
스택(Stack)
스택의 사전적 정의는 '쌓다'이다. 즉, 하나씩 데이터를 쌓는 구조로 보면 된다.
스택은 선형 자료구조의 일종으로 Last-In-First-Out(LIFO) 즉, 후입선출 구조이다.
이는 나중에 들어간 원소가 먼저 나온다는 의미이다.
아래에서 위로 쌓이는 구조로, 먼저 Stack에 들어간 원소는 바닥에 깔리는 형태이다.
그렇기 때문에 늦게 들어간 원소들은 그 위에 쌓이게 되고 먼저 빼내지게 된다.
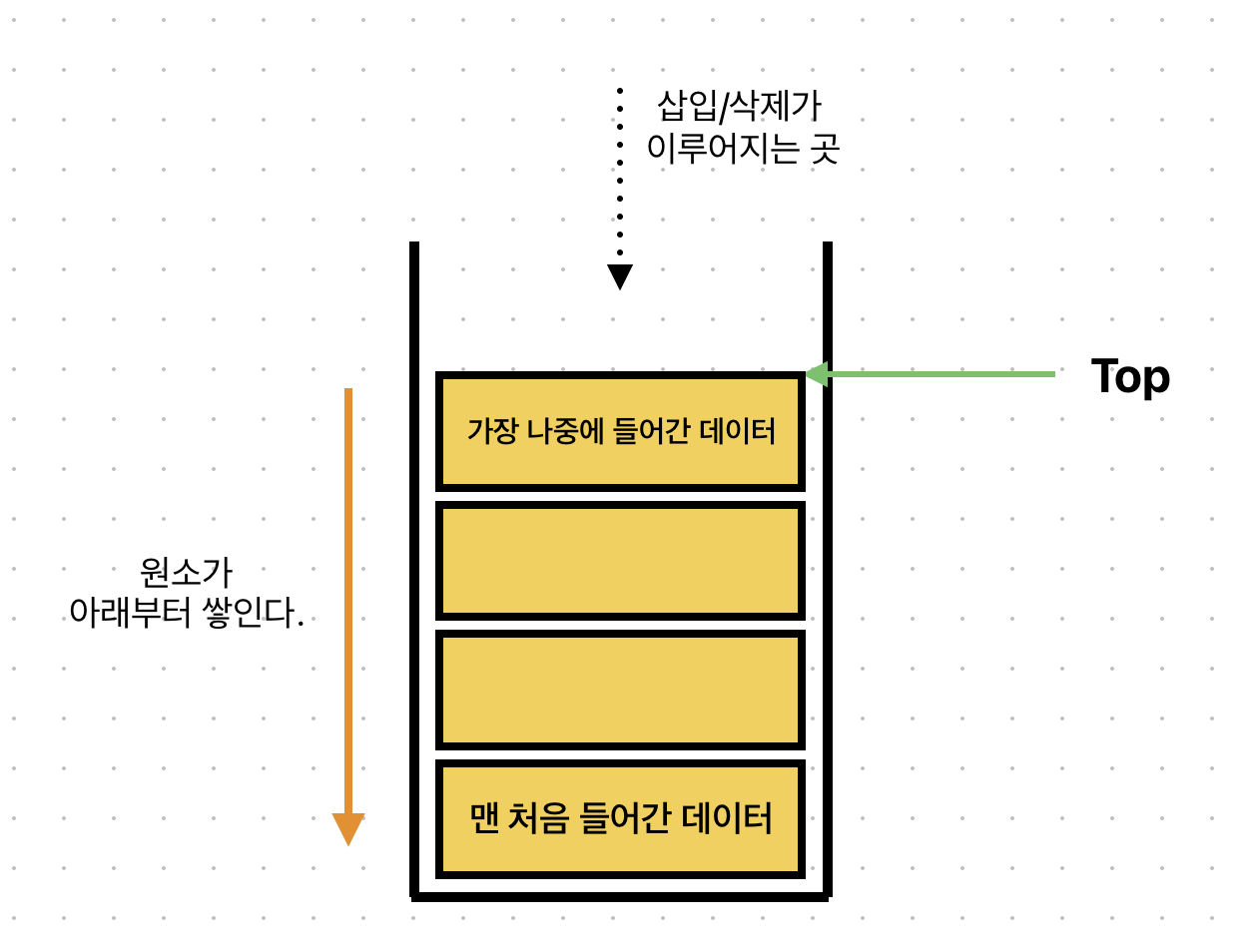
위의 그림에서 볼 수 있듯이,
가장 최근에 들어온 데이터를 가리키는 일종의 포인터를 top이라고 한다.
