데이터를 train / val / test 로 나누는 것은 홀드아웃(Hold-Out) 방식이었다. 하지만 이 방법은 데이터 셋의 크기가 너무 적을 경우에 문제가 발생한다.
train set이 작아서 모델이 제대로 학습 하지 못하는 문제, val set이 작아서 성능 검증이 제대로 되지 않는 문제.
이럴 때 사용하는 방법이 K-fold Cross Validation(K-fold 교차 검증)이다.
단, K-fold 교차 검증을 사용할 때는 교차 검증의 목적을 잘 생각하고 진행해야하며, 이 목적은 크게 Model Selection(모델 선택)과 하이퍼파라미터 튜닝으로 인한 Model Tuning(모델 튜닝)으로 나눌 수 있다.
먼저 교차 검증에 대해 알아보자.
💡 K-fold Cross Validation
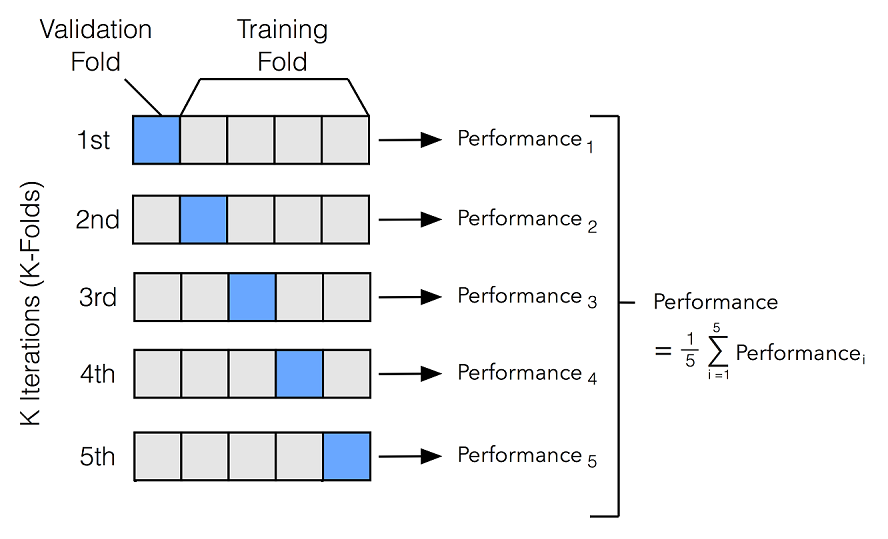
K-fold 교차 검증는 말 그대로 모델의 학습과 검증에 사용되는 데이터를 k 개의 fold로 나누어서 교차로 검증하는 방법이다.
예를 들어 아래 그림처럼 k=5일 때를 가정하면, 데이터를 5개로 분할한 뒤 4개의 training fold와 1개의 validation fold로 나누는 것이다. 이렇게 5개의 데이터(1st, 2nd, .. 5th)를 이용해 모델을 학습 및 검증(평가)하고 나면, 5개의 performance(ex. Accuracy, f1 등)가 나오게 된다.
😶🌫️ Modle selection
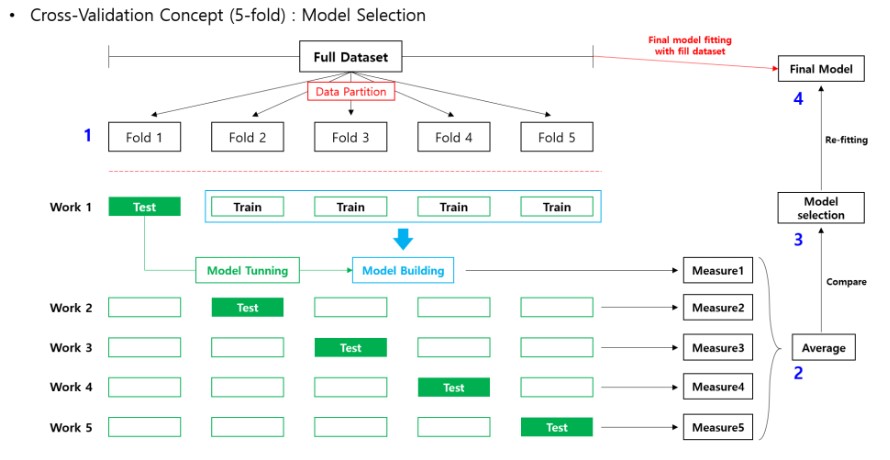
말 그대로 교차 검증이 모델 선택에 이용되는 경우이다. 순서는 다음과 같다.
