지난 번에 기본 특성 중요도에 대해서 배운 적이 있었다. 간단하게 만든 모델의 .feature_importances_를 통해서(의사결정트리, 랜덤포레스트에서 배웠음). 오늘은 이 특성 중요도를 계산하는 방법을 복습하면서 또 다른 2가지 방법을 공부해보고자 한다.
💡Mean decrease impurity (MDI)
MDI는 각 변수가 split 될 때 불순도 감소분의 평균을 중요도로 정의하는 것이다.
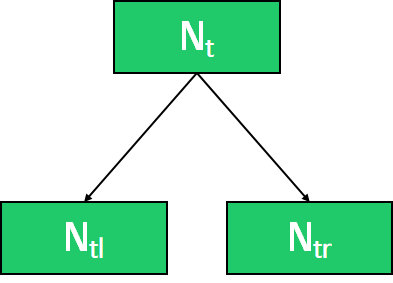
- : t노드의 impurity (entropy, gini index, variance, ...)
: 현재 노드 t에 존재하는 관측치 수
-> 각각의 노드에 관측치 갯수를 고려해 불순도의 감소 정도가 계산된다. 이 값이 클수록 중요도가 높다.
- 장점 : 빠르고 직관적
단점 : high-cardinality 범주형 변수에 대해서는 bais가 나타난다.
(범주가 많은 특성은 트리가 분기할 때 이용될 확률이 높다. 그래서 전체적인 일반화보단 범주가 많은 특성에 편향되어 과적합을 일으키기 쉽고, 의 값이 높게 나오는 오류를 발생시키기 때문에 잘못된 해석을 할 수 있으므로 주의해야한다)
📖 Python
# 계절 독감 유무에 대한 데이터의 MDI 특성 중요도
# 랜덤포레스트를 포함한 파이프라인이 구성되어 있다고 가정
rf = pipe.named_steps['randomforestclassifier']
#특성중요도는 다음과 같이 구할 수 있다
rf.feature_importances_
importances = pd.Series(re.feature_importances_, X_trian.columns)
%matplotlib inline
import matplotlib.pyplot as plt
n=20
plt.title(f'Top {n} features')
importances.sort_values().plot.barh()
# 여기서 주의해야 할 것, raw data를 확인했을 때 state는 high-cardinality를 가짐.
# 과적합 위험성이 있기 때문에 주의해야함.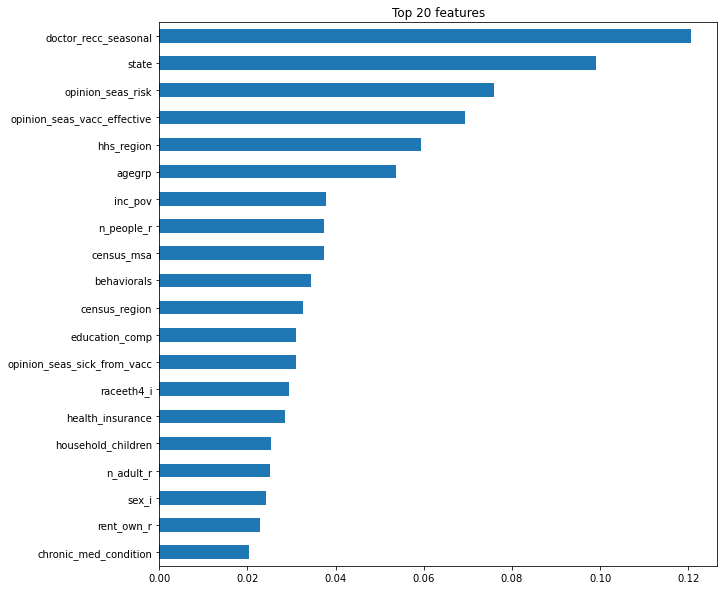
💡Drop-Column Importance
말 그대로 column을 하나씩 제거해가면서 중요도를 구하는 방법이다. 가장 직관적이고 해석하기가 쉬운 방법이지만, 매 특성을 drop한 후 재학습을 해줘야하기 때문에 시간이 오래 걸린다는 단점이 있다.
결국 특성 n개가 있을 때는 전체 중요도를 구하는 것 + 각 특성 하나씩 제거 후 구하는 것으로 n+1번의 학습이 필요하다.
