Object Detection
object detection 문제는 classification보다 더 어려운 문제로 multiple objects에서 각각의 object에 대해 classification + localization(객체의 위치를 bounding box로 찾는 것)을 수행하는 것이다.

object detection에는 1-stage, 2-stage detector로 나뉘는데 오늘 볼 RCNN은 2-stage detector이다.
우선, object가 있을만한 영역을 뽑아내고 각 영역들을 convnet을 통해 classification, box regression을 수행한다.
RCNN 이전에는 sliding window 방법을 주로 사용했는데, 이는 시간이 너무 오래걸리기 때문에 RCNN같은 방법이 제안되었다.
RCNN
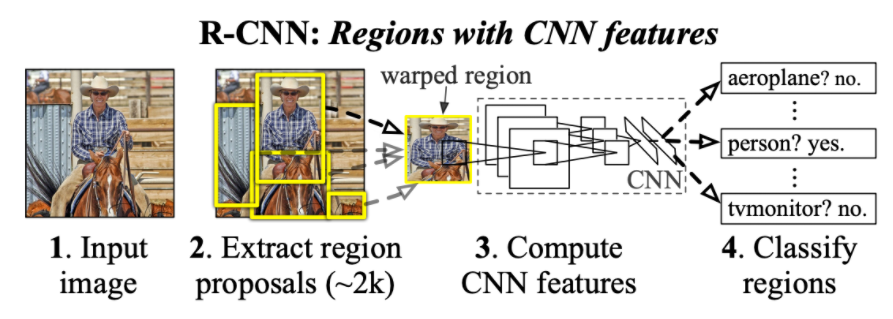
RCNN의 절차
-
Selective Search로 region proposal
-
1번에서 나온 이미지를 동일한 size로 warping
-
CNN과 fc layer를 통과시켜 나온 결과를 하나는 SVM을 통해 분류, 또 하나는 좌표에 대한 regression을 진행한다.
실험결과 CNN classifier보다 SVM을 쓰는 것이 성능이 더 좋았다고 한다. 그리고 우선 학습은 softmax로 진행한 후에 그것을 SVM의 input으로 쓰고 한 번더 SVM(class개수만큼 binary svm)으로 학습해 분류를 진행한다.
논문의 저자들은 이미지넷2012 데이터로 미리 학습된 CNN 모델을 가져와 fine tuning하는 방식을 취했다고 한다.
fine tuning 시에는 실제 object detection을 적용할 데이터셋에서 ground truth에 해당하는 이미지를 가져와 학습시켰다고 한다.
그리고 classification 클래스 수를 아무것도 없는 배경까지 포함해 N+1로 맞췄다고 한다.
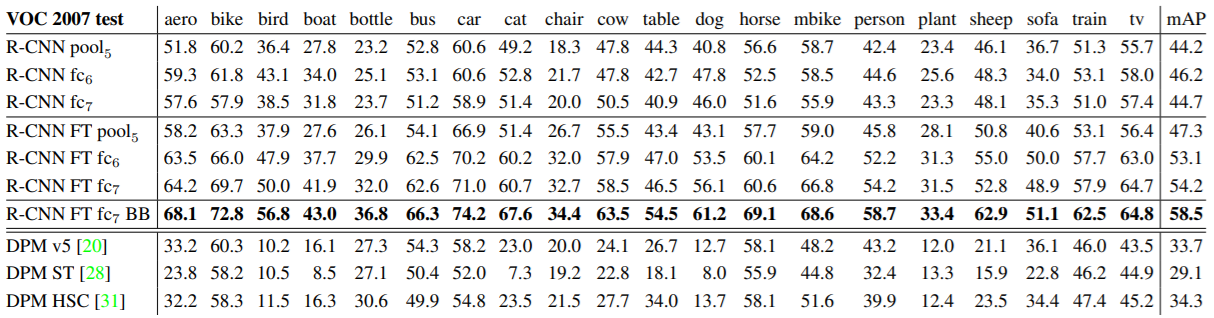
FT가 의미하는 것이 fine tuning이다.
dpm은 sliding window로 영역을 뽑아 HOG와 같은 알고리즘을 적용해 detection하는 방법이라고 한다.
mAP는 object detection 분야에서 사용되는 정확도 측정 지표인데, 다른 포스팅에서 소개하도록 하겠다.
BB는 bounding box regression을 적용한 것을 의미한다.
Non-Maximum Suppression
위에서 selective search를 보면 2000개의 박스를 제안하는데 2000개가 모두 필요하지 않다.
아래의 사진처럼 동일한 물체에 여러 개의 박스가 쳐져있는 경우도 존재한다.

이러한 경우에는 가장 정확?한 박스만 남기고 나머지는 제거해야 하는데 이때 쓰이는게 Non-Maximum Suppression(NMS)이다.
그러면 어떻게 겹쳐있는 지 판단할 것인가에서
IOU라는 개념이 등장한다.
IOU는 Intersection Of Union의 약자로 아래의 그림이 잘 설명한다.
