
본 게시글은 A (Mostly) Complete Guide to React Rendering Behavior 게시글을 바탕으로 씌여졌습니다.
I. React의 개요와 필요성
React의 동작 가이드에 대해 알아보기에 앞서 왜 React를 사용해야 하는지에 대해 리액트의 렌더링 과정에 대해 간략히 짚고 넘어가보겠습니다.
Document Object Model
DOM
DOM은 웹페이지에 대한 인터페이스로 브라우저가 웹페이지의 콘텐츠와 구조를 어떻게 보여줄 것인지에 대한 정보를 담고 있습니다.
Critical Rendering Path
웹 브라우저의 동작 원리는 간략하게 정리하자면 아래와 같이 네 단계로 나눌 수 있습니다.
① HTML은 DOM으로, CSS는 CSSOM으로 변환
② Render Tree 생성
③ Layout: Render Tree를 기반으로 요소 배치
④ Painting: 실제로 요소들을 화면에 그려내는 과정이 과정에서 DOM이 수정되면 전체 과정이 반복되며, 이때 발생하는 reflow와 repaint는 많은 연산을 필요로 하므로 성능에 영향을 미칩니다.
🤷🏻♀️ Why React?
위의 과정에서 DOM이 수정되면 브라우저는 전체 과정을 다시 수행해야 하며, 이때 발생하는 리플로우(reflow)와 리페인트(repaint)는 웹 성능에 부정적인 영향을 미칩니다.
이를 방지하기 위해 DOM 조작을 최소화해야 하는데, React는 개발자가 별도로 신경쓰지 않아도 DOM 업데이트를 효율적으로 관리하며 최소한의 렌더링만 수행할 수 있도록 도와줍니다.
II. React의 아키텍처
🥊 Stack vs Fiber
React는 초기에는 Stack Reconciler 구조를 사용했으나, 대규모 애플리케이션에서 성능 이슈를 야기할 수 있었습니다. 이러한 재귀적으로 동작하는 재귀 호출 스택의 문제를 해결하기 위해 Fiber 아키텍처로 변경되었습니다.
Stack Reconciler
모든 UI 업데이트를 한 번에 처리하므로,
큰 작업이 메인 스레드를 오래 점유하게 됩니다.
Fiber Architecture
UI 업데이트를 작은 작업 단위로 나누어 처리하며,
메인 스레드 점유 시간을 줄여 UI의 응답성을 향상시킵니다.재귀적으로 동작하는 재귀 호출 스택?
재귀 함수 호출(Recursive Function Call)
재귀 함수는 자기 자신을 호출하는 함수입니다. 재귀 함수는 일반적으로 특정 조건이 만족될 때까지 계속 자신을 호출하며, 각 호출이 끝날 때마다 반환되는 것이 특징입니다.
호출 스택(Call Stack)
호출 스택은 프로그램이 함수 호출을 추적하는 데 사용하는 구조입니다.
함수를 호출하면 그 함수의 정보가 스택에 추가되며, 함수가 종료되면 스택에서 제거됩니다. 스택은 LIFO(Last In, First Out) 구조이므로, 마지막에 호출된 함수가 가장 먼저 종료됩니다.
재귀 호출 스택
리액트의 초기 렌더링 알고리즘은 컴포넌트 트리를 순회하는 방식으로 동작했습니다.
이 때 재귀 호출을 사용하여 부모 컴포넌트가 자식 컴포넌트를 렌더링하고, 자식 컴포넌트가 또 그 자식을 렌더링하는 방식으로 내려갑니다.
이 과정에서 리액트는 재귀 호출 스택을 사용하여 각 컴포넌트의 렌더링 과정을 추적했습니다.
이러한 접근 방식은 작은 트리 구조에서는 잘 동작하지만, 컴포넌트 트리가 매우 깊거나 복잡해졌을 때 문제가 생기게 됩니다.
① 스택 오버플로우
너무 깊은 재귀 호출은 호출 스택의 한계를 초과하여 스택 오버플로우를 발생시킴
② 비효율성
모든 작업이 한 번에 처리되기 때문에, 렌더링이 완료될 때까지 UI의 중단 불가
이러한 점은 대규모 애플리케이션에서 사용자 경험을 저하를 야기Fiber 아키텍처
이러한 문제를 해결하기 위해 리액트는 Fiber라는 새로운 구조를 도입했습니다.
Fiber는 재귀 호출을 사용하지 않고, 컴포넌트 트리의 각 노드를 순차적으로 탐색할 수 있도록 하여 작업을 작은 조각으로 나누어 처리합니다. 아키텍처의 변경으로 리액트는 더 복잡한 UI에서도 높은 성능을 유지할 수 있게 되었습니다.
Fiber Algorithm
Fiber 알고리즘은 작업을 쪼개고 우선순위에 따라 효율적으로 스케줄링하는 방법을 정의하며, 이를 통해 리액트는 다음과 같은 기능을 제공합니다.
1️⃣ 유연한 렌더링
렌더링 작업을 유연하게 관리하여 UI의 응답성을 높입니다.
2️⃣ 성능 최적화
작업을 작은 단위로 나누어 메인 스레드의 차단을 최소화합니다.
3️⃣ 비동기 작업 처리
비동기 작업을 효율적으로 처리하여 복잡한 애플리케이션에서도 성능을 유지합니다.III. Reconciler와 Fiber
🧐 Reconciler
React의 Reconciler는 컴포넌트 트리를 탐색하여 어떤 자식 요소를 렌더링할지 결정하고, 가상 DOM과 실제 DOM을 비교해 최소한의 변경만 적용합니다.
이 과정을 재조정(Reconciliation)이라 하며, 성능을 최적화하고 불필요한 DOM 업데이트를 방지합니다.
[Reconciler 단계]
1️⃣ Diffing
- 이전 가상 DOM과 새로운 가상 DOM을 비교하여 변화된 부분을 찾는 단계
- react는 이를 통해 변경된 요소만을 식별
2️⃣ Rendering
- 변화된 부분을 실제 DOM에 반영하는 단계
- react는 변경 사항을 최소화하여 성능을 최적화Stack 기반에서 Fiber 기반으로 전환
Stack 기반 Reconciler는 트리 전체를 한 번에 처리하므로 긴 작업을 중단할 수 없지만, Fiber Reconciler는 작업을 작은 단위로 나누어 처리하며 우선순위를 동적으로 관리할 수 있습니다. 이로 인해 사용자 인터페이스의 반응성을 유지할 수 있습니다.
-
Abort/Stop/Restart
Fiber는 작업을 중단(abort)하거나 멈춤(stop)으로써 더 중요한 작업을 먼저 처리할 수 있습니다.
필요할 경우 중단된 작업을 다시 시작(restart)할 수 있습니다. -
렌더링 우선순위 변경
React는 작업의 우선순위를 동적으로 변경할 수 있으며, 이를 통해 사용자 인터페이스의 반응성을 유지합니다.
useTransition 훅이 이러한 기능을 활용하는 예입니다.
