AlexNet은 ILSVRC-2012에서 압도적으로 1위를 차지한 딥러닝 모델이다.
이 모델 덕분에 CNN이 세간에 주목을 받았다고 한다.
어떤 기법들이 사용되었는 지 살펴보자
dataset은 ImageNet dataset을 사용하였다.
22000개의 class로 구성되어 있고, 1500만 장의 이미지가 포함되어 있다고 한다.
ILSVRC는 ImageNet dataset의 일부를 이용하는데, 클래스당 1000장의 이미지,
1000개의 class를 이용한다.
약 100만장 이상의 학습 데이터와 5만 개의 검증셋, 15만 개의 테스트 셋을 이용한다고 한다.
전처리로는 나중에 FC layer에서 입력 크기가 고정되어야 하므로 256 * 256으로 입력 이미지를 고정시켰다.
resize 방법은 가로와 세로중 짧은 쪽을 256으로 고정시키고 중앙 부분을 crop했다고 한다.
각 이미지의 학습 데이터의 평균을 빼서 normalize를 시켜줬다고 한다.
AlexNet 구조
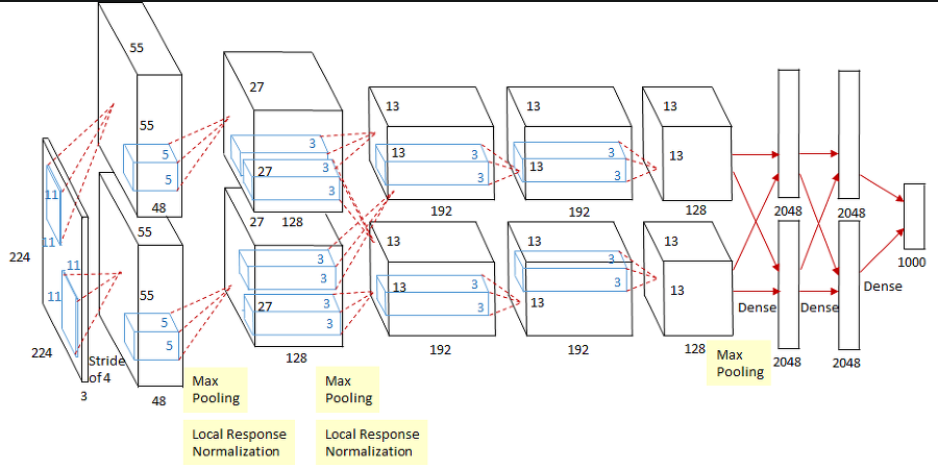
위의 이미지를 보면 이전 LeNet과 구조가 크게 다르지 않다. convolution, pooling, fc layer로 구성되어 있다.
바뀐 것들에 집중을 해보자면
-
활성화 함수를 Relu로 바꿨다.
이전에는 tanh, sigmoid가 표준이었지만 Relu를 사용했다.
Relu를 사용함으로서 학습 속도를 높일 수 있었다.,
이므로 역전파시 미분이 1이 되어 그대로 전달되기 때문, sigmoid나 tanh는 미분값이 작아져 학습이 느려지거나 안되는 gradient vanishing 현상이 나타난다.
논문에서는 CIFAR-10으로 학습할 때 25% errorㅇ 도달하는데 relu가 tanh에 비해 6배 빠르다는 내용이 담겨져 있다. -
2개의 GPU로 나누어 학습
저자는 많은 데이터를 하나의 GPU로 부족하다고 생각해 2개의 GPU로 나누어 학습시켰다고 한다.
상세하게 알고 싶다면, GPU parallelization를 찾아보자 -
Local Response Normalization(LRN)
현대 구조에서는 잘 사용되지 않지만(다른 normalization 기법이 더 효과적이기 때문에) 아직 다른 라이브러리나 프레임워크에서 볼 수 있다고 한다.
이 것을 쓰는 이유는 1번에서 소개한 Relu를 사용하면서 큰 값이 들어온다면 큰 값을 그대로 흘려보내는데, 컨볼루션에서 하나의 픽셀이 큰 값을 가진다면 주변의 값이 작더라도 큰 값을 내게되는 문제를 유발할 수 있다.
이 문제를 해결하기 위해 아래의 수식을 이용하여 normalization을 한다.

