
NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE
NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE는 2014년에 발표된 논문으로 현재 NLP에서 가장 중요한 요소 중 하나인 어텐션의 시초가 되는 논문입니다. 발표된 지 10년이나 된 논문이지만 어텐션에 대해 좀 더 알아보기 위해 읽어보았습니다.
요약
해당 모델이 나오기 전에는 기계 번역 작업에서 큰 문제가 하나 있었습니다. 바로 길이가 긴 문장에서 성능이 떨어진다는 점이었습니다.
번역 작업을 모델에서 수행하기 위해서는 문장의 길이에 상관없이 고정된 길이의 벡터로 변환해야 했는데 이 때문에 긴 문장을 번역할 때 모델의 성능이 떨어질 수밖에 없었습니다.
그래서 해당 논문에서는 모델이 직접 문장에서 다음 단어를 예측하는 데 필요하다고 생각되는 부분을 찾아 이러한 문제를 어느 정도 해결할 수 있도록 하였고 영-불 번역 작업에서 그 당시 SOTA 수준의 성능을 내었습니다.
개요
기계 번역에 사용되는 모델들은 대부분 인코더와 디코더로 이루어진 모델로 인코더에서 입력 문장을 고정 길이의 vector로 변환하면 디코더에서 그를 통해 출력 문장을 생성하는 방식을 사용했습니다.
연구진들은 입력 문장을 고정된 길이로 변환하는 것이 긴 문장을 번역하는 작업에서 성능을 저하시키는 원인일 것이라고 생각을 하였고 각 출력 단어 예측 과정에서 필요한 부분을 입력 문장에서 찾아오는 방식을 적용했습니다.
이러한 방식은 문장의 길이에 상관없이 성능의 향상을 가져왔고(문장의 길이가 긴 경우에는 더 큰 성능 향상을 가져왔습니다.) 이후 수많은 모델들에 영향을 미쳤습니다.
모델의 구조
해당 모델의 구조는 인코더와 디코더 형식으로 이루어져 있고 인코더에서는 BiRNN을 사용하고 디코더에서는 번역 과정에서 어떤 단어를 해석하기 위해 필요한 부분을 찾는 Alignment를 활용하도록 하였습니다. 참고로 해당 모델은 기계 번역을 위한 모델이기 때문에 아래의 설명들은 번역 작업의 상황에서 설명된 내용들입니다.
BiRNN 인코더
보통 일반적인 RNN에서는 입력된 문장을 앞에서부터 뒤로 순서대로 처리합니다. 하지만 해당 모델에서는 문장을 순서대로 처리하는 것에서 끝나지 않고 역순으로도 처리하도록 하였습니다.
인코더에서 RNN 모델 두 개를 사용하여 하나는 문장의 순서대로, 다른 하나는 문장의 역순으로 문장을 처리하며 이 둘의 결과를 합쳐 디코더와 alignment 모델에서 활용합니다. 이를 통해서 각 단어의 의미를 해당 단어 앞의 단어들뿐만 아니라 뒤의 단어들까지도 활용하여 예측할 수 있습니다.
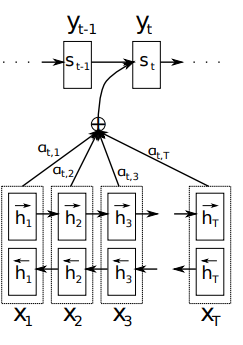 위의 그림을 통해 BiRNN 인코더 모델 구조를 간단하게 볼 수 있습니다.
위의 그림을 통해 BiRNN 인코더 모델 구조를 간단하게 볼 수 있습니다.
ALIGNMENT
ALIGNMENT는 Attention의 시초로 주어진 단어가 어떤 단어와 서로 연관이 있는지를 나타낸 것으로 해당 모델에서는 주어진 원문 단어를 어떤 단어로 해석할지에 대한 확률을 다음과 같이 정의했습니다.
