LSTM
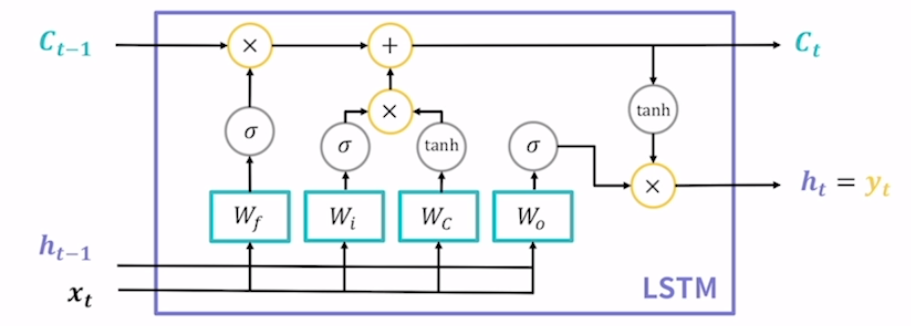
vanila rnn의 기울기 소실 문제를 해결하고자 등장. Long Short Term Memory(장단기 메모리)의 약자. vanila rnn은 기울기 소실 때문에 장기 의존성을 기억할 수 없다는 단점이 있었는데 해당 모델은 장기 의존성과 단기 의존성을 모두 기억할 수 있다는 의미. 새로 계산된 hidden state를 출력값으로도 사용. 그래서 vanila rnn에서는 출력값을 계산하기 위한 별도의 장치가 있었는데 lstm은 그렇지 않음.
Cell State
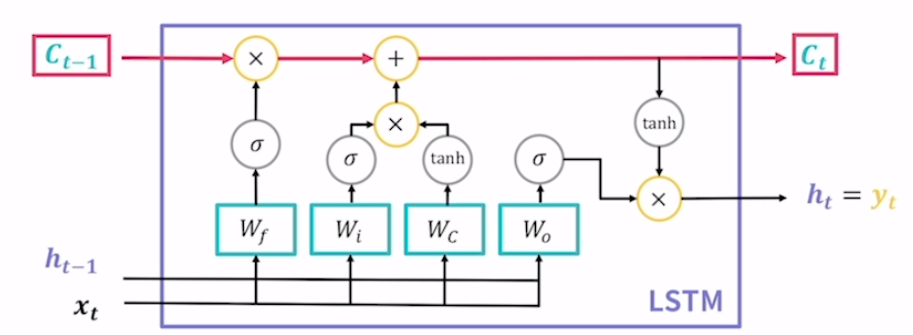
lstm의 가장 중요한 특징. lstm이 고안한 두번째 hidden state라고 보면 됨. 기울기 소실 문제를 해결하기 위한 핵심 장치로 장기적으로 기억할 정보를 조절하여 저장. 긴 문장에서 앞단어와 뒷 단어 사이의 연관이 있어 연관된 정보를 cell state에 저장했다고 가정. 다음 문장이 등장했을 때 앞 문장과 연관이 거의 없다면, 기존에 있던 cell state는 삭제함. 그래서 조절은 이런 것을 의미.
gate
본질은 fclayer. 모델의 파라미터를 담당하는 부분. 이걸 게이트라고 따로 부르는 이유는 lstm에서 들어오는 입력값과 이전 시점의 hidden state, cell state들을 서로 유기적으로 연결시켜 정보전달을 위한 관문으로 작용한다는 의미. 이 게이트의 동작 과정을 이해하는 것이 곧 lstm의 동작과정을 이해하는 것. 3종류의 게이트를 4개의 fclayer로 구성.
