
문서 유사도 측정
문서 : 문서는 다양한 요소와 이들의 상호작용으로 구성. 단어 -> 형태소 -> ... -> 문장 -> ... -> 문단

가장 기본 단위인 단어 조차 문서와 관련된 다양한 정보를 포함.
문서 유사도를 측정할 때는 가장 기본 단위인 단어를 활용하여 문서를 표현. 문서 유사도를 측정하기 위해 단어 기준으로 생성한 문서 벡터 간의 코사인 유사도를 활용. 정확한 문서 유사도 측정을 위해 문서의 특징을 잘 보존하는 벡터 표현 방식이 중요
Bag of Words
문서 내 단어의 빈도수를 기준으로 문서 벡터를 생성.

데이터 안에서 이 두개의 문서가 주어졌을 때, 각각의 문서를 FEATURE는 전체 문서에서 발생하는 단어. 그리고 값은 총 발생한 빈도수. 이 때 문서 벡터를 표현할 때는 FEATURE를 합쳐서 생성하기 때문에 어떤 문서에는 해당 단어가 존재하지 않아 값이 0일수도 있음.
여기서 나타나는 특징은 자주 발생하는 단어가 문서의 특징을 나타낸다는 것을 가정.
Bag of Words에서 문서 벡터의 차원은 데이터 내 발생하는 모든 단어의 개수와 동일. 데이터가 많아져서 문서가 많아질 경우 모든 문서에서 발생하는 단어들이 각각의 축이 됨.
단점은 종종 합성어를 독립적인 단어로 개별 처리.

Bag of N-grams
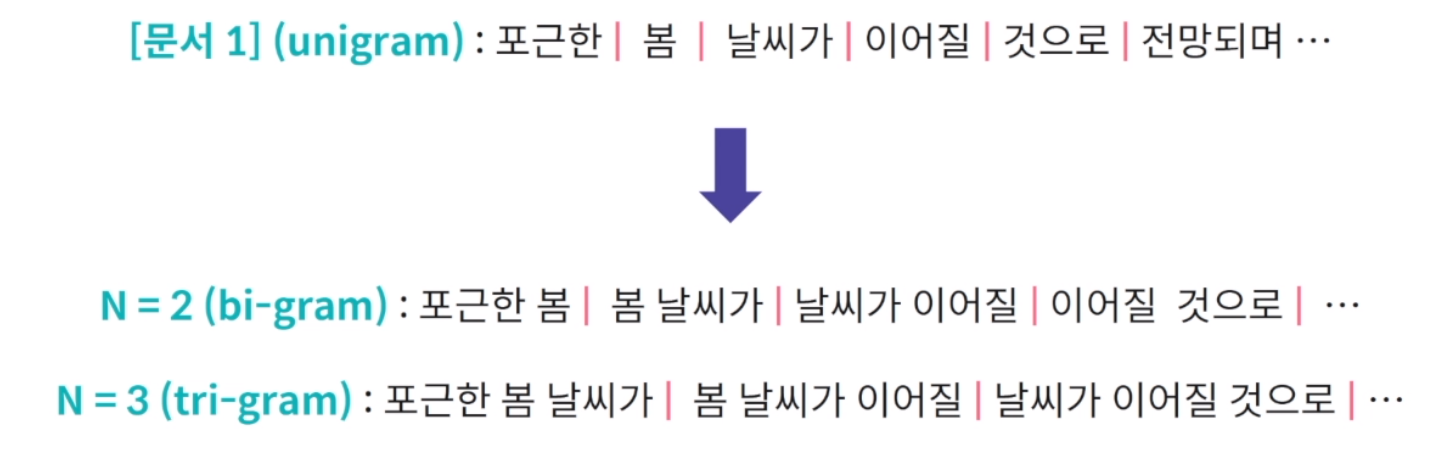
앞서 나온 합성어 문제를 해결하기 위한 방법. N-gram은 연속된 N개의 단어를 기준으로 텍스트 분석을 수행.

