
Improving Language Understanding by Generative Pre-Training
Improving Language Understanding by Generative Pre-Training는 2018년 OPEN AI에서 발표한 모델로 LLM 전성시대의 포문을 연 ChatGPT의 원형이 되는 모델입니다. GPT는 BERT처럼 Transformer에서 파생된 모델이지만 BERT와 달리 Decoder 부분을 활용하는 모델로 출시 당시 9개의 태스크에서 SOTA를 달성했었습니다.
요약
GPT는 Transformer의 Decoder 부분을 활용하는 모델로 많은 분들이 아시는 ChatGPT의 원형 모델입니다. 논문의 Abstract 부분에서는 모델의 구조에 관한 언급이 없지만 요약 부분에 대략적인 설명을 첨부하는 것이 좋을 것 같아 임의로 내용을 추가하였습니다.
NLU분야 태스크를 진행하는 데 있어서 겪게 되는 어려움 중 하나는 학습에 필요한 labeled 데이터의 양이 부족하다는 점입니다. 해당 논문에서는 unlabeled 데이터를 활용하여 먼저 선 학습을 진행하는 방법을 통해 이러한 문제를 극복할 수 있다는 점을 보여주었고 12개의 태스크 중 무려 9개의 태스크에서 SOTA를 달성했었습니다.
Related Work
Semi-supervised learning: 그동안 많은 실험들을 통해 unlabeled 데이터를 활용한 학습이 성능 향상에 도움이 된다는 것이 증명되었습니다. 하지만, 이 실험들은 단어 수준에서의 정보를 활용하는 것에 그쳤지만 해당 논문에서는 구문이나 문장 수준에서의 정보를 활용할 수 있도록 하였습니다.
Unsupervised pre-training: Unsupervised learning은 다양한 분야에서 활용되는 기술로 다양한 실험을 통해 그 효과가 입증되었습니다. NLP 분야에서도 역시 Unsupervised learning이 활용되었지만, LSTM 모델의 한계로 인해 제약이 있었습니다. 하지만 Transformer의 등장으로 그 제약을 상당 부분 해소할 수 있었고 해당 논문에서는 실험을 통해 그 내용을 입증하였습니다.
Auxiliary training objectives: Auxiliary training(보조 학습)은 semi-supervised learning의 한 방식으로 이전의 실험들을 통해 효과가 입증되었고 해당 논문에서도 이 방식을 사용하였습니다.
모델 학습 과정
GPT의 모델 학습 과정은 두 단계로 이루어져 있는데 첫 번째 단계에서는 대량의 텍스트 데이터에서 언어의 특성을 학습하고 두 번째 단계에서는 특정 태스크에 맞는 labeled data로 fine-tuning을 수행합니다.
Unsupervised pre-training: 현재 단계에서는 υ개의 토큰으로 이루어진 텍스트 데이터에서 아래의 수식의 값을 최대화 시키는 것을 목적으로 학습을 진행합니다.
위 수식은 이전까지 나온 단어들을 기반으로 그 뒤에 이어져 등장할 확률이 가장 높은 token을 찾는 수식으로 k는 context window의 크기이고 는 모델 파라미터입니다.
Supervised fine-tuning: 위의 단계에서 언어의 특성을 모델에게 학습시켰다면 이번 단계에서는 태스크에 관한 학습을 진행합니다. 학습 방식은 입력 토큰의 시퀀스와 정답으로 이루어진 labeled 데이터셋 C가 있을 때 C의 데이터를 모델에 입력해 모델의 최종 출력값 을 구하고 이를 linear layer에 입력해 정답을 예측하는 방식으로 학습을 진행합니다.
위의 과정에서 정답을 예측하는 방식을 수식으로 나타내면 아래와 같고 부터 까지의 token으로 이루어진 시퀀스에서 가 등장할 확률은 모델의 최종 출력값 과 파라미터 의 내적에 소프트맥스 함수를 적용한 값입니다.
