
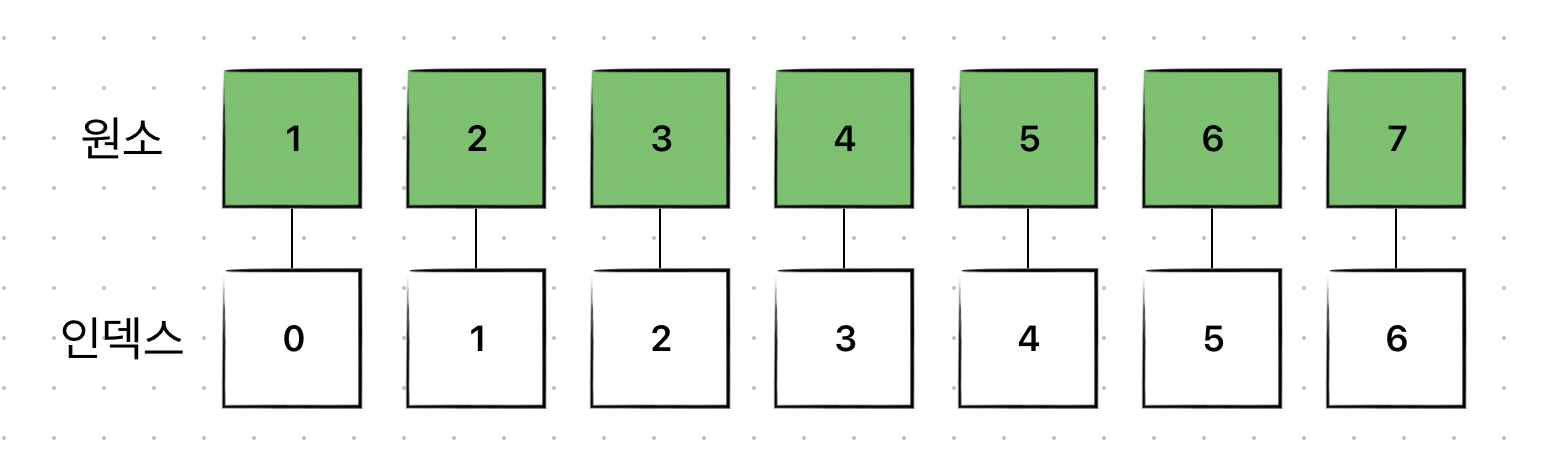
배열 (Array)
배열은 정적 자료구조이다.
여기서 정적이란? 메모리 공간에 미리 사이즈를 할당한다는 의미이다.
즉, 배열은 메모리 공간에 미리 사이즈를 할당한 후 사용하는 자료구조이다.
(자바의 경우에는 int[] array = new int[5] 와 같이 선언한다.
여기서 []안의 5가 미리 할당하려는 사이즈를 의미한다.)
배열은 입력된 데이터들이 메모리 공간에서 연속적으로 저장되어있다. 그래서 할당된 크기 만큼의 연속된 메모리 주소를 할당 받는다.
메모리 상에서 연속적으로 저장되어 있기 때문에, 인덱스(index)를 갖는다.
인덱스를 갖는다는 것은 임의 접근(random access)이 가능하다는 것이다.
그러므로 인덱스를 통한 접근과 탐색이 용이하다.
하지만, 배열의 크기가 처음 생성할 때 정해지므로 이후에 수정하는 것이 불가능하다.
이 말은 정해진 크기 이상의 데이터를 저장하기가 불가능함을 의미한다.
연산의 시간복잡도
탐색, 삽입, 삭제 연산의 시간복잡도를 살펴보자.
- 탐색 : →
index로 접근을 수행하므로 - 삽입/삭제 : → 접근 자체는 이지만, 이후 원소들의
shift연산에서 소요.
탐색
인덱스로 접근을 하기 때문에 탐색은 단순하게 이다.
삽입
더 자세히 살펴보도록 하자.
삽입에서 원소 접근 자체는 이 소요되지만, 추가적인 과정이 필요하다.
특정 자리에 새로운 원소를 삽입하는 과정을 그림으로 살펴보자.
초기 배열은 다음과 같고, 3과 4 사이에 77을 삽입하려고 한다.