Fiber의 작동 과정
1️⃣ 단위 작업 분할
Time Slicing이라고도 하는 단위 작업 분할 과정은 렌더링 작업을 작은 단위로 나누어 처리하는 것을 말합니다. 나뉘어진 작은 작업 단위(chunk)들은 각각 독립적으로 실행되며, 단위 작업이 끝날 때마다 메인 스레드는 잠시 휴식 시간을 가집니다.
단위 작업 분할은 작은 단위로 나누어 일정한 시간을 두고 실행되며, UI가 반응성을 유지할 수 있도록 합니다. 따라서 이 방식은 긴 작업을 효율적으로 처리하면서도 사용자가 느끼는 지연을 최소화할 수 있도록 도와줍니다.
2️⃣ 작업 우선순위 관리
Fiber는 작업에 우선순위를 부여합니다.
높은 우선순위 작업은 즉시 처리하고, 낮은 우선순위 작업은 나중으로 미룰 수 있습니다. 이렇게 작업을 관리함으로써 중요한 작업이 지연되지 않도록 할 수 있습니다.
[우선순위 목록]
0 작업 없음 (작업 대기 중인 것이 없음)
1 동기적 우선순위 (제어된 텍스트 입력을 위한 동기적 부작용)
2 작업 우선순위 (현재 틱이 끝날 때 완료되어야 함)
3 애니메이션 우선순위 (다음 프레임 이전에 완료되어야 함)
4 높은 우선순위 (반응성을 느낄 수 있도록 빠르게 완료되어야 하는 상호작용)
5 낮은 우선순위 (데이터 가져오기 또는 스토어 업데이트 결과)
6 오프스크린 우선순위 (화면에 보이지 않지만 나중에 보일 가능성이 있어 작업 수행)3️⃣ 중단 및 재개
Fiber는 작업을 중단하고 나중에 재개할 수 있는 기능을 제공합니다.
예를 들어, 애니메이션 프레임이 필요할 때 긴 렌더링 작업을 중단하고, 프레임이 끝난 후 작업을 재개할 수 있습니다.
🧩 Fiber
🌳 Fiber Tree
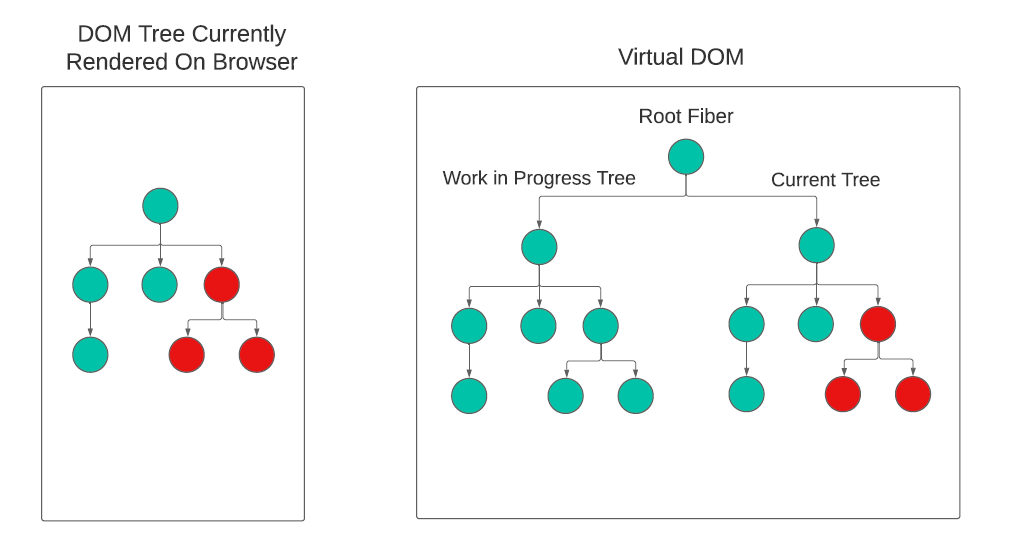
리액트에는 현재 상태를 나타내는 current tree와 작업 중인 workInProgress tree라는 두 개의 Fiber Tree가 존재합니다. 작업이 완료되면 React는 단순히 포인터를 변경해 workInProgress tree를 current tree로 바꾸는데, 이를 더블 버퍼링이라고 합니다.
- Work-in-Progress: 현재 작업 중인 Fiber 트리
- Current: 현재 화면에 렌더링된 Fiber 트리
- Root Fiber: 트리의 루트 노드로, 보통 `ReactDOM.render`로 생성된 노드1️⃣ current DOM
- DOM에 mount된 fiber
npx create-react-app@latest로 프로젝트 생성 후 파일을 살펴보면 id가 root인 element를 가져와 DOM의 root로 만드는 것을 확인할 수 있습니다.
아래가 바로 current tree를 만드는 코드입니다.
// 📂 src/index.tsx
const root = ReactDOM.createRoot(
document.getElementById('root') as HTMLElement,
);
root.render(
<React.StrictMode>
<App />
</React.StrictMode>
)// 📂 index.html
<body>
<noscript> ... </noscript>
<div id="root"></div> ✅
</body>2️⃣ workInProgress DOM
- render phase에서 작업 중인 fiber
- commit phase를 지나면서 current tree가 되고, 자기 복제 후 new workInProgress가 재생성됨
📌 정리
컴포넌트를 호출 → react element를 반환(return) → 반환 값이 fiberNode로 확장 → 그 결과가 VDOM에 반영
💡 component rendering
렌더링 과정 후 DOM에 mount되어 페인트(paint)가 되는 과정은 렌더링되지 않습니다.
🎪 Fiber Nodes
Fiber Nodes는 컴포넌트의 상태, props, 렌더 결과 등을 저장하며, 컴포넌트 트리의 각 요소를 나타냅니다. 이를 통해 컴포넌트 트리의 변화를 효율적으로 관리할 수 있습니다.
Fiber Node 구조
type:컴포넌트 타입 (함수, 클래스, 호스트 컴포넌트 등)stateNode: 컴포넌트 인스턴스 또는 DOM 노드return: 부모 Fiber 노드child: 첫 번째 자식 Fiber 노드sibling: 형제 Fiber 노드
⚙️ useTransition
Fiber 아키텍처는 React 18에서 도입된 useTransition 훅을 통해 비동기 작업을 처리하고 우선순위를 낮출 수 있습니다. 이를 통해 UI의 응답성을 유지하면서도 백그라운드에서 상태 업데이트를 수행할 수 있습니다.
import React, { useState, useTransition } from 'react';
function MyComponent() {
const [isPending, startTransition] = useTransition();
const [count, setCount] = useState(0);
const handleClick = () => {
startTransition(() => {
setCount(prevCount => prevCount + 1);
});
};
return (
<div>
<button onClick={handleClick}>
Increment
</button>
{isPending ? <p>Loading...</p> : <p>Count: {count}</p>}
</div>
);
}🔗 metaData & Fiber
Fiber 객체는 현재 렌더링되는 컴포넌트의 유형, 현재 Props와 State, 부모, 형제, 자식 컴포넌트에 대한 포인터, 그리고 렌더링 추적을 위한 메타데이터를 포함합니다. 이 구조를 통해 React는 컴포넌트를 효율적으로 렌더링하고 업데이트할 수 있습니다.