- 전체 데이터를 K-fold 교차 검증을 통해 k 개의 performance를 얻는다.
- 각 모델에서 k개의 performance의 평균 값을 비교해서 더 나은 모델을 선택한다.
- 선택된 모델에 전체 데이터 셋을 재학습 시킨다.
Python 예제를 통해 이해해보자.
📖 Python
- 선형모델에 교차검증 수행
# k=3 교차검증을 시행, 선형모델과 랜덤포레스트 중 어떤 모델을 선택할지?
# X_train, y_train, X_test, y_test 데이터가 존재하는 상황.
# 필요한 lib import 생략
from sklearn.model_selection import cross_val_score
# 파이프라인 구성
pipe = make_pipeline(OneHotEncoder(use_cat_names=True),
SimpleImputer(strategy='mean'),
StandardScaler(),
SelectKBest(f_regression, k=20),
Ridge(alpha=1.0))
# k=3 교차검증
k=3
scores = cross_val_score(pipe, X_train, y_train,
cv=k, scoring='neg_mean_absolute_error')
print(f'MAE ({k} folds):', -scores)
# [out] : MAE (3 folds): [19912.3716215 23214.74205495 18656.29713167]
-scores.mean()
# [out] : 20594.470269371817
# 선형 모델을 통해 얻은 MAE 값의 평균은 20594이다.
'''
# scoring = performance 방법을 나타냄. 분류/회귀문제를 잘 구분해서 넣어야함.
neg(-)를 사용하는 이유는?
mae는 값이 작을수록 좋은 모델이다.
그런데 모델 알고리즘은 기본적으로 값이 클수록 좋은 모델이라고 인식한다.
결국 값이 크게 보이게 하기위해 neg를 사용하는 것이다!
ex) mae가 [1, 2, 3]이 나왔다면, 가장 작은 값인 1이 나온 모델이 가장 좋은 모델이된다.
neg를 하면 [-1, -2, -3]을 하면, 가장 큰 값인 -1이 나온 모델이 가장 좋은 모델이 된다!
결국 -를 통해 값이 크게 보이도록 하기 위해서 neg를 사용하는 것이다.
'''- 랜덤 포레스트 회귀모델에 교차검증 수행
# 파이프라인 구성
pipe = make_pipeline(OrdinalEncoder(),
SimpleImputer(strategy='median'),
RandomForestRegressor(max_depth=10, n_jobs=-1, random_state=2)
# k=3 교차검증
k=3
scores = cross_val_score(pipe, X_train, y_train,
cv=k, scoring='neg_mean_absolute_error')
print(f'MAE for {k} folds:', -scores)
# [out] MAE for 3 folds: [16289.34502313 19492.01218055 15273.23000751]
-scores.mean()
# [out] : 17018.19573706592
# 랜덤포레스트를 통해 얻은 MAE 값의 평균은 17018이다.- 두 모델을 통해 얻은 MAE 값의 평균은 다음과 같다.
선형모델 : 20594.470269371817
랜덤포레스트 : 17018.19573706592
결국 랜덤포레스트의 성능이 더 좋다고 판단되므로 랜덤포레스트 선택!
😶🌫️ Modle Tuning = Hyper-parameter 튜닝
모델 튜닝은 하이퍼파라미터의 튜닝을 통해 최적의 모델을 찾는 것이다.
이때 중요한 것은 최적화(optimization)이다. 일전에 배운 일반화(generalization)와 헷갈릴 수 있는데 조금 다른 개념이니 숙지할 필요가 있다.
- 최적화(optimization)는 train data로 더 좋은 성능을 얻기 위해 모델을 조정하는 것
- 일반화(generalization)는 학습된 모델이 unseen data에서도 좋은 성능을 내는 모델인가 말하는 것
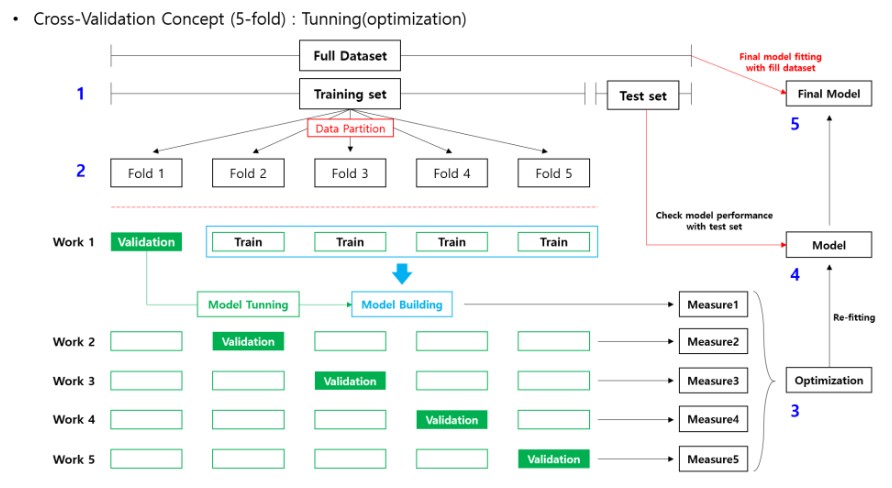
모델 튜닝의 과정은 다음과 같다.