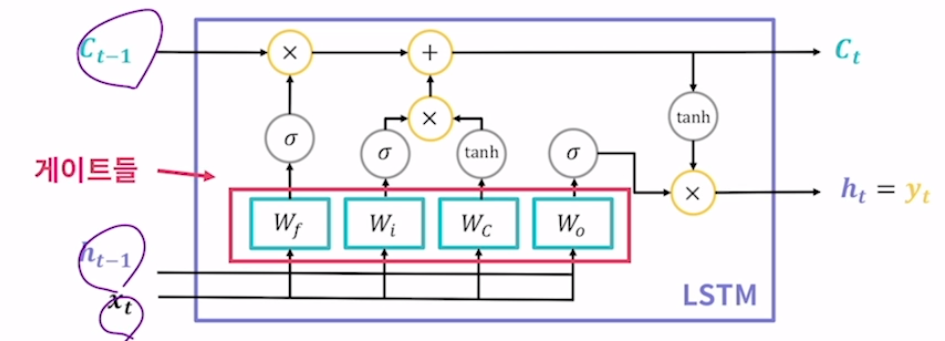
(1) Wf : 망각 게이트(forget gate)
기존 cell state에서 어떤 정보를 잊을지 결정하는 게이트. 잊을지 말지의 결정은 이전의 hidden state와 현재 시점의 입력값을 합쳐 망각 게이트를 구성하는 fc layer에 전달해서 그 결과로 결정. sigmoid는 활성화함수로 탄젠트 하이퍼파라미터와 비슷한 모양을 가지고 있는데 탄덴트 하이퍼파라미터의 값의 범위는 -1에서 1사이였지만 시그모이드는 0에서 1사이. 합친다는 것은 벡터를 concatenate한다고 표현. 예시로는 [1 2 3]과 [4 5 6]을 concatenate하면 [1 2 3 4 5 6]이 됨. hidden state의 값들과 입력값들을 하나로 합친다는 것을 의미. 망각게이트의 연산 결과는 ft로 표현.
(2) Wi, Wc : 입력 게이트(input gate)
현재 입력받은 정보에서 어떤 것을 cell state에 저장할지 결정. 2개의 fc layer가 있음.
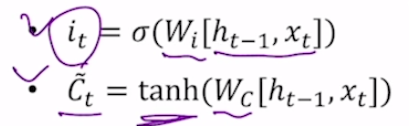
함수가 시그모이드, 탄젠트 하이퍼파라미터인것은 모델을 만든 사람이 만들 때 이미 결정된 것.
Ct, 즉 cell state 모양 위에 물결이 있는데 그 이유는 cell state에 저장될 정보의 일부라는 의미.
- 새로운 cell state
앞선 망각 게이트와 입력 게이트의 정보를 통해 cell state 갱신.
Ct = Ft Ct-1 + It C~t
이전의 cell state(ct-1)과 망각 게이트에서 나온 결과물이 곱해지고 앞선 인풋 게이트의 두 결과를 곱해서 ct-1과 ft를 곱한 결과와 더해줌. 망각게이트는 이전 cell state의 곱셈이 이루어짐. 망각 게이트는 이전의 cell state와 곱셈이 이루어짐. 이전의 기억된 정보 중 일부를 잊게 만드니까 망각 게이트임을 한 번 더 이해할 수 있음. 이 때 일어나는 곱셈은 벡터간의 곱셈이라 우리에게 익숙한 사칙연산과는 다른 곱셈. 벡터의 원소별로 곱하는 연산은 Hadamard Product라고 부름. 예를 들면 [1 2 3] * [4 5 6] = [4 10 18]. 같은 위치의 값들끼리 곱함. 컨볼루션 연산에서 커널과 커널이 겹쳐진 이미지에서 같은 위치의 픽셀의 값만 곱하는 것과 비슷한 것이라고 볼 수 있음.
(3) W0 : 출력 게이트(Output Gate)
다음 hidden state이자 output을 결정하는 게이트. 여기서는 앞선 과정에서 새로 계산된 cell state를 계산. 연산은 앞의 fc layer와 동일하게 이전 hidden state의 값과 현재의 입력값을 concatenate한 후 시그모이드에 전달해 Ot란 결과물을 뽑아냄. 이 Ot와 새로 계산된 cell state에 탄젠트 하이퍼볼릭에 적용후 그 두 값을 곱해줌. 이것도 hadamard product. 이것을 새로운 hidden state로 사용하고 출력값으로도 사용.
? lstm은 내부 연산 방식만 vanila rnn과 다르고 나머지 입력값과 출력값은 vanila rnn처럼 사용할 수 있기 때문. 즉 vanila rnn을 사용하는 모델을 lstm으로 바꾸기만 하면 똑같이 사용할 수 있음. 한 번 입력값과 출력값을 정의해놓으면 모델만 바꿔 더 좋은 성능을 기대할 수 있는 것이 딥러닝의 매력. 모델 자체를 만드는 것은 어렵지만 만들기만 하면 사용하기 간편한게 딥러닝이 발전하게 된 원인이라고도 볼 수 있을듯ㅎ
GRU
lstm을 계량한 모델. gated recurrent unit의 약자. lstm이 가지는 3개의 게이트를 2개로 간소화하고 cell state를 없앰. 파라미터 수가 감소하여 lstm보다 빠른 학습 속도를 가짐. 그럼에도 성능은 일반적으로 lstm과 비슷한 수준. 마찬가지로 새로 계산된 hidden state를 출력값으로 사용.
