Backgroung
딥러닝 라이브러리의 종류
- Tensorflow
: 구글이 개발. 사용이 복잡했으나 2.0 이후 개선됨. colab에서 간편하게 gpu 사용을 지원. Tensorboard를 통한 강력한 시각화. TF lite를 통한 간편한 모바일 변환
- Keras : Tensorflow의 모델 구현과 학습을 편리하게 작성하기 위한 API. layer.add 등을 통해 일반적인 구조의 모델은 간편하게 구현이 가능함. tf.keras를 통해 사용이 가능하며 GPU 사용 여부와 관계없이 하나의 라이브러리를 유지. keras를 사용하고 있다면 tensorflow 1. version. tf.keras면 2.0 버전으로 이해하면 됨.
현재는 2.7 버전
- Pytorch
: 페이스북이 개발. 일부 모델의 구현이나 데이터 처리에 더 적합. 모델의 자세한 구조나 연산을 연구하는 용도로 적합
과적합
처음 모델학습을 진행할 때 가장 많이 마주치는 문제. 모델이 데이터의 일반적인 특징이 아닌 학습 데이터에만 특화되어 학습. (문제집 답을 외운 학생과 유사한 특징. 외운 문제집을 풀면 100점 가까운 점수를 달성하지만 시험을 보면 점수가 매우 떨어짐)
-
과적합의 원인
(1) 데이터의 수나 다양성이 부족 : 문제집의 문제가 적어서 잠깐만 봐도 외울 수 있다
(2) 데이터에 비해 모델이 너무 큼(모델에 포함된 weight 수가 많다) : 난이도에 비해 학생의 암기력이 너무 좋다
(3) 너무 많은 epoch를 학습함(1epoch는 데이터를 처음부터 끝까지 다 확인했다) : 같은 문제집을 너무 오래 보게 했다
=> 적당히 크고 적당히 많은 epoch를 사용해야함. underfitting은 학습이 너무 덜 된 상태로 조정이 필요함 -
과적합 해결 방법
(1) 데이터를 늘린다 : 가장 근본적인 해결 방법 중 하나. 충분히 많은 데이터를 확보한다면 과적합이 잘 일어나지 않음
(2) 과적합이 일어나기 전에 학습을 정지한다(early stop) : 검증 성능이 가장 높은 시점에서 학습을 중단하고 모델을 사용
(3) 데이터 증강(Data augmentation) : 같은 데이터도 반전시키거나 약간 변형해서 입력. 적은 수의 데이터를 이용하여 좀 더 일반적인 특징을 학습하도록 유도. 사진을 예로 들자면 뒤집은 사진, 좌우를 반전한 사진, 일부를 잘라낸 사진, 돌린 사진 등 하나의 사진으로 여러가지 변형 버전으로 학습시키는 방법. 이미지를 다루는 모델이라면 거의 사용하고 있음
Fit 함수
tf.keras.model.fit()

모델을 학습하는 핵심 함수. 모델이 학습을 시작하는 함수. 굉장히 많은 매개변수를 가지고 있음.
