기존의 RCNN은 뒤에 FC layer가 붙기 때문에 고정된 input size를 넣어줘야 했다.
이 때문에 warping하는 부분이 있었는데 이 때문에 화질이 깨지거나 원하지 않는 모양으로 바뀌는
문제가 있었다.
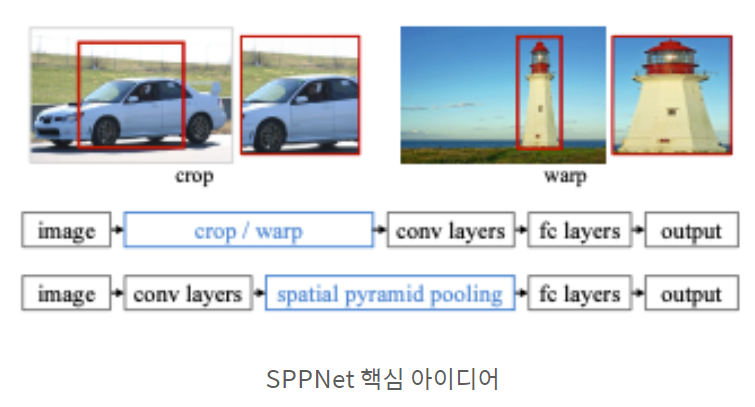
이를 해결하기 위해 위의 사진처럼 아이디어가 나왔다.
사실 conv layer는 input size가 고정될 필요가 없다. sliding window 방식으로 동작하기 때문이다.
conv를 거친 뒤에 고정된 사이즈로 만들기 위해 SPP가 제안이 된다.
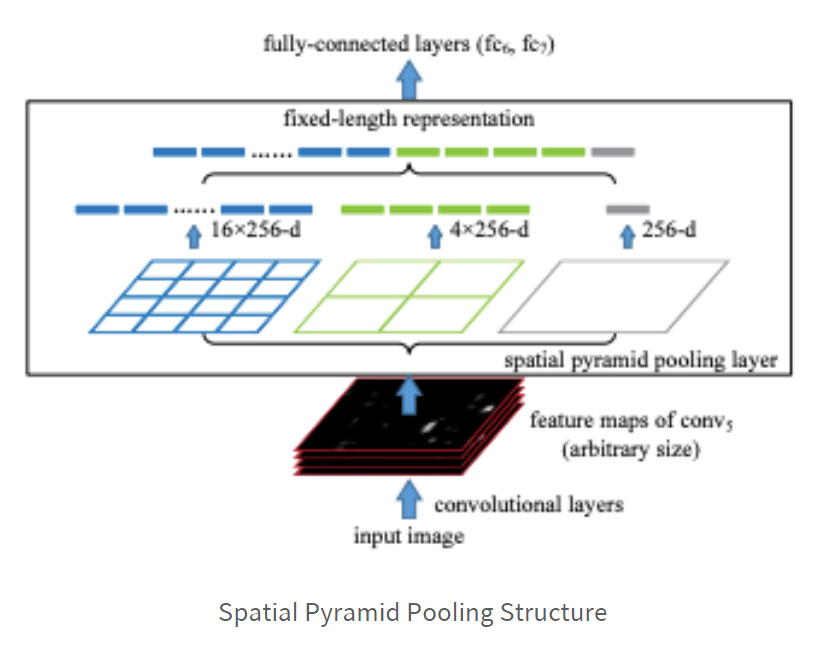
위의 이미지는 spp의 구조로 pooling작업으로 파란색 사각형은 feature map을 4x4 사이즈로 만들고, 연두색 사각형은 2x2 사이즈로 만들고, 회색 사각형은 하나의 사각형으로 만드는 작업이다.
저렇게 만들면 (16 + 4 + 1) * 256(채널)의 사이즈로 고정으로 만들 수 있다.
이렇게 되면 input size의 관계없이 고정된 사이즈로 만들 수 있게 된다.
(논문의 저자는 1x1, 2x2, 3x3, 6x6 4개의 피라미드로 구성했다고 한다.)
마지막으로 정리한다면,
입력 이미지를 conv layer를 통과시켜 feature map을 뽑아내고
입력 이미지에 대해 selective search를 적용한 결과를
feature map에 매핑하고 spp를 통과하여 사이즈를 고정시킨다.
그 후에 fc layer를 통과시켜 기존 RCNN과 동일하게 SVM과 bbox regression을 통해
output을 도출한다.
오직 pooling 연산만을 사용하므로 연산 속도 상승과 성능적인 부분(warp로 인한 데이터 손실이나 왜곡이 일어나지 않기 때문에)에서도 기존 RCNN에 비해 향상되었다고 한다.
참고 사항 : https://yeomko.tistory.com/14
