GoogleNet 배경
CNN은 이미지에서 일반적인 구조가 되었습니다.
AlexNet 이후에 2014년 ILSVRC에서 우승한 GoogleNet을 알아본다.
일반적으로 신경망의 성능을 향상시키는 방법은 네트워크의 크기(넓이와 깊이)를 키우는 것이다. 하지만, 큰 네트워크일 수록 많은 파라메타를 가지게 된다.
파라미터가 많아진다면 오버피팅이 일어나게 될 가능성이 생기는데, 이를 해결하기 위해선 데이터의 수를 늘려야 하는데 이 일은 생각보다 쉽지 않다.
또한, 신경망이 커질수록 연산량이 많아져 컴퓨터의 리소스를 많이 사용하게 된다. (연산량이 많아진다고 무조건 성능이 좋아지는 것도 아님.) Vanishing gradient 문제도 남아있다.
이를 위해 Dropout 같은 방법이 도입되었지만, 근본적인 해결책이 아니다.
GoogleNet은 AlexNet보다 12배나 적은 가중치로 더 좋은 성능을 이뤄낼 수 있다고 했는데 어떻게 했는지 알아보자
google은 mobile, embedded 등의 다양한 환경에서 자유롭게 사용될 수 있어야 한다고 주장한다. 그래서 더 깊이 쌓으면서도 파라미터를 줄이는 방향으로 생각한 것 같다.
Network In Network
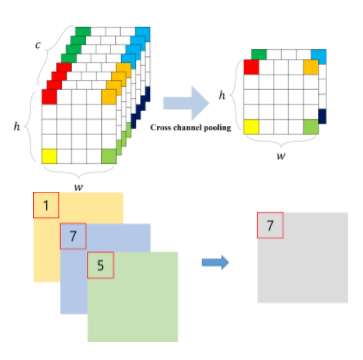 위의 사진은 NIN(Network In Network)에서 Cascade Cross Channel Pooling이라는 기법이라고 하는데, 잘 보면 1*1 conv filter와 유사하다는 것을 알 수 있다. 실제로 저자도 동일하다고 주장한다.
위의 사진은 NIN(Network In Network)에서 Cascade Cross Channel Pooling이라는 기법이라고 하는데, 잘 보면 1*1 conv filter와 유사하다는 것을 알 수 있다. 실제로 저자도 동일하다고 주장한다.
이 1x1 convolution은 특히나 차원감소 효과가 탁월했다. feature map으로부터 유사한 성질들을 묶어낼 수 있고 수를 줄일 수 있다.
NIN의 설계자는 Convolution layer가 local receptive field에서 특징을 추출해내는 능력은 좋지만, filter의 특징이 linear하기 때문에 비선형적인 특징을 추출하기엔 어렵기 때문에 feature map의 개수를 늘리는 것에 집중했다. 이를 위해 convolution을 수행하는 filter 대신 MLP를 사용해 feature를 추출하도록 했다.
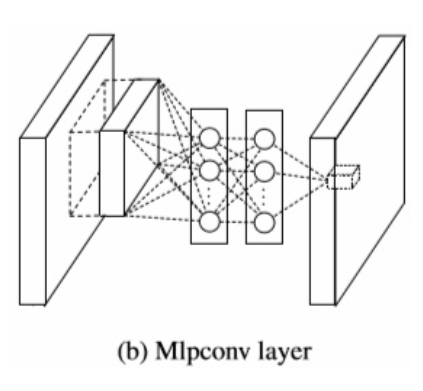
이를 통해 기존 convolution kernel보다 비선형적인 성질을 활용해 특징을 잘 추출할 수 있게된다.
또한, GlobalAveragePooling을 FC대신에 사용하였다.
앞의 Convolution 단에서 MLP를 도입해 좋은 feature를 추출했으므로 average pooling으로 충분하다고 주장한다.
이를 통해 overfitting의 문제를 피할 수 있고, 연산량이 대폭 감소할 수 있다.
하지만, googleNet에서는 비선형성보다는 차원감소의 효과를 좀 더 중요하게 생각하는 듯하다.
Inception module 구조
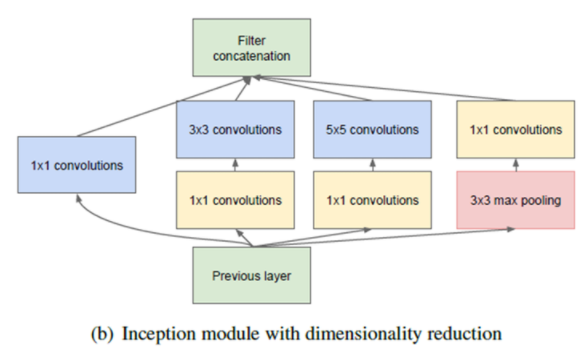 위의 사진은 Inception module의 구조이다. 위에서 설명한 이유로 1x1 Convolution을 넣은 이유를 알 수 있었고
위의 사진은 Inception module의 구조이다. 위에서 설명한 이유로 1x1 Convolution을 넣은 이유를 알 수 있었고
google은 다양한 feature를 뽑기 위해 여러 개의 convolution을 병렬적으로 활용하려고 하였다. 그래서 위의 모양처럼 나왔고, Dropout을 생각해봤을 때 정확도를 높여주지만, sparse한 연산은 리소스 측면에서는 비효율적이다. 그래서 google은 연산은 dense하게 하자는 의미로 conv 후에 concat하는 과정이 이런 목적을 담았다고 본다.