삽입/삭제 접근은 모두 top에서 이루어지며, 데이터가 삽입되면 top은 위로 늘어나고 데이터가 삭제되면 top은 아래로 줄어든다.
- 그리고 스택이 비어있을 때, 스택에서 원소를 빼내려고 하면
Stack Underflow에러가 발생하고, - 반대로 꽉 차있는 경우 원소를 넣으려고 하면
Stack Overflow에러가 발생한다.
스택의 활용
그렇다면 스택은 쓰이긴 쓰이는가? 어디에서 사용될까?
- 웹 브라우저 방문기록 (뒤로 가기) : 가장 나중에 열린 페이지부터 다시 보여준다.
- 역순 문자열 만들기 : 가장 나중에 입력된 문자부터 출력한다.
- 실행 취소 (undo) : 가장 나중에 실행된 것부터 실행을 취소한다.
- 후위 표기법 계산
- 수식의 괄호 검사 (연산자 우선순위 표현을 위한 괄호 검사)
연산의 시간복잡도
큐에는 다음과 같이 삽입, 삭제, 탐색 연산이 있다. 각각의 시간복잡도를 살펴보자.
- 삽입 :
- 항상 맨 위를 가리키는
top때문에 상수시간이 소요된다.
- 항상 맨 위를 가리키는
- 삭제 :
- 항상 맨 위를 가리키는
top때문에 상수시간이 소요된다.
- 항상 맨 위를 가리키는
- 탐색 :
- 특정 원소를 찾으려면
top에서부터 탐색해야하므로 평균적으로 이 소요된다.
- 특정 원소를 찾으려면
큐(Queue)
큐의 사전적 정의는 '줄', '줄을 서서 기다리다' 이다.
우리가 맛집 대기열을 기다릴 때나 퇴근길 버스를 기다릴 때 항상 줄을 선다.
이때 줄은 어떤 순서를 가지는가? 만약, 내가 먼저 서서 기다리고있는데 맨 나중에 온 사람이 먼저 타거나 들어가면 어이가 없을것이다. 그래서 우리는 항상 먼저 선 사람이 먼저 타거나 들어간다.
큐도 마찬가지이다. 먼저 들어간 데이터가 먼저 나오게 되는 구조이며,
이를 First-In-First-Out(FIFO) 즉, 선입선출이라고 한다.
