감정 분석 서비스
텍스트 데이터의 종류
(1) 객관적인 정보 : 뉴스, 백과 사전 같은 텍스트
(2) 주관적인 평가나 감정 : 리뷰, 소설 같은 텍스트
감정 분석이란 주관적인 평가나 감정이 들어가있는 문서를 대상으로 함. 대량의 텍스트가 있는 경우, 일일이 데이터를 하나씩 살펴보고 판단하기 어려움. 모델링을 통해 자동으로 문장이 주어졌을 때 문장의 주관적인 감정을 예측하거나 분류하는 모델 학습을 함. 이 때 비슷한 감정을 표현하는 문서는 유사한 단어 구성 및 언어적 특징을 보일 것이라고 가정.
감정 분석(Sentiment analysis)은 텍스트 내에 표현되는 감정 및 평가를 식별하는 자연어 처리의 한 분야.
그렇다면 모델링 관점에서 감정 분석은? 크게 두가지 기준으로 감정 분석을 진행할 수 있음. 텍스트 내 (1)감정을 분류하거나 (2)긍정/부정의 정도를 점수화하는 방법. 즉, 분류와 예측을 할 수 있는 모델. 머신러닝 기반 감정 분석 서비스의 경우, 데이터를 통한 모델 학습부터 시작. 지도 학습으로 문제를 풀어 나가야 함.
잘 주어진 학습 데이터 셋을 기반으로 잘 학습된 모델을 통해 신규 텍스트가 서비스를 통해 들어오고 이를 감정예측 하게 되는 것.
나이브 베이즈
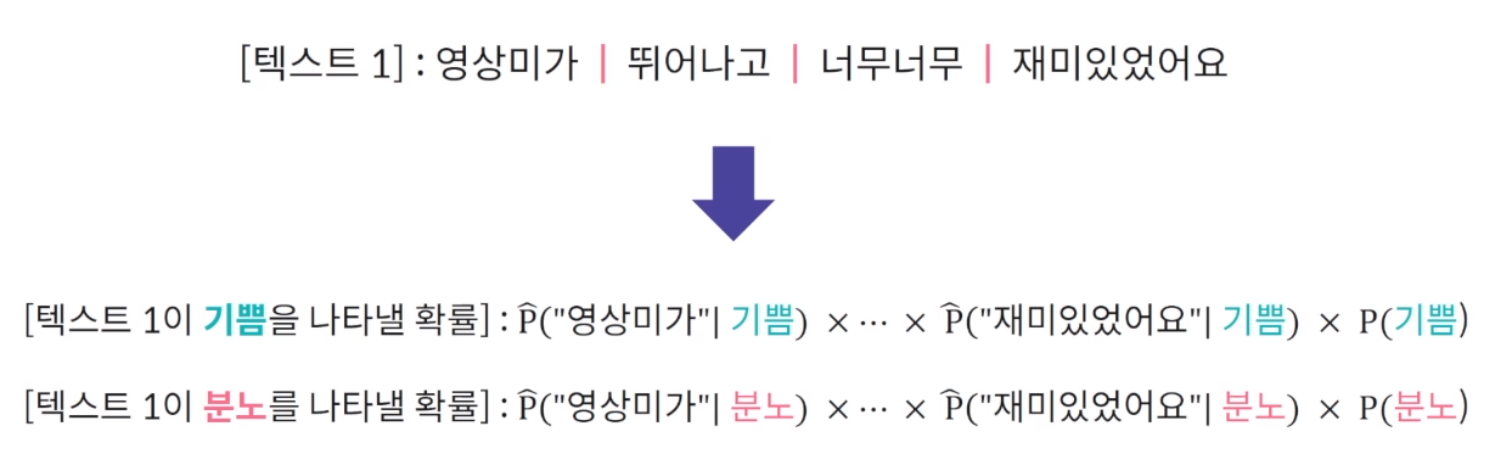
텍스트가 주어졌을 때 특정 감정을 나타낼 확률을 예측하는 문제로 텍스트의 감정을 분류함. 예를 들어 문장이 주어졌을 때 긍정적인 감정일 확률과 부정적인 감정일 확률을 구해 더 큰 확률을 가지는 감정으로 확률을 예측. 주의해야할 점은 여기서 조건부 확률을 사용한다는 점.