N-GRAM의 발생 빈도를 기준으로 문서 벡터를 표현.

여러 N-GRAM을 합쳐서 발생 빈도를 기준으로 문서 벡터를 표현할 수도 있음. UNIGRAM과 BI-GRAM을 같이 혼용해 FEATURE를 많이 사용할 수 있음.
하지만 BAG OF WORDS에서 가정한 자주 발생하는 단어가 문서의 주요 내용 및 특징을 나타낸다는 것이 항상 효과적인 것은 아님. 문서의 양이 많아질수록 그리고, 그러나 등 단어의 빈도수가 월등하게 높아질 수 있음.
TF-IDF(term frequency-inverse document frequency)
앞선 문제를 해결하기 위해 단순히 단어의 빈도수로 문서 벡터를 생성하는 것이 아니라 TF-IDF. 문서 내 상대적으로 자주 발생하는 단어가 더 중요하다는 점을 반영
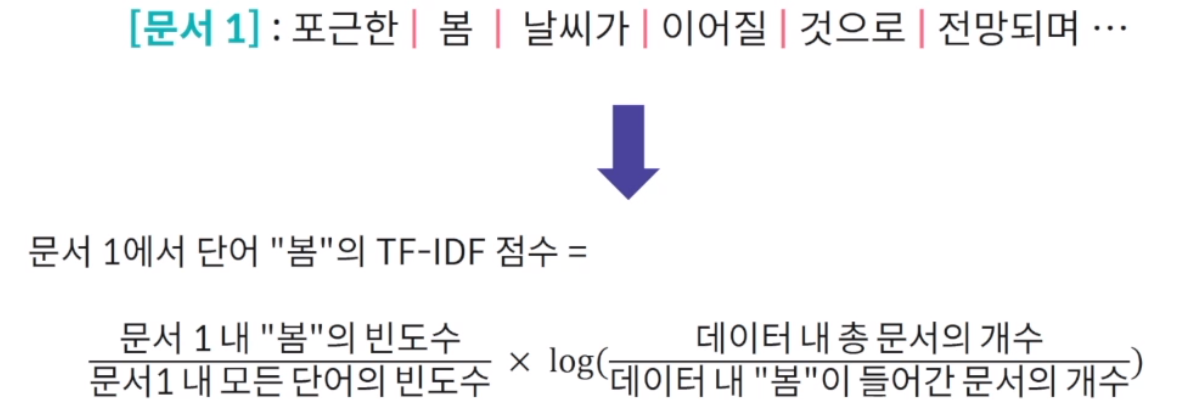
이것은 결국 이 단어 자체가 많이, 자주 모든 데이터에서 발생했다면 의미가 없는 단어로 판단할 수 있고 이를 통해 점수 자체를 낮춰 문서 벡터간 유사도를 계산할 때 큰 영향을 줄 수 없도록 함.