그리고 이를 이용해 정답 y가 등장할 확률을 최대화 시키는 것이 학습의 목적이 되고 목적 함수를 수식으로 나타내면 아래와 같습니다.
해당 논문에서는 여기서 그치지 않고 auxiliary objective를 이용하여 성능을 좀 더 향상시키는데 에 을 일정 비율만큼 더하여 를 구하여 성능을 추가로 향상시켰고 해당 수식은 아래와 같습니다.
Task-specific input transformations: 몇몇 태스크에서는 별다른 작업 없이 위의 두 단계만으로 모델을 튜닝할 수 있지만 QA나 textual entailment(두 문장의 내용이 모순되는지 알아내는 태스크) 처럼 입력 데이터의 형식이 문장의 쌍이나 문서 & 질문 & 정답의 형태 등으로 이루어진 경우 약간의 작업이 필요합니다. 해당 논문에서는 간단하게 이 데이터들을 sequence 형식으로 묶는 방식을 사용합니다. 기존에는 RNN 계열 모델을 사용하다 보니 데이터가 길어질 경우 성능이 하락하는 문제가 발생했었는데 Transformer 계열 모델의 특성상 데이터의 길이에 영향을 덜 받는다는 점 때문에 이런 방식이 가능해진 것 같습니다.
모델 상세 사항
GPT 모델은 기본적으로 Transformer 모델과 유사하지만, 인코더 없이 12개의 디코더로 이루어져 있으며 Postion-wise feed-forward network의 크기는 3,072차원입니다. 인코딩 방식은 BPE 방식을 사용하였고 활성화 함수는 GELU를 사용하였습니다.
모델 성능 실험 결과
NLI 태스크 성능 실험 결과
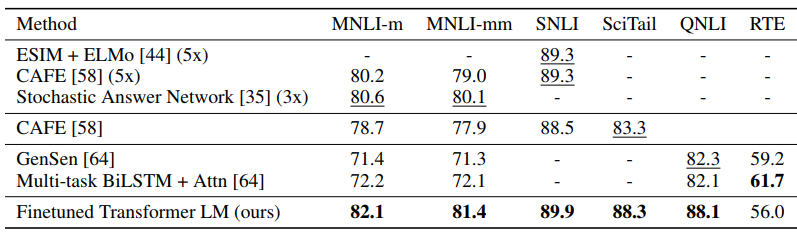
QA & 지식 기반 추리 태스크 성능 실험 결과
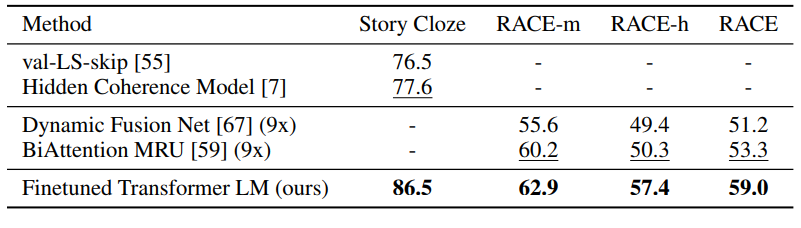
문맥 유사도 추리 & 문장 분류 태스크 성능 실험 결과
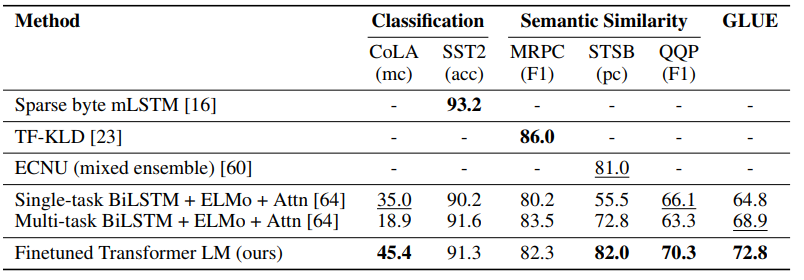
실험 결과 12개의 태스크 중 9개의 태스크에서 SOTA를 달성하였고 일부 태스크에서는 다른 모델들을 앙상블한 성능마저도 능가하였습니다.