문장의 처음부터 해당 위치 이전까지의 번역 결과와 현재 주어진 원문 단어가 주어졌을 때, 번역 결과로 특정 단어가 나올 확률을 라는 수식으로 표현했으며 여기서 는 input의 i번째 위치에 대한 hidden state로 아래의 수식과 같습니다.
그리고 는 어떤 단어를 해석하기 위해서 어떤 단어가 중요한지를 나타내는 변수로
와 같습니다.
이 수식에서 는 output의 i번째 자리의 단어와 input의 j번째 자리의 단어가 얼마나 연관되어 있는 지를 나타내는 변수입니다. 결과적으로 는 각 hidden state가 i번째 output과 얼마나 연관이 되어 있는지를 담고 있는 변수로 볼 수 있습니다.
이제 모든 요소들에 대해 알아보았으니 다시 함수를 들여다보면 이 함수가 직전 위치에서 나온 단어(), 해당 위치에서의 hidden state(), 해당 위치의 단어를 해석하기 위해서 주목해야 할 정보()를 종합해 결과를 산출한다는 것을 알 수 있습니다.
이러한 방식을 통해서 인코더에서 모든 정보를 고정된 길이의 vector로 압축해야 한다는 제약에서 벗어날 수 있었고 길이가 긴 문장에서도 좋은 성능을 보일 수 있게 되었습니다.
모델 성능 실험 결과
해당 모델의 성능을 알아보기 위해 연구진들은 기존의 모델(RNNenc)과 본인들이 제작한 모델(RNNsearch)을 두 가지 학습 데이터셋(30 단어 이상으로 이루어진 문장들이 포함된 데이터셋, 50 단어 이상으로 이루어진 문장들이 포함된 데이터셋)으로 학습하여 성능을 비교해 보았습니다.
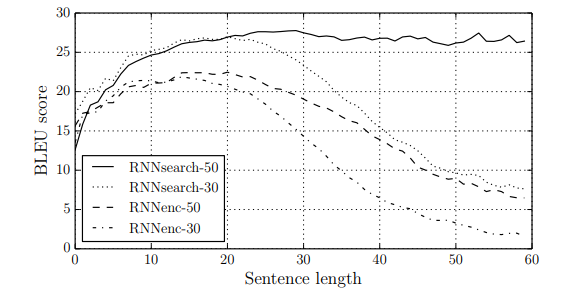
위 표를 통해서 RNNsearch가 RNNenc보다 훨씬 뛰어난 성능을 보여준다는 것을 알 수 있으며 RNNsearch-50 같은 경우에는 긴 문장에서도 성능이 떨어지지 않고 유지된다는 것을 볼 수 있습니다.
ALIGNMENT에 대한 분석
ALIGNMENT는 문장을 번역하면서 각 문장의 요소를 해석하는데 어떤 요소들이 중요한지 알려주는 메커니즘입니다. 그렇다면 모델은 어떤 식으로 그 중요성을 인지할까요? 아래 그림을 통해 모델이 단어 간의 관계를 어떻게 인지했는지 볼 수 있습니다.
