ELECTRA: PRE-TRAINING TEXT ENCODERS AS DISCRIMINATORS RATHER THAN GENERATORS
ELECTRA: PRE-TRAINING TEXT ENCODERS AS DISCRIMINATORS RATHER THAN GENERATORS는 2020년 발표된 논문입니다.
요약
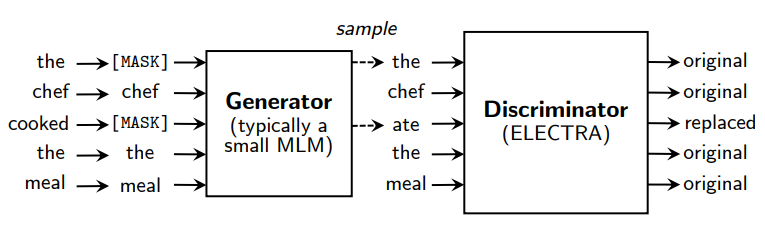
ELECTRA는 Generator와 Disciriminator 모델로 이루어져 있는데, Generator에서는 문장을 생성하고 Discriminator에서는 주어진 문장이 Generator에 의해 생성된 문장인지 검증합니다. GAN 모델의 학습 방식을 NLP에 적용한 것으로 이 방식을 통해 ELECTRA는 기존 MLM 모델에 비해 훨씬 적은 자원을 사용하고도 더 좋은 성능을 보였습니다.
개요
기존의 MLM 방식에서는 pre-training에서는 문장 내의 일부 토큰이 마스킹 된 데이터를, fine-tuning에서는 완전한 데이터를 학습하였는데, 이 두 데이터의 차이점으로 인해 학습의 효율이 떨어졌습니다. 그에 대한 대안으로 ELECTRA에서는 replaced token detection 방식을 제시하였습니다. 해당 방식은 문장의 일부 토큰을 마스킹하는 것 대신에 그 자리에 들어갈 만한 다른 단어로 교체하는 것입니다. 이렇게 하면 pre-training 시에도 fine-tuning에서 활용하는 데이터처럼 완전한(하지만 일부 토큰은 원래 토큰과 유사한 다른 토큰임) 문장을 학습할 수 있습니다.
그래서 ELECTRA는 Disicriminator에서 각 토큰이 원래의 토큰인지 아니면 모델에 의해 교체된 동의어 토큰인지를 구별합니다. 이 방식의 장점은 데이터의 모든 토큰을 학습에 활용할 수 있다는 점입니다. 기존의 MLM 모델은 데이터 중 매우 일부인 [MASK] 토큰을 위주로 학습을 하였기 때문에 ELECTRA의 방식을 활용하면 훨씬 효율적인 학습이 가능합니다.
학습 방식
ELECTRA는 Generator와 Discriminator 모델이 합쳐진 것으로 각각 G, D라고 부르겠습니다. 각각의 모델은 토큰 를 vector representation 로 매핑하는 encoder로 이루어져 있습니다. 위치 에서 generator의 출력은 해당 위치에 toekn 가 등장할 소프트맥스 확률로 수식은 아래와 같습니다.
위 수식에서 는 토큰 임베딩으로 수식을 해석해 보면 해당 위치 에서 전체 token들 중 특정 token이 등장할 확률을 소프트맥스 함수로 계산한 것임을 알 수 있습니다.
위치 에서 discriminator의 예측값은 현재 위치에서 token 가 원래의 token일 확률에 대한 시그모이드 값으로 수식은 아래와 같습니다.
Generator는 MLM처럼 작동하는 것을 목표로 학습이 되었습니다. Input 가 주어지면 MLM은 먼저 마스킹할 토큰을 선정하고 그 자리를 마스킹 처리합니다. 논문에서는 이를 라고 정리하였습니다. Generator는 마스킹 된 토큰의 원래 의미를 예측하는 학습을 합니다. 그리고 Discriminator는 주어진 토큰이 원래의 토큰인지 아니면 모델에 의해 교체된 토큰인지를 예측하는 학습을 합니다.
모델에 입력되는 값은 아래의 방식으로 생성됩니다.
Generator
unif
Discriminator
for
Generator 모델의 입력 데이터에는 마스킹이 적용되고 마스킹 위치는 1부터 n 사이의 정수로 유니폼 분포에 따라 결정됩니다. Discriminator 모델의 입력데이터는 일부 토큰을 Generator 모델에서 해당 위치에 들어갈 만하다고 예측한 토큰으로 변환하는 방식으로 생성됩니다.
각 모델의 학습에 사용되는 손실 함수는 아래와 같습니다.
Generator
Discriminaotr
마지막으로 ELECTRA와 GAN의 차이에 대해 알아보겠습니다. 가장 먼저 ELECTRA는 Generator에서 정확한 토큰을 생성할 경우 해당 데이터를 real 데이터로 간주합니다. 두 번째로 기존의 GAN에서는 Generator의 discriminator의 점수를 낮추는 방향으로 학습하는 것이었다면 ELECTRA는 maximu likelihood로 학습이 됩니다. 마지막으로 ELECTRA에서는 Generator에 노이즈 데이터를 입력하지 않습니다.
