import streamlit as st # 앱을 만드는 미니멀한 프레임워크
import os
import torch
import nltk
import urllib.request
from models.model_builder import ExtSummarizer
from newspaper import Article
from ext_sum import summarize
def main():
st.markdown("<h1 style='text-align: center;'>Extractive Summary✏️</h1>", unsafe_allow_html=True)
# Download model
if not os.path.exists('checkpoints/mobilebert_ext.pt'):
download_model()
# Load model
model = load_model('mobilebert')
# Input
## input type 버튼 생성해서 raw/url 클릭하는지에 따라 실행하는 방법
input_type = st.radio("Input Type: ", ["URL", "Raw Text"])
st.markdown("<h3 style='text-align: center;'>Input</h3>", unsafe_allow_html=True)
if input_type == "Raw Text":
with open("raw_data/input.txt") as f:
sample_text = f.read()
text = st.text_area("", sample_text, 200)
else:
url = st.text_input("", "https://www.cnn.com/2020/05/29/tech/facebook-violence-trump/index.html")
st.markdown(f"[*Read Original News*]({url})")
text = crawl_url(url)
input_fp = "raw_data/input.txt"
with open(input_fp, 'w') as file:
file.write(text)
# Summarize
## 결과물의 길이를 버튼으로
sum_level = st.radio("Output Length: ", ["Short", "Medium"])
## 버튼에 따른 결과물 길이
max_length = 3 if sum_level == "Short" else 5
result_fp = 'results/summary.txt'
## 실제로 요약된 값
summary = summarize(input_fp, result_fp, model, max_length=max_length)
st.markdown("<h3 style='text-align: center;'>Summary</h3>", unsafe_allow_html=True)
st.markdown(f"<p align='justify'>{summary}</p>", unsafe_allow_html=True)
def download_model():
nltk.download('popular')
url = 'https://www.googleapis.com/drive/v3/files/1umMOXoueo38zID_AKFSIOGxG9XjS5hDC?alt=media&key=AIzaSyCmo6sAQ37OK8DK4wnT94PoLx5lx-7VTDE'
# These are handles to two visual elements to animate.
weights_warning, progress_bar = None, None
try:
weights_warning = st.warning("Downloading checkpoint...")
progress_bar = st.progress(0)
with open('checkpoints/mobilebert_ext.pt', 'wb') as output_file:
with urllib.request.urlopen(url) as response:
length = int(response.info()["Content-Length"])
counter = 0.0
MEGABYTES = 2.0 ** 20.0
while True:
data = response.read(8192)
if not data:
break
counter += len(data)
output_file.write(data)
# We perform animation by overwriting the elements.
weights_warning.warning("Downloading checkpoint... (%6.2f/%6.2f MB)" %
(counter / MEGABYTES, length / MEGABYTES))
progress_bar.progress(min(counter / length, 1.0))
# Finally, we remove these visual elements by calling .empty().
finally:
if weights_warning is not None:
weights_warning.empty()
if progress_bar is not None:
progress_bar.empty()
@st.cache(suppress_st_warning=True)
def load_model(model_type):
checkpoint = torch.load(f'checkpoints/{model_type}_ext.pt', map_location='cpu')
model = ExtSummarizer(device="cpu", checkpoint=checkpoint, bert_type=model_type)
return model
def crawl_url(url):
article = Article(url)
article.download()
article.parse()
return article.text
if __name__ == "__main__":
main()
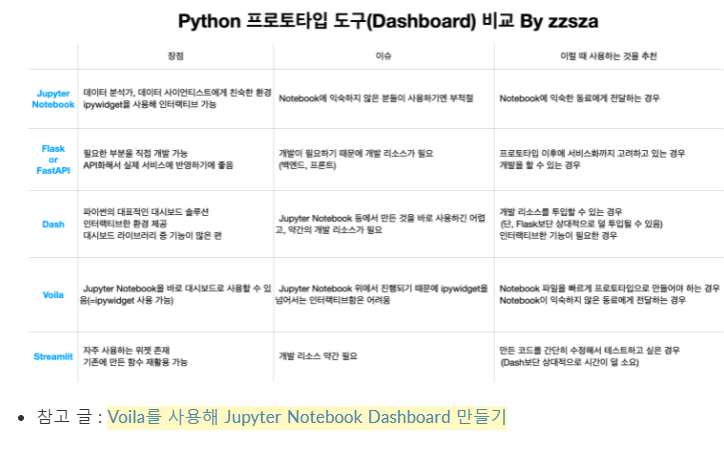
https://zzsza.github.io/mlops/2021/02/07/python-streamlit-dashboard/
input
처음 오류
Traceback (most recent call last):
File "real_test.py", line 104, in <module>
main()
File "real_test.py", line 48, in main
summary = summarize(input_fp, result_fp, model, max_length=max_length)
