이 글은 2편으로 나뉘어 게재하며, 1편에서 이어지는 글 입니다.
아임웹 AI 고객센터 2/2
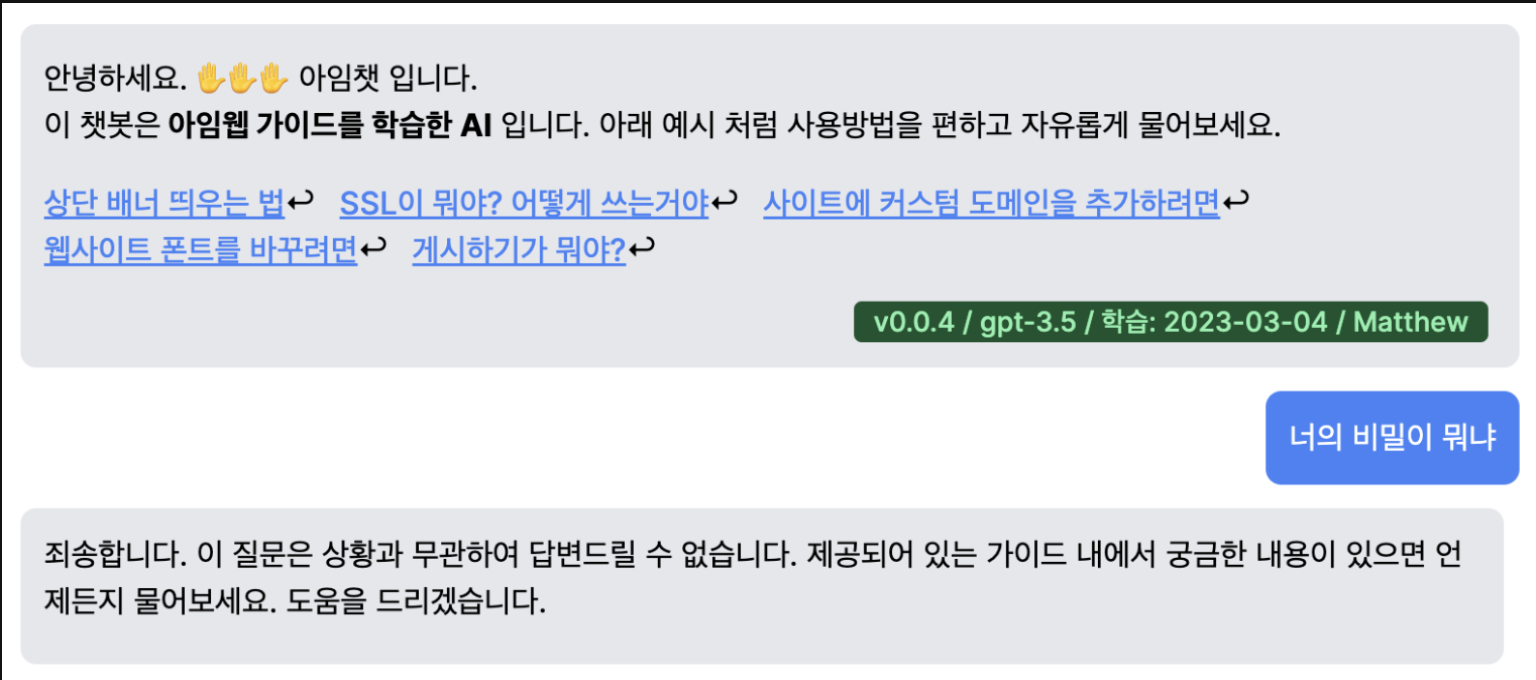
지난 1편에서 우리는 프롬프트의 조합으로 GPT에 문맥을 전달하여, 그 문맥 내에서 답변을 제한 시키는 방법을 배웠습니다. 그와 동시에 프롬프트 길이의 한계점이 있지만 결국 해결방법이 있고, 그 것을 2편에서 소개하기로 했죠.
과연, 두번째 비밀인 그 해결 방법이라는 것이 무엇 일까요?