(1) x : 학습 세트의 입력 데이터
(2) y : Label, Ground truth. 학습 세트의 입력 데이터를 넣었을 때 정답 값. (.x를 넣었을 때 이 값이 나왔으면 좋겠다) np.array, list, tensor 등의 자료형 사용 가능
(3) batch_size : 한번에 입력할 데이터의 수. 모델의 input_shape도 이 값을 고려하여 설정(주머니 속에 개사진 100개, 고양이사진 100개가 있을 때 한 줌씩 꺼내서 학습하는 과정을 반복. 이 때 한줌에 몇 장의 사진을 꺼낼지를 의미. 10장씩 꺼낸다면 batch_size = 10) 마음대로 설정해도 되지만 가급적 큰 값을 설정하기를 추천. (예를 들어 주머니에서 5개씩만 꺼내서 보는데 우연히 하얀색 강아지가 모두 들어있었음. 그렇다면 이 모델에서 하얀색 털이 있다면 강아지구나 라고 학습할 수도 있음. 하나의 batch를 어떻게 잡냐에 따라 학습이 느려지거나 잘못된 방향으로 갈 수도 있음. 또한 batch가 작을수록 batch내 편향이 발생할 확률도 높아짐. 따라서 메모리가 허락하는 선에서 가능한 크게 잡기를 추천)
(4) epochs : 학습 데이터를 몇 번 학습할 것인지. 전체 데이터를 한 번 보는것이 1 epochs.(앞서 batch_size가 10이었다면 epoch는 20으로 설정하는 것을 추천. 곱한 것이 전체 데이터보다 작은 값을 넣는 것은 보지않고 지나치는 데이터가 있기 때문에 추천하지 않음)
(5) steps_per_epoch : 한 epoch는 몇 번의 입력을 수행하는지. None으로 전달하면 batch_size에 따라 데이터셋을 전체로 볼 수 있는 숫자로 자동으로 설정됨
=> batch_size * steps_per_epoch = 학습 데이터의 수
(6) verbose = 학습 과정을 출력하는 방법
-> 0 : 어떤 출력도 하지 않음 / 1 : 진행바를 표시하여 진행상황을 표시(기본값) / 2 : 진행바는 표시하지 않고 수치 정보만 표시

검증 데이터셋 관련
(7) validation_data : 검증 데이터 셋을 입력하는 부분. 하나로 묶어서 전달.
-> (x_val, y_val) 의 형태로 전달하거나 Generator로 전달 / 이 데이터는 학습에 반영하지는 않고 현재 epoch의 성능을 평가하기 위해 사용
(8) validation_freq : 검증하는 주기
-> 1[기본값] : 매 epoch마다 검증 / 자주 수행할수록 걸리는 시간은 증가하지만, 세밀하게 성능을 평가할 수 있음. 따라서 본인이 학습할 epoch에 따라서 적절하게 설정해야 함.
dataset은 보통 train 학습, validation 검증, test 테스트 로 나누어짐. train은 문제집, validation은 모의고사, test는 수능이라고 생각해보자. 결국 모델이 학습하는 데이터는 train 데이터고 이것은 x, y로 입력. 그렇다면 validation은 모의고사, 즉 그 학습이 잘 되고 있는지 과정을 체크하기 위한 검증과정. 검증을 위한 데이터이기 때문에 validation 값 같은 경우에는 학습에 사용되지 않고 test용으로만 사용. test셋 같은 경우는 가장 마지막에 모델이 완전 학습된 후 모델 전체의 성능을 평가하기 위해 사용하기도 하는데 보통은 검증데이터와 묶어서 하나만 처리하는 경우도 존재.
순서 섞기
(9) shuffle : 학습 데이터를 섞을지 여부.
-> 정해진 학습 데이터의 입력 순서에 맞춰 학습되지 않도록 순서를 변경. generator를 사용할 경우 generator의 옵션에 관련 내용이 이미 존재하므로 이 값은 무시됨. True를 하면 매 epoch마다 batch에 담는 데이터가 무작위로 바뀐다는 의미. 즉, 매번 다르게 batch를 뽑겠다는 것. 그러면 batch의 편향이 일어날 확률도 적어지고 일어나더라도 다음 epoch에는 또 조합이 바뀌기 때문에 영향을 줄여주는 기능. 굉장히 중요한 점은 학습 데이터만 섞는다는 점. 정확한 성능을 보기 위해 검증데이터 validation data는 섞지 않음. 사실 검증데이터는 학습을 하지 않으니까 섞을 필요도 없음.
❓ generator란?
Iterator를 만들어주는 함수. 대용량의 데이터셋을 처리할 때 사용합니다. 10만장의 이미지를 학습한다고 하면, 10만장의 정보를 모두 담기에는 메모리가 버거울 겁니다. Generator는 1개씩만 이미지를 꺼내서 쓰는 방식으로 메모리를 아낄 수 있습니다.