tf-idf 기반의 bag of words 문서 벡터는 단어의 상대적 중요성을 반영. 상대적 중요성이라는 것은 특정 문서 안에서 자주 발생하는 키워드 비슷한 단어들에 대해 점수를 올려주는 것. 모든 문서에서 발생하는 단어의 값은 줄여줌. 기능적 요소의 단어나 문법적 단어는 줄어듬. 이러한 값을 코사인 유사도로 계산.
doc2vec
BAG OF WORDS 기반 문서 벡터의 장점은 직관적. 직관적이라는 것은 어떠한 문서 벡터가 주어졌을 때 문서 벡터의 각각의 컬럼, FEATURE 값들이 단어의 빈도수를 의미하기 때문에 만약 어떤 문서간의 유사도를 계산해 유사도가 낮다, 크다 를 왜 그런지 보고 판단할 수 있음. 하지만 텍스트 데이터의 양이 증가하면, 문서 벡터의 차원증가. 지프의 법칙은 단어 빈도수가 낮은 애들 롱테일이 있음. 문서 벡터 차원이 증가하면 대부분 단어의 빈도수가 0인 희소(SPARSE) 벡터가 생성. 희소 벡터가 많이 생기고 문서 차원이 커지면 메모리 제약 및 비효율성 발생. 또한 문서 벡터의 차원 증가에 따른 차원의 저주가 발생됨. 차원의 저주란 어떠한 벡터의 차원이 증가하면 증가할 수록 벡터간의 거리, 유사도의 의미가 점점 사라짐을 의미.
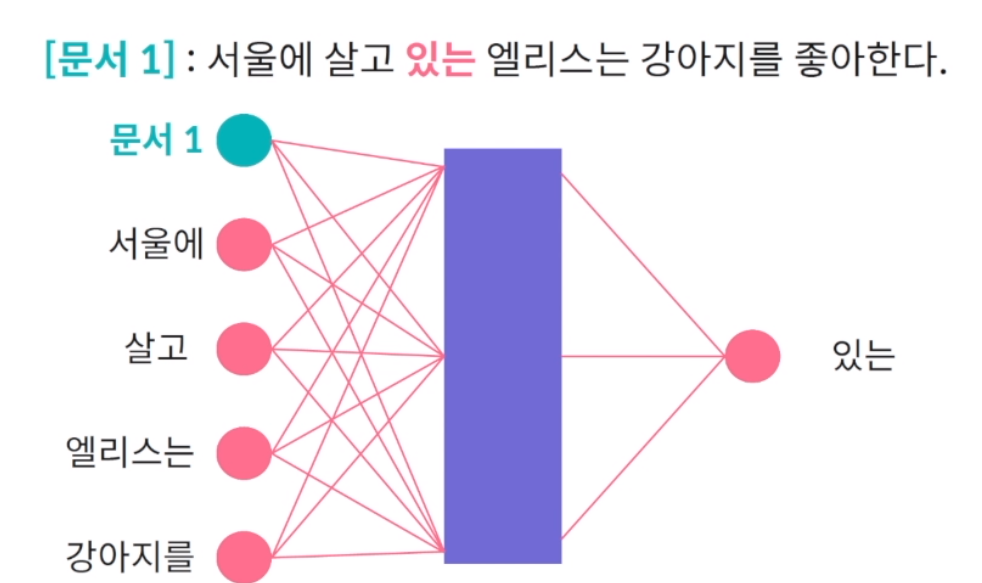
DOC2VEC WORD2VEC과 굉장히 유사. 차이점이 있다면 문서 내의 단어간의 문맥적 유사도를 기반으로 해서 하나의 IMPUT NODE가 더 생김. 이것은 문서를 나타내는 NODE가 되고 WORD2VEC에서 학습한 것과 같이 문맥이 주어졌을 때 단어를 맞추는 것을 풀때 문서 벡터는 계속 유지가 되어서 이 문서 벡터의 WEIGHT 값들도 학습됨. 이 문서 벡터도 단어 임베딩과 비슷하게 단일 신경망을 기준으로 은닉값을 사용해 수치형 벡터로 학습. 하나의 단어에 대해서 예측하는 문서를 학습하는데 WORD2VEC. 문장 내에서 단어들을 순차적으로 예측하는 문제를 풀면서 다음 단 벡터를 학습. DOC2VEC에서도 문서 벡터는 계속 유지가 되어서 WEIGHT를 지속적으로 학습. 문서 내 단어의 임베딩 벡터를 학습하면서 문서의 임베딩 또한 지속적으로 학습.