Render Pass 동안 React는 fiber tree를 순회하며 새로운 렌더링 결과물을 계산하여 업데이트된 트리를 생성합니다. Fiber 객체들은 컴포넌트의 실제 Props와 State 값을 저장하며, React는 이러한 값을 이용해 렌더링을 수행합니다. 다만, React는 값을 "복제하여" 사용하는 것이 아니라, fiber tree에 저장된 값을 기반으로 새로운 상태나 props를 계산하고 이를 렌더링하는 과정에서 활용합니다.
React Hook이 동작하는 이유는 React가 각 컴포넌트에서 사용되는 모든 hook들을 컴포넌트의 fiber와 연결된 연결 리스트(Linked List)로 관리하기 때문입니다. React는 함수형 컴포넌트를 렌더링할 때 해당 컴포넌트의 fiber에서 이 리스트를 참조하여 hook의 상태를 관리하고 업데이트합니다.
부모 컴포넌트가 자식 컴포넌트를 처음으로 렌더링할 때, React는 자식 컴포넌트의 인스턴스를 추적하기 위해 fiber 객체를 생성합니다.
1️⃣ 클래스형 컴포넌트
const instance = new YourComponentType(props) 호출
실제 컴포넌트 인스턴스를 fiber에 저장
2️⃣ 함수형 컴포넌트
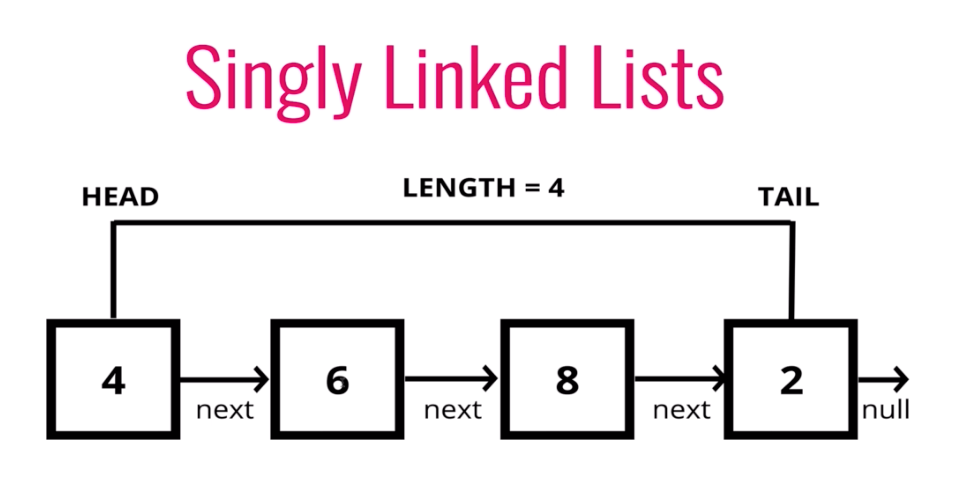
YourComponentType(props)를 함수로 호출💡 Linked List
node 안에 node.next 값이 다음 node를 가리키고 있습니다.
다음 node를 할당해 놓는다고도 할 수 있습니다.
즉, next라는 값으로 다음 node를 연결한 목록을 linked list라고 합니다.
IV. React의 주요한 개념
React는 가상 DOM을 관리하며, Fiber 아키텍처를 통해 효율적인 렌더링을 수행합니다. 이를 통해 개발자는 복잡한 UI를 쉽게 관리하고 성능 최적화를 수행할 수 있습니다.
간략하게 리액트에서 주요한 패키지와 용어들을 정리하자면 아래와 같습니다.
🎁 Package
react core
- component 정의
- 다른 패키지에 의존하지 않으므로 다양한 플랫폼에 렌더 가능
renderer
- 호스트와 리액트를 연결하는 역할
- 의존 : 호스트 렌더링 환경, reconciler, legacy-events
- 호스트 렌더링 환경 예시 → react-dom, react-native-renderer
event (legacy-events)
- react 내부적으로 개발된 이벤트 시스템으로 SyntheticEvent라고도 함
- react 내부적으로 이벤트를 사용하는데 추가적인 기능(기존 웹의 event를 wrap)이 필요했고 이를 수행할 수 있도록 하기 위해 개발된 패키지
scheduler
- react는 task를 비동기로 실행
- 각 task의 실행 타이밍을 관리하는(알고 있는) 패키지
reconciler
- fiber 아키텍처에서 VDOM을 재조정하는 역할 ⭐️
- 컴포넌트를 렌더링하는 공간
📖 Term
rendering
- 컴포넌트를 호출해 react element를 반환하고 이를 토대로 VDOM 재조정
react element
- 컴포넌트 호출 시 return하는 값
- JSX → babel을 통해
react.createElement함수로 호출 - 컴포넌트의 정보를 담은 객체
fiber
- VDOM의 노드 객체
- 아키텍처와 이름 같으나 다름
- react element가 DOM에 반영되기 위해 VDOM에 추가되는 과정에서 필요한 추가 정보를 제공하기 위해 확장한 객체 ⭐️
- 추가 정보의 종류 : 컴포넌트의 상태, life cycle, hook 등
V. React의 렌더링 과정
🎨 React의 렌더링
브라우저의 렌더링과 react의 렌더링
브라우저에서의 렌더링이란 간단히 말하자면 HTML과 CSS 리소스를 기반으로 웹페이지에 필요한 UI를 그려내는 과정을 의미합니다.
리액트의 렌더링은 브라우저가 렌더링에 필요한 DOM 트리를 만드는 과정을 의미합니다. 리액트도 브라우저와 마찬가지로 이 렌더링 작업을 위한 자체적인 렌더링 프로세스가 있습니다.
그리고 프론트엔드 개발자는 최적화를 위해 이러한 렌더링 프로세스를 이해하고 과정을 최소화할 수 있도록 노력해야 합니다. 리액트에서 렌더링은 시간과 리소스를 소비해 수행되는 과정으로, 이 비용은 모두 웹 애플리케이션을 방문하는 사용자에게 청구되기 때문입니다.
즉, 시간이 길어지고 과정이 복잡해질수록 사용자 경험(UX)은 저해될 수 있습니다.
react의 렌더링은 정리하자면, 리액트 애플리케이션 트리 안에 있는 모든 컴포넌트들이 현재 자신들이 갖고 있는 props와 state의 값을 기반으로 어떻게 UI를 구성하고 이를 바탕으로 어떤 DOM 결과를 브라우저에 제공할 것인지 계산하는 일련의 과정을 의미합니다.
렌더링 발생 시점
렌더링은 최초의 렌더링과 리렌더링(re-rendering)으로 나눌 수 있습니다.
최초의 렌더링은 사용자가 처음 애플리케이션에 진입했을 때 결과물을 보여주기 위한 과정입니다. 리액트는 브라우저에 결과물에 대한 정보를 제공하기 위해 최초 렌더링을 수행합니다.
리렌더링은 처음 애플리케이션에 진입했을 때 최초 렌더링이 발생한 이후에 발생하는 모든 렌더링을 지칭합니다. 리렌더링이 발생하는 경우는 아래와 같습니다 :
re-rendering이 일어나는 경우
리액트에서 리렌더링이 발생하는 경우는 아래 7가지 상황 뿐입니다.