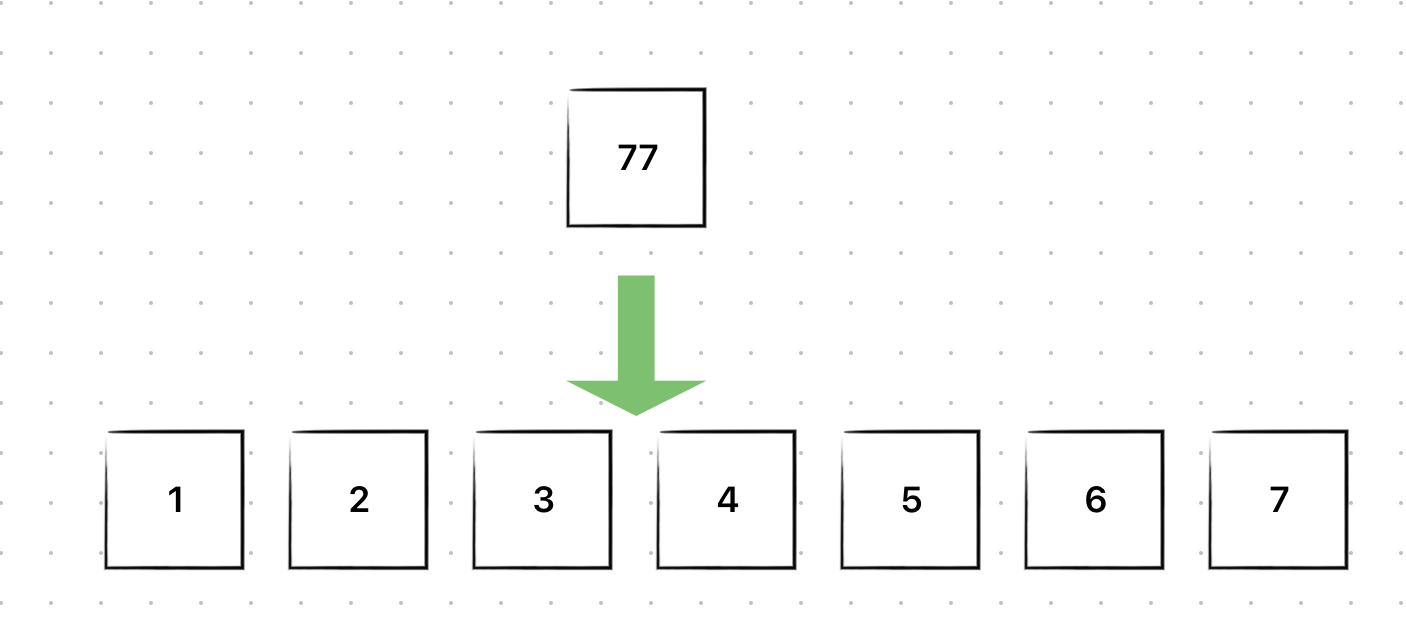
이때는 3뒤에 77을 넣고, 기존 3뒤에 있던 4부터 모든 원소들을 뒤로 shift해야 한다.
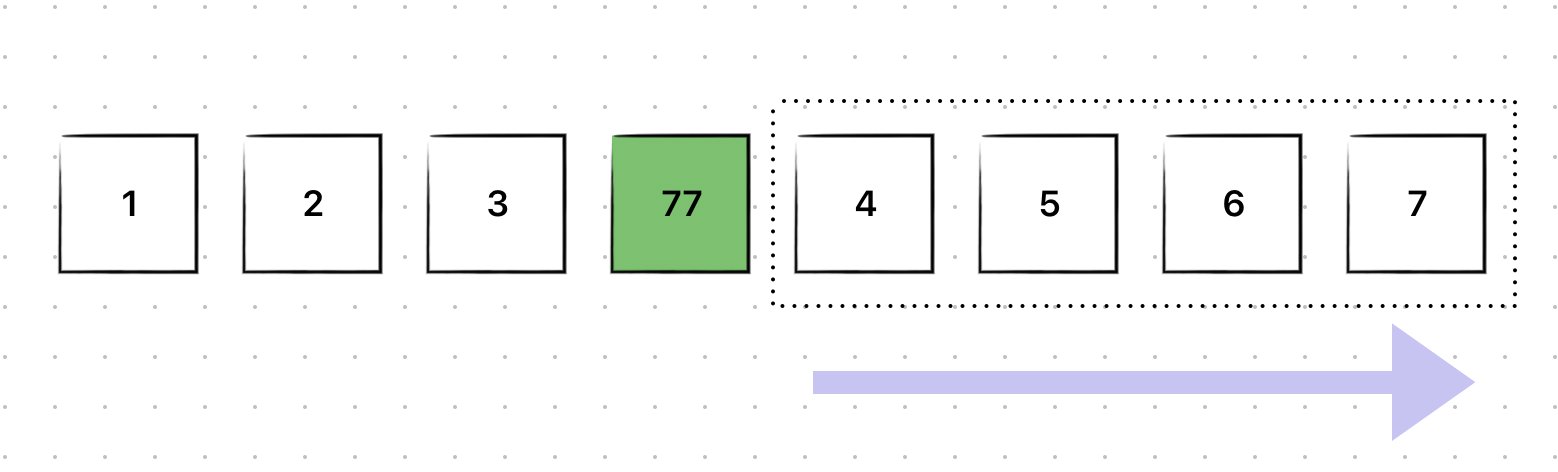
만약, 배열의 크기가 N이라고 할 때 최악의 경우 77을 1앞에 넣으려고 한다면 모든 원소를 뒤로 shift해야 하므로 이 소요된다.