유사한 문맥의 문서 임베딩 벡터는 인접한 공간에 위치.
DOC2VEC은 고차원 문제를 해결. 상대적으로 저차원의 공간에서 문서 벡터를 생성. WORD2VEC에서 벡터의 차원은 은닉층(HIDDEN NODE)의 개수에 따라 생성되는 벡터의 차원이 정해짐. 따라서 지정 가능하고 조정 가능. 그렇기 때문에 단어가 더욱 많아지더라도 HIDDEN NODE가 단어가 늘어나는 만큼 늘어날 필요가 없고 우리가 조정할 수 있음. 또한 희소 벡터가 아닌 연속적인 벡터로 문서 벡터를 표현하기 때문에 하드웨어 제약, 차원의 저주에서 비교적 자유로움.
N-gram 기반 언어 모델
언어 모델 : 주어진 문장이 텍스트 데이터에서 발생할 확률을 계산하는 모델
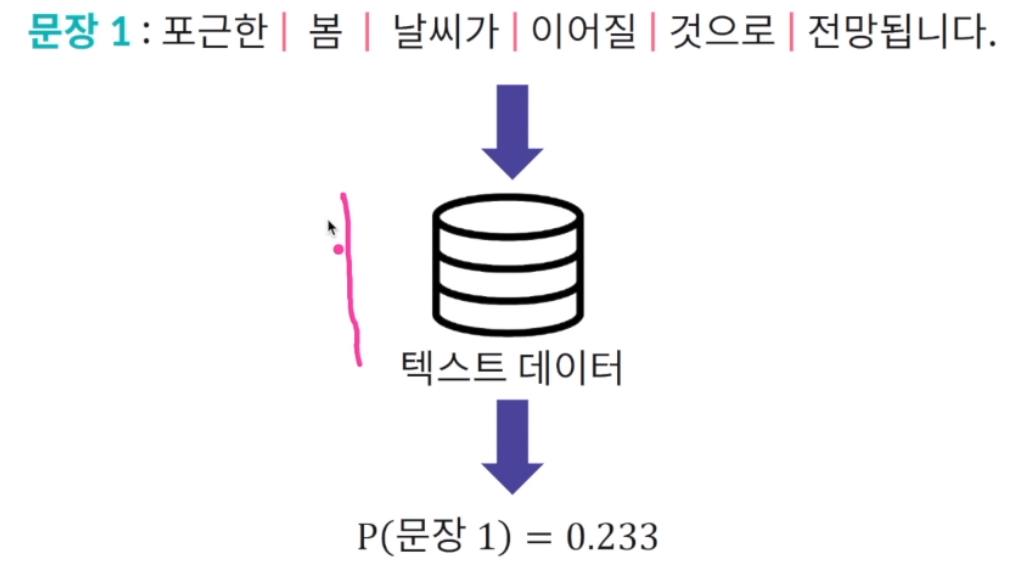
텍스트 데이터를 활용해서 문장1이 얼마나 말이 되고 실제로 발생할 수 있는 문장인지 예측하는 것이 목적. 기존에 주어진 텍스트 모델을 활용해 0.233이 나왔다면 이 문장이 말이 되는지, 생성할 수 있는 문장인지 판별 가능.
언어 모델의 확률값은 자동 문장 생성이 가능. 우리가 사용하는 인터넷 포털에서 원하는 질문의 일부분을 적으면 포털에서 알아서 문장을 완료해서 가장 말이되고 관심을 가질 만한 질문들을 자체적으로 생성. 자동 문장을 생성할 때는 언어 모델을 사용해 입력되는 단어들이 주어졌을 때 가장 발생 가능성이 높은 문장을 계산하고 사용자에게 반환. 챗봇 내 핵심 요소 중 하나. 챗봇 안에서도 언어 모델로 문장생성을 하고 계산되는 확률값을 기반으로 가장 발생 가능할 문장이나 단어들을 추출하는 방식으로 문장을 생성.
문장의 발생 확률은 단어가 발생할 조건부 확률의 곱으로 계산.
 결국 맨 마지막 단어 기준으로 보면 맨 앞에서 부터 직전 단어까지 주어졌을 때 해당 단어가 발생할 확률 곱까지 모두 곱해 발생 확률을 계산. 이미 오래전에 발생한 단어가 주어졌을 때 해당 단어의 발생 확률을 살펴본다는 것은 계산량도 많고 오래전보다는 바로 직전 발생한 단어가 조금 더 영향이 많을 것이라는 가정. 이것이 바로 N-GRAM기반 언어모델. 이전 모델에서는 처음 단어부터 바로 직전 발생 단어가 모두 주어졌을 때 해당 단어의 발생확률을 모두 곱했는데
결국 맨 마지막 단어 기준으로 보면 맨 앞에서 부터 직전 단어까지 주어졌을 때 해당 단어가 발생할 확률 곱까지 모두 곱해 발생 확률을 계산. 이미 오래전에 발생한 단어가 주어졌을 때 해당 단어의 발생 확률을 살펴본다는 것은 계산량도 많고 오래전보다는 바로 직전 발생한 단어가 조금 더 영향이 많을 것이라는 가정. 이것이 바로 N-GRAM기반 언어모델. 이전 모델에서는 처음 단어부터 바로 직전 발생 단어가 모두 주어졌을 때 해당 단어의 발생확률을 모두 곱했는데 
N-GRAM 을 사용하여 단어의 조건부 확률을 근사.