아래 상황에 해당하지 않는다면 어떤 경우라도 리렌더링이 일어나지 않기 때문에 변경된 값을 DOM에서 확인할 수 없습니다.
1️⃣ 클래스 컴포넌트의 setState가 실행되는 경우
2️⃣ 클래스 컴포넌트의 forceUpdate가 실행되는 경우
3️⃣ 함수 컴포넌트의 useState의 두 번째 배열 요소인 setter가 실행되는 경우
4️⃣ 함수 컴포넌트의 useReducer의 두 번째 배열 요소인 dispatch가 실행되는 경우
5️⃣ 컴포넌트의 key props가 변경되는 경우
6️⃣ props가 변경되는 경우
7️⃣ 부모 컴포넌트가 렌더링될 경우React의 렌더링 프로세스, 재조정(reconciliation)
렌더링 프로세스가 시작되면 react는 컴포넌트의 루트(root)에서부터 위에서 아래 방향으로 내려가며 업데이트가 필요하다고 저장돼 있는 모든 컴포넌트를 찾습니다.
만약 여기서 업데이트가 필요하다고 지정돼 있는 컴포넌트를 발견하면
클래스 컴포넌트의 경우에는 클래스 내부의 render() 함수를 실행하게 되고,
함수 컴포넌트의 경우에는 FunctionComponent() 자체를 호출한 뒤 결과물을 저장합니다.
이런 과정들을 거치며 각 컴포넌트의 렌더링 결과물을 수집한 다음, 리액트의 새로운 트리인 가상 DOM과 비교해 실제 DOM에 반영하기 위한 모든 변경 사항을 차례차례 수집합니다.
위의 일련의 과정을 리액트에서는 재조정(reconciliation)이라고 하며 과정이 모두 끝나면 모든 변경 사항을 하나의 동기 시퀸스(sequence)로 DOM에 적용해 변경된 결과물을 사용자에게 보여줄 수 있게 됩니다.
(VDOM, 가상 DOM)
👭 Virtual DOM
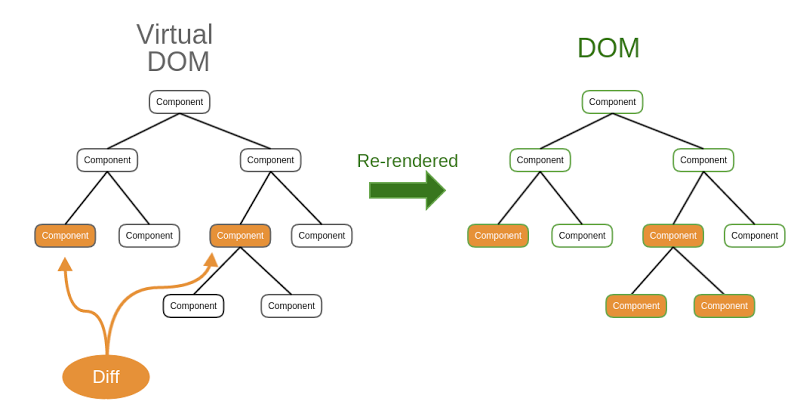
VDOM은 메모리 상에 가상의 UI 관련 정보를 띄우고 라이브러리를 활용해 실제 DOM과 동기화되는 (재조정(reconciliation)) 프로그래밍 개념입니다.
굳이 가상으로 진행하는 이유는 실제로 mount를 paint할 경우 비용이 가상보다 많이 들기 때문입니다.
🗄️ 렌더링 단계
리액트의 렌더링 단계는 렌더 단계(render phase)와 커밋 단계(commit phase)로 나눌 수 있습니다.
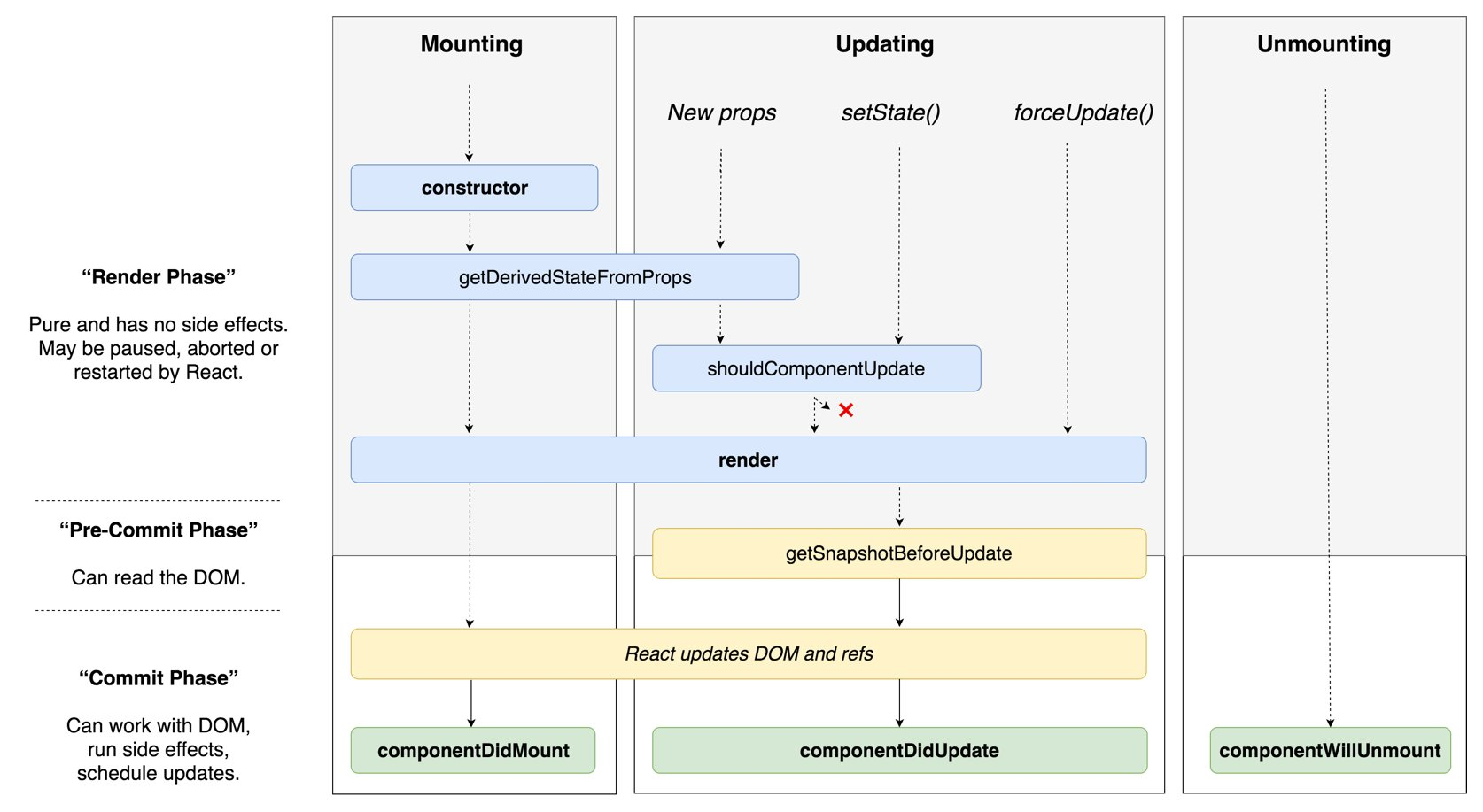
VDOM 재조정(reconciliation)하는 단계
✏️ render phase
렌더 단계(render phase)는 컴포넌트 트리가 어떻게 변경될지 결정하는 단계입니다.
