VGG NET
VggNet(Very Deep Convolutional Networks for large-scale image recognition)은 ILSVRC 2014에서 2등한 모델이다.
보통 1등만 기억되는 세상에서 자주 사용되는 모델이다. 그 이유는 밑에서 설명이 되겠지만 좋은 성능을 가지며 단순한 구조를 띄기 때문이다.
신경망의 깊이가 깊어짐에 따라 Overfitting, Gradient Vanishing, 연산량 문제 때문에 이전까진 최대 8 Layer에 그쳤었다.
하지만 VggNet은 19층까지 깊이를 증가시킬 수 있었다.
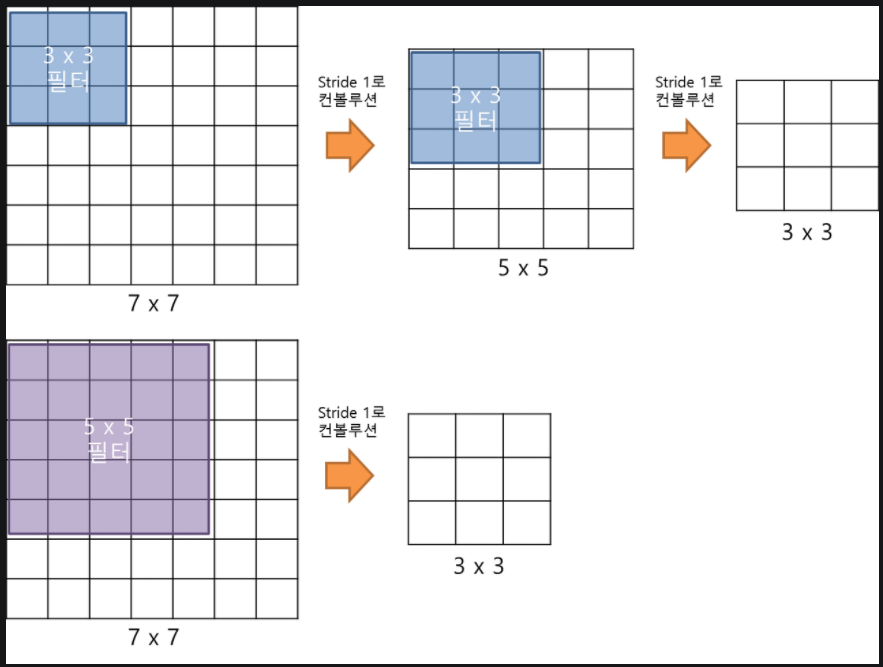
VggNet은 오로지 3x3 filter만 사용했고, 여러 겹을 사용하여 5x5, 7x7 filter들을 대체하였다.
아래의 사진을 보면 결국 5x5 필터 한 번의 컨볼루션이 3x3 필터 두 번의 컨볼루션과 동일한 사이즈의 특성맵이 나온다.
3x3 필터를 두 번 사용하는 것이 파라미터 수도 18개로 5x5보다 적고 연산량에서도 이득을 볼 수 있다.
또한, 5x5에서는 활성화 함수를 한 번만 통과하였지만 3x3에서는 두 번 통과를 하며 비선형성을 더해 더 복잡한 특징을 추출해낼 수 있게 된 것이다.
VGG NET 구조
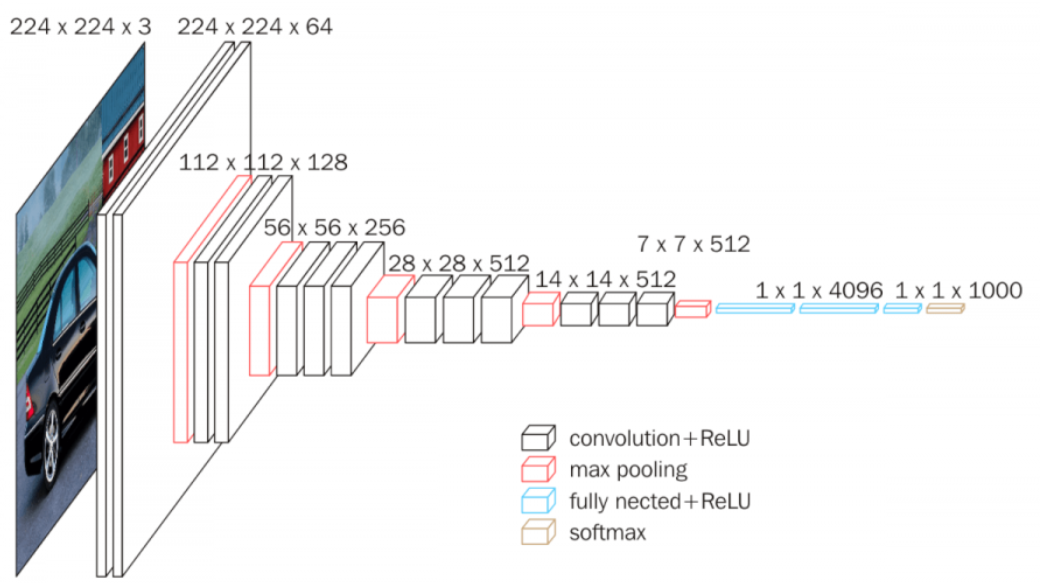
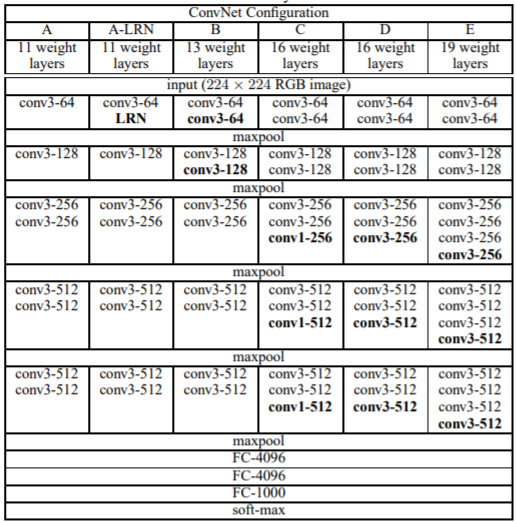
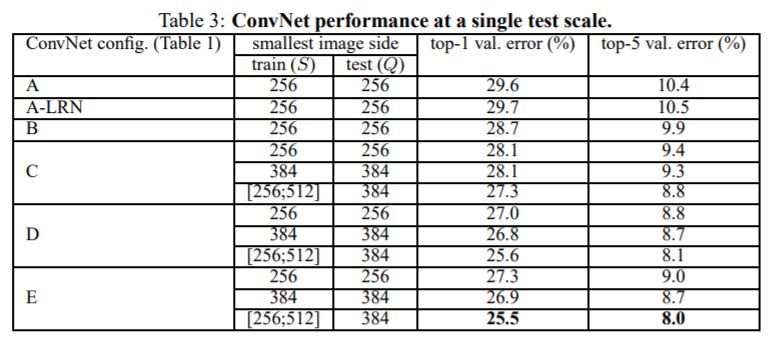