추가 실험 결과
transfer learning에 사용된 레이어 개수에 따른 성능 변화: transfer learning의 영향을 받은 레이어의 개수에 따라 모델의 성능이 어떻게 변하는지 보기 위한 실험의 결과 아래와 같은 결과가 나왔습니다.
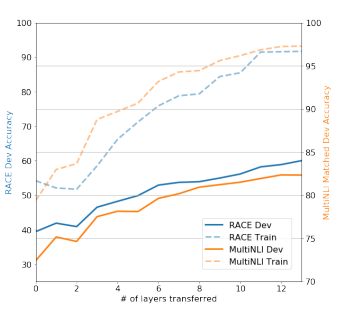
transfer learning에 사용된 레이어의 개수가 늘어날수록 성능이 우상향 되는 모습을 보여주고 이를 통해 많은 수의 레이어를 이용할수록 성능이 좋아진다는 것을 알 수 있습니다.
제로샷 모델의 성능: 해당 논문의 연구진들은 사전학습 단계에서 이미 모델이 다양한 태스크에서 어느 정도 성능을 낼 수 있을 정도로 학습이 되었을 거라 가정하고 파인 튜닝 없이 모델을 태스크에 적용해 보았습니다. 실험 결과 아래의 결과가 나왔는데, 이를 통해 일부 태스크에서는 사전 학습만으로도 꽤 좋은 성능을 낸다는 것을 볼 수 있습니다.
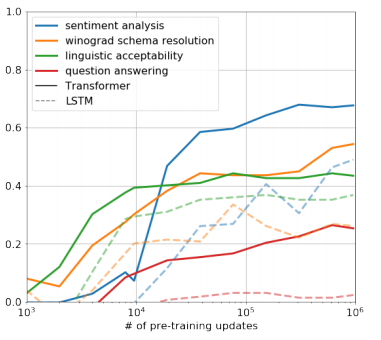
일부 요소 제외 실험 결과: 연구진들은 모델 학습의 요소가 성능에 얼마나 영향을 끼치는지 알아보기 위해 각각 사전 학습, Auxiliary object 요소를 제거하고 모델을 학습시켜 성능을 확인해 보았습니다.

위의 표에서 볼 수 있듯이 사전 학습을 진행하지 않은 모델은 성능이 굉장히 낮은 모습을 보여줬습니다.
하지만 Auxiliary object를 제거한 경우에는 일부 태스크에서 성능이 더 좋아지기도 했습니다. 마지막은 LSTM 모델의 성능을 비교용으로 활용하기 위해 가져온 것인데 GPT 모델에 비해 성능이 떨어지는 모습을 보였습니다.
결론
해당 논문에서는 Transformer 모델의 디코더를 가져와서 큰 변화 없이 사용하였는데, 대량의 데이터로 사전 학습을 진행한 것만으로도 매우 좋은 성능을 낸다는 것을 알 수 있습니다. 논문에서도 모델의 구조보다는 학습 방식에 중점을 두고 설명했는데, 연구진들도 이 논문의 핵심 주제는 대량의 데이터에서 사전 학습을 진행하는 것으로 다양한 태스크에서 상당한 성능을 낼 수 있다는 사실로 정한 것 같습니다. 따라서 이 논문의 가장 핵심적인 내용은 대량의 데이터를 사용한 사전 학습의 중요성인 것 같습니다.
후기
GPT 논문을 읽고 정리를 하면서 나름의 해석을 함께 적어보았는데 그중 제대로 된 내용이 얼마나 될지 모르겠습니다. 만약 이 글을 읽으시는 분이 계신다면 저의 해석을 적당히 무시하시고 읽으시면 좋을 것 같습니다.