이 단계에서는 React가 새로운 UI 상태를 계산하고, 이를 위해 어떤 변화가 필요한지 알아냅니다. 실제 DOM을 변경하지 않으며, 이를 통해 변경이 필요한 요소들을 결정합니다.
여기에서 비교하는 것은 type, props, key 크게 세 가지입니다.
이 중 하나라도 변경된 것이 있다면 변경이 필요한 컴포넌트로 체크해 둡니다.
과정
1️⃣ 재조정을 위해 Work를 scheduler에 등록
-
Work 등록
React는 재조정(reconciliation) 작업을 위해 할 일(work)을 스케줄러에 등록합니다. 이는 React가 컴포넌트 트리를 순회하며 어떤 변경이 필요한지 확인하는 작업을 말합니다. -
Scheduler
스케줄러는 작업의 우선순위를 관리하고, 긴 작업을 여러 프레임에 나누어 처리할 수 있도록 합니다. 이를 통해 React는 더 중요한 작업이 발생했을 때 즉시 대응할 수 있습니다.
❓ Work
Work란 reconciler가 컴포넌트 변경을 DOM에 적용하기 위해 수행하는 일을 뜻합니다.
2️⃣ element 추가/수정/삭제
-
변경 사항 확인
스케줄러에 등록된 작업은 컴포넌트 트리를 순회하면서 각 컴포넌트의 상태와 요소의 변화를 확인합니다. -
가상 DOM 업데이트
React는 가상 DOM(Virtual DOM)을 사용하여 변경된 요소를 추적하고, 이를 통해 어떤 요소가 추가되거나 수정되었는지, 삭제되어야 하는지를 기록합니다. -
Fiber Nodes
각 컴포넌트와 그 자식 요소들은 Fiber 노드로 표현되며, 이러한 노드들이 트리 형태로 구성됩니다. Fiber 노드는 이전 렌더링과 새로운 렌더링을 비교하여 차이점을 기록합니다.
3️⃣ reconciler가 담당
- Reconciler
Reconciler는 렌더 단계에서 가장 중요한 역할을 담당합니다. Reconciler는 컴포넌트 트리의 변화를 확인하고, 이를 기반으로 새로운 UI 상태를 계산합니다.
특징
1️⃣ 순수 계산
렌더 단계에서는 실제로 DOM을 변경하지 않습니다. 대신, 변경해야 할 사항을 계산합니다.
2️⃣ 비동기 가능
이 단계는 비동기적으로 실행될 수 있으며, 필요한 경우 작업을 중단하고 나중에 재개할 수 있습니다. 이는 React Fiber 아키텍처 덕분에 가능해졌습니다.
3️⃣ 부수 효과 없음
이 단계에서는 DOM에 접근하거나 변경하지 않으며, 부수 효과를 일으키지 않습니다. 따라서 이 단계는 순수 함수처럼 동작합니다.
4️⃣ 중간 상태 저장
Fiber는 렌더링 과정에서 각 컴포넌트의 중간 상태를 저장하고, 이를 기반으로 최종 결과를 계산합니다.
재조정한 VDOM을 DOM에 적용 + lifeCycle을 실행하는 단계
📤 commit phase
커밋 단계는 렌더 단계에서 계산된 변경 사항을 실제 DOM에 적용하는 단계입니다. 이 단계에서 React는 변경된 내용을 DOM에 반영하고, 필요한 경우 부수 효과
(side effects)를 실행합니다.
특징
1️⃣ 동기 실행
커밋 단계는 일관성을 위해 sync(동기적)로 실행됩니다.
이 단계에서는 모든 작업이 한 번에 완료되어야 하기 때문에 중간에 중단될 수 없습니다. 따라서 DOM 조작 일괄처리 후 react가 callstack을 비워준 다음 browser가 paint를 시작하게 됩니다.
2️⃣ 부수 효과 실행
이 단계에서는 DOM 업데이트뿐만 아니라 componentDidMount, componentDidUpdate, useEffect 등과 같은 부수 효과도 실행됩니다.
3️⃣ DOM 업데이트
커밋 단계에서는 렌더 단계에서 계산된 변경 사항을 실제 DOM에 적용합니다.
📌 정리
커밋 단계(commit phase)가 끝나야 비로소 브라우저의 렌더링이 발생하게 됩니다.
리액트가 먼저 DOM을 커밋 단계에서 업데이트한다면 이렇게 만들어진 모든 DOM node 및 인스턴스(instance)를 가리키도록 리액트 내부의 참조를 업데이트합니다.
그 다음, 생명주기 개념이 있는 클래스 컴포넌트에서는 componentDidMount, componentDidUpdate 메서드를 호출하고 함수 컴포넌트에서는 useLayoutEffect 훅을 호출합니다.
여기에서 알 수 있는 사실 중 하나는 리액트의 렌더링이 일어난다고 해서 무조건 DOM 업데이트가 발생하는 것은 아니라는 겁니다.
레더링을 수행했으나 커밋 단계까지 갈 필요가 없다면, 즉 변경 사항을 계산했는데 변경 사항이 감지되지 않는다면 이 커밋 단계는 생략될 수 있기 때문입니다.
리액트의 렌더링은 꼭 가시적인 변경이 일어나지 않아도 발생할 수 있습니다.
그리고 렌더링 과정 중 첫 번째 단계인 렌더 단계에서 변경 사항을 감지할 수 없다면 커밋 단계가 생략되어 브라우저의 DOM 업데이트가 일어나지 않을 수 있습니다.
📋 React의 렌더링 기준
⭐️ React의 렌더링 기준
React는 기본적으로 부모 컴포넌트가 렌더링되면,
그 안에 있는 모든 자식 컴포넌트를 재귀적으로 렌더링합니다.
example
아래와 같은 component tree를 예시로 들어보겠습니다.

B 컴포넌트 안에는 버튼이 하나 있는데, 누르면 숫자가 1 증가합니다.
유저가 이 버튼을 한번 클릭하게 됐을 때 어떻게 동작하게 될까요?
이미 페이지에 보여지고 있는 상황이라고 가정했을 때 아래와 같은 순서로 동작하게 됩니다.
1️⃣ <B />
setState()가 호출되어 B의 리렌더링이 큐(Queue)에 들어갑니다.
2️⃣ React
tree의 최상단부터 렌더 패스(Render Pass)를 시작합니다.
3️⃣ <A />
update inneed mark X
업데이트가 필요하다는 마크가 없는 것을 확인 후 pass 합니다.
4️⃣ <B />
React는 B에 업데이트가 필요하다는 마크가 있는 것을 보고 렌더링합니다.
B return C
5️⃣ <C />
update inneed mark X
하지만 B의 child이기 때문에 C는 렌더링됩니다.