베이즈 정리를 사용하여 텍스트의 감정 발생 확률을 추정. 긍정, 부정일 때 P(감정)은 긍, 부정일 때가 서로 다르지만 P(텍스트)가 같기 때문에 비교가 가능. 우리의 목적은 긍, 부정 확률의 비교이기 때문에 P(텍스트)로 나누는 연산은 반복적이기 때문에 서로 제거 가능.
나이브 : 단순한, 순진한, 심플한
감정의 발생 확률과 텍스트를 구성하는 단어들의 가능도(LIKELIHOOD)로 텍스트의 감정을 예측. 텍스트가 발생할 확률? 그래서 나이브 베이즈에서는 간단한 가정을 함. 텍스트는 단어들로 구성 되어 있으므로 감정이 주어졌을 때 텍스트의 발생 확률 보다 감정이 주어졌을 때 텍스트 내 각각의 단어들이 발생할 확률을 사용하자는 의미.
즉, 최종 계산식 = 해당 감정 내 단어들이 발생할 가능성 * 감정의 발생확률
단어의 가능도

텍스트 데이터에서의 가능도는 단어의 빈도수로 추정
감정의 발생 확률

감정의 발생 확률은 주어진 텍스트 데이터 내 해당 감정을 표현하는 문서의 비율로 추정.
텍스트의 감정별 확률값 중 최대 확률값을 나타내는 감정을 해당 문서의 감정으로 예측.
단어의 가능도를 모두 곱해 나이브 계산이 들어가고 이후 감정의 발생 확률을 곱해줌.
나이브 베이즈 기반 감정 예측
스무딩(smoothing)
스무딩을 통해 학습 데이터 내 존재하지 않은 단어의 빈도수를 보정

예측할 때 예측 문장 내 학습데이터 내 감정 문서 중 단어의 빈도수가 0 이 되고 최종 곱이 0이됨. 일종의 작은 값을 갖게됨. 나이브 베이즈에서 중요한 부분. 단어의 감정별 가능도와 감정의 발생 확률은 모두 소수로 표현. 연속적으로 소수를 곱하게 되면 결괏값을 끊임없이 감소. 나이브 베이즈를 통해서 감정 예측을 할 때 단어의 수가 많아질수록 텍스트의 확률값은 컴퓨터가 처리할 수 있는 소수점의 범위보다 작아질 수 있음. 단어에 대한 가능도를 계속 곱하기 때문에. 이를 해결하기 위해 각 소수점에 로그를 사용함. 로그를 사용하면 끊임없이 숫자가 작아지는 것을 방지.
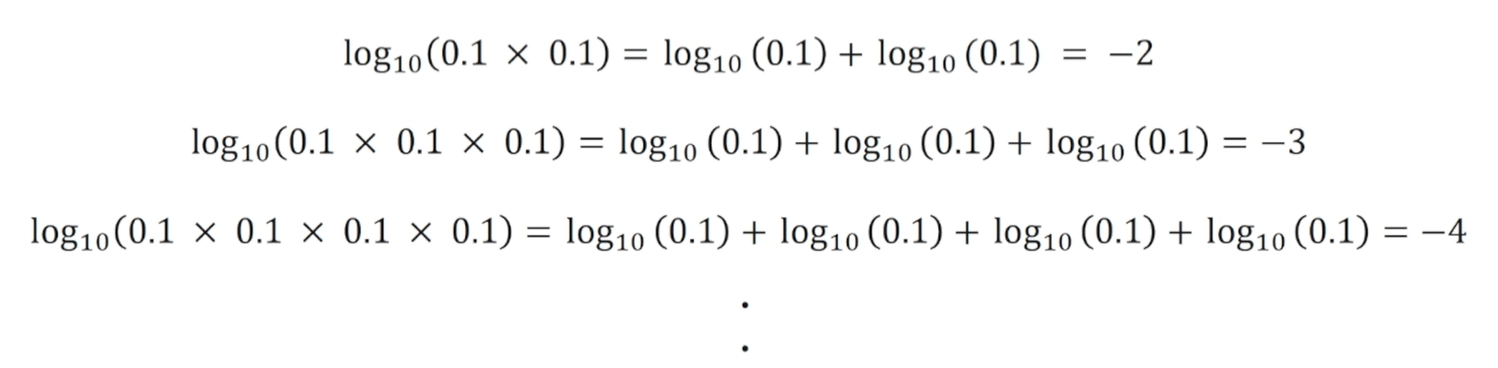
=> 최종 나이브 베이즈