삭제
삭제의 경우도 원소 접근 자체는 이 소요되고, 추가적인 과정이 필요하다.
특정 자리의 원소를 삭제했다고 가정하자. 이때 연속적인 특징이 깨지기 때문에,
즉 빈 공간이 생기기 때문에, 삭제한 원소보다 뒤에 위치한 원소들을 shift해줘야 한다.
이때 발생하는 비용 때문에 시간 복잡도는 이 된다.
그림으로 살펴보자.
초기 배열은 다음과 같고, 4를 삭제하려고 한다.
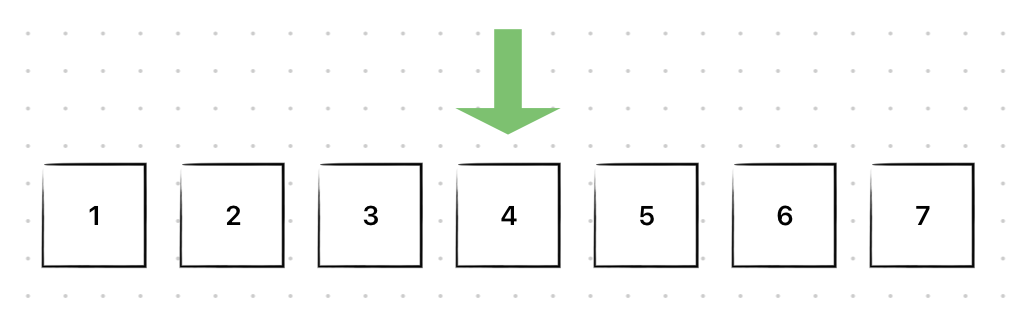
4를 삭제해보자.
배열은 다음과 같은 형태를 가지고, 뒤의 원소들을 앞으로 shift해야 한다.
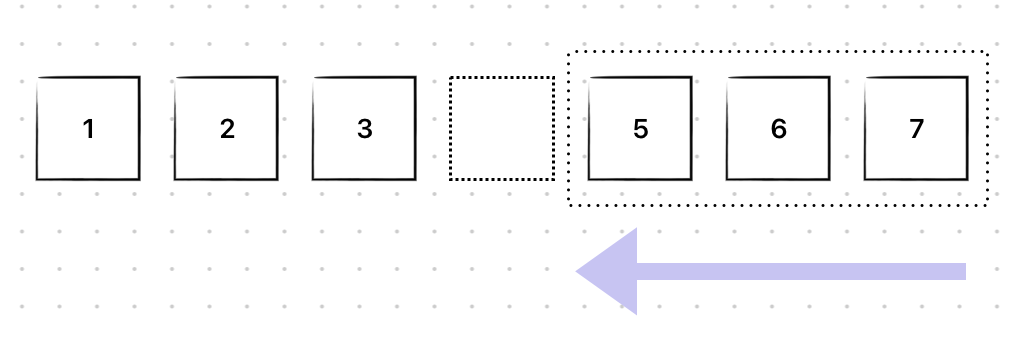
shift까지 모두 마치면 다음과 같다.
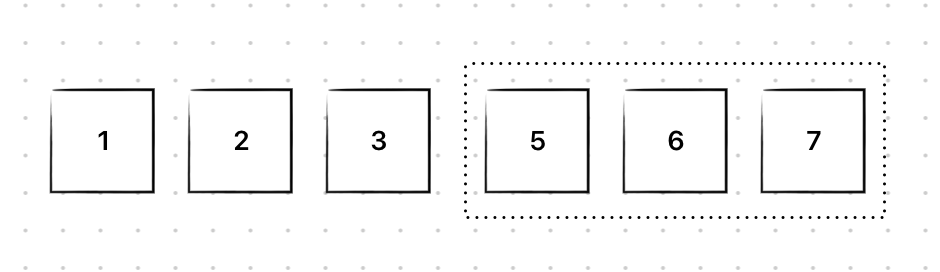
결국, 삭제 연산도 삽입과 마찬가지로 배열의 크기가 N이라고 할 때 최악의 경우 맨 앞의 원소인 1을 삭제한다면 모든 원소를 앞으로 shift해야 하므로 이 소요된다.
✅
shift를 왜 해야 하는가?
배열은 연속적이라는 특징을 갖는다고 했다.
그래서 현재 삽입/삭제하려고 하는 위치 뒤의 원소들을 모두 shift해줘야 한다.
연결 리스트 (LinkedList)
연결리스트(a.k.a 링크드리스트)는 동적 자료구조이다. 그러므로 크기를 따로 정해주지 않아도 된다.
그러면 데이터를 어떻게 접근할 수 있을까?
연결 리스트에는 노드가 존재한다. (처음 노드 : head, 끝 노드 : tail)
노드 안에 데이터가 있고, 다음 데이터를 가리키는 주소(like 포인터)를 가지고 있다. 이러한 여러 개의 노드가 순차적으로 연결된 형태를 갖는 것이 연결리스트이다.