1. train set을 통해 k-fold 교차검증을 한다. 4개의 trian fold를 통해 모델 학습을 진행 할 때, 하이퍼파라미터의 후보들 마다 각각 작업을 진행한다.
2. 가장 높은 measures를 산출하는 하이퍼파라미터를 fix 한 뒤, 기존 Train set을 통해 재적합한다. (결과 확인용)
3. test set으로 performance 계산 후 성능이 만족스럽다면, full dataset을 모델에 재적합한다. (모델 활용용)
이 과정에서 최적의 하이퍼파라미터 조합을 찾도록 해주는 대표적인 기법이
GirdSearchCV 와 RandomizedSearchCV 이다.
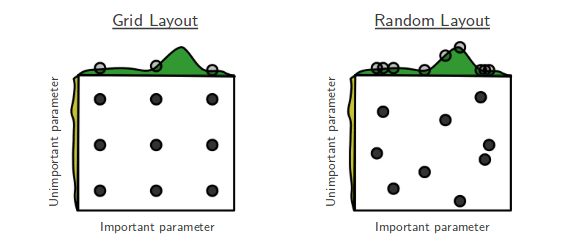
- GirdSearchCV : 검증하고 싶은 하이퍼파라미터들의 수치를 정해주고 그 조합을 모두 검정함.
- RandomizedSearchCV : 검증하려는 하이퍼파라미터들의 값 범위를 정해주면 무작위로 값을 지정해 그 조합을 모두 검정함.
RandomizedSearchCV = GridSearch에 비해 시간상 효율적이다. 데이터가 많고 파라미터 튜닝이 많이 필요할 떄 효과적이다.
GridSearchCV = 데이터가 많고, 튜닝해야 할 파라미터가 많은 경우 비효율적이다. 성능 개선을 위해 모든 파라미터 조합을 진행해야할 때 사용하는 것이 적절하다.
📖 Python
랜덤포레스트 분류모델에 하이퍼파라미터 튜닝
from category_encoders import OrdinalEncoder
from sklearn.impute import SimpleImputer
from sklearn.ensemble import RandomForestClassifier
from sklearn.pipeline import make_pipeline
from scipy.stats import randint
from sklearn.model_selection import RandomizedSearchCV
# 파이프라인 구성
pipe = make_pipeline(OrdinalEncoder(),
SimpleImputer(),
RandomForestClassifier())
# 하이퍼파라미터 값의 범위 설정
dist = {
'simpleimputer__strategy' : ['mean', 'median', 'most_frequent'],
'randomforestclassifier__n_estimators' : randint(50, 300),
'randomforestclassifier__max_depth' : [5, 10, 15, 20],
'randomforestclassifier__min_samples_split' : randint(10, 30),
'randomforestclassifier__max_features' : ['sqrt', 'log2', None]
}
# RandomizedSearchCV
clf = RandomizedSearchCV(
pipe,
param_distributions = dist,
n_iter = 10, #위 조합 중 몇 개의 조합을 추출할 것인가?
cv = 3,
scoring = 'f1', # 분류문제이므로
verbose = 1, # 진행상황 확인 여부
n_jobs=-1)
clf.fit(X_train, y_train)
# 이렇게 실행하면, 10*3 = 30개의 fits 진행하게 된다. 시간이 꽤오래걸림
# 최적의 파라미터, 최고의 f1 score 찾는 방법
print('최적의 파라미터 :', clf.best_params_)
print('f1 score :', clf.best_score_)
# 각 조합으로 만들어진 모델을 순위별로 나열해서 확인해보는 방법
pd.DataFrame(clf.cv_results_).sort_values(by='rank_test_score').T
# 각 모델 중 가장 좋은 모델 불러오기
pipe = clf.best_estimator_
pred = pipe.predict(X_train) # 예측 값 확인