로그 확률값의 합으로 텍스트의 감정을 예측
scikit-learn을 통한 나이브 베이즈 구현
scikit-learn은 각종 데이터 전처리 및 머신 러닝 모델을 간편한 형태로 제공하는 파이썬 라이브러리.
나이브 베이즈 구현
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
doc = ['i am very happy', 'this product is really great']
emotion = ['happy', excited]
# 나이브 베이즈로 텍스트 처리를 할 때는 텍스트 데이터를 수치형 데이터로 변환해야함.
## 클래스 객체 생성
cv = CountVectorizer()
## 수치형 데이터로 변환하기 위해서 생성한 객체.fit_transform(학습으로 사용할 문장)
## 행렬 형태의 수치형 데이터로 변환됨
csr_doc_matrix = cv.fit_transform(doc)
## 행렬을 만들어 각 줄은 문장1, 문장2. 각 컬럼들은 문장에서 생성된 모든 단어들. 값은 문장에서 해당 컬럼 단어가 발생한 빈도수. 이걸 합쳐 하나의 행렬, 큰 벡터로 생성.
# 각 단어 및 문장별 고유 ID 부여 및 단어의 빈도수를 계산
Pprint(src_doc_metrix)
# (0, 0) 1, (0, 7) 1
## 클래스 객체 생성
clf = MultinomialNB()
# CountVectorizer로 변환된 텍스트 데이터를 사용해 모델 학습
## 학습 데이터와 학습 데이터 내 문장이 나타내는 감정(레이블)을 넣어줌.
## 감정(레이블)은 텍스트 자체를 넣어도 상관이 없으나 학습 데이터 자체는 문장 자체가 아닌 CountVectorizer로 fit_transform을 한 행렬을 넣어줘야함.
clf.fit(csr_doc_matrix, emotion)
test_doc = ['i am really great']
# 학습된 CountVectorizer 형태로 변환
transformed_test = cv.transform(test_doc)
pred = clf.predict(transformed_test)
print(pred)
# array(['excited'], dtype = '<U7')기타 감정 분석 기법
지금까지는 나이브 베이즈 기반으로 감정을 분석함. 감정 분석은 결국 지도 학습 기반으로 분류 및 예측의 문제를 푸는 것. 학습 데이터에 감정만 존재하면 머신러닝 알고리즘 학습이 가능.
임베딩 벡터를 사용하여, 머신러닝 알고리즘 적용이 가능. 수치형 데이터로 텍스트가 변환만 잘 되면 그 뒤는 자연어 처리의 범주보다는 머신러닝과 더 밀접.
(1) 평균 임베딩 벡터
텍스트가 주어졌을 때 각 단어의 임베딩 벡터를 평균을 내서 텍스트를 하나의 벡터로 표현하는 방법. 가장 간단한 방법. 입력값이 수치형 데이터이기 때문에 분류, 예측 알고리즘은 머신러닝에서 골라서 사용 가능.
(2) CNN
단어 임베딩 벡터에 필터를 적용하여 CNN 기반으로 감정 분류. 단어 기준으로 감정 분석을 진행할 때는 단어를 임베딩 벡터로 표현하고 이 단어들의 범위에 따라 임베딩 벡터에 필터를 적용해 CNN 기반으로 감정 분석을 진행할 수 있음. 한 번에 살펴볼 단어의 개수를 조절해 다양한 FEATURE를 만든 후 CNN으로 학습 가능. 중요한 것은 임베딩 벡터를 사용했다는것. 앞서는 단어로 했는데 문자 레벨의 임베딩 또한 가능함.
결국 중요한 것은 얼마만큼의 학습 데이터가 있는가, 학습 데이터 내 감정을 나타내는 단어가 있는가.
(3) RNN
LSTM, GRU를 활용하여 RNN 기반으로 분류 및 예측. 각각 단어의 CELL에 임베딩 벡터를 넣고 순차적으로 RNN 구조로 만들고 감정을 예측할 수 있도록 설계하면 됨. RNN또한 문자 단위 임베딩 벡터를 사용할 수 있음. 자연어 처리에서 문자를 어떻게 수치형 데이터로 표현하는가가 고민이 많이 되는 부분인데 이 이후는 기존 알고리즘들을 다양하게 적용 가능.
=> 문장별 감정이 매핑되어 있는 데이터셋만 제공된다면 모든 지도학습 기반 알고리즘을 사용할 수 있음.