위의 구조와 성능을 봤을 때 층이 깊어질 수록 더 높은 성능을 가진다는 사실을 알 수 있으며, VGG NET을 만든 연구팀이 실험했을 때 AlexNet에서 적용했던 LRN은 성능 향상이 없었기 때문에 적용하지 않았다고 한다.
사용한 기법
VGG Net 연구팀이 사용한 기법을 살펴보면
-
Learning rate decay
-
L2 regularizer
-
Dropout
-
Pre-initialisation
가장 얇은 구조인 A를 학습시킨 이후 첫번째, 네번째 conv와 3개의 FC의 가중치를 이용하여 다른 깊은 모델을 학습시켰다고 한다. 이를 통해 더 빨리 수렴할 수 있었다고 한다. -
preprocessing
전처리로는 RGB의 평균값을 각 픽셀에 빼주는 거만 사용했다고 한다. -
data augmentation
randomly crop
horizontal flip(crop된 이미지)
random RGB color shift
3가지 rescale(256 고정, 384 고정, [256, 512] 사이의 랜덤사이즈)
그래서 성능 지표를 보면 256, 384, [256ㅣ512] 이렇게 세 개가 있다.
(이미지 안의 object가 다양한 규모로 나타나므로 다양한 크기로 학습했더니 효과가 있었다고 한다.
384 사이즈는 256으로 pre-trained된 가중치로 초기화를 했고, 가변 사이즈에서는 384로 pre-trained된 가중치로 초기화하여 학습하였다.)
- 4 GPU parallelism
구현
나는 직접 구현할 때 4GPU, pre-initialisation은 사용하지 않았다.
data는 cifar10 데이터를 이용했다.