연결리스트는 동적 자료구조여서 크기에 제한이 없다. 그래서 데이터 삽입, 삭제가 비교적 자유롭다.
(만약, 배열이라면 새로운 크기의 배열을 하나 만들고 이전 배열의 값을 모두 복사해야한다.)
하지만, 연속된 메모리 주소를 가지지 않기 때문에 임의로 접근하는 것이 불가능하다.
또한, 우리는 첫번째 노드(head)만 직접적으로 접근이 가능하므로 특정 노드를 찾으려면 head부터 시작해서 순차적으로 접근해야 한다.
연산의 시간복잡도
탐색, 삽입, 삭제 연산의 시간복잡도를 살펴보자.
- 탐색 : → 첫번째 노드(
head)만 직접적으로 접근이 가능하므로, 특정 노드를 찾으려면head부터 시작해야 한다. - 삽입/삭제 : → 삽입/삭제할 인덱스의 주변 노드들 간의 연결된 링크만 수정하면 된다.
탐색
연결리스트는 head만 직접 접근이 가능하므로 다른 노드들은 순차적으로 탐색해야한다.
따라서, 시간복잡도는 이 소요된다.
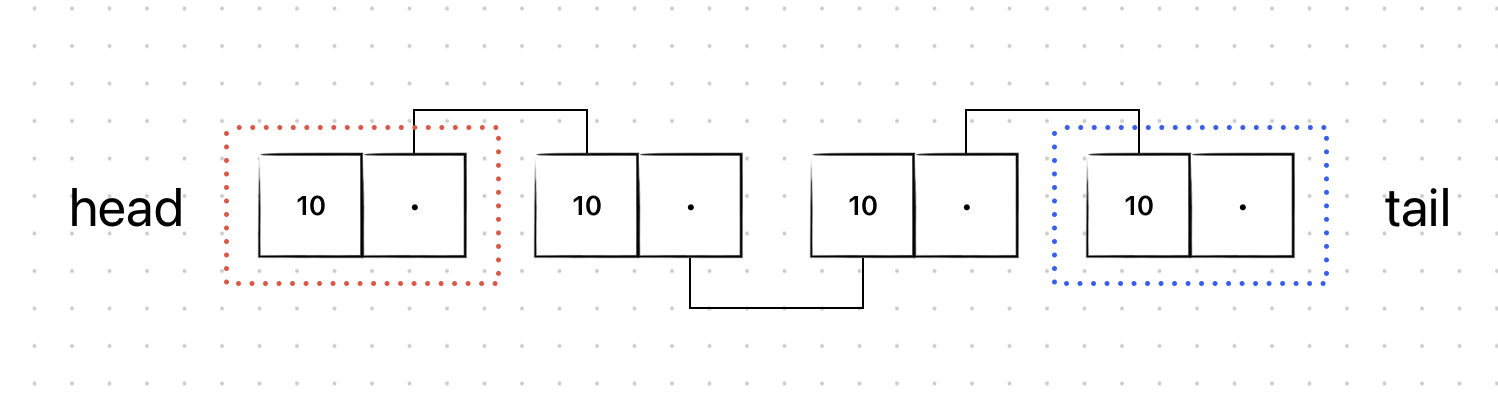
삽입
값이 20인 새로운 노드를 삽입해보자.
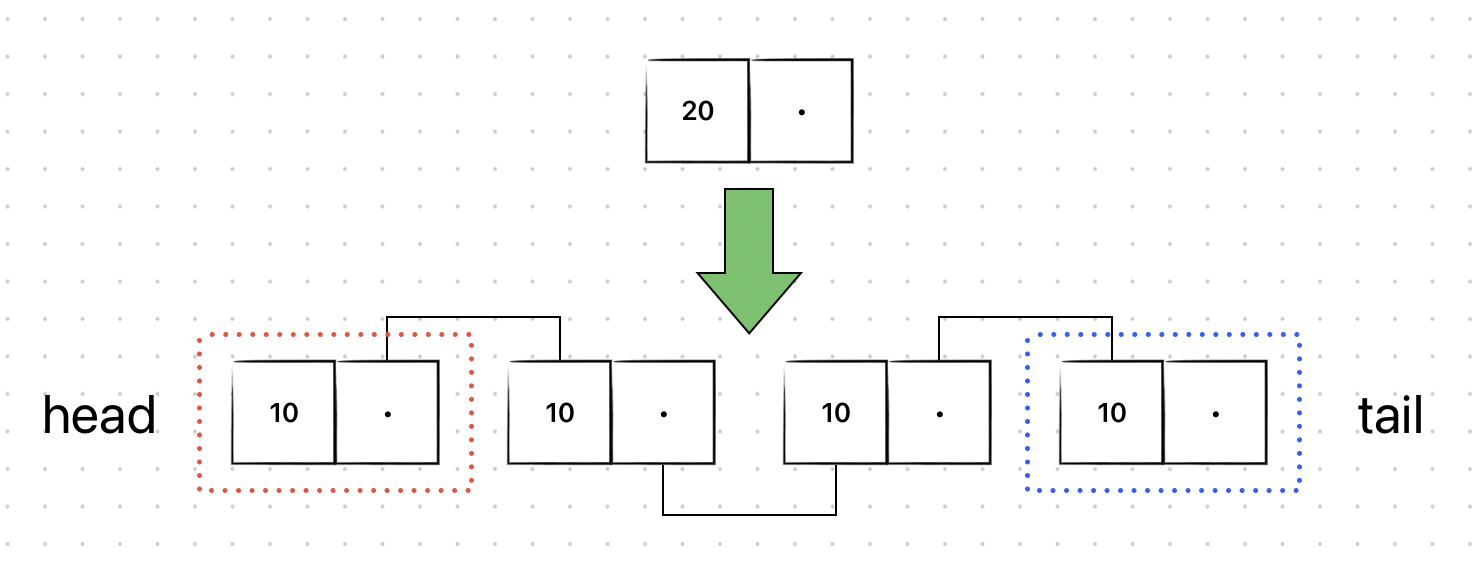
삽입하고자 하는 곳의 앞/뒤 노드들의 연결된 링크를 수정하게 되면 다음과 같다.