각 N-GRAM 기반 조건부 확률은 데이터 내 각 N-GRAM의 빈도수로 계산.

문장 생성 시, 주어진 단어 기준 최대 조건부 확률의 단어를 다음 단어로 생성.
RNN 기반 언어 모델
ngram 기반의 언어 모델에서는 직접 단어의 조건부 확률들을 계산해서 문장이나 단어들을 생성. rnn을 사용해서도 비슷한 모델을 만들어 문장 생성을 할 수 있음. rnn은 문장의 각 단어가 주어졌을 때 다음 단어를 예측하는 문제로 언어 모델 학습.

문자단위로도 가능. 문자 단위 언어 모델로 학습 데이터 내 존재하지 않았던 단어 처리 및 생성 가능.
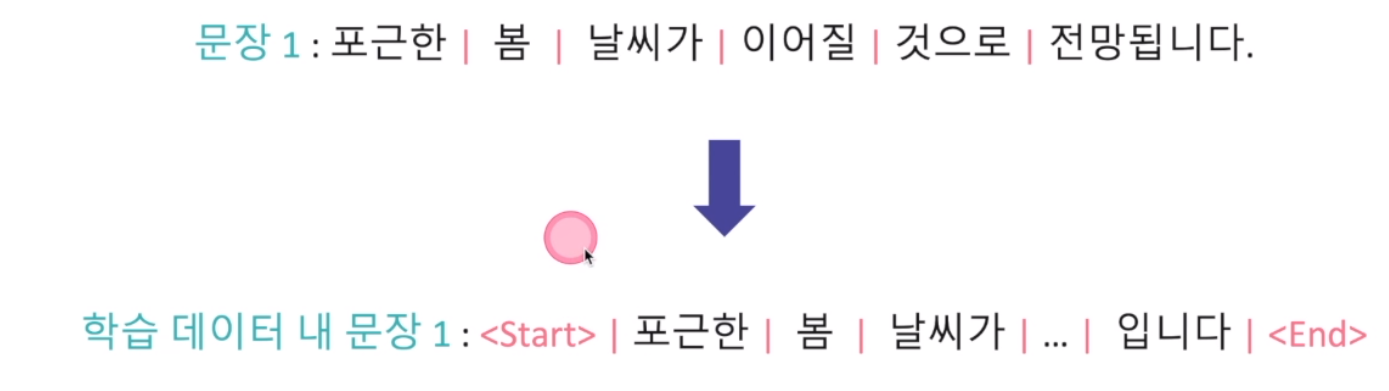
rnn 기반으로 학습을 할 때는 모델 학습시 문장의 시작과 종료를 의미하는 태그(tag)추가. 그래서 문장 생성시 주어진 입력값부터 순차적으로 예측 단어 및 문자를 생성.
언어모델은 학습하기 어려움. 고성능 언어 모델은 대용량 데이터와 복잡한 네트워크 구조로 이를 학습할 수 있는 하드웨어가 필수. openai를 가져와 트레이닝 하거나 활용할 수 있음.