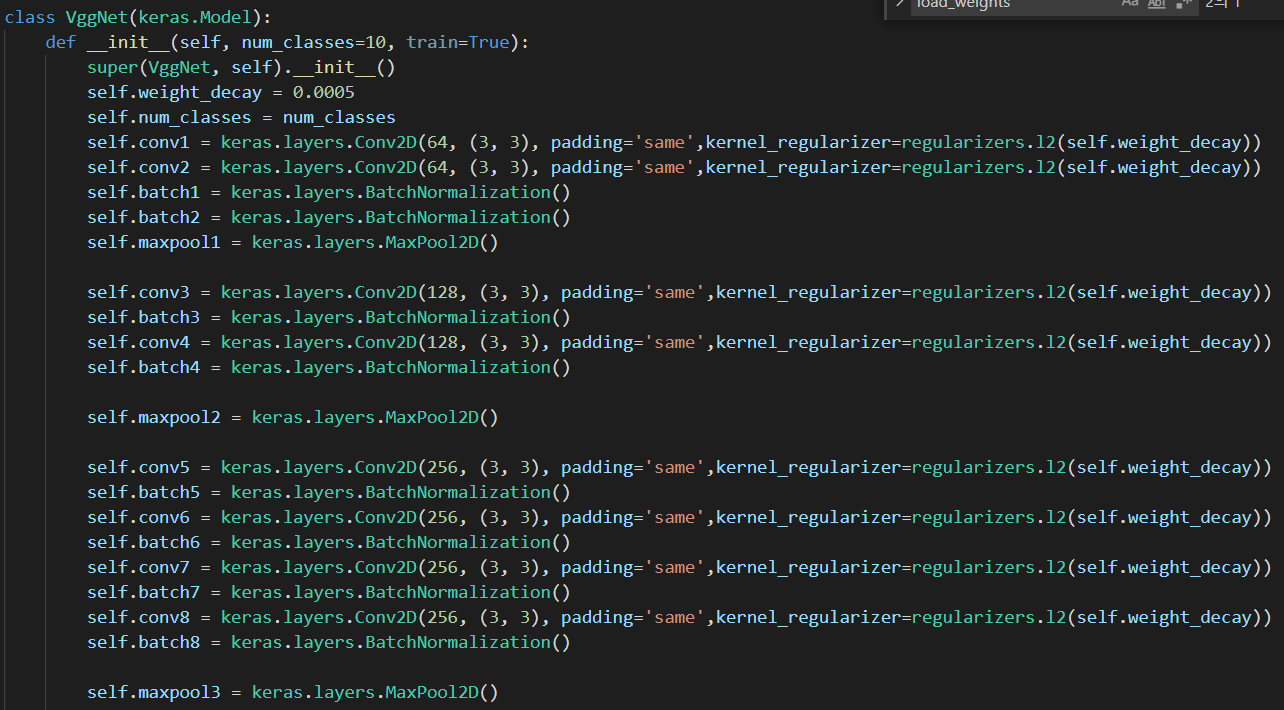
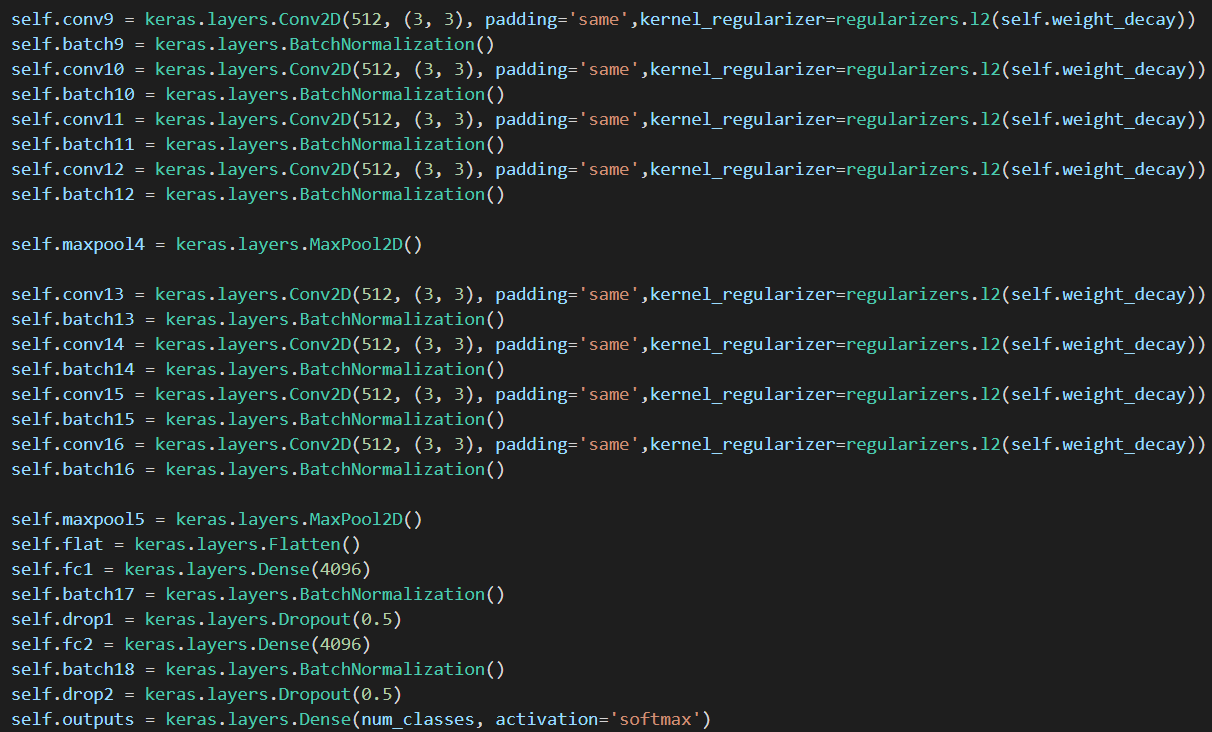
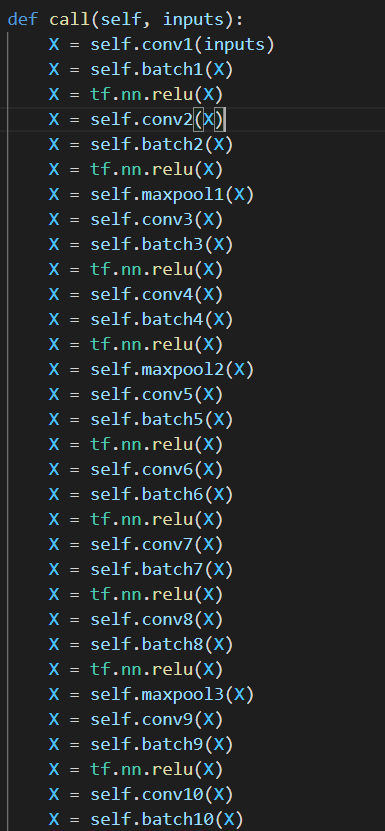
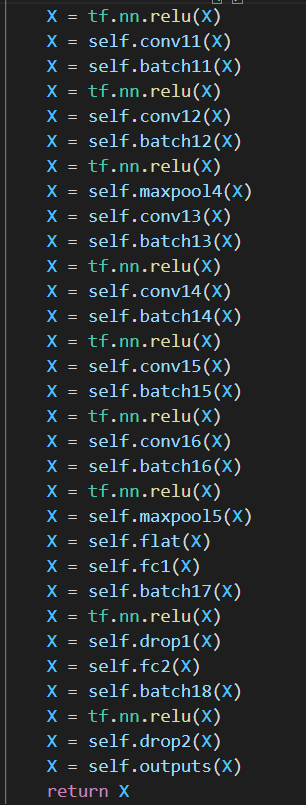
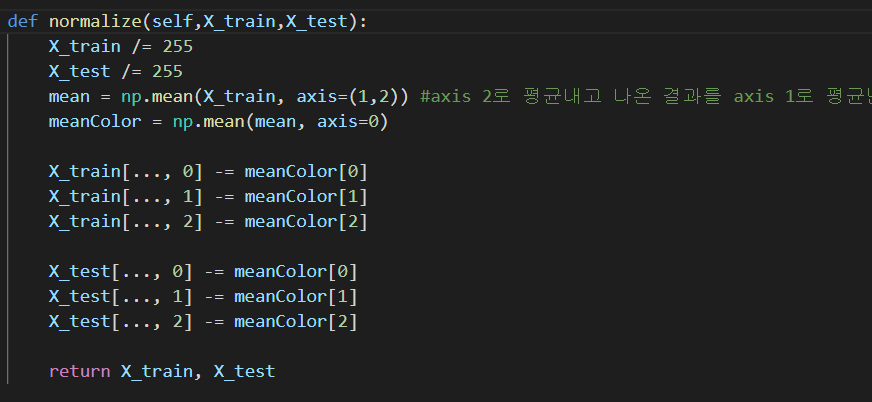 RGB의 평균을 빼는 부분인데 R값, G값, B값 각각 빼는 것 같아 이렇게 사용했다.
RGB의 평균을 빼는 부분인데 R값, G값, B값 각각 빼는 것 같아 이렇게 사용했다.
실제로 https://github.com/keras-team/keras/blob/master/keras/applications/vgg16.py#L227-L230
의 링크로 가면 각 색상마다 빼주는 것으로 나온다.
 32 x 32 이미지이므로 crop은 하지 않았다.
32 x 32 이미지이므로 crop은 하지 않았다.
 optimizer는 adam보다 SGD(momentum=0.9)가 더 금방 loss가 줄어드는 거 같았다.(여러 번 해본 것은 아니라 단정할 수 없다.)
optimizer는 adam보다 SGD(momentum=0.9)가 더 금방 loss가 줄어드는 거 같았다.(여러 번 해본 것은 아니라 단정할 수 없다.)
이미지 참조 : https://bskyvision.com/504, https://arxiv.org/pdf/1409.1556.pdf, https://neurohive.io/en/popular-networks/vgg16/
내용 참조 : https://arxiv.org/pdf/1409.1556.pdf