두 모델의 손실 함수를 합쳐만든 ELECTRA 모델의 손실 함수는 수식으로 나타내면 으로 ELECTRA의 최종 목표는 이 손실 함수를 최소로 만드는 것입니다.
모델 성능 향상
연구진들은 ELECTRA 모델의 성능 향상을 위해 몇가지 추가 실험을 진행하였습니다.
Weight Sharing
연구진들은 학습 효율 향상을 위해 Generator와 Discriminator의 가중치를 공유하는 방안을 제안했습니다. 두 모델 모두 transformer 기반이기 때문에 같은 사이즈라면 서로 가중치를 공유할 수 있습니다. 또한 연구진들은 작은 사이즈의 generator를 가지고 두 모델의 embedding만 공유하는 것이 성능은 전체 가중치를 공유하는 것에 비해 약간 떨어지지만, 훨씬 더 효율적인 학습이 가능하다는 것을 발견했습니다. 거기에다 Generator와 Discriminator의 사이즈가 반드시 같아야한다는 점은 큰 제약이었기 때문에 이후의 실험에서는 embedding weight sharing만을 사용하였습니다.
Smaller Generators
만약 Generator와 Discriminator가 같은 사이즈라면 ELECTRA의 학습에는 MLM 단일 모델의 학습에 필요한 것보다 두 배에 가까운 자원이 필요할 것입니다. 따라서 작은 사이즈의 generator를 사용하는데 이때 다른 하이퍼파라미터는 건들지 않고 레이어의 수만 줄이는 방식으로 모델의 사이즈를 줄였습니다.
연구진들은 연구 결과 Generator의 사이즈가 Discriminator의 1/4에서 1/2 정도일 때 가장 성능이 좋다는 것을 발견하였습니다. 이러한 이유에 대해 연구진들은 Generator의 성능이 너무 높을 경우 Discriminator가 제대로 학습하지 못한다는 문제가 발생하는 것 같다고 짐작을 하였고 따라서 이후의 실험은 위에서 발견한 비율로 사이즈를 조절하여 진행하였습니다.
Training Algorithms
마지막으로 연구진들은 새로운 학습 알고리즘 활용도 도전하였습니다. Generator와 Discriminator를 jointly하게 학습하는 방법으로 아래의 두 단계를 활용한 방식으로 학습을 진행하였습니다.
1. Generator를 step만큼 학습한다.
2. Generator의 가중치를 통해 Discriminator의 가중치를 initialize한다. 그 후 Discriminator를 step만큼 학습한다. 이 과정에서 Generator의 가중치는 freeze해놓는다.
이 방법을 사용하기 위해서는 Generator와 Discriminator의 사이즈가 동일해야 합니다. 또한 해당 과정에서 Discriminator가 Generator의 가중치를 사용하지 않고 처음부터 학습을 할 경우 두 모델 간의 극심한 성능차이로 인해 학습이 정상적으로 진행되지 않습니다. Jointly한 학습 방법을 통해 이런 점을 상쇄시키는 것입니다.
이 외에도 GAN처럼 adversary한 방식으로도 학습을 진행하였습니다. 하지만 이 방식은 기존의 학습 방식에 비해서 좋은 모습을 보이지 못했는데 그 이유는 첫째로 MLM의 성능이 낮았고(maximum likelihood 방식에 비해) 두 번째로 adversary한 방식으로 인해 Generator가 분포의 엔트로피가 낮았고 그에 따라 생성되는 토큰의 수가 제한적이었기 때문입니다.
기존 방식과 Jointly 학습 방식, adversary 학습 방식을 비교한 결과 Jointly 방식이 가장 성능이 좋았습니다.
학습의 효율성
연구진들은 토큰의 일부 정보만 학습하는 MLM 모델이 학습 효율이 떨어진다고 하였습니다. 연구진들은 과연 ELECTRA가 얼마나 효율적인지 알아보기 위해 다른 방식들과 비교를 하는 실험을 하였습니다.
ELECTRA 15%: ELECTRA와 동일하지만, 전체 입력값 중 마스킹 된 15%의 토큰에서만의 discriminator loss를 통해 학습하는 ELECTRA
Replace MLM: 기존의 MLM 모델과 동일한 방식이지만 [MASK] 토큰 대신 Generator 모델에서 예측한 토큰을 사용하였습니다.
All-Tokens MLM: Relpace MLM처럼 마스킹 된 토큰들은 Generator의 예측값으로 치환됩니다. 하지만 All-Tokens 방식에서는 일부 토큰이 아닌 모든 토큰이 치환됩니다.
실험 결과는 아래와 같습니다.

