파이썬에서 변수를 저장하는 방식에 대해 알아보자
파이썬에서는 변수를 어떻게 저장할까? 그냥 변수를 선언하면 메모리에 해당 변수만큼의 공간을 차지하고 거기에 그 값을 넣어놓을까?
C나 Java에서는 위 설명이 맞겠지만, 파이썬에서는 다르다.
파이썬에서는 변수에 값을 대입해도, 실제로 해당 변수가 그 값을 갖고 있지는 않다. 대신 값 자체가 아닌 객체를 가리키는 주소 값이 들어있다. 쉽게 말해 변수는 실제 값을 가지고 있는 객체를 참조한다고 볼 수 있다.
조금 더 자세히 설명해 보겠다. 파이썬에서는 변수를 namespace라는 딕셔너리(정확히는 PyDictObject) 형태의 자료구조에서 관리하는데, 변수 선언 시 key-value 형식으로 변수명과 해당 변수에 들어있는 값이 있는 메모리를 가리키는 주소 값을 저장한다.
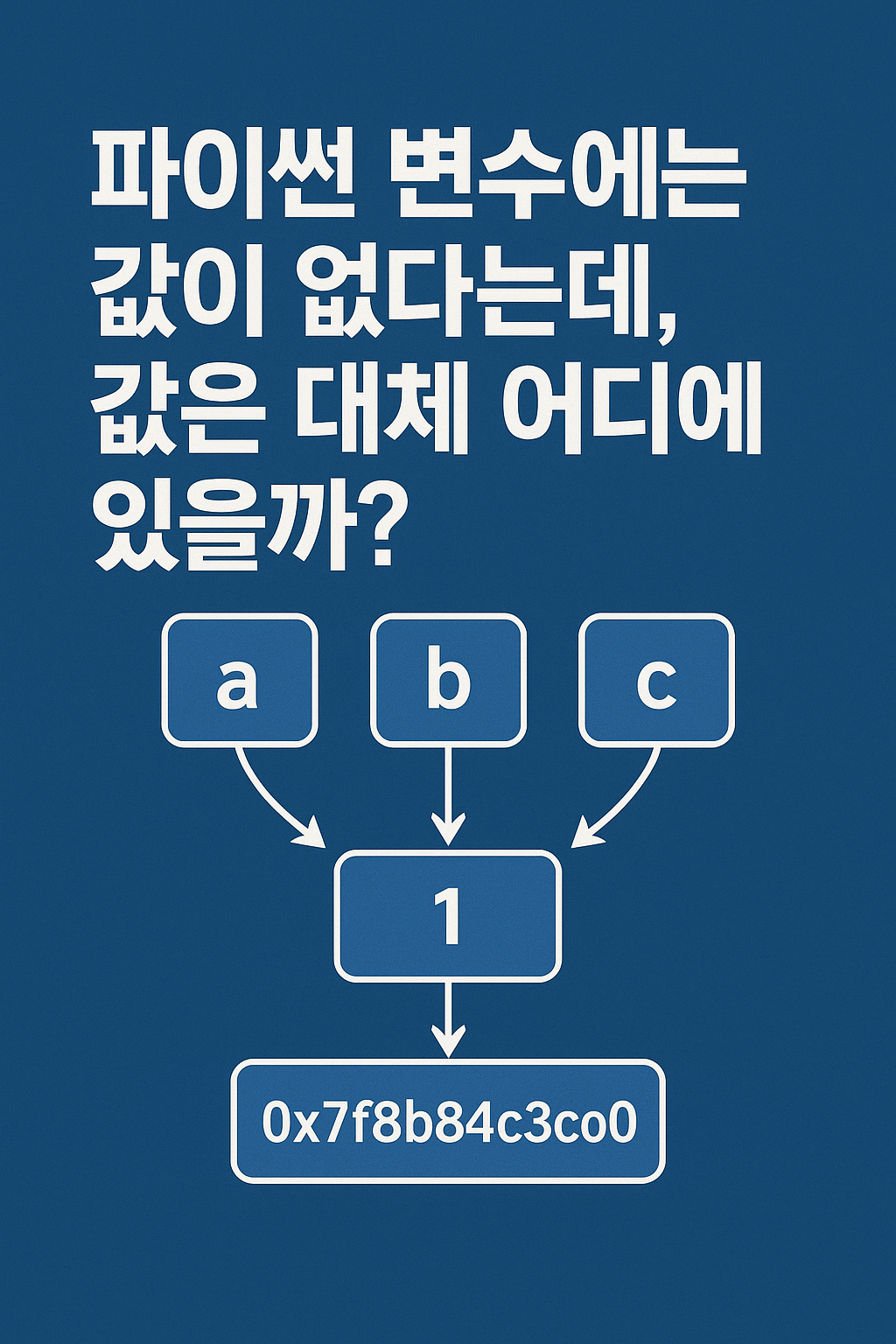
예를 들자면 N=1이라고 했을 때, 메모리상에서 1이 0x7f8b84c3c0a0라는 곳에 저장되어 있다면 namespace에 {key:N, value: 0x7f8b84c3c0a0}라는 값이 들어있는 것이다.
아래는 a라는 변수와 b라는 변수에는 1을 대입하고, c라는 변수에는 2를 대입하였을 때, 각 변수들이 가리키는 객체의 메모리상 주소이다.