File "/home/u7ryean/project-template/ai/bert-extractive-summarization/ext_sum.py", line 114, in summarize
test(model, input_data, result_fp, max_length, block_trigram=True)
File "/home/u7ryean/project-template/ai/bert-extractive-summarization/ext_sum.py", line 80, in test
sent_scores, mask = model(src, segs, clss, mask, mask_cls)
File "/home/u7ryean/anaconda3/envs/test/lib/python3.6/site-packages/torch/nn/modules/module.py", line 493, in __call__
result = self.forward(*input, **kwargs)
File "/home/u7ryean/project-template/ai/bert-extractive-summarization/models/model_builder.py", line 47, in forward
sents_vec = top_vec[torch.arange(top_vec.size(0)).unsqueeze(1), clss]
IndexError: tensors used as indices must be long, byte or bool tensors결과물 : MarianaMazzucato_Government
PyTorch version 1.1.0 available.
PyTorch version 1.1.0 available.
loading configuration file checkpoints/mobilebert/config.json
Model config MobileBertConfig {
"attention_probs_dropout_prob": 0.1,
"classifier_activation": false,
"embedding_size": 128,
"hidden_act": "relu",
"hidden_dropout_prob": 0.0,
"hidden_size": 512,
"initializer_range": 0.02,
"intermediate_size": 512,
"intra_bottleneck_size": 128,
"key_query_shared_bottleneck": true,
"layer_norm_eps": 1e-12,
"max_position_embeddings": 512,
"model_type": "bert",
"normalization_type": "no_norm",
"num_attention_heads": 4,
"num_feedforward_networks": 4,
"num_hidden_layers": 24,
"pad_token_id": 0,
"trigram_input": true,
"true_hidden_size": 128,
"type_vocab_size": 2,
"use_bottleneck": true,
"use_bottleneck_attention": false,
"vocab_size": 30522
}
loading file https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-uncased-vocab.txt from cache at /home/u7ryean/.cache/torch/transformers/26bc1ad6c0ac742e9b52263248f6d0f00068293b33709fae12320c0e35ccfbbb.542ce4285a40d23a559526243235df47c5f75c197f04f37d1a0c124c32c9a084결과물 : input
PyTorch version 1.1.0 available.
PyTorch version 1.1.0 available.
loading configuration file checkpoints/mobilebert/config.json
Model config MobileBertConfig {
"attention_probs_dropout_prob": 0.1,
"classifier_activation": false,
"embedding_size": 128,
"hidden_act": "relu",
"hidden_dropout_prob": 0.0,
"hidden_size": 512,
"initializer_range": 0.02,
"intermediate_size": 512,
"intra_bottleneck_size": 128,
"key_query_shared_bottleneck": true,
"layer_norm_eps": 1e-12,
"max_position_embeddings": 512,
"model_type": "bert",
"normalization_type": "no_norm",
"num_attention_heads": 4,
"num_feedforward_networks": 4,
"num_hidden_layers": 24,
"pad_token_id": 0,
"trigram_input": true,
"true_hidden_size": 128,
"type_vocab_size": 2,
"use_bottleneck": true,
"use_bottleneck_attention": false,
"vocab_size": 30522
}
loading file https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-uncased-vocab.txt from cache at /home/u7ryean/.cache/torch/transformers/26bc1ad6c0ac742e9b52263248f6d0f00068293b33709fae12320c0e35ccfbbb.542ce4285a40d23a559526243235df47c5f75c197f04f37d1a0c124c32c9a0841. 사실 (Facts)
- bert-extractive-summarization 컴퓨터에서 실행해보기
- 해당 모델 ai_modeltest 브랜치 만들어서 푸시하기
- 해당 모델 구조를 완벽히 뜯어보는게 아니라 우선 결과값을 도출할 수 있을정도로만 파악 후 test용 text
5개(슬아님이 추가해주실 예정) 4개 샘플링해보기
2. 느낌 (Feeling)
- 나 오늘 깃 처음 써봤다! 저번 데이터 분석때는 그냥 쥬피터로 분석 결과랑 데이터셋 정리만 해드리면 되어서 깃을 써볼일이 없었고 쥬피터 파일도 그냥 웹에서 넣었는데.. 생각보다 별거없고 재밌다!