📖 Python
column = 'opinion_seas_risk'
# column 제거하고 fit
pipe = make_pipeline(
RandomForestClassifier(n_estimators=100, random_state=2, n_jobs=-1))
pipe.fit(X_train.drop(columns=column), y_train)
score_without = pipe.score(X_val.drop(columns=column), y_val)
# column 포함해서 fit
pipe = make_pipeline(
RandomForestClassifier(n_estimators=100, random_state=2, n_jobs=-1))
pipe.fit(X_train, y_train)
score_with = pipe.score(X_val, y_val)
# column 제외한 경우와 포함한 경우에 정확도 계산
print(f'검증 정확도 ({column} 제외): {score_without}')
print(f'검증 정확도 ({column} 포함): {score_with}')
# opinion_h1n1_risk 포함 전 후 정확도 차이를 계산합니다
print(f'{column}의 Drop-Column 중요도: {score_with - score_without}')
'''
[out]
검증 정확도 (opinion_seas_risk 제외): 0.733127742853754
검증 정확도 (opinion_seas_risk 포함): 0.7526983750444787
opinion_seas_risk의 Drop-Column 중요도: 0.019570632190724635
이럴 경우 해당 column의 중요도를 알 수 있다.
'''💡Permutation Importance (순열 중요도)
순열 중요도는 '어떤 feature의 값이 랜덤 분포될 경우, 성능이 얼마나 떨어지는지'를 통해 feature importances를 측정하는 방법이다. 즉, 관심있는 features에 랜덤으로 노이즈를 주고 예측했을 때, 성능 평가지표가 얼마나 감소하는지 측정한다고 보면 된다.
*노이즈 : 특성이 제기능을 하지 못하지 못하도록 하는 것.
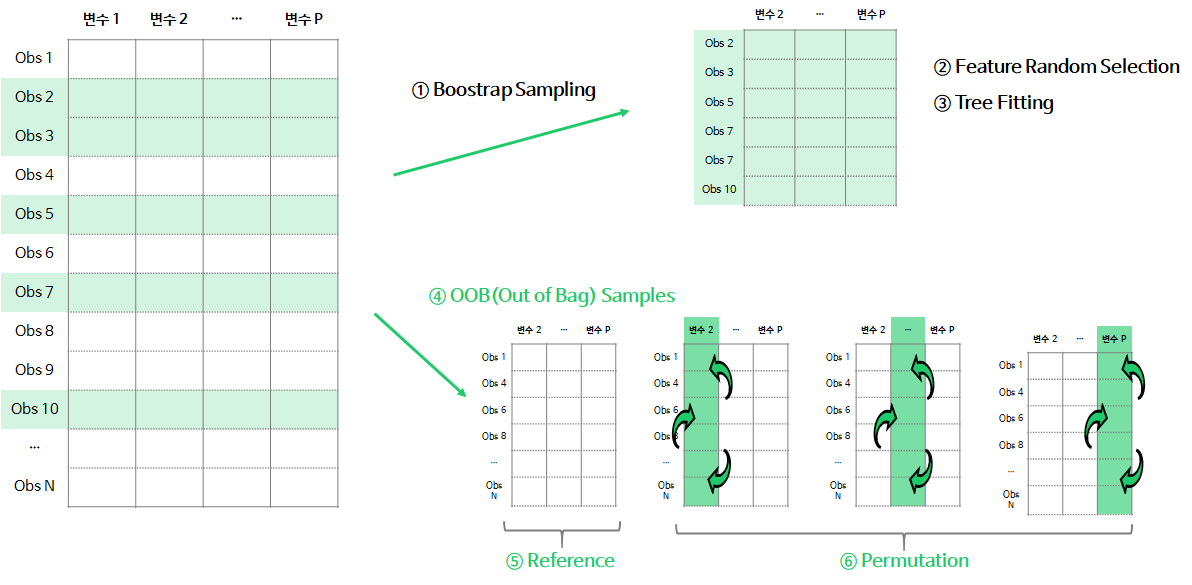
- ①~③ n번째 tree를 생성할 때, bootstrap sample로 나무를 학습
- ④ OOB Samples : 학습할 때 사용되지 않은 데이터 셋으로 Validation 데이터를 생성
- ⑤ Reference Measure : OOB Sample로 트리의 성능 평가지표(accuracy, R-square, MSE 등)을 계산
- ⑥ Permutation Measure : OOB Sample에서 j번째 변수의 데이터를 무작위로 섞은 뒤, 학습된 트리의 성능 평가지표를 계산
- ⑤, ⑥단계에서 저장된 평가 지표 차이(⑤ - ⑥)를 계산
위의 과정을 n(나무의 갯수)만큼 시행하여, 각 변수에서 계산된 중요도의 평균이 Permutation Importance가 된다. 순열 중요도 기존 Reference 척도보다 낮아지게되면, 해당 변수는 중요하다고 판단되며 척도가 유사하거나 오히려 좋아지면 불필요하다고 판단내릴 수 있다.
