등장 배경
깊은 네트워크의 문제점
-
Vanishing/Exploding gradient : CNN에서 파라미터를 update할 때 그레디언트 값이 너무 크거나 작아져 더 이상 학습의 효과가 없는 문제를 의미한다.
망이 깊어질수록 문제가 커지며, 이를 위해 batch normalization과 같은 기법이 있지만, layer가 일정 수를 넘어간다면 해당 문제는 여전히 남아있다. -
학습이 어려워지는 문제 : 망이 깊어짐에 따라 파라미터의 수가 늘어 오버피팅 뿐만 아니라 에러가 커지는 문제가 발생한다.
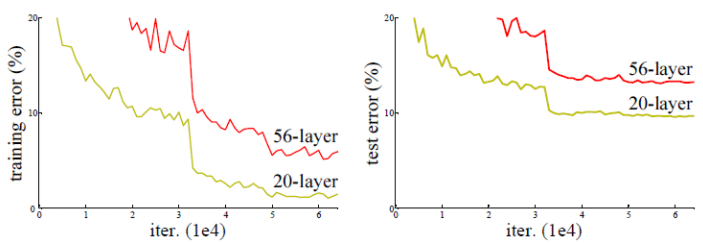
ResNet 팀은 위의 그림처럼 실험했고 더 깊은 신경망인 56-layer의 성능이 더 좋지 않은 것을 확인하였다.
이를 위해 아래와 같은 구조인 residual learning을 제시했다.
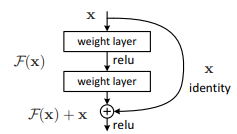
ResNet의 구조
일반적인 신경망과는 달리 덧셈이 추가되었다. 이는 추가적인 파라미터가 필요없다.
또한, 연산량을 위해 drop out, fc, maxpooling을 사용하지 않았다.
그리고 VggNet의 설계 철학?을 지켰는데, feature map의 사이즈가 줄어들 때에는 연산량의 균형을 위해 필터의 수는 두 배로 증가시켰다. 또한, feature map의 크기(w, h)가 같을 때엔 해당 layer에서 모두 동일한 filter 수를 가지게 했다.
그리고 사이즈를 줄일 때에는 pooling 대신에 convolution의 stride를 2로 진행하였다.
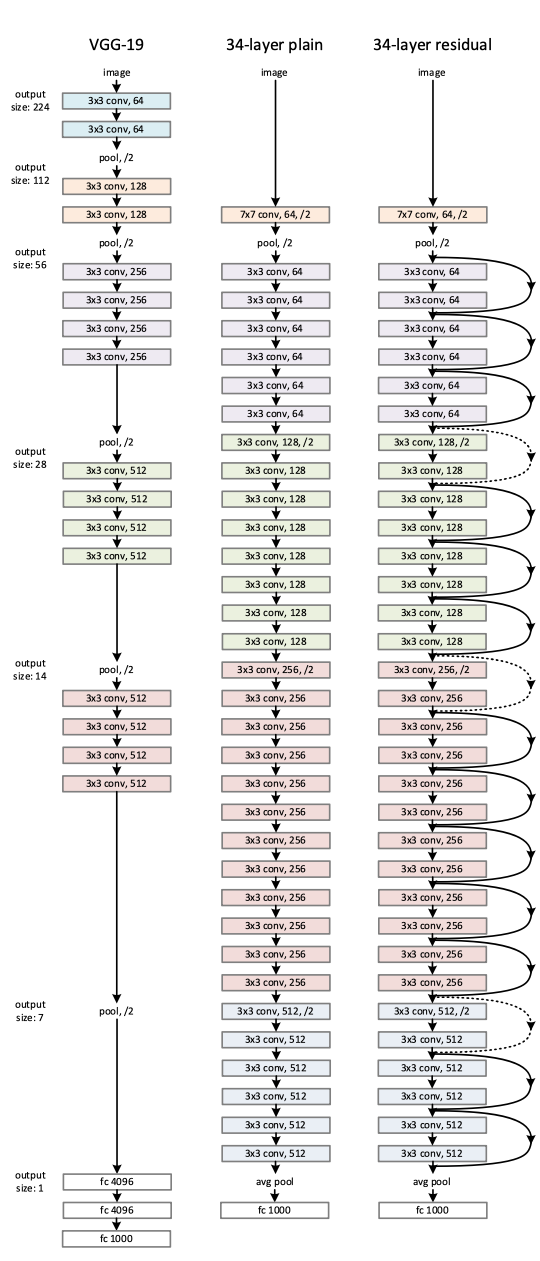
위와 같은 구조로 아래처럼 일반적인 신경망에 비해 층이 깊어짐에도 좋은 성능을 내는 것을 확인할 수 있다.