사용 방법은 #Keras 의 #ImageDataGenerator 를 이용하면 손쉽게 이미지 데이터셋을 만들 수 있습니다. 하지만 직접 만들어야 할 경우에는 다음과 같이 #yield 문법으로 만들 수 있습니다. 다음은 기초적인 이미지 분류기의 예제입니다.
[출처][파이썬] Keras용 Generator 함수 만들기|작성자 Shane
https://blog.naver.com/shane5321/221662218616
검증 과정의 epoch, batch
(10) validation_batch_size : 한 번 입력에 입력할 데이터의 수
(11) validation_step : 한번 검증할 때 데이터 입력의 횟수
=> validation_batch_size * validation_steps = 검증의 수
데이터 불균형을 위한 가중치
(12) class_weight : 클래스별 반영 정도
-> 데이터 불균형을 해결하는 방법 중 하나 / 적은 수의 클래스에는 더 많은 관심을 기울이는 개념 / 클래스별 데이터의 수가 차이날 경우, 적은 수의 클래스는 더 많이 반영하여 학습 / {클래스index:반영비율}의 딕셔너리 문제를 형태로 전달
( 위에서 주머니 예시에서 개사진이 100장, 고양이 사진이 50장이 있다고 가정. 이 경우에는 고양이 사진이 개의 절반정도 밖에 되지 않기 때문에 데이터가 불균형하게 존재. 이 문제를 해결하기 위해 class_weight를 사용. 고양이 사진이 개 사진의 절반이기 때문에 고양이 사진을 볼때는 개 사진을 볼때보다 2배 관심을 기울인다. 따라서 class에 따라 관심을 기울이는 정도를 다르게 한다는 것이 class_weight. 만약 개를 0 고양이를 1이라고 한다면 {0:0.5, 1:1.0} 형태로 표현
데이터 병렬 처리
(13) workers, use_multiprocessing : 병렬 처리를 위한 인수들
-> GPU를 사용할 경우 데이터를 읽고 변환하는 과정이 학습하는 시간보다 길게 소모 / GPU는 그동안 기다리는 idle time(아무것도 하지 않는 시간)이 발생하면서 효율이 저하 / 여러 workers가 동시에 데이터를 불러오고 학습을 진행 / generator를 사용하는 경우에만 사용. 따라서 gpu와 generator를 모두 사용하는 경우에만 사용 가능
콜백함수의 리스트
(14) callbacks
- 콜백함수(Callback Function)
: 다른 코드의 인수로 함수를 넘겨주면, 그 코드가 필요에 따라 실행하는 함수
: callbacks 옵션으로 함수들의 리스트를 전달하면 학습 과정 중에 Tensorflow가 실행
: 다양한 함수로 학습과정을 세밀하게 조정하거나, 중간 경과를 살펴볼 수 있음
-> 즉 함수를 실행하는 주체가, 우리가 함수를 호출하는 것이 아니라 다른 코드에 의해 함수를 호출하는 것
콜백함수
콜백함수 정의하기
keras.callbacks.Callback을 상속받아서 클래스 정의. 호출될 타이밍에 따라 해당 함수를 재정의.