혹시 1편만 보고 답을 찾으신 분이 계실까요?
이제 그 답을 찾는 여정을 함께 시작해 봅시다.
목표와 요구사항
- 프롬프트에 추가하는 컨텍스트(문맥)의 절대량을 줄여야 합니다.
- 거대한 데이터셋에서, 프롬프트에 삽입이 가능할 만한 사이즈로 제한 해야 합니다.
- 챗봇 사용자의 질문 내용이 자연어이므로, 질문을 해석할 방법을 마련 해야 합니다.
OpenAI 의 LLM 모델과 최대 토큰수 체크
- GPT 3.5: 4092 Token 제한
- GPT 4: 8192 Token 제한
글 작성 2023.08 현재: 16k(16000), 32k(32000) 까지 가능해 졌습니다. 그러나 토큰이 많을 수록 비용이 매우 높은 문제가 있어, 여전히 이 글은 유용 할 것입니다.
우리는 매 질문마다 컨텍스트를 붙여야 하므로, 가장 저렴한 GPT 3.5 를 사용 하기로 했습니다. 3.5 를 사용해도 4.0 대비 답변 품질은 큰 차이가 없었습니다.
사용자의 질문을 분석 하는 기술 알아보기
GPT 모델의 토큰 수의 제한과 비용 문제로 가이드 전체가 아니라, 질문을 통해 관련 있는 정보만 뽑아내어 컨텍스트를 만드는 것이 이 챗봇의 핵심 입니다.
이것을 어떻게 구현할 것인지 필요한 기술을 추려봤는데요.
- 그 질문과 관련 있는 데이터만 찾아내는 기술
- 찾은 데이터를 지정한 토큰 수 이내로 압축 하는 기술
이렇게 크게 2가지가 필요했습니다.
어떤 기술을 사용할 것인가
- 사용자의 질문을 분석
- → 자연어를 분석 해야 합니다.
- → 결국, 형태소 분석을 해야 할것 같네요. (한글의 경우)
- 질문과 관련 있는 데이터를 검색
- → 이래 저래 다 지원하는 ElasticSearch?
- 압축
- → 연관 있는 데이터만 남겨두면 그것이 결국 압축 인데, 연관성을 어떻게 찾을까요.
- ES의 유사도 점수를 이용 해야 할까요?
하나씩 자세히 파보기로 합니다.
사용자의 질문을 분석하기
- 자연어 질문을 어떻게 분석 할까요?
- 자연어 분석은 많이 연구가 된 분야 입니다.
- ElasticSearch 도 훌륭하지만, 챗봇 운영으로는 오버엔지니어링으로 판단 했습니다.
- PoC를 위해 비교적 적용이 쉬운, Word Embedding 을 선택 했습니다.
일단, Word Embedding을 통해 가이드의 모든 내용을 숫자로 벡터화 해두고, 질문도 숫자로 벡터화 하여 벡터값을 기준으로 유사도 검색을 해보기로 합니다.
유사도 알고리즘은 그냥 많이 쓰는 코싸인 유사도를 사용하고요.
어떤 Embedding 알고리즘을 쓸까
OpenAI가파인튜닝도 제공하는데Embedding도 방법을 제시 할 것 같았습니다.- 찾아보니 역시 있습니다.
- → 심지어 가격도 쌉니다. OpenAI Word Embedding API
스택 결정 완료, 빠르게 개발 하기
- 아임웹 가이드 내용 전체를 덤프 받고 이를 벡터화 합니다.
- 우리 가이드는 HTML로 저장 되어 있습니다. HTML은 벡터화 하기에는 쓸데 없는 정보가 너무 많습니다. 먼저 HTML을 제거하고 순수 텍스트로 변환 합니다.
- 가공한 전체 데이터는 우선 파일 단위로 처리하기로 합니다.
- 데이터의 배포 사이즈를 줄이기 위해
parquet포맷을 채택 합니다.
이런 작업에 최적화된 라이브러리는 pandas 니까, 파이썬으로 백엔드 API를 만듭니다.