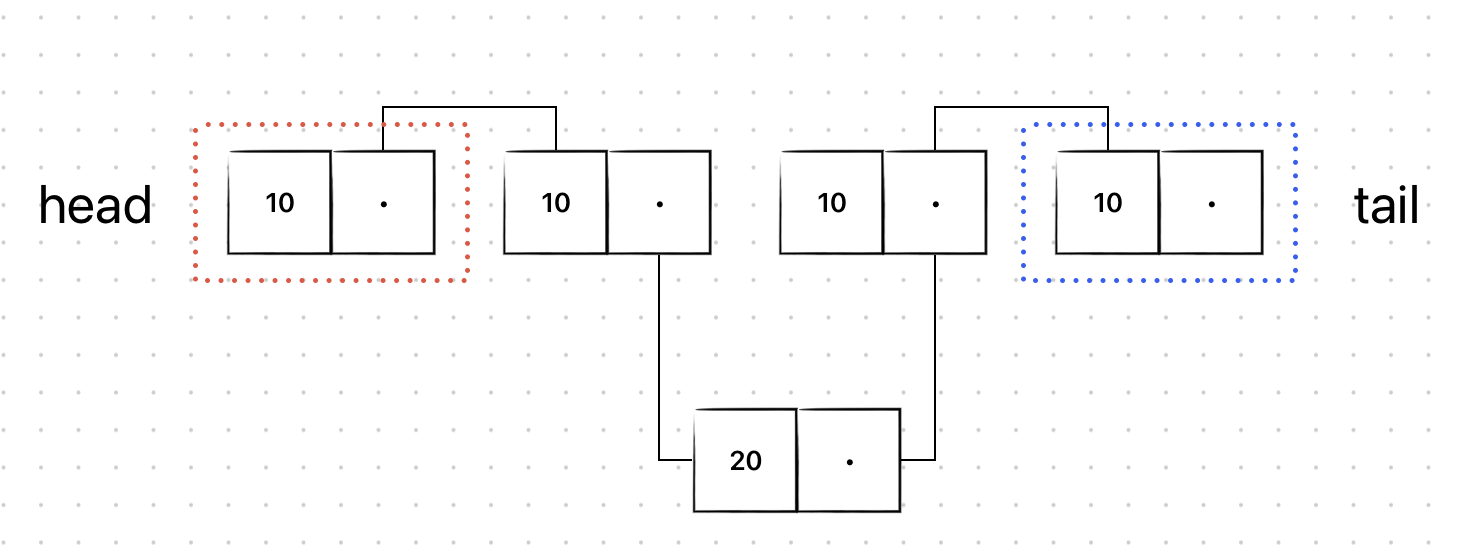
결국, 삽입/삭제할 인덱스의 주변 노드들 간의 연결된 링크만 수정하면 되므로 이 소요된다.
삭제
삭제도 삽입과 마찬가지이다. 아래 노드를 삭제한다고 가정하자.
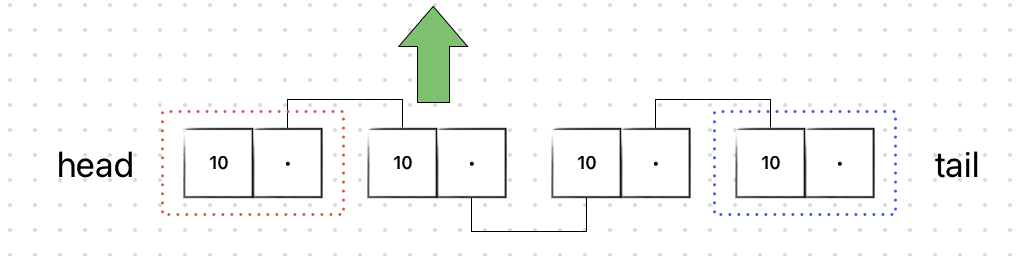
삭제하려는 노드와 연결된 링크들만 수정하면 된다.