on_train_end(self, logs = None) : 학습이 종료될 때 호출
on_epoch_end(self, epoch, logs = None) : 한 epoch이 끝날 때 호출
on_predict_end(self, logs = None) : 예측이 끝날 때 호출
정의한 클래스의 인스턴스를 리스트에 포함하여 callbacks에 전달

: MyCallback이라는 클래스를 만들고 keras.callbacks.Callback를 상속받아 클래스를정의. 그리고 on_epoch_end(self, epoch, logs = None) 한 epoch가 끝날때마다 호출하는 함수를 재정의하고 있으며 여기서는 logs.keys()를 받아서 list로 만들고 있음. 이렇게 키를 뽑아낸 다음 key를 epoch와 함께 호출하고 있음. 여기서 epoch은 현재가 몇 epoch 인지를 함께 인자로 전달해줌. log는 설정에 따라 loss값이나 정확도 같은 값이 딕셔너리 형태로 들어옴. 그렇게 정의한 클래스는 아래 인스턴트를 만들어 전달하고 있음
내장콜백함수
tf.keras.callbacks에 정의된 것들 중 주요 콜백함수
- EarlyStopping : 학습이 진전이 없을 경우, 조기에 학습을 종료
: 일정 시점부터 학습 성능이 증가하지만 검증 성능이 감소하거나 유지되는 것은 과적합. 과적합이 시작되면 더 학습을 진행할수록 성능이 감소함. 따라서 과적합이 발생하는 epoch를 감지하고 자동으로 학습을 종료하는 방법
: 모델 학습의 목표는 loss 값을 최소화하는 과정. loss값을 감시하고 있다가 더 이상 감소하지 않는다면 학습이 종료됨. 과적합을 방지하고 무의미한 학습과정을 생략하여 연산자원 절약
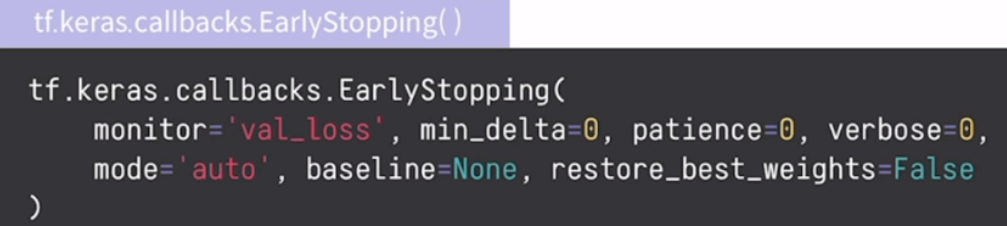
(1) monitor : 감시할 수치의 이름. ex) 'val_loss' 는 검증 loss값
(2) mode : 원하는 방향 (monitor값이 어떻게 되어야 하는 값인지 결정. 'min'은 monitor 값이 최소가 되어야 성능이 좋아지는 모델일 때로 loss, error가 해당됨. 'max'는 monitor값이 최대가 되어야 성능이 좋아지는 모델일 때로 정확도나 성능이 해당됨.
- ModelCheckpoint : 일정 주기마다 모델이나 모델의 가중치를 자동으로 저장. 과적합이 발생했을 때 처음부터 수행하지 않고 중간부터 다시 학습이 가능. 성능 그래프를 보면서 가장 좋은 성능의 가중치를 서비스에 사용. 가장 성능이 좋은 버전만 저장하는 기능이 포함.

(1) monitorm mode : 감시할 지표와 모드로 early stopping 과 동일
(2) save_best_only : 가장 좋은 버전만 저장 (True일 경우 가장 좋은 버전만 남기고 다른 버전의 체크포인트는 모두 삭제하며 False일 경우 모든 버전을 저장하고 삭제하지 않음 / False 추천)
(3) save_weights_only : 모델의 가중치의 값만 저장 (True : 학습 진행상황, 모델의 구조에 대한 데이터를 빼고 저장하여 공간이 절약되지만 불러오기 위해서는 모델의 구조를 저장하고 있어야 함 / False 추천)
(4) filepath : 체크 포인트를 저장할 디렉토리. 고정된 문자열을 전달하면 하나의 디렉토리에 계속 저장되어 계속 덮어쓰게됨. 이렇게 되면 특정 버전의 모델을 불러오기에는 사용할 수 없음. 따라서 epoch에 따라 이름을 다르게 하도록 포맷 문자열을 사용해 설정하는 것을 추천.
한 epoch이 끝날때마다 호출되는 on_epoch_end(self, epoch, logs = None)의 경우 epoch 값을 매개변수로 전달받음. 따라서 포맷문자열을 사용해 epoch라는 값을 넣어주면 epoch에 따라 파일명을 각각 다르게 저장할 수 있음.