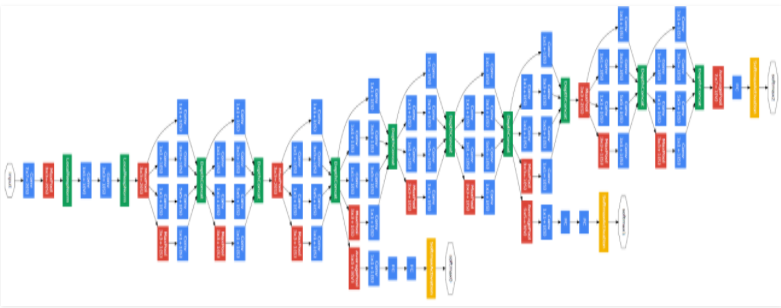
GoogleNet 구조
- Pre-Layer
- Inception Layers
- Global Average Pooling
- Auxiliary Classifier
인셉션 모듈은 저층에서의 학습효율이 떨어져 학습의 편의성을 위해 Pre-Layer가 추가되었다.
이 구간에서는 일반적인 CNN 연산을 거친다.
인셉션 계층은 총 9번의 Inception Module을 거쳐 총 22층의 레이어를 구성하였다.
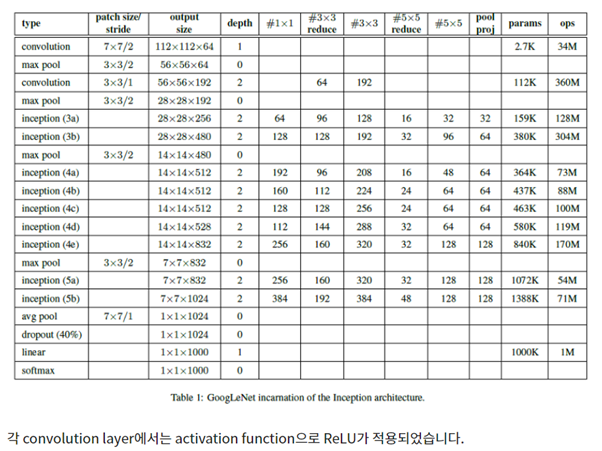
GAP(Global Average Pooling)은 위에서 이미 언급한 부분을 제외한 이점은 풀링 과정이므로 어떠한 파라미터도 학습을 위해 추가로 발생하지 않는 이점이 있다.
실제로 GAP 이후에 FC가 붙기는 했지만 이는 class 개수를 맞추기 위함이다.
마지막으로 Auxiliary Classifier는 네트워크가 깊어짐에 따라 Vanishing Gradient의 위험을 안게 되는데, 이를 피하기 위해 연산 중간에 분류를 해 backpropagation이 앞단까지 전파될 수 있게끔 하는 것이다. 학습을 위해 존재하므로 학습이 완료가 되면 사용하지 않는다.
GoogLeNet은 ILSVRC14에서 1위를 거머쥐긴 했으나, 사실 VGGNet에 비해 잘 이용되지는 않았습니다. 구조가 너무 복잡하다는 것이 이유였지요. 때문에 이후로도 Inception module은 여러차례의 수정을 거치게 된다.
구현
Learning rate decay, BatchNormalization 외에는 딱히 쓰지 않았다.
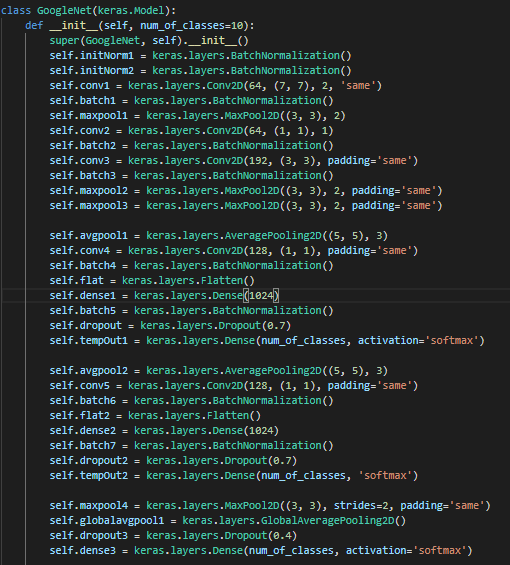
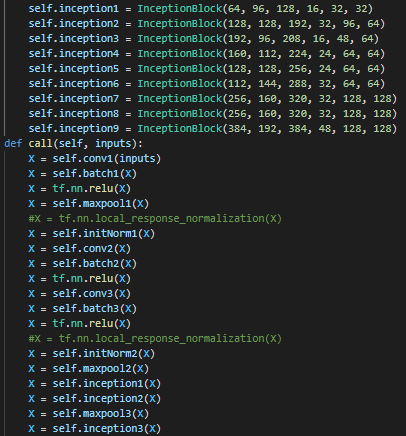
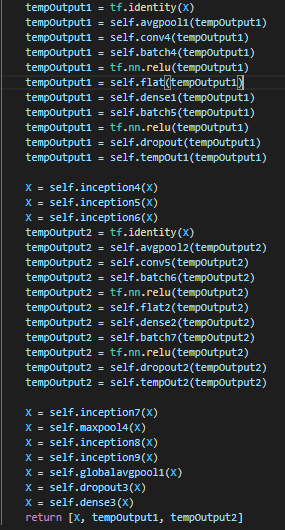

이미지 참조 : https://89douner.tistory.com/62, https://poddeeplearning.readthedocs.io/ko/latest/CNN/GoogLeNet/, https://blog.naver.com/laonple/220692793375