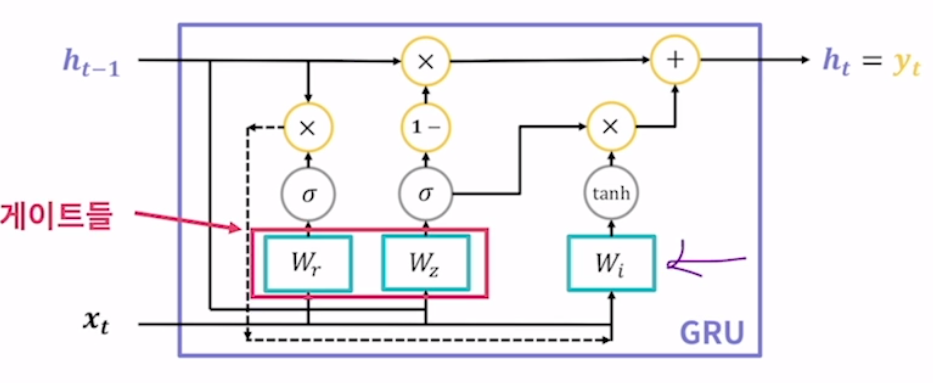
이미지 상에서는 화살표친 것이 하나의 게이트 같지만 아님.
(1) reset gate : 기존 hidden state의 정보를 얼마나 초기화할지 결정하는 게이트. lstm의 망각게이트와 어느정도 비슷하다고 할 수 있음. 연산 과정은 이전의 hidden gate와 현재의 입력값은 concatenate, 그리고 reset gate를 이루는 fc layer에 통과시킨 후 시그모이드 함수 적용.
(2) update gate : 기존 hidden state의 정보를 얼마나 사용할지 결정하는 게이트. 이 값은 zt라고 하며 앞선 리셋 게이트와 같은 연산 방식.
- 새로운 hidden state 계산. reset gate의 결과를 통해 새로운 hidden state의 후보를 계산.
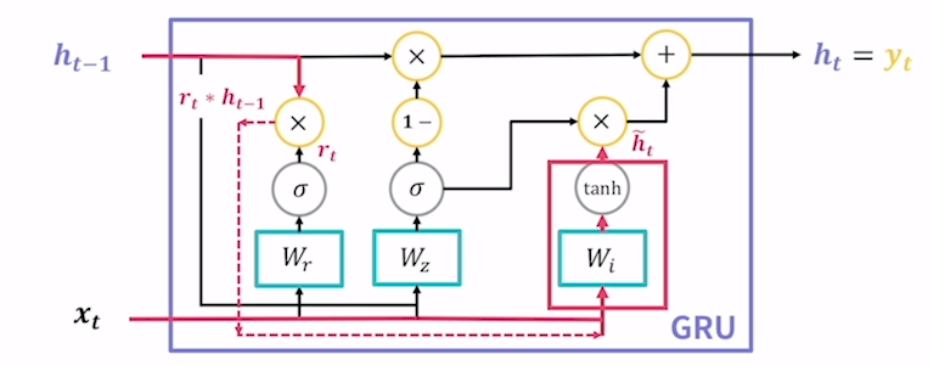
이전 hidden state의 값과 reset gate의 결과인 rt를 서로 haramad product. 실선이 아닌 점선을 통해 wi쪽으로 전달되고 있음. 점선으로 표시한 이유는 다른 실선과 겹치는 것이 전혀 없다는 것을, 별도의 경로라는 것을 명확히 전달하기 위해 사용. 이 점선은 3번째 fclayer에 전달하여 탄젠트 하이퍼볼릭 함수를 통해 새로운 h~t(hiddenstate 후보).
마지막으로 update gate의 결과를 통해 새로운 hidden state를 계산. update gate의 정보만이 새로운 hidden state 계산에 사용됨. update gate가 lstm의 forget gate와 input gate를 하나로 합친 것과 유사한 역할.