그리고 ResNet50부터는 기본 구조를 아래의 이미지처럼 변경하였다.
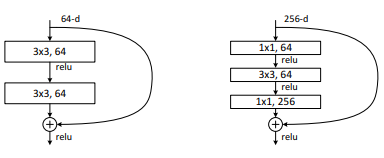
googleNet에서 봤던 1x1 conv를 추가하여 차원감소를 노렸고, 그 후 3x3 conv 후 다시 1x1 conv를 통해 차원을 확대시켰다.
이를 통해 3x3 conv를 두 번 한 것보다 연산량을 절감시킬 수 있었다.
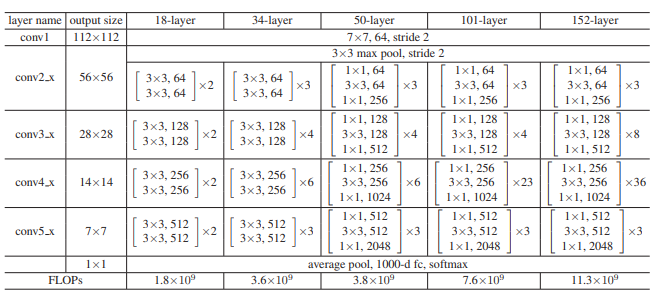
아래의 이미지는 각 층에 따른 구조이다.
잘 보면은 FLOPs가 층이 매우 깊어짐에도 엄청난 차이를 보이지 않는다.
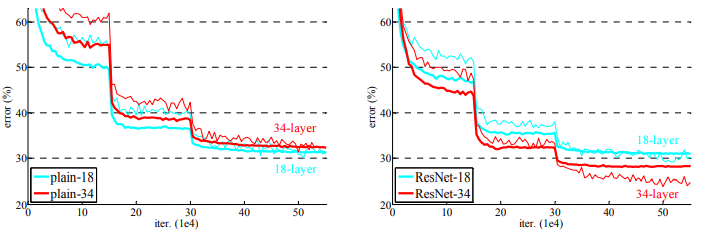
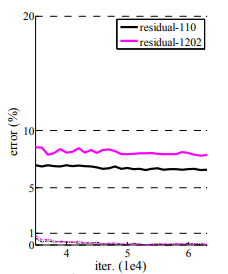
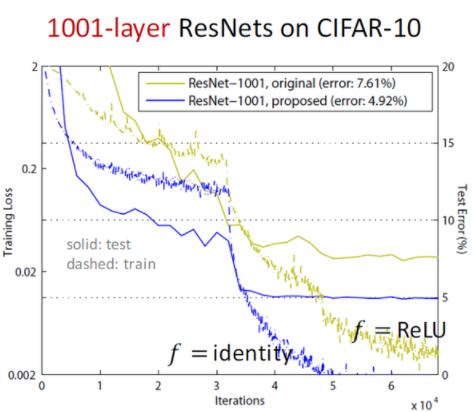
resnet이 깊은 신경망에서도 좋은 성능을 이뤄낼 수 있었지만, 층이 1000개를 넘어가니 성능이 저하되는 부분도 있었다. 하지만 어느 정도 최적화가 가능했다고 한다.
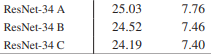
아래의 이미지에서 A, B, C로 나눠 성능을 평가했는데, 여기서 A는 F(X) + X 부분에서 사이즈가 다를 경우 X에 zero-padding한 경우를 의미하며, B는 사이즈가 다를 때 projection을 하고 나머지에는 단순 identity로 진행한 경우, C는 모든 경우에 projection을 진행한 경우의 차이다.
차이가 미미하기 때문에 크게 신경쓰지 않아도 될 것 같다. 대체로 B나 C가 많이 쓰이는 거 같다.
그리고 저자는 shortcut을 적용하지 않은 네트워크와 비교했을 때 차이가 나는 것을 vanishing/exploding gradient가 아니라 convergence rate(최적화 수렴 난이도?)가 떨어지기 때문이라고 추정하고 있다.
이런 효과를 가지고 2015 ILVRC에서 우승할 수 있었다.
pre-activation resnet
resnet에서 skip connection의 위치와 activation위치에 따라 어느 것이 더 성능이 좋은지 여러 것을 실험하였고
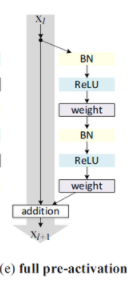
위와 같은 구조를 pre-activation이라고 하며 앞에 오는 BN 덕에 regularization 효과를 볼 수 있었다.
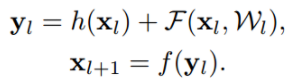
위의 식은 기존 residual의 계산식이다.
h는 identity, f는 활성화 함수, F는 residual block안에 conv를 거친 함수이다.