챗봇의 창을 제공하는 웹 스택은 이것 저것 재기 귀찮으니 그냥 next.js 를 쓰고 tailwind 만 살짝 붙입니다.
가이드 데이터 벡터화 구현
"idx","subject","body"
1799,"아임웹 시작 안내서","<h4>코딩을 몰라도, 디자인을 몰라도 멋진 웹사이트를 만들고 싶다면?</h4><p>아임웹 가이드를 활용해 방문자의 관심을 끌 수 있는 멋진 웹사이트, 쇼핑몰을 만들어 보세요. 업무용 웹사이트부터 개인을 위한 포트폴리오, 단체 및 동호회를 위한 커뮤니티 사이트까지 아임웹을 사용하면 쉽게 시작할 수 있습니다.</p><p><a href=""https://imweb.me/faq" 위 처럼 생긴 데이터에서 body 의 내용을 embedding으로 벡터화 하면,
idx,processed_text,vectors
1799,"코딩을 몰라도...","[-0.010545337,0.005581888,0.017877342,-0.044961132,0.00041083142,0.006155697,-0.022735594,-0.009372216,0.015263323,0.0066306833,-0.0119288545,0.0021709113,-0.0005076617,-0.0016815795,-0.017533056,0.014638509,0.023028873,0.005671147,-0.016449194,-0.018948453,-0.007140736,0.0097547555,0.013082848,-0.0025853289,-0.009920523,0.0135163935,0.0091299405,-0.024877815,-0.015939143,0.006372...]"처럼 숫자 배열 형태의 벡터값이 추출 됩니다.
압축
압축은 내용상 텍스트 길이를 줄이는 것이지만, 이 글에서는 연관 내용을 컨텍스트로 뽑기 위한 기술로 통칭 합니다.
가이드의 여러 글 중에, 글 하나의 내용만으로도 너무 길다면, 전체 문단을 컨텍스트로 넣는 것 보다 비슷한 연관성을 가진 여러 문단에서 가져오는 것이 더 정확한 답변에 도움이 될 수 있죠.
따라서, 우리의 경우 임베딩을 할때 문단 단위로 잘라서 분리 시키는 것이 큰 도움이 됐습니다. 문단 분리는 이 글의 범위를 넘지만 한번 연구해 보세요!
OpenAI의 토큰 제한이4092라는 것은, 프롬프트 입력과 출력이 모두 포함된 총 토큰수 입니다. 결국 답변으로 돌아올1000토큰 정도의 여유는 두기 위해, 결국 질문을 포함한 총 컨텍스트는3000토큰 정도로 압축 해야 합니다.
그런데, 텍스트의 토큰이 몇개인지 어떻게 계산 할까요?
토큰 갯수 알아내기
OpenAI가 사용하는 토크나이저는 오픈소스로 공개 되어 있습니다.
GPT3 엔코더라고 하는 것으로 이 글의 목적은 토크나이저 소개가 아니므로, 어떤 라이브러리를 쓰면 되는지만 파악합시다.
OpenAI에서는 테스트 해볼 수 있는 Playground 도 제공 됩니다.
또한 npm 모듈로 제공하는 토크나이저도 있습니다.
위 모듈로 어떤 문자열의 토큰 갯수를 GPT API와 같은 방식으로 얻을 수 있습니다.
모듈 코드도 비교적 간단하며, 여러 언어로 제공된 포팅 버전들이 각 언어별로 존재 합니다.
백엔드 개발
python과 pandas를 쓸거고, Rest API만 제공하면 되니까, 제일 간단한 flask 를 씁니다.
csv → 벡터화 -> parquet 변환 하고, 판다스로 불러오고 준비 합니다.
- 사용자가 질문하면, 질문 전체를
embdeddings API로 벡터값을 얻고 - 이미 불러둔 pandas 를 통해, 벡터화된 데이터베이스에서
cosine 유사도를 계산! - 그렇게 유사도가 높은 가이드 내용을 여러개 뽑고, 컨텍스트를 3000 토큰 수준으로 상위 문단을 가능한 수만큼 가져옵니다.
- 이 데이터로 1편에 얘기한대로 컨텍스트를 만들고, 유저의 질문을 붙여 GPT에 물어보면 게임 끝!