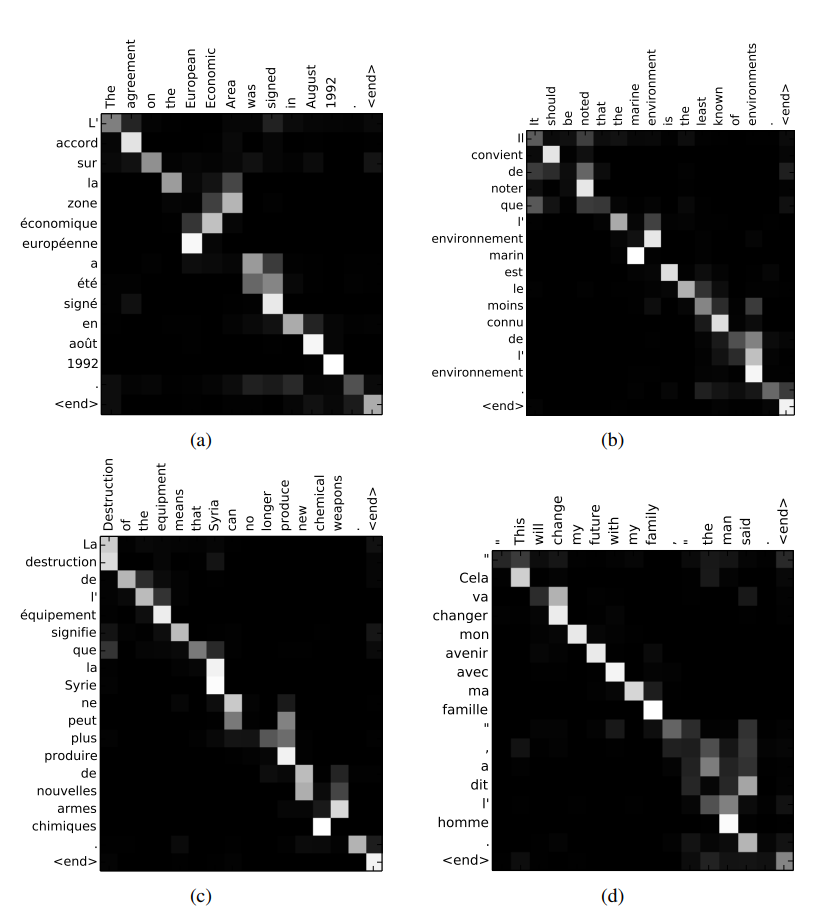
위 그림은 영어 문장과 프랑스어 문장 간의 ALIGNMENT 계산 결과를 시각화한 것으로 밝은 부분일수록 연관성이 높다는 뜻입니다.
그림을 보면 거의 대각선 방향으로 밝은 부분들이 분포하는 것을 볼 수 있는데 프랑스어와 영어의 문장 진행 방식이 비슷하기 때문에 이런 식으로 분포하는 것으로 볼 수 있습니다. 또한 중간중간 대각선을 벗어난 부분이 밝은 것을 볼 수 있는데 이는 영어와 프랑스어에서는 명사와 형용사의 위치가 반대로 오기 때문에 그렇다고 합니다.
저는 프랑스어를 모르기 때문에 자세히 알 수 없지만 연구진들에 따르면 영어 문장과 프랑스어 문장에서 각 요소 간의 관계를 잘 나타냈다고 합니다.
결론
기존에 기계 번역 작업에 활용되던 인코더-디코더 모델들의 문제점인 고정 길이 벡터 문제를 ALIGNMENT라는 메커니즘을 통해서 해결하였고 추가로 어떤 단어를 번역할 때 중요하게 고려해야 할 단어들을 모델이 알 수 있게 하는 방법으로 모델의 성능 향상을 가져올 수 있었습니다.
연구진들이 향후 주요한 과제 중 하나로 생각한 것은 자주 사용되지 않거나 정보가 부족한 단어를 처리하는 문제로 현재는 대규모 데이터를 활용한 사전 학습을 통해서 어느 정도 해결이 되었다고 생각이 됩니다.
후기
이번에는 기존 논문들에 비해서 오래된 논문을 읽어보았습니다. 그동안 Transformer 계열 논문들을 읽으면서 언젠가 한 번 어텐션에 대해서 좀 더 알아봐야겠다는 생각을 하고 있었는데 드디어 실천을 하게 되었습니다. RNN 모델에 대한 지식이 부족해서 논문 내용을 이해하는 데 어려움이 있었지만 대충 컨셉 정도만 알아보자는 생각으로 정리해 보았습니다.
해당 글에는 저의 주관적인 해석이 포함되어 있으므로 틀린 내용이 있을 경우 무시하거나 댓글로 남겨주시기 바랍니다.
