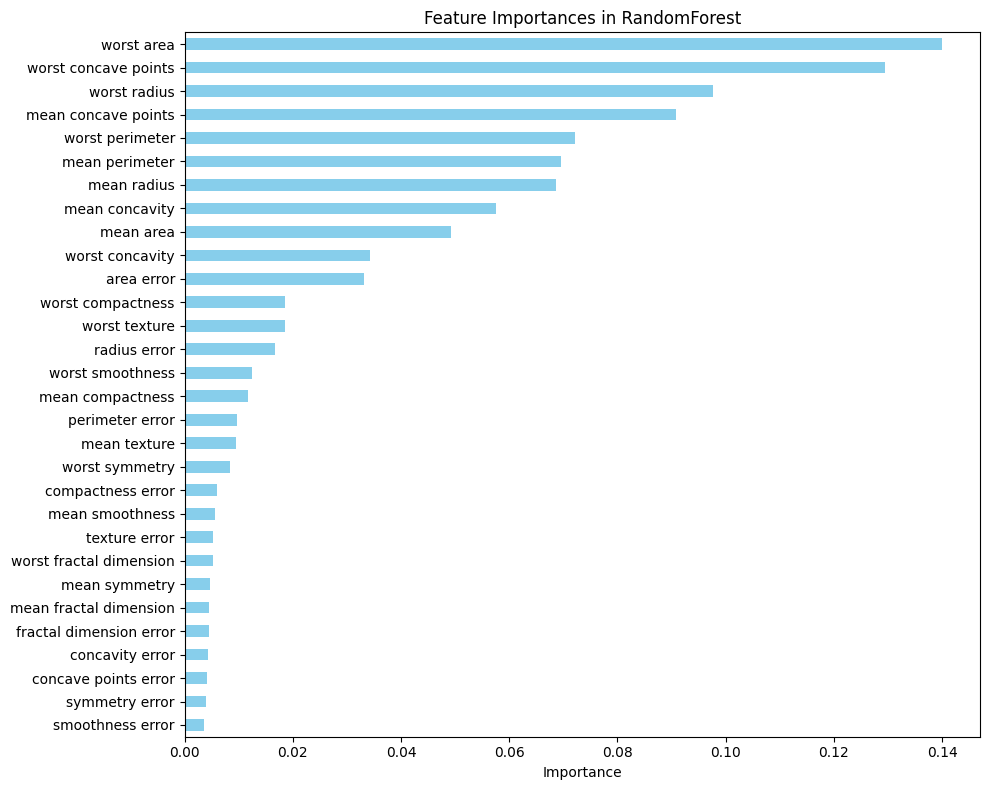
-
종합
XGBoost → worst radius(종양 반지름)
Random Forest → worst area(종양 면적)
- 두 가지 모델 비교해봤을때 결국 종양 크기가 유방암에 영향을 미친다
- 유방암 진단 데이터니까 재현율이 더 중요 → XGBoost 채택
코드카타
SQL - Customer Who Visited but Did Not Make Any Transactions
SQL - Product Sales Analysis I
SQL - Replace Employee ID With The Unique Identifier
Python - 숫자 문자열과 영단어
Python - 시저 암호
일기
- SQL
코드카타 82-84 ✅ - Python
코드카타 45-46 ✅ - 머신러닝
특강 2-3회차 ✅기초강의 5-6강 ✅기초강의 7강❌
이제는 더이상 물러날 곳이 없어서.. 머신러닝 6강까지 끝냈다..
세션 하루에 4시간 들으니까 너모 힘들고요 네..
그래도 오늘 현지 튜터님 첫 수업이었는데 흐름을 쭈욱 따라가면서 하는 방식이라 너무 좋았다!
수업 중에 다항회귀 모델이랑 단순회귀 모델은 항상 같이 쓰는 건지 질문했는데, 항상 그렇지는 않다고 답변을 받았다! 근데 정훈님이 슬랙으로 그거 물어본 거 아니지 않냐고 연락을 주셔서, 덕분에 다시 튜터님한테 여쭤보고 확인할 수 있는 기회가 생겼다😀
모델 사용이 아니라 개념적인 부분에서 답변을 해주신 거였다
정훈님도, 튜터님도 매우매우 감사합니다~~
내일은 머신러닝 꼭 끝내야지.. 프로젝트 시작 전까지 파이팅🍀
💿오늘의 추천곡 BROCKHAMPTON - Sugar

아무리 노래 앱을 옮겨도 애착인형 마냥 플리에 박혀있는 곡 ,,🤣
요즘도 생각날때마다 종종 들어서 추천해봤따