-
pooling overlapping
전통적으로 pooling은 겹치게 사용하지 않지만 AlexNet에서는 겹치게 사용했다.
어떤 이점을 가지는 지 보기 어렵지만, 논문에서는 오버피팅을 줄여주는 효과가 있다고 한다.
(maxpooling 사용) -
data augmentation
일반적으로 크기 조정, crop, flip등이 사용되지만
AlexNet에서는 이미지 내의 픽셀 강도 변경(PCA가 사용되었다고 하는 거 같은데 아직 PCA의 개념을 몰라 추후에 선형대수파트에서 PCA를 다뤄야겠다.), crop(256 256 -> 224 224)이 사용되었다고 한다.data augmentation은 데이터를 추가적으로 획득하지 않고 데이터의 불변성을 증가시킬 수 있다.
신경망의 일반화 능력도 증가시킬 수 있다.
실제 데이터를 취득할 때에는 이상적인 환경에서만 데이터를 취득할 수 없다. 어떨 때에는 기울어지거나, 흐리거나 다양한 상황이 있다. 따라서 사람 얼굴을 분류하는 모델을 개발한다고 할 떄에도 웹에서 크롤링한 데이터로만 해서 잘되는 것이 아닌 변형을 포함하는 데이터로 학습한다면 더 성능이 좋을 수 있게 된다.
그리고 실제로 서비스한다고 가정해도 실제 데이터를 취득하는 것은 시간과 비용은 생각보다 크다. -
Drop Out
학습할 때 뉴런의 활성화 여부에 확률 요소를 추가한 것이다.
확률에 따라 뉴런이 활성화되지 않고 죽은 뉴런으로 되기도 하고 활성화되기도 한다.
AlexNet에서는 FC layer에서 첫번째와 두번째에 적용하였다.
한가지 단점이 있는데, 네트워크가 학습하면서 수렴하는데 시간을 증가시킨다고 한다.optimizer와 weight decay같은 것은 상세히 다루지 않고 deeplearning 카테고리에서 다룬다.
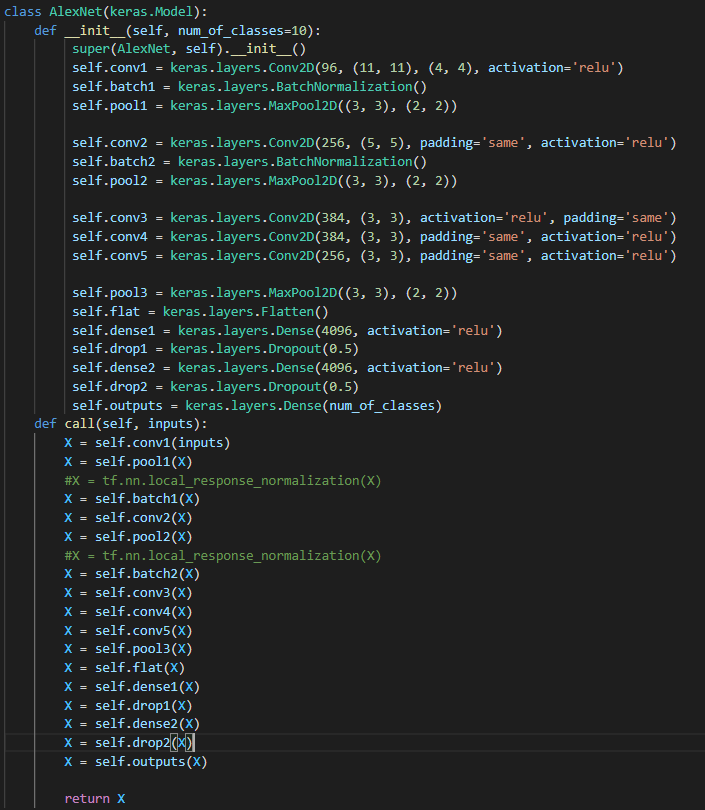

네트워크는 위처럼 구성하였고, lrn을 적용한 것보다는 BN을 적용한 것이 조금 더 좋았다.
이미지 참조 : https://bskyvision.com/421?category=635506, https://deep-learning-study.tistory.com/376?category=963091