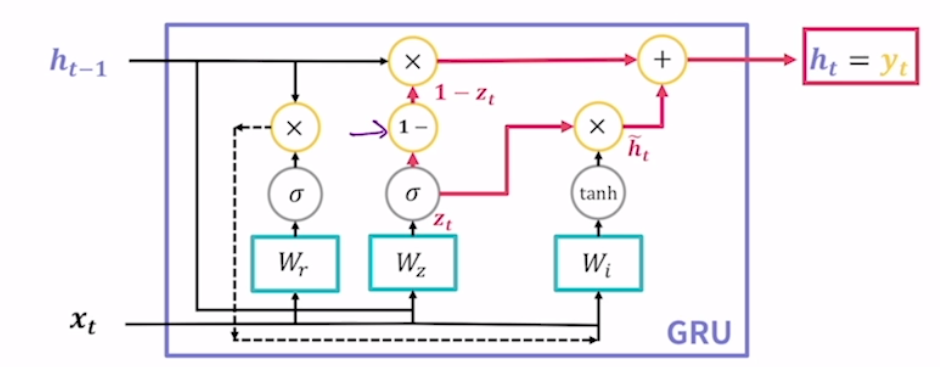
여기서 1-는 앞선 업데이트 결과 zt를 1에서 뺀다는 의미. (1) 뺀 결과인 1-zt를 이전 시점의 hidden state와 hadamard product 함. (2) 한편에서는 zt와 최종 hidden state 후보(h~t)가 벡터의 원소별로 곱해지는 hadamard product 진행. 그 후 (1) + (2) 진행.
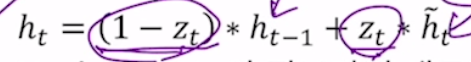
따라서 업데이트 게이트가 원래 히든스테이트를 얼마나 사용할지, 새로운 히든스테이트를 얼마나 사용할지 모두 결정하고 있음. 따라서 gru는 lrtm보다 파라미터수가 줄었음에도 유사한 성능을 보이는 것.
RNN 모델 활용
rnn/lstm/gru는 모두 회귀분석과 분류작업에 모두 활용 가능.
회귀 분석 : 각 시점의 출력값이 어느 정도일지 예측
분류 작업 : 각 시점의 데이터가 어느 클래스일지 예측. ex) 문장 내에서 나온 단어가 어떤 품사를 가지고 있을지
모델 학습을 위한 손실 함수 계산
모델이 예측가능한 값과 실제 값은 차이가 있기 마련. 그것이 손실이기 때문에 손실함수라고 함. cnn은 마지막에 예측 값이 하나로 나오지만 rnn은 각 시점 별로 예측값이 따로 나옴.
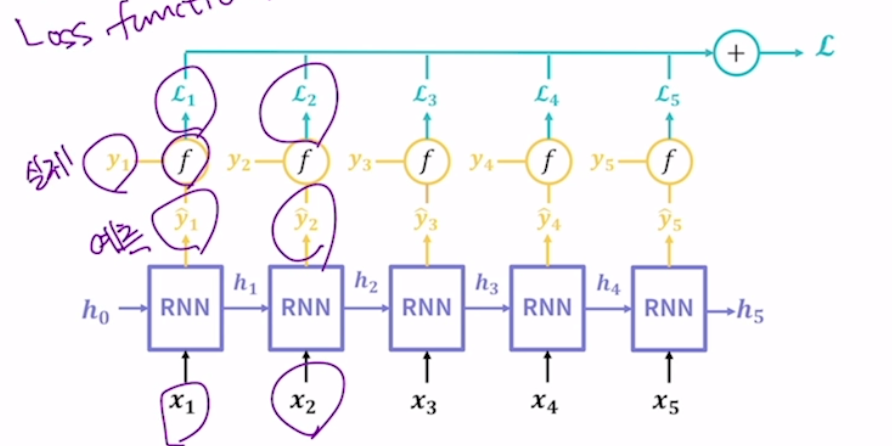
손실함수는 모두 다 더해서 사용.
회귀분석에서는 주로 Mean Squared Error(MSE)를 많이 사용하고 분류 작업에서는 Cross Entropy를 사용.
(1) 회귀 분석 예시
주가 예측, 기온 예측
(2) 분류 작업 예시
문장에서 다음 단어 예측(it 다음에 be동사가 나올 것 같은데 was가 나올지 is가 나올지 중 선택하는 작업이 일종의 분류라고 보는 것), 각 단어의 품사 예측

