파이썬의 List 자료형
List는 파이썬에서 데이터를 순차적으로 저장하기 위해 사용하는 기본적인 자료구조로 간단히 말하면 파이썬의 배열로 아래와 같은 특징들이 있다.
1. 파이썬에서 사용하는 List는 C나 Java의 Array와는 달리 서로 다른 자료형을 하나의 List 안에 담을 수 있다. 즉 ['BF', 8, 'MR', 10, 3.5]와 같은 형태로 사용 가능하다는 것이다.
2. List는 가변 길이 자료구조이다. 즉 List는 스택이나 큐처럼 pop 연산과 append 연산도 사용이 가능하고 이덕분에 PS 풀이를 할 때에도 다른 언어에 비해 굉장히 간단하게 코드를 짤 수 있다.
3. List는 다차원 배열을 사용할 때 각 원소 배열들의 길이가 동일하지 않아도 된다. 예를 들면 [[1,2,3],['A','G'],[1.7]]처럼 각 원소 배열들의 길이가 각각 3, 2, 1로 달라도 파이썬 list에서는 문제가 되지 않는다.
이 정도만 보아도 파이썬의 List가 굉장히 간단하고 사용하기 편하다는 것을 알 수 있다. 하지만 이런 좋은 자료구조를 딥러닝에서는 사용하지 않는다. 대신 Numpy라는 라이브러리의 array를 사용하는데 이제 그 이유를 알아볼 것이다.
파이썬의 Numpy 라이브러리
Numpy는 파이썬에서 주로 행렬이나 벡터를 처리할 때 사용하는 라이브러리로 다양한 선형대수 관련 연산을 수행할 수 있으며 보통 np로 축약을 해서 사용한다. Numpy는 파이썬 라이브러리지만 내부 구현은 C와 포트란으로 되어있기 때문에 좀 더 빠른 연산이 가능하다.
Numpy의 array 자료형
Numpy의 array는 Numpy 라이브러리에서 사용하는 배열 자료구조로 딥러닝 연산에서 자주 사용된다. Numpy는 보통 np.array로 호출을 하고 파이썬의 List와는 다른 점들이 많이 존재한다.
1. np.array는 List보다는 다른 언어들의 Array와 비슷하다. np.array는 하나의 array에서 한가지 자료형만 사용이 가능하고 비가변 길이 자료구조이며 다차원 배열을 사용 시에는 모든 원소 배열의 길이가 동일해야 한다.
2. np.array는 파이썬 List에 비해 더 다양한 연산을 할 수 있다. 일례로 '+' 연산을 한 결과를 가져왔다.

위 사진에서 보이듯이 파이썬 List는 '+' 연산을 하면 두 배열을 이어 붙이지만 np.array는 각 원소의 합을 계산한다.(만약 두 np.array 배열을 이어 붙이고 싶은 경우 concatenate 연산을 사용하면 된다.)
이외에도 다차원 배열의 경우 각 원소 배열 별로 평균을 구하거나 합을 구하는 연산도 가능하고 브로드캐스팅(모든 원소에 각각 특정 연산을 수행) 연산도 지원을 한다.
3. Numpy에서는 연산 작업을 여러 개의 프로세스로 나누어서 병렬 연산을 수행한다고 한다.
4. np.array는 메모리에 저장될 때 연속된 공간에 저장이 되지만 파이썬 List는 그것이 보장되지 않는다고 한다. 위에서 언급한 특성들과 이 특성으로 인해 np.array에서의 연산이 파이썬 List의 연산보다 빠르게 수행된다고 한다.
이렇게 np.array와 List의 차이를 대략적으로 알아보았고 이제 두 자료구조의 연산속도를 비교해 볼 것이다.
np.array와 List의 연산 속도 차이
np.array와 List의 성능을 비교해 보기 위해 모든 원소에 1을 더해주는 연산을 하고 그 시간을 측정해 보았다. 이때 List는 for문을 이용하였고 np.array는 브로드캐스팅 연산을 이용하였다.