C return D
6️⃣ <D />
update inneed mark X
하지만 C의 child이기 때문에 D는 렌더링됩니다.
일반적으로 컴포넌트가 렌더링되면 그 안에 있는 모든 컴포넌트 역시 렌더링 됩니다.
또한 일반적인 렌더링 과정에서, React는 Props의 변경 유무는 신경쓰지 않습니다.
렌더링의 기준은 그저 부모 컴포넌트가 렌더링되었는가 뿐입니다.
나아가 이는 <App> 컴포넌트에서 setState()를 호출하면 컴포넌트 트리 안에 있는 모든 컴포넌트가 렌더링된다는 것을 의미합니다. 결과적으로 React는 매번 업데이트를 할 때마다 어플리케이션 전체를 다시 그리는 것처럼 동작한다고 볼 수 있습니다.
💡 React's Render Rules
제일 핵심적인 규칙 중 하나는 바로 렌더링은 순수해야만 하며 부수 효과를 만들어내서는 안된다는 것입니다.
📚 렌더링 순서
최초의 렌더가 끝난 이후, React가 리렌더링을 Queue에 넣도록 하는 방법은 여러가지가 있습니다.
1️⃣ 클래스형 컴포넌트
this.setState()
this.forceUpdate()2️⃣ 함수형 컴포넌트
useState setters
useReducer dispatches3️⃣ 그 외
ReactDOM.render(<App>) 을 다시 호출
루트 컴포넌트에서 forceUpdate()를 호출하는 것과 동일VI. 렌더링 최적화
React는 컴포넌트 렌더링을 생략할 수 있도록 3개의 API를 제공하며 모두 얕은 비교 기법을 사용합니다. JS 엔진 입장에서 얕은 비교는 일치 비교(===)에 비해 매우 심플한 동작이기 때문에 빠른 작업으로 분류됩니다.
즉, const shouldRender = !shallowEqual(newProps, prevProps) 와 같은 방법론을 사용하고 있다고 볼 수 있습니다.
💡 얕은 비교
얕은 비교란 서로 다른 2개 객체를 각각 모두 조사해서 내용물 중에 차이가 있는지 여부를 검사하는 것입니다.
1️⃣ 불필요한 렌더링 방지
① React.Component.shouldComponentUpdate
- Optional 클래스 컴포넌트의 라이프사이클 메소드
- 렌더링 과정 초반에 호출
- if return false, pass component render
- 컴포넌트의 props와 state가 마지막에 변경 여부 검사 가능② React.PureComponent
- shouldComponentUpdate의 가장 일반적인 사용법은 props와 state의 업데이트 여부를 검사
- PureComponent의 클래스 컴포넌트는 shouldComponentUpdate 메소드를 기본적으로 탑재
- Component + shouldComponentUpdate와 동일③ React.memo()
- React에 내장된 "고차 컴포넌트 (Higher Order Component)"
- 컴포넌트 타입을 인수로 받고, 새로운 Wrapper 컴포넌트를 반환
- Wrapper 컴포넌트의 기본 동작: Props 변경 유무 확인
- if false, prevent re-rendering
- 함수형 컴포넌트와 클래스형 컴포넌트 모두 사용 가능④ props reference
⑴ 클래스형 컴포넌트
항상 동일한 참조 갖고 있는 인스턴스 메소드를 가질 수 있기 때문에 새로운 콜백 함수 참조를 실수로 생성하는 일을 걱정할 필요가 없습니다.
하지만 상황에 따라 새로운 참조가 생성될 수 있습니다. 하지만 React는 이러한 케이스를 최적화하기 위한 수단을 갖고 있지 않습니다.
💡 새로운 참조가 생성될 수 있는 특수 상황이란?
① 여러 개의 자식들에게 각각 다른 고유한 콜백 함수를 생성해서 적용할 필요가 있거나
② 익명 함수에서 값을 가져와서 자식에게 넘겨줄 필요가 있거나
⑵ 함수형 컴포넌트
같은 참조를 재사용하기 위한 Hook을 2개 제공(메모이제이션)
- useMemo : 객체 생성 또는 복잡한 연산과 관련된 일반적인 데이터를 다루는 경우
- useCallback : 새로운 콜백 함수를 생성하는 경우2️⃣ Memoization
메모이제이션은 값비싼 함수 호출의 결과를 캐싱하고 동일한 입력이 다시 발생했을 때 캐싱된 결과를 반환하는 프로그래밍 기술입니다.
동일한 입력으로 여러 번 호출되는 함수, 컴포넌트에 주로 사용되며 React에서는 useCallback, useMemo와 같은 memoization hook을 사용해 성능을 향상시킴과 동시에 코드의 복잡성을 줄일 수 있습니다.
하지만 메모이제이션은 메모리에 특정한 값을 저장하기 때문에 남용 시 오히려 성능을 저하시킬 수 있습니다.
functional programming
함수형 프로그래밍은 동일한 입력에 대해 동일한 출력을 생성하고 부작용이 없는 함수(순수 함수)의 사용을 강조하는 프로그래밍
메모이제이션은 함수형 프로그래밍과 밀접한 관련이 있습니다. 주로 순수 함수의 실행 최적화를 위해 함수형 프로그래밍에서 일반적으로 사용되기 때문입니다.
메모이제이션은 캐싱된 결과 반환 시 부작용이나 변경 가능한 상태를 고려하지 않기 때문에 함수형 프로그래밍의 원칙과 부합한다고 볼 수 있습니다.
즉, 메모이제이션은 순수 함수 호출을 최적화하고 중복 계산을 줄이며 성능을 향상시키는 방법을 제공함으로써 함수형 프로그래밍 패러다임을 보완하는 강력한 기술 중 하나로 볼 수 있습니다.
🤔 React는 왜 기본적으로 React.memo()로 모든걸 감싸지 않는걸까?
모든 컴포넌트를 자동으로 React.memo()로 감싸는 것이 항상 옳은 방법이 되지 않을 수 있습니다. 렌더링이 빈번하지 않거나 컴포넌트 자체가 간단하거나, 부모 컴포넌트에서의 리렌더링이 거의 없는 경우에는 이러한 최적화가 불필요할 수 있습니다.
또한, React.memo()를 사용하면 컴포넌트가 props의 얕은 비교(shallow comparison)를 통해 업데이트 여부를 결정하므로, props 내부의 객체나 함수 등이 자주 변경되는 경우에는 주의가 필요합니다. 이 경우에는 적절한 최적화를 고려해야 합니다.
각 컴포넌트에 대해 최적한 성능 최적화를 적용하는 것이 중요하며 무조건적으로 감싸는 것은 오히려 성능 저하를 야기할 수 있습니다.
🔥 React Issue
React.memo를 언제 사용하지 말아야될까?
immutable and re-rendering
3️⃣ 불변성과 리렌더링
React에서 상태 업데이트는 항상 불변성을 지켜야 하는 이유는 무엇일까요?
- 수정한 내용을 또 어디서 수정하느냐에 따라서, 컴포넌트가 개발자의 의도대로 렌더링되지 않을 수 있습니다.