모두 기존의 ELECTRA의 성능에 미치지 못했지만, BERT 모델보다 좋은 성능을 보였습니다. 이를 통해 ELECTRA의 모든 토큰을 활용해 학습을 하는 것이 효율적이라는 점(ELECTRA 15% vs ELECTRA 100%), 사전 학습에서 [MASK] 토큰을 사용하는 것이 파인 튜닝 과정에서 성능 저하를 부른다는 점(BERT vs Replace MLM)는 점을 알 수 있습니다.
모델 성능 실험 결과
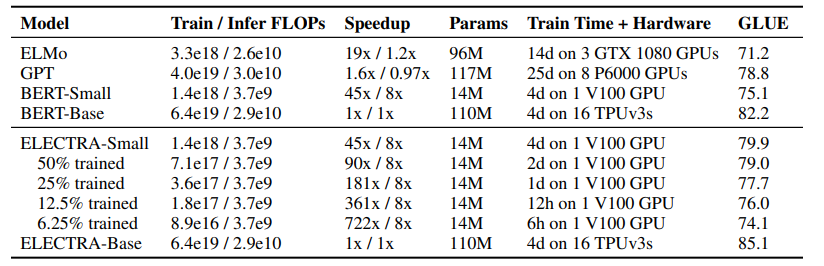 pre-training의 효과를 알아보기 위해 하나의 GPU에서도 빠르게 학습 가능한 작은 모델 사이즈로 실험을 진행하였다. 그리고 실험 결과 ELECTRA는 14M의 사이즈로도 본인보다 훨씬 파라미터 숫자가 많은 모델들의 성능을 뛰어넘었다.
pre-training의 효과를 알아보기 위해 하나의 GPU에서도 빠르게 학습 가능한 작은 모델 사이즈로 실험을 진행하였다. 그리고 실험 결과 ELECTRA는 14M의 사이즈로도 본인보다 훨씬 파라미터 숫자가 많은 모델들의 성능을 뛰어넘었다.
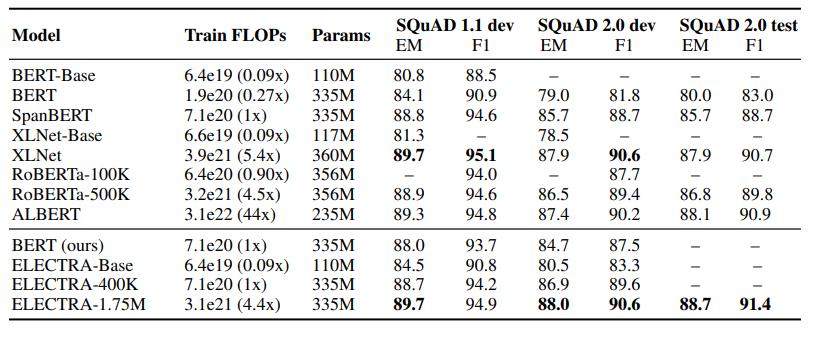 ELECTRA의 모델 사이즈에 따른 성능, 다른 모델들과의 성능 차이를 비교하기 위한 실험 결과로 ELECTRA-1.75M 모델이 한 가지 태스크를 제외하고 모두 최고 성적을 거둔 것을 알 수 있다.
ELECTRA의 모델 사이즈에 따른 성능, 다른 모델들과의 성능 차이를 비교하기 위한 실험 결과로 ELECTRA-1.75M 모델이 한 가지 태스크를 제외하고 모두 최고 성적을 거둔 것을 알 수 있다.
결론
해당 논문에서는 replaced token detection이라는 새로운 self-supervised 학습 방식을 제시했다. 이 방식의 핵심 아이디어는 작은 크기의 generator에서 높은 퀄리티의 샘플들을 뽑아내고 이를 구별해내는 것이다.
MLM 모델과 비교하였을 때, ELECTRA의 방식은 훨씬 효율적인 학습과 높은 성능이라는 장점을 가집니다. 이런 방식을 통해 적은 자원으로도 모델을 학습할 수 있는 환경이 만들어지고 NLP 연구의 접근성이 오를 수 있었습니다.
후기
이번에도 부캠 시절 사용해 본 모델의 논문을 읽어보았다. 그 당시 사용했던 모델의 논문을 이제서야 읽는다는 게 어이가 없기도 하지만 그때 이름이라도 들어놓았기 때문에 이제라도 읽게 되었다는 생각도 든다. 이런 과정을 거치면서 그때의 내가 얼마나 부족했는지에 대해 다시 생각해 보게 된다.
미래의 나도 또 다른 논문이나 책을 읽으면서 지금의 내가 부족했는지 다시 생각해 볼 시간이 올 거라고 생각한다. 이런 순환은 내가 이 길을 가는 이상 무한히 반복될 것이라 생각하고 그때마다 이렇게 적어놓은 후기들을 보며 이렇게 생각할 것이다.
"그래도 이때보다는 낫네"