만일 f가 relu가 아닌 identity라면
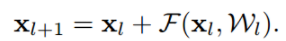
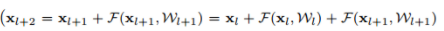
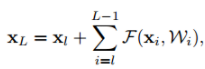
으로 간단히 나타낼 수 있고, 초기 입력값이 최종 레이어까지 남아있게 된다.
이는 역전파시 1이 남아있게 되어(우측 항은 -1이 될 수 없기 때문) 기울기 값이 소실되지 않는다.
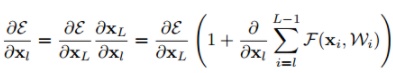
그래서 f를 identity로 바꾸기 위해 위의 사진처럼 pre-activation 구조로 바꿨다.
기존 resnet은 Skip connetion을 거쳐서 입력값과 출력값이 더해지고, ReLU 함수를 거친다. 결과 값이 음수라면 relu를 거쳐 0이 된다.
만약, 층이 깊다면 이 증상의 영향이 더 커지게 되어 더 많은 값이 0이 될 수 있다.
이때문에 초기 학습시에 불안정해져 수렴이 되지 않습니다.
하지만 pre-activation 구조는 relu를 거치지 않기 때문에 음수 값도 그대로 이용하게 된다.
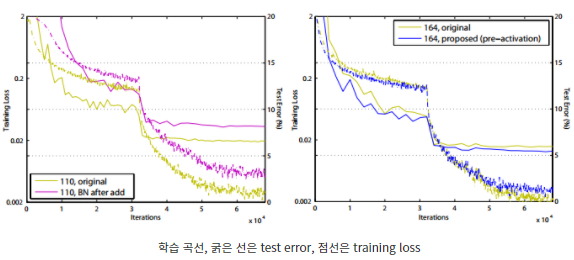
위 그림을 보면 수렴지점에서 pre-activation 구조의 training loss가 original보다 높지만 test error가 낮은 것은 오버피팅을 방지하는 효과가 있다는 것을 의미한다.
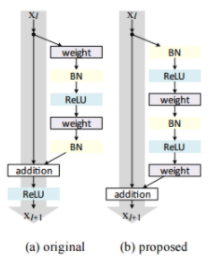
original Residual unit은 BN을 거치고 값이 short cut에 더해집니다.
따라서 더해진 값은 정규화되지 않습니다. 이 정규화되지 않은 값이 다음 convolution layer 입력값으로 전달됩니다.
Pre-activation Residual unit은 더해진 값이 BN을 거쳐서 정규화 된 뒤에 convolution layer에 입력됩니다. 따라서 overfitting을 방지한다고 저자는 추측한다.
구현
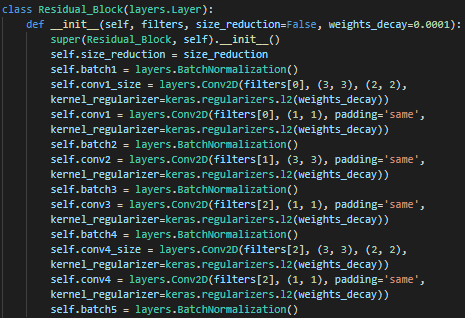
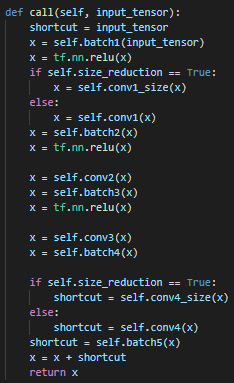
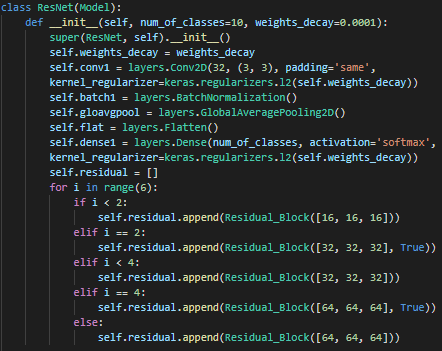
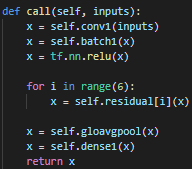
pre-activation 방법으로 구현했다.
googleNet에 비해 training 데이터가 수렴하는 것이 훨씬 더뎠고, epoch가 500회를 넘어도 트레이닝 데이터에 대해 92% 주변에 머물었다.
하지만, 테스트 데이터에 대해선 googleNet보다는 더 좋은 성능을 볼 수 있었다.
참고 사항 : https://www.cv-foundation.org/openaccess/content_cvpr_2016/papers/He_Deep_Residual_Learning_CVPR_2016_paper.pdf, https://deep-learning-study.tistory.com/510