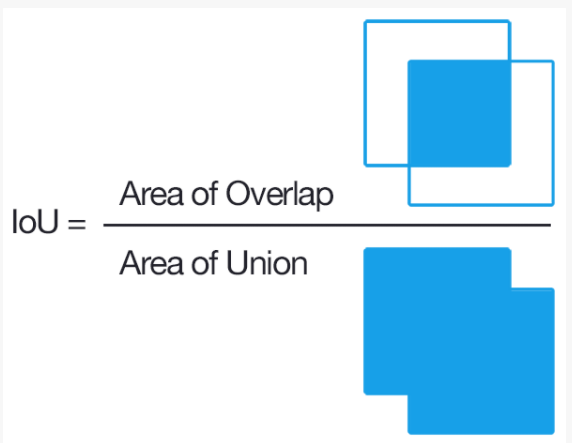
논문에서는 IOU가 0.5보다 크다면 동일한 물체를 대상으로 여러 번 친 박스라고 판단하고 NMS를 적용한다.
NMS 절차
- confidence가 가장 높은 박스를 선택하고 박스 리스트에서 제거하고 최종 아웃풋 리스트에 추가한다.
- 선택한 박스와 다른 모든 박스를 비교한다. 이 박스와 다른 박스들의 IOU를 계산하고 임계값보다 크다면 박스 리스트에서 제거한다.
- 이 과정을 박스 리스트가 빌 때까지 반복한다.
- 각 클래스에 대해 반복한다.
bounding box regression
selective search를 통해 찾은 박스는 부정확한 편인데, 이 성능을 끌어올리기 위해 박스 위치를 교정해주는 것을 bounding box regression이라 한다.
박스의 중심점을 (x, y), 너비와 높이를 (w, h)라고 할 때
ground truth의 박스도
라 표현할 수 있다.
우리의 목표는 박스가 최대한 G에 가깝도록 하는 함수를 학습시키는 것이다.
수식으로 표현해본다면
x, y는 단순 좌표이기 때문에 이미지의 크기와 관계없다.
하지만 w, h는 이미지의 크기에 비례하하게 조정을 시켜주어야 한다.
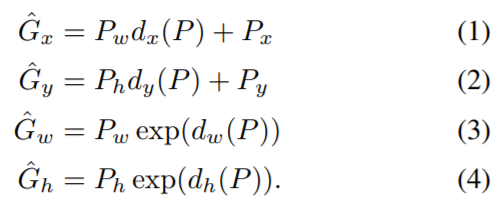
논문의 저자는 d함수를 구하기 위해 특징 벡터를 사용하며 함수에 학습 가능한 웨이트 벡터를 주어 계산한다. 그것을 식으로 나타내면 아래와 같다.
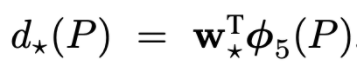
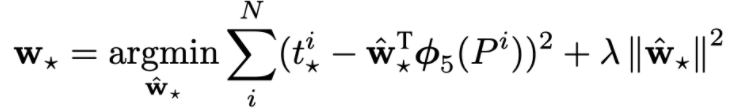
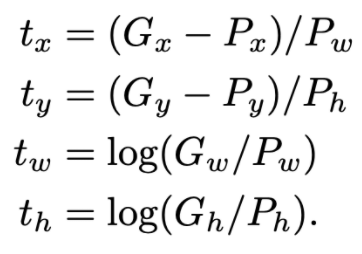
는 VGG Net의 pool5를 거친 피쳐맵을 의미한다. 여기서 P는 selective search를 거치고 나오고 region proposal되어 warp된 이미지
두번째 사진은 웨이트를 학습시킬 loss function이고, MSE 함수에 L2 normalization을 추가했다.
저자들은 람다를 1000으로 설정하였다고 한다.
t는 P를 G로 이동시키기 위해 필요한 이동량을 의미한다. 위의 식에서 이항시키고 나눠준 거라고 생각하면 된다.
test시 GPU에서는 13초, CPU에서는 54초가 걸린다고 한다.
2천개의 이미지에 대해 CNN을 돌리기 때문에 오래 걸릴 수 밖에 없다.
정확도는 Pascal VOC 2010 기준 53.7%로 정확도는 면에서는 엄청난 향상을 이뤄냈지만 실시간의 사용으로는 무리가 있는 것을 알 수 있다.
기존 Classification에 비해 매우 복잡해졌기 때문에 detection 모델은 지금도 쓸만한? 모델들만 구현해보려고 한다.
그러므로 RCNN은 구현은 pass하겠다.
이미지 링크 : https://hoya012.github.io/blog/Tutorials-of-Object-Detection-Using-Deep-Learning-what-is-object-detection/ , https://www.pyimagesearch.com/2014/11/17/non-maximum-suppression-object-detection-python/ , https://arxiv.org/pdf/1311.2524.pdf , https://ndb796.tistory.com/502
내용 참고 : https://yeomko.tistory.com/13 , https://arxiv.org/pdf/1311.2524.pdf