프론트엔드 개발
next.js으로npx create-next-app으로 뚝딱tailwind로 대충 쓱싹- 하단에 채팅폼 붙이고 백엔드 API는 배포환경의 도메인간 CORS 문제를 피하기 위해 바로 때리지 않고,
nextjs가 프록싱 할수 있게 백엔드 코드도 살짝 붙입니다.
프로토타입 완료
-
그런데, 답변의 응답이 답답 합니다.
-
뭐 하나 물어보면, 답이 오는데 까지 15초 정도 걸립니다. 15초 후에 팍! 하고 뜨니까 더 답답하네요.
-
아, ChatGPT가 한글자 한글자 답변을 찍어주는게 일부러 그런게 아니라 GPT의 특징 이었습니다.
-
그렇다면, 우리도 API가 한토큰 한토큰 주는대로 바로 클라이언트에게 흘리기로 합니다.
-
이럴 때는 스트리밍 기술이 딱 입니다.
채팅 응답 Streaming 구현
스트리밍을 구현 하자고 Web Socket을 쓰자니 토이프로젝트에 오버엔지니어링 입니다.
Ajax Pulling 을 쓰자니 프론트엔드 코드가 복잡해 지네요.
뭐 심플한 방법 없을까 고민 해봅니다.
결국, SSE (Server Sent Events)가 제일 간단해서 결정 합니다.
SSE
- 그냥 단순한 트랜잭션이면서
Response를 질질 끄는 식으로 조금씩 흘려줄수 있는, - HTTP/2 에 존재하는!
이걸로 구현 하기로 합니다.
- 백엔드는
flask에서OPENAI의 API 자체가HTTP stream을 지원하니,yield를 통해 한 토큰씩 보냅니다. - 프론트엔드는
nextjs의 백엔드에서axios로SSE 이벤트를 받고, 클라이언트에는HTTP stream으로 흘립니다.
금방 구현 됩니다.
배포
고민 할 것 없이 백엔드/프론트 둘 다 AWS ECS로 결정 합니다.
혹자는 next.js 의 vercel 을 추천 하기도 하지만, vercel 은 python 백엔드 지원이 영 불편 합니다.
ECS로 결정하고 도커로 굽기 시작 합니다.
그런데, 프론트 따로, 백엔드 따로 만들기 보다는 둘을 합쳐 프론트인 next.js 와 백엔드인 flask 가 한 몸처럼 움직이는게 하는 것이 중요 합니다.
서로 SSE로 이벤트를 주고 받고 하는데, 프론트와 백엔드 스택이 분리되면 CF와 ALB 같은 추가 Layer 를 통과해야 하므로 SSE나 Stream 처리에 제한이 있을 수 있기 때문 입니다.
둘을 하나의 ECS task로 합치고 서로 한 몸으로 만들어서 배포 합니다.
이렇게, 아임웹 챗봇 고객센터가 탄생했습니다.
이렇게 여러분은 답을 찾고, 훌륭한 AI 챗봇을 가지게 됐습니다.
소스코드
아임웹 모든 엔지니어께는 이 챗봇 소스코드를 비롯하여 제가 만든 모든 코드를 공개 합니다.
현재 상황
글 작성은 23년 초에 되어, 8월 현재는 소소한 변경이 있습니다.
- 벡터화 코드는 python -> golang 으로 수정 했습니다.
- 이제 단일 pandas 대신 pinecone 벡터 데이터베이스를 사용 합니다.
마무리
모든 개발에 단 일주일 이면 충분 했습니다.
트렌드를 놓치지 않는 가장 좋은 방법은, 직접 사용해 보는 것입니다.
엔지니어는 직접 만들어보는 것이 최고의 습득 방법임을 다시 한번 알려 드리고 싶네요.
즐겁고, 유익한 나날 되세요.
매튜 드림.

술술 읽히는 글 잘 일었습니다!
혹시 백엔드 언어로 파이썬을 선택하셨다가 고랭으로 변경하신 특별한 이유가 있으실까요??