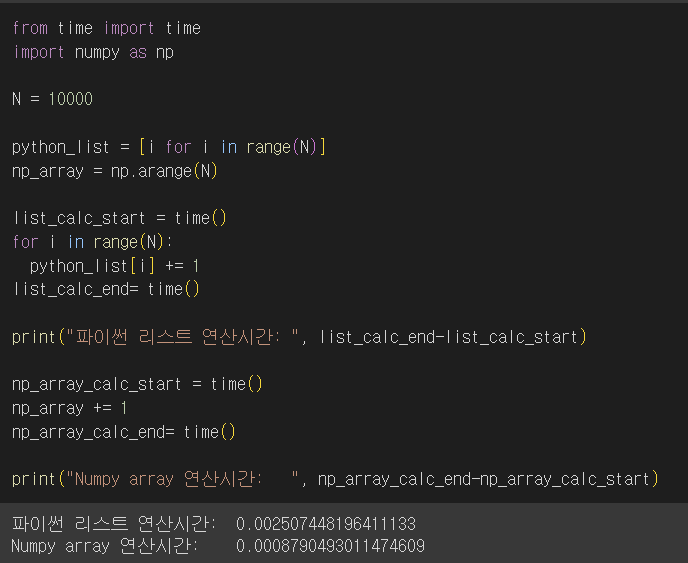 원소의 개수가 10,000개일 때는 np.array가 약 3배 정도의 빠른 시간에 연산을 완료했다.
원소의 개수가 10,000개일 때는 np.array가 약 3배 정도의 빠른 시간에 연산을 완료했다.
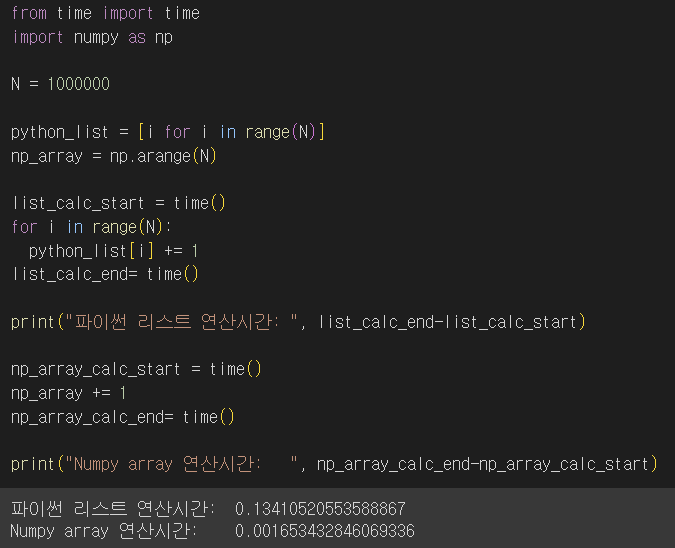 원소의 개수를 100만 개로 늘리자 연산 시간의 차이가 약 80배가 넘는 차이로 벌어졌다.
원소의 개수를 100만 개로 늘리자 연산 시간의 차이가 약 80배가 넘는 차이로 벌어졌다.
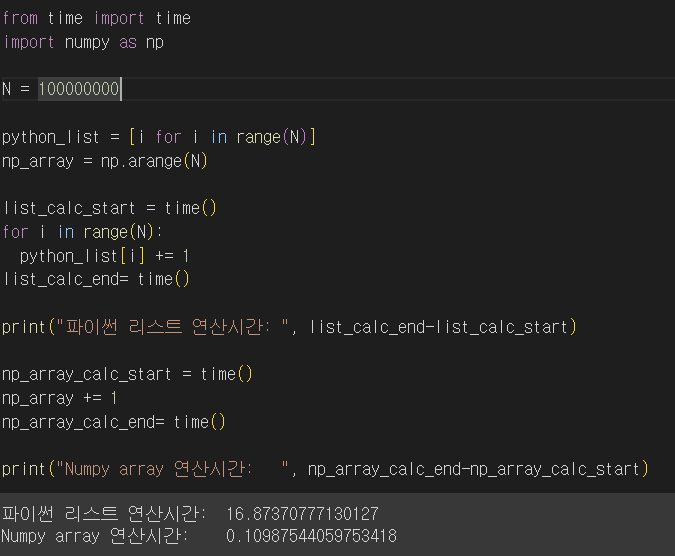 원소의 개수를 1억 개까지 늘리자 연산 시간이 160배가 넘게 벌어지면서 N이 크면 클수록 차이가 크게 벌어졌다.
원소의 개수를 1억 개까지 늘리자 연산 시간이 160배가 넘게 벌어지면서 N이 크면 클수록 차이가 크게 벌어졌다.
결론
이렇게 두 자료구조의 특성과 연산 속도를 비교해 보았다. 연산 속도 비교의 결과로 처리해야 할 연산의 양이 많을수록 np.array와 List의 성능 차이가 크게 벌어진다는 것을 볼 수 있었다. 딥러닝 수행 과정에서는 보통 굉장히 많은 연산을 필요로 하기때문에 List보다는 np.array가 더 좋은 성능을 보일 것이므로 딥러닝에서는 List보다는 np.array를 활용하는 것이 맞는 것 같다.