- 장점 : 재학습이 필요 없어서 계산이 빠르다. 직관적 해석이 가능하다.
단점 : 상관관계가 높은 feature에 대해서 비현실적인 데이터 조합이 생성될 가능성이 높다. (ex. shuffle을 통해 키 180cm, 몸무게 30kg의 데이터가 조합되는 경우)
📖 Python
from sklearn.pipeline import Pipeline
# encoder, imputer를 preprocessing으로 묶음
pipe = Pipeline(
[('preprocessing', make_pipeline(OrdinalEncoder(), SimpleImputer())),
('rf', RandomForestClassifier(n_estimators=100, random_state=2, n_jobs=-1))]
)
# 학습
pipe.fit(X_train, y_train)
# eli5를 통해 순열 중요도를 구한다.
import eli5
from eli5.sklearn import PermutationImportance
# permuter 정의
permuter = PermutationImportance(
pipe.named_steps['rf'], # model
scoring='accuracy', # metric
n_iter=5, # 다른 random seed를 사용하여 5번 반복
random_state=2)
# permuter 계산은 preprocessing 된 X_val을 사용
X_val_transformed = pipe.named_steps['preprocessing'].transform(X_val)
# 실제로 fit 의미보다는 스코어를 다시 계산하는 작업
permuter.fit(X_val_transformed, y_val);
# 특성별 score 확인
feature_names = X_val.columns
pd.DataFrame({'feature' : feature_names,
'importance' : permuter.feature_importances_}).sort_values('importance', ascending = True)
# eli5를 통해 특성별 score 확인
feature_names = X_val.columns.tolist()
eli5.show_weights(
permuter,
top=None, # top n 지정 가능, None 일 경우 모든 특성
feature_names=feature_names # list 형식으로
)
⭐ 중요도가 -인 특성은 제외해도 성능에 거의 영향이 없다.
그러므로 제외해 시키는 것이 좋고, 모델 학습 속도도 개선된다.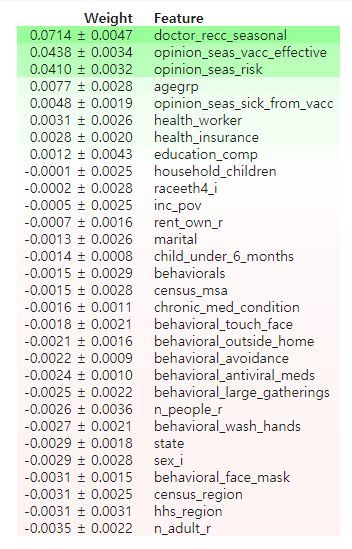
# 결과 확인
minimum_importance = 0.001 # 위 결과에서 0.001 이하는 - 값이라 삭제위해 기준을 잡음
mask = permuter.feature_importances_ > minimum_importance
features = X_train.columns[mask]
X_train_selected = X_train[features]
X_val_selected = X_val[features]
# pipeline 다시 정의
pipe = Pipeline([
('preprocessing', make_pipeline(OrdinalEncoder(), SimpleImputer())),
('rf', RandomForestClassifier(n_estimators=100, random_state=2, n_jobs=-1))
], verbose=1)
pipe.fit(X_train_selected, y_train);
pipe.score(X_val_selected, y_val)
'''
특성 삭제 전 / 후의 중요도를 확인
특성 삭제 전 검증 정확도: 0.7526983750444787
특성 삭제 후 검증 정확도: 0.7513936662317637
조금 떨어졌지만, 특성이 삭제 된 것을 생각하면 일반화가 더 잘된 모델이 된다.
'''