- 데이터가 언제 그리고 왜 업데이트 되었는지를 파악하기 어려울 수 있습니다.조금 더 자세히 알아보자면 :
1️⃣ 성능 최적화
React는 상태 불변성을 유지할 때 효과적으로 리렌더링을 최적화할 수 있습니다. 불변한 상태로 업데이트하면 React는 새로운 객체가 이전 상태와 다르다는 것을 쉽게 감지할 수 있게 되고 결과적으로 변경된 부분만 업데이트를 진행해 불필요한 렌더링을 방지할 수 있습니다.
2️⃣ 참조 동등성(Reference Equality)
React는 상태를 업데이트할 때 이전 상태와 새로운 상태의 참조 동등성을 비교합니다. 만약 상태가 불변하지 않고 같은 참조를 가진다면 React는 변경되지 않은 것으로 간주하여 리렌더링이 발생하지 않게 됩니다.
3️⃣ 컴포넌트 생명주기 메서드 최적화
React의 PureComponent나 shouldComponentUpdate 메서드를 사용하여 성능을 최적화할 때, 불변한 상태를 사용하면 이전 상태와의 비교가 간편해집니다. 이를 통해 렌더링 필요 여부를 효과적으로 결정할 수 있습니다.
5️⃣ 예측 가능한 상태 변화
불변한 상태를 유지하면 상태의 변경이 항상 새로운 상태로 이어지며, 이로써 코드의 예측 가능성이 높아집니다. 변화가 예측 가능하면 디버깅이 쉬워지고 코드 유지보수가 간편해집니다.
6️⃣ Undo/Redo와 같은 기능 구현 용이
이전 상태를 변경하지 않고 복제하여 새로운 상태를 만들 수 있기 때문에 불변한 상태를 사용하면 이전 상태를 보존하거나 롤백하는 등의 작업이 더 쉬워집니다.
React에서는 상태 업데이트 시 불변성을 지키기 위해 주로 spread 연산자나 불변성을 유지하는 라이브러리(Immutable.js)가 활용되곤 합니다.
4️⃣ 이벤트 처리 최적화
① Debounce
Debounce는 사용자가 연속적으로 발생시키는 이벤트를 제어하는 기법입니다.
예를 들어, 사용자가 입력 필드에 빠르게 타이핑할 때, 입력이 끝난 후 일정 시간이 지나기 전까지 이벤트 핸들러를 호출하지 않도록 할 수 있습니다. 이처럼 Debounce는 주로 사용자가 작업을 완료한 후에만 특정 작업을 실행하고 싶을 때 사용됩니다.
② Throttle
Throttle은 이벤트가 반복적으로 발생하더라도 일정 시간 간격으로만 이벤트 핸들러를 호출하는 기법입니다. 주로 스크롤이나 리사이즈와 같은 고빈도 이벤트에서 사용됩니다. 이벤트가 자주 발생하더라도 성능을 유지하면서 일부 이벤트만 처리하고 싶을 때 유용합니다.
🧐 더 자세한 내용 알아보기
Debounce? Throttle?
5️⃣ 렌더링 성능 향상
Automatic Batching
Automatic Batching은 React 18부터 도입된 기능으로, 여러 상태 업데이트를 하나의 렌더링 사이클로 묶어서 처리하는 기법입니다. 해당 기능으로 불필요한 렌더링을 줄일 수 있기 때문에 리렌더링이 더 효율적으로 다룰 수 있고 나아가 성능을 향상시킬 수 있습니다.
Code Splitting
Code Splitting은 애플리케이션을 작은 청크(chunk)로 나누어 필요한 코드만 로드하는 기법으로 초기 로딩 시간을 단축하고, 사용자가 필요할 때만 해당 모듈을 로드하여 성능을 최적화할 수 있습니다. React에서는 주로 React.lazy와 Suspense를 사용해 구현합니다.
🧐 더 자세한 내용 알아보기
모아서 해? 나눠서 해?
VII. 렌더링 성능 측정

React DevTools Profiler를 사용하면 컴포넌트가 각각의 커밋 단계에서 어떤 것을 렌더링하는지 확인할 수 있습니다.
어플리케이션을 개발 모드로 프로파일링하면 어떤 컴포넌트가 렌더링되는지와 그 이유를 확인할 수 있고 렌더링 시 필요한 상대적 시간을 컴포넌트끼리 서로 비교할 수도 있습니다.
⚠︎ CAUTION ⚠︎
React는 dev 빌드에서 더 느리게 동작
절대적인 횟수는 반드시 production 빌드에서만 사용
🔎 React DevTools Profiler 사용 방법
🧐 더 자세한 내용 알아보기
React, 성능 최적화 (feat. DevTools) 게시글 읽으러 가기
VIII. React의 고급 기능과 미래 방향
💂🏻♀️ Concurrent Mode와 렌더링
Concurrent Mode는 React 18에서 완전히 도입된 새로운 렌더링 패러다임입니다. 렌더링 작업을 작은 단위로 나누고, 우선순위를 지정하여 처리합니다.
작동 방식
1️⃣ 작업 단위 분할
기존의 React 렌더링 방식에서는 모든 작업이 하나의 단일 프로세스로 처리되었습니다.
이 때문에 긴 작업이 발생하면 사용자의 인터랙션이 지연될 수 있었습니다.
그러나 Concurrent Mode에서는 렌더링 작업을 여러 개의 작은 단위로 나누어 수행합니다. 이를 통해 긴 렌더링 작업 도중에도 사용자의 인터랙션이 중단되지 않고, 부드럽게 처리될 수 있습니다.
2️⃣ 우선순위 기반 처리
Concurrent Mode에서는 각 작업에 우선순위를 지정하여 처리합니다.
예를 들어, 사용자의 입력이나 중요한 인터랙션은 높은 우선순위를 가지며, 이 작업은 즉시 처리됩니다.
반면에, 덜 중요한 작업은 백그라운드에서 천천히 처리됩니다.
이렇게 우선순위를 지정함으로써, 사용자가 느끼는 인터랙션의 지연이 최소화됩니다.
사용 시 이점
Concurrent Mode는 React 애플리케이션의 렌더링 성능을 크게 향상시키고, 특히 복잡한 UI를 가진 애플리케이션에서 사용자 경험을 최적화하는 데 큰 도움이 됩니다.
고려 사항
하지만 Concurrent Mode를 도입했을 때 고려해야 하는 부분도 존재합니다.
렌더링 프로세스가 더욱 유연해지고 강력해지지만, 동시에 애플리케이션의 복잡성도 증가할 수 있습니다. 모든 컴포넌트가 Concurrent Mode를 잘 활용하기 위해서는 추가적인 테스트와 최적화가 필요할 수 있습니다.
또한 일부 오래된 라이브러리나 컴포넌트는 Concurrent Mode와 호환되지 않을 수 있습니다. 따라서, 기존 코드베이스와의 호환성을 고려하면서 단계적으로 적용하는 것이 중요합니다.
[핵심 API]
① useTransition → 우선순위가 낮은 상태 업데이트를 표시
② useDeferredValue → 값의 업데이트를 지연시켜 더 중요한 업데이트를 먼저 처리🪖 Suspense와 Error Boundaries
Suspense
suspense는 컴포넌트가 렌더링을 하기 전에 무언가를 기다려야 할 때 사용합니다.