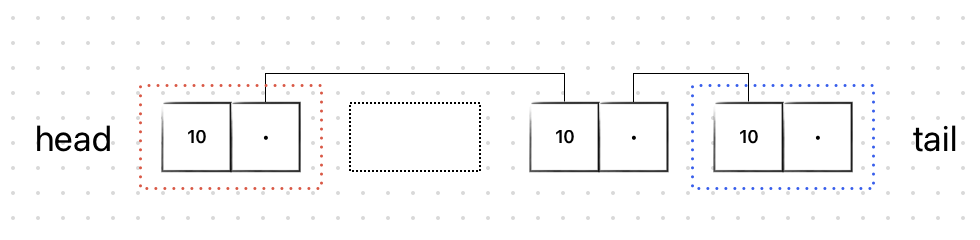
총 정리
차이점
| 배열(Array) | 연결리스트(LinkedList) |
|---|---|
| 정적 자료구조 | 동적 자료구조 |
| 연속된 메모리 주소 | 비연속적인 메모리 주소 |
| 접근, 탐색 용이 | 추가, 삭제 용이 |
| index 접근 | Node 접근 |
시간복잡도
- 탐색
- 배열(Array) :
- 연결리스트(LinkedList) :
- 삽입/삭제
- 배열(Array) :
- 연결리스트(LinkedList)
- head :
- tail :
- 그 외 :
연결리스트의 경우 삽입, 삭제 연산 자체는 이 소요되지만, 접근까지 고려했을 때 최악의 경우 이 소요된다. (
head의 경우 이 소요)
결론...
배열과 연결리스트는 각 특성에 따라 탐색, 삽입/삭제에서 다른 장점을 보인다.
결국, 접근과 탐색이 중요하다면 배열을 사용하고
삽입/삭제가 중요하다면 연결리스트를 사용하는게 용이할 것이다.
배열은 크기가 정해져있어서 불편하니 무조건 연결리스트를 써야지! 같은 접근은... ❌
(추가) 질문 정리
파이썬에서는 정적 자료구조가 없나요?
파이썬에서 튜플이 정적 자료구조에 해당한다. 튜플은 정적이고 '배열'처럼 동작하여 '정적배열'로 볼 수 있다. (단, 배열이라는 것은 아니고, 배열 처럼 동작한다는 것이다.)
튜플에 대해서 간단하게 살펴보자면, []가 아닌 ()로 감싸고 리스트는 요소 값의 생성, 삭제, 수정이 가능하지만 튜플은 요소 값을 바꿀 수 없다.
튜플은 다음과 같이 만들 수 있다.
>>> t1 = ()
>>> t2 = (1,)
>>> t3 = (1, 2, 3)
>>> t4 = 1, 2, 3
>>> t5 = ('a', 'b', ('ab', 'cd'))여기서 눈여겨 볼 것은, 원소가 1개만 존재할 때는 뒤에 ,를 붙여야한다는 것이고, ()도 생략이 가능하다는 점이다.
그리고 튜플 안에 튜플도 선언할 수있다.(tuple-in-tuple)
얼핏보면 리스트와 튜플은 기능의 차이만 존재하고 나머지는 비슷해보이지만 구별해서 사용해야 한다.
튜플과 리스트의 가장 큰 차이는 요솟값을 변화시킬 수 있는가 여부이다.
그래서 만약, 프로그램이 실행되는 동안 요소가 변하지 않길 원한다면 튜플을 사용해야 한다. 그런데 이 정도로는 튜플을 왜 사용해야 하는지에 대한 필요성을 느끼지 못할 수 있다.
튜플의 특징에 대해서 알아보자.
-
메모리 공간을 적게 차지한다.
리스트는 다른 언어의Array + LinkedList의 기능을 한다.
동적 자료구조이기 때문에 언제든지 요소를 추가하여 리스트 사이즈를 늘릴 수 있다. 하지만 튜플은 사이즈가 정해져있고 요소의 변경이 불가능하기 때문에 메모리를 훨씬 적게 차지한다. 그리고 정적이기 때문에 파이썬 내부적으로 수행하는 리소스 캐싱이 가능하다.
파이썬은Garbage Collection을 통해 더 이상 사용되지 않는 변수에 할당된 메모리를 반환해 해제한다.
크기가 20이하인 Tuple은 크기별로 최대 2만개(e.g. 크기가 1인 Tuple 2만개, 2인 Tuple 2만개, …)까지 즉시 해제하지 않고 나중을 위해 저장해둔다.