- clone해온 파일을 다시 깃랩에 올리려는 git이 중복되면서 문제가 발생했다. 폴더는 생기지만 해당 폴더를 사용할 수 없는 이슈... 구글링 해보면서 해결방법을 진즉 찾았었는데! 한단계만 따라해봤다가 뭔가 다 지워지는 느낌이 들어 허걱 하고 그만둬버렸었다. 근데 그게 제대로 된 방법이 맞았다. ㅋㅋㅋㅋ 계속 다시 해보는건 전혀 손해보는 일 아니고 오히려 정리하면서 더 빨리 진행할 수 있으니까 너무 겁먹지 말기! 지금 나는 병아리라 실수해도 병아리만큼의 실수만 한다.
- 남이 써놓은 코드를 훑어보며 여러 파일을 넘어다니면서 기억하고 정리하고.. 재밌었다!
- 가상환경도 vscode 터미널에서 돌리고 원래 해당 모델은 웹페이지가 돌아가는 코드가 있는데 그 뒤까지는 다 건드리기 힘들 것 같아서 그냥 터미널에서 결과값만 볼 수 있도록 했는데... 데이터 분석가에서 데이터 과학자가 되고 싶다가 이제는 풀스택 개발자가 되고싶은지도...? 바쁘다 바빠
3. 배운점 (Findings)
- 구글링을 잘 하자. 그리고 잘 따라하자.
- 깃 사용하는 방법! 도와주신 승수님, 진화님 감사합니다.
# 현재 내가 위치한 브랜치
git branch
# 브랜치를 새로 만들면서 브랜치 변경
git checkout -b 브랜치명
# 브랜치 삭제
git branch -d 브랜치명
git add .
git commit -m "커밋할 메세지"
git config --global user.name "내이름"
git push- 이번 모델에서 처음본거! 버튼을 만들거나 값을 받아오거나 이런 과정이 되게 간단한 것 같았다.
import streamlit as st # 앱을 만드는 미니멀한 프레임 워크4. 잘한 것, 못한 것에 대한 원인 분석
오늘 계획을 모두 수행했다면 그렇게 할 수 있었던 성공요인이 무엇이었나?
생각대로 되지 않았다면 그 이유는 무엇이었나? 어떤 점을 개선해야 같은 실수를 반복하지 않을 수 있을까?
- clone해온 파일을 하나하나 뜯어보며 어떤 모양을 가지고 있는지 머리속으로 그려가며, 모르는건 주석도 달아가며 살펴본게 이해하는데 큰 도움이 된 것 같다.
- 다만 더 구체적인것까지 이해하는건 시간낭비인가?하는 생각이 자꾸 들어 더 깊게 공부하지는 못했고 실제로 bert관련 논문, 논문 요약본을 살펴봤는데도 뭔지 잘 모르겠다. 역시 이 분야는 어렵다. 공부를 더 해야겠다.
5. 계획
전체 프로젝트의 진행 상황에 비추어 내일 이어서 해야할 일, 앞으로 해야할 일은 무엇인가?
가지고 있는 계획이 여전히 유효한가? 수정이 필요할까?
- 내일 있을 오피스아워에서 코치님께 결과물을 공유하고 모델 사용은 잘 했는지, 결과물은 보기 좋은지, 성능 파악을 위해 추가해야할 코드는 무엇인지 여쭤봐야 할 것 같다. 개인적으로 클린코드는 절대 아니라고 생각해서...^^ 도와주세요

유가연