Suspense 경계 내의 컴포넌트가 아직 렌더링할 준비가 되지 않았다고 React에 알려주는 방식으로 작동합니다.
[주요 사용 사례]
1️⃣ 데이터 페칭
API 응답을 기다리는 동안 대체 UI를 보여줄 수 있습니다.
2️⃣ 코드 스플리팅
동적으로 임포트된 컴포넌트가 로드되는 동안 로딩 UI를 표시합니다.Error Boundaries
error boundaries는 컴포넌트 트리의 어느 부분에서든 JavaScript 에러를 포착하고 처리합니다.
componentDidCatch 생명주기 메서드나 static getDerivedStateFromError 메서드를 사용해 구현 가능합니다.
[주요 특징]
1️⃣ 에러 로깅
개발 중 에러를 쉽게 추적할 수 있습니다.
2️⃣ fallback UI
에러 발생 시 사용자에게 친화적인 메시지를 표시할 수 있습니다.🧐 더 자세한 내용 알아보기
비동기 처리로 더 빠르고 부드러운 UX
💻 SSR과 SSG
서버 사이드 렌더링 (SSR)
SSR은 서버에서 React 컴포넌트를 렌더링하여 HTML을 생성하고, 이를 클라이언트에 전송합니다. SSR을 사용할 경우 초기 페이지 로드 시간을 단축할 수 있고 검색 엔진 최적화(SEO) 향상이 가능하다는 장점이 있습니다.
Next.js, Gatsby 등의 프레임워크를 사용하면 SSR을 쉽게 구현할 수 있습니다.
🧐 더 자세한 내용 알아보기
정적 사이트 생성 (SSG)
SSG는 빌드(build) 시점에 모든 페이지의 HTML을 미리 생성시키기 때문에
페이지의 로드(load) 시간이 매우 빠르고 서버의 부하를 감소시킬 수 있다는 장점이 있습니다.
[정적인 사이트의 특징]
1️⃣ 빌드 시점에 HTML 생성
- SSG는 웹사이트의 모든 페이지를 빌드 시점에 미리 생성해 정적인 HTML 파일로 저장
- 정적 HTML 파일은 사용자가 요청할 때 서버에서 즉시 제공되므로 로드 속도가 매우 빠름
2️⃣ 빌드 과정 필요
- 콘텐츠가 변경될 때마다 build & deploy 과정이 필요
- 모든 변경 사항마다 사이트를 재빌드하는 것은 비효율적
2️⃣ 캐싱의 이점
- SSG는 서버나 CDN(Content Delivery Network)에서 쉽게 캐시 가능
- 캐싱된 SSG는 서버 부하를 줄이고 사용자에게 매우 빠르게 제공
- 그러나 콘텐츠의 잦은 변경 시 캐싱된 페이지를 자주 무효화하고 다시 생성 → 캐싱의 장점 X따라서, 콘텐츠가 자주 변경되지 않는 웹사이트(예를 들어 포트폴리오, 블로그, 문서 사이트 등)에서는 SSG가 적합한 반면, 실시간 업데이트가 중요한 웹사이트에서는 다른 접근 방식(SSR 또는 CSR)이 더 적합할 수 있습니다.
✨ React 18의 새로운 기능들
React 18은 여러 새로운 hooks와 기능을 도입했습니다.
간략하게 소개하자면 아래와 같습니다.
useId
- 서버와 클라이언트에서 일관된 고유 ID를 생성
- 특히 접근성 속성에 유용
useSyncExternalStore
- 외부 데이터 소스와의 동기화를 단순화
- Redux와 같은 상태 관리 라이브러리와의 통합에 유용
useInsertionEffect
- CSS-in-JS 라이브러리를 위한 최적화된 훅
- 레이아웃 효과 이전에 스타일 삽입이 가능
🍡 상태 관리 라이브러리와 렌더링
상태 관리 라이브러리(Redux, MobX, Recoil 등)는 React의 렌더링 과정과 밀접하게 연관되어 있습니다.
이러한 라이브러리들은 각각 고유한 방식으로 React의 렌더링 프로세스와 상호작용하며, 최적화된 상태 업데이트와 렌더링을 제공합니다.
Redux
중앙 집중식 상태 관리를 제공하며, 불필요한 리렌더링을 방지하기 위해 최적화가 필요할 수 있습니다.
MobX
반응형 프로그래밍 모델을 사용하여 자동으로 상태 변화를 추적하고 필요한 부분만 업데이트합니다.
Recoil
React를 위해 특별히 설계된 상태 관리 라이브러리로, 비동기 상태 관리와 파생 상태를 쉽게 다룰 수 있게 해줍니다.
예정된 변화와 렌더링에 미칠 영향
🌈 React의 미래
React 팀은 지속적으로 성능 개선과 개발자 경험 향상을 위해 노력하고 있는 것으로 보입니다.
1️⃣ React Forget
- 자동 메모이제이션 기능
- 개발자가 수동으로 최적화 작업을 하지 않아도 됨
2️⃣ Server Components
- 서버에서 렌더링되고 클라이언트에서 상호작용이 가능한 컴포넌트
- 초기 로드 성능을 크게 향상 가능
3️⃣ 새로운 React 문서
- 새로운 문서를 통해 함수형 컴포넌트와 훅을 중심으로 한 현대적인 React 개발 방식을 강조이러한 변화들은 React 애플리케이션의 성능을 향상시키고, 개발자 경험을 개선하며, 더 효율적인 렌더링 프로세스를 가능하게 할 것으로 기대됩니다.
modern react deepdive의 말을 빌리자면...
맺음말
React.js: The Documentary의 질의응답 영상에 따르면 현재 react가 가장 집중적으로 역량을 쏟고 있는 것은 서버에서의 리액트의 활용입니다.
어떻게 하면 서버에서 리액트를 효율적으로 사용할 수 있을지, 그리고 이러한 작동 방식을 사용자에게 어떻게 소개할지에 대해 고민하고 있는 것으로 보입니다.
과거 리액트는 클라이언트에 초점을 맞추고 있었고, 앞으로도 브라우저와 클라이언트에서의 작동을 개선할 예정이라고 밝힌 바 있습니다.
리액트 팀은 클라이언트에서는 할 수 없었던 서버에서의 작업, 그리고 서버 환경이 갖고 있는 가능성에 무게를 두고 앞으로도 서버에서 작동할 수 있는 다양한 유스케이스를 추가할 것으로 보입니다.
따라서 리액트를 계속 사용할 예정인 프론트엔드 개발자들은 새로운 가능성에 대비하며 서버와 클라이언트의 경계를 넘나드는 개발 역량을 갖추는 것이 중요할 것 같습니다.
🧐 React의 과거와 미래 보러 가기
🔗 References.
[📄 Original]
[🌎 Translate]
[🐱 GitHub]
[🎤 Officials]
[📖 Books]
- 모던 리액트 Deep Dive
[👩🏻💻 Blogs]
- Virtual DOM and Internals
- A Visual Guide to References in JavaScript
- [React] Fiber 아키텍처의 개념과 Fiber Reconcilation 이해하기
- React Virtual DOM, Reconciliation and Fiber Reconciler
- React Compiler & React 19 — forget about memoization soon?
[📽️ Videos]