그렇기 때문에 나중에 메모리가 필요해지면 새로 할당받는 것이 아닌 기존에 할당받은 메모리를 재사용한다. -
실행시간에서의 이점
>>> timeit.timeit('t = (0,1,2,3,4,5,6,7)', number=100000)
0.014356082999999999
>>> timeit.timeit('l = [0,1,2,3,4,5,6,7]',
number=100000)
0.06533462500000001timeit은 작은 코드의 실행 시간을 측정하는 모듈이다. 위 그림은 List와 Tuple의 할당을 100,000번 실행한 코드이다.
List는 운영체제에서 100,000번 새롭게 메모리를 할당받아 실행-해제를 반복하지만, Tuple은 한번 메모리를 할당하고 해제하지 않기 때문에 캐싱을 통해 메모리를 재사용한다.
이에 따라 속도차이를 보면 Tuple이 List보다 약 5배 정도 빠른 것을 볼 수 있다.
배열과 링크드 리스트의 memory allocation
배열은 정적 배열과 동적 배열로 나눠서 살펴보겠다.
정적 배열
- 정적 배열은 프로그램의 컴파일 타임에 크기가 결정되며, 주로 스택(
Stack)이나 전역 데이터 영역(Global Data Segment)에 할당된다. - 컴파일러는 배열의 크기를 기반으로 필요한 메모리 공간을 할당한다.
- 정적 배열은 선언 시점부터 프로그램의 종료까지 메모리에 유지되며, 크기가 변경되지 않는다.
동적 배열
- 동적 배열은 런타임에 크기가 동적으로 결정되며, 대부분의 프로그래밍 언어에서 동적 배열은 힙(
Heap) 메모리에 할당된다. - 동적 배열을 사용하기 위해서는 메모리 할당을 위한 동적 할당 함수(
malloc,new등)을 사용하여 메모리를 요청한다.
연결리스트
- 연결리스트(
Linked List)는 동적 자료구조로서, 크기가 런타임에 결정된다. - 연결리스트의 메모리 할당은 주로 힙(
Heap) 메모리 영역에서 이루어진다. - 힙(
Heap) 메모리는 런타임에 동적으로 할당되고 해제되는 메모리 영역으로, 프로그램 실행 중에 필요한 메모리를 동적으로 할당하여 사용할 수 있도록 한다.
✅ 단, 언어 및 환경에 따라 배열의 메모리 할당 방식이 다를 수 있다.
일부 언어는 동적 배열을 기본적으로 제공하지만, 다른 언어는 정적 배열만을 지원할 수도 있다.
링크드 리스트의 탐색 효율을 높일 수 있는 방법에는 무엇이 있을까요?
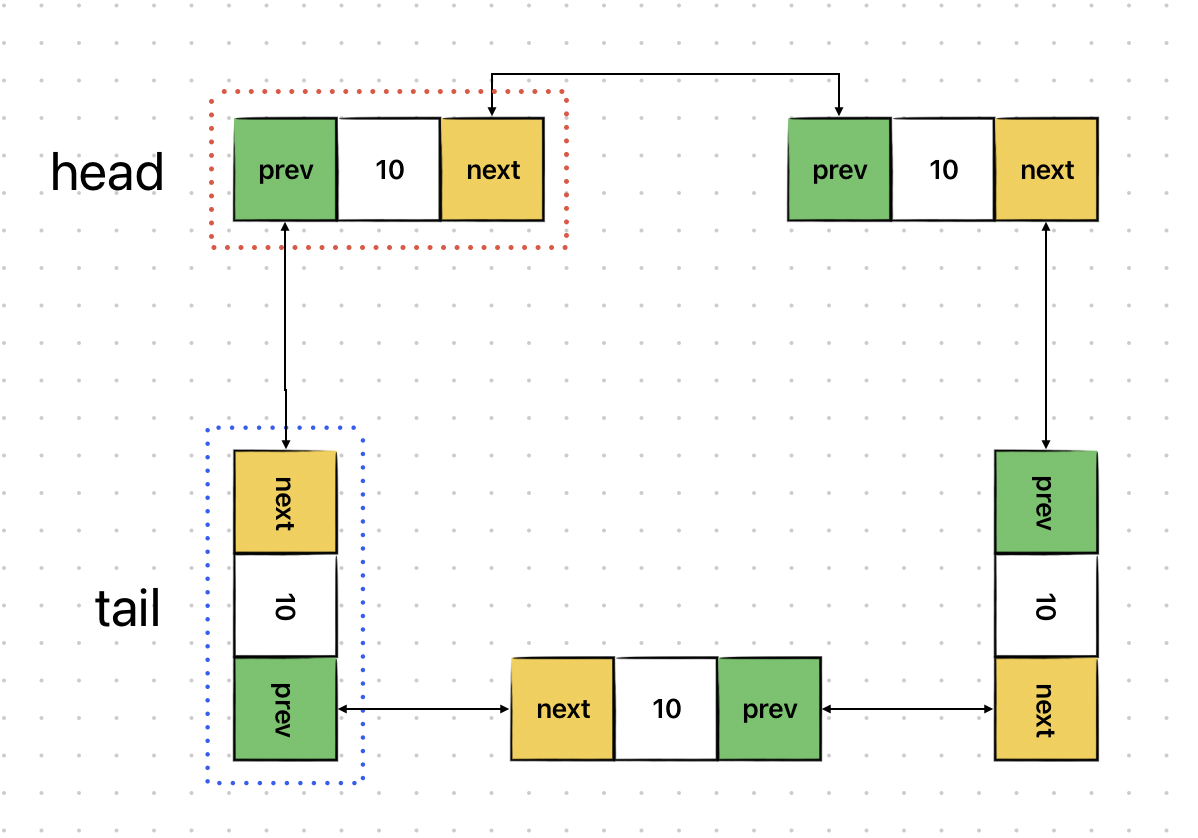
Doubly LinkedList
앞선 LinkedList는 Singly LinkedList라고도 한다.