(편돌이, 편순이 경험이 있다면 선입선출은 지겹게 들었을 것이다. 유통기한 Issue)
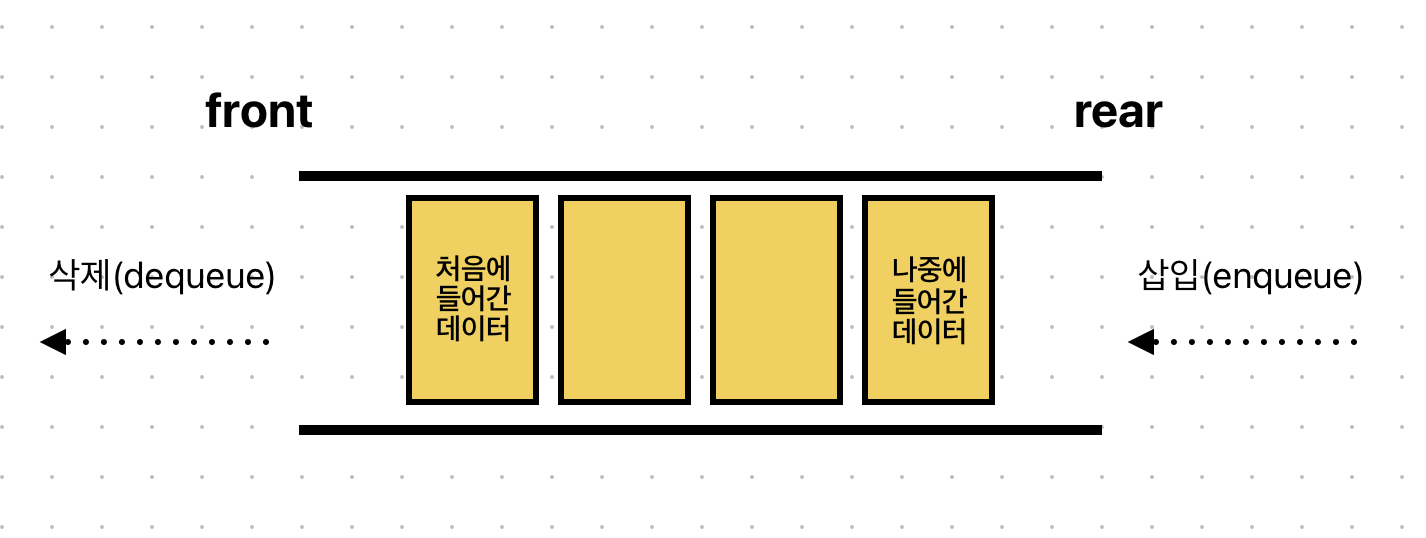
위에서 스택은 top에서만 삽입/삭제, 접근이 가능하다고 했다.
하지만 큐는 양 쪽에서 접근이 가능하다.
한쪽 끝에서는 삽입 연산, 다른 한쪽 끝에서는 삭제 연산이 이루어진다.
이때 삽입 연산이 이루어지는 곳을 rear, 삭제 연산이 이루어지는 곳을 front라고 한다.
그리고 큐의 삽입 연산은 enqueue, 삭제 연산은 dequeue라고 칭한다.
✅ 결론적으로 큐는
rear에서 들어오지만front에서 나가고, 가장 먼저 들어온 데이터가 먼저 나가는 구조이다.
큐의 활용
그렇다면 큐는 어디서 쓰일까?
- 우선순위가 같은 작업 예약 (프린터의 인쇄 대기열)
- 은행 업무
- 콜센터 고객 대기시간
- 프로세스 관리
- 너비 우선 탐색(BFS, Breadth-First Search) 구현
- 캐시(Cache) 구현
연산의 시간복잡도
큐도 스택과 동일한 시간복잡도를 갖는다.
- 삽입 :
- 맨 뒤를 가리키는
rear에서 항상 삽입을 수행하므로
- 맨 뒤를 가리키는
- 삭제 :
- 맨 앞을 가리키는
front에서 항상 삭제를 수행하므로
- 맨 앞을 가리키는
- 탐색 :
- 특정 원소를 찾으려면
front에서rear까지 탐색해야하므로 평균적으로 이 소요된다.
- 특정 원소를 찾으려면
결론
스택과 큐의 차이
| 입출력 방식 | 기능 | 시간복잡도 | 장점 | 단점 | |
|---|---|---|---|---|---|
| 스택 | LIFO(후입선출) | push & pop | 삽입/삭제 : , 탐색 : | 구현이 간단, 빠른 속도 | 중간에 위치한 원소 접근이 어려움 |
| 큐 | FIFO(선입선출) | enqueue & dequeue | 삽입/삭제 : , 탐색 : | 데이터 접근 용이 | 구현이 복잡, 메모리 관리 어려움 |