- Tensorboard : 학습 과정이나 모델의 정보를 시각화 할 수 있도록 로그를 기록
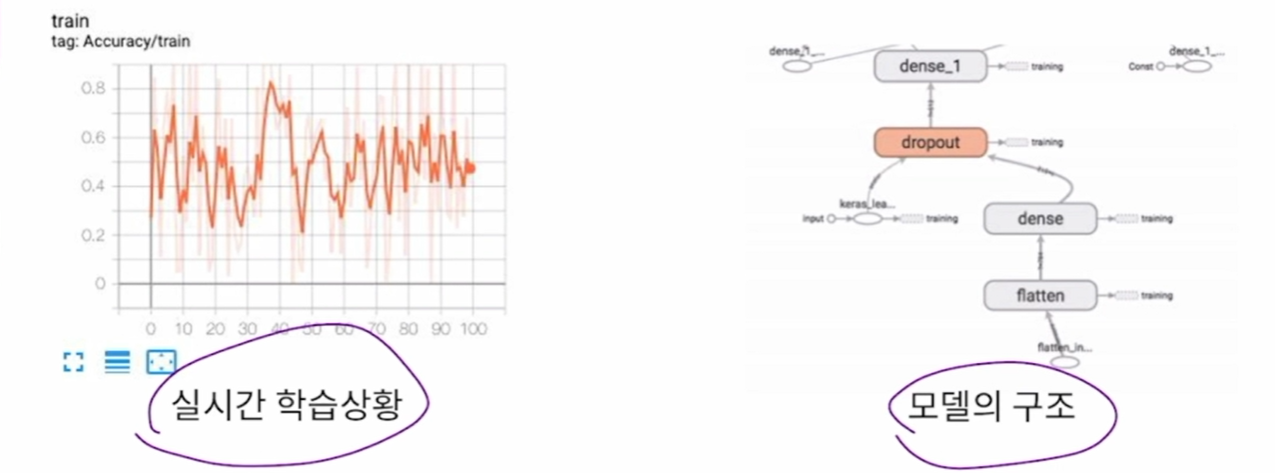
TensorBoard를 사용하는 이유
- 장점 : 원격에서 실시간으로 모델의 학습정보를 포함한 다양한 정보를 확인. 간단하게 callback을 추가하고 시각화된 웹페이지를 제공. 포트와 ip를 설정하면 서버가 아닌 원격에서 이 결과물을 활용 가능
- 사용과정 : callback에 TensorBoard 콜백함수를 추가하여 로그 디렉토리에 기록을 저장. TensorBoard 모듈을 실행하여 로그 디렉토리의 로그를 웹페이지로 호스트. 웹페이지에 출력된 정보들을 보고 학습 과정을 모니터링.
TensorBoard 콜백함수의 인자
(1) log_dir : 로그를 저장할 경로
(2) update_frep : 저장하는 주기
-> 'epoch' : 한 epoch마다 기록을 저장 / 'batch' : batch마다 기록을 저장(학습속도저하)
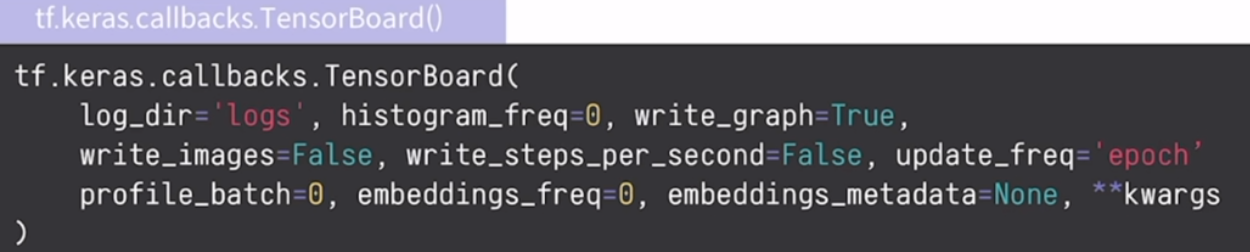
TensorBoard 사용방법
(1) Fit 함수에 콜백함수 추가하기

이렇게 정의된 콜백함수는 callbacks라는 매개변수를 통해 리스트로 묶어서 전달.
(2) 명령줄에서 tensorboard를 실행

TensorBoard