Singly LinkedList는 각 노드가 다음노드(단방향)에 대한 정보를 가지고 있기 때문에 특정 노드를 탐색할 때 단방향으로 가야하는 단점이 있다.
이러한 단점을 개선하기 위해 나온것이 Doubly LinkedList이다.

Doubly LinkedList는 다음 노드에 대한 포인터 뿐만 아니라 이전 노드에 대한 포인터도 가지고 있는 양방향 특징을 가지기 때문에, 앞/뒤 노드에 대해 탐색을 할 수 있는 장점을 가진다.
이로 인해 현재 노드의 이전 값을 가져오는 경우 처음부터 다시 찾아갈 필요 없이 현재 노드에 저장된 포인터를 활용하면 바로 이전노드의 값을 가져올 수 있다.
Circular LinkedList
Circular LinkedList는 Doubly LinkedList에서 Head와 Tail을 연결한 구조이다.
말 그대로 원형, 사이클 처럼 생긴 LinkedList이다.
배열과 연결리스트를 언제 사용하나요?
배열
- 정렬 알고리즘(예: 퀵 정렬, 병합 정렬)에서의 사용
- 스택, 큐, 힙 등과 같은 다른 자료 구조의 구현에서의 사용
- 3차원 이상의 다차원 배열은 컴퓨터 그래픽스, 과학 및 공학 계산 등 다양한 분야에서 사용
- 게임 개발에서는 배열을 사용하여 맵 데이터, 캐릭터 속성, 아이템 목록 등을 저장
- 데이터베이스 시스템에서는 배열을 사용하여 레코드와 필드를 표현
- 이미지 파일에서 픽셀 값을 배열에 저장하여 이미지를 표현
연결리스트
- 음악 스트리밍 어플
- 다음 곡 넘어가기
- 이전 곡 넘어가기
- 이미지 뷰어에서 사용
- 다음 이미지 보기
- 이전 이미지 보기
- 포토샵에서의 사용
- ctrl + z (수정 이전으로 되돌리기)
- ctrl + y (이전으로 되돌린 것 되돌리기 → 복구)
동적배열이란?
동적 배열(Dynamic Array)은 배열과 연결리스트의 장점을 결합한 자료 구조이다. 동적 배열은 크기를 동적으로 조정할 수 있는 배열로, 필요에 따라 크기를 늘리거나 줄일 수 있다.
특징
- 크기 조정: 동적 배열은 초기에는 작은 크기로 시작하며, 요소의 추가로 인해 배열이 가득 차면 자동으로 크기를 확장하여 추가 요소를 수용할 수 있다.
크기를 동적으로 조정할 수 있으므로, 사전에 배열 크기를 정확히 알 수 없거나 변경되는 상황에서 유용하다. - 연속적인 메모리 할당: 동적 배열은 메모리 상에서 연속적으로 요소를 저장한다. 이로 인해 배열의 인덱스를 사용하여 상수 시간()에 요소에 액세스할 수 있는 장점을 가진다.
- 삽입 및 삭제의 비용: 동적 배열은 요소의 삽입 및 삭제를 지원한다. 배열의 마지막에 요소를 삽입하거나 삭제하는 경우에는 상수 시간()이 소요된다.
그러나 배열의 중간에 요소를 삽입하거나 삭제하는 경우에는 해당 위치 이후의 요소들을 이동해야 하므로 최악의 경우에는 의 시간이 소요될 수 있다. - 메모리 관리: 동적 배열은 필요에 따라 메모리를 동적으로 할당하고 해제한다. 크기를 확장할 때는 더 큰 메모리 블록을 할당하고, 크기를 축소할 때는 불필요한 메모리를 해제하여 메모리 관리를 최적화한다.
[참고]
https://www.happycoders.eu/algorithms/array-vs-linked-list/