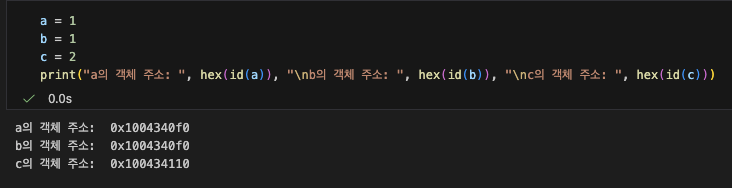
1을 대입한 a와 b는 같은 객체를, 2를 대입한 c는 홀로 다른 객체를 가리키고 있다.
(단 함수 내부에서 선언된 로컬 변수는 함수 호출 시 생성된 객체 내부에서 따로 관리되므로 위와 다를 수 있다.)
파이썬에서 변수는 객체를 가리키는 주소 값을 저장하는 공간이고, 객체는 실제 값을 저장하는 공간이다.
변수는 아까 말했듯이 namespace(로컬 변수의 경우는 localfast라는 별도의 공간)에 저장이 되고 객체는 heap에 저장이 된다.
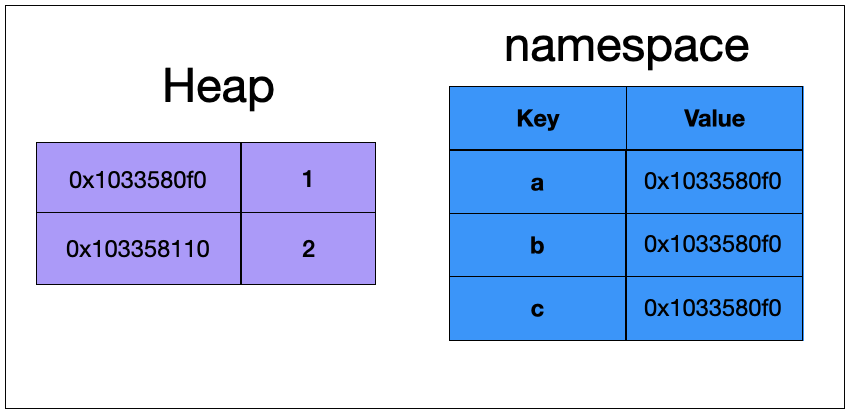
그림으로 간략하게 표현하면 위처럼 볼 수 있는데 Heap에서는 실제 값을 가지고 있고, namespace는 Key(변수명), Value(실제 객체 주소) 형태로 값을 가지고 있다.
리스트를 저장하는 방식에 대해서도 알아보자
그렇다면 리스트는 메모리에 어떻게 저장될까?
변수와 동일한 방식으로 저장이 된다. 애초에 리스트도 변수의 일종이므로 당연하다.
하지만 다른 점도 있다.
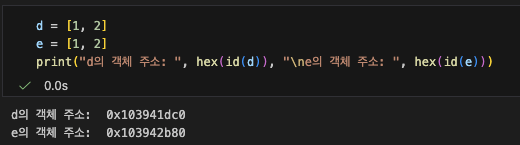
위는 같은 값을 가지는 두 리스트의 객체 주소이다. 그런데 이번에는 두 리스트의 객체 주소가 다르다.
왜 이렇게 된 것일까? 파이썬에서는 가변 객체와 불변 객체를 구분한다. 가변 객체(list, dict 등)는 선언 시마다 새로운 객체를 생성하고, 불변 객체(int, str, tuple 등)는 기존 객체를 재사용한다.(다만 불변 객체도 상황에 따라 새로운 객체를 생성하는 경우가 존재)
따라서 리스트 d와 e는 각기 다른 객체이기 때문에 다른 객체 주소를 가지는 것이다.
리스트의 원소들을 저장하는 방식도 알아보자
그렇다면 리스트의 각 원소들은 어떻게 저장이 될까?
파이썬에서 리스트는 내부적으로 C 포인터 배열을 사용하고 해당 배열의 원소는 객체를 가리키는 포인터이다. 따라서 namespace에 key:value형태로 저장하는 대신 배열에 저장하는 것이다. 그 이외에는 기존과 동일하다. 만약 해당 원소가 불변 개체일 경우 기존 객체를 사용하고 가변 객체일 경우 새로운 객체를 생성하고 그 주소를 저장하는 것이다.

위의 결과를 보면 알겠지만, 불변 객체인 int형은 하나의 객체를 공유하지만, 가변 객체인 list는 각각의 객체를 가진다.
또한 변수 선언 부분을 보면 1을 가리키는 a와 b라는 변수가 리스트 f의 1번, 2번 원소와 같은 객체를 공유하고 있다는 것을 알 수 있을 것이다.
따라서 파이썬에서는 리스트 내부의 원소들도 각각 하나의 변수로 바라보고 다른 변수들과 같은 관점에서 관리한다는 것을 알 수 있다.
다차원 리스트, 읽는 순서에 따라 성능이 다르다?
다차원 리스트를 순회할 때, 순회 순서는 연산 속도에 얼마나 영향을 미칠까?
파이썬에서 다차원 리스트는 리스트 안의 원소가 리스트인 경우로, 원소가 되는 리스트는 하나의 객체로 저장된다고 하였다.
그렇다면 이번에는 2차원 리스트에서 행 기준, 열 기준으로 리스트를 순회할 때 연산 속도에 어느 정도 차이가 있는지 알아보겠다.
왼쪽은 행 기준, 오른쪽은 열 기준으로 순회를 한 결과로 각각 10번씩 순회하여 평균 실행 시간을 구하였다.
아래 결과는 크기의 리스트를 순회할 때의 연산 속도 차이이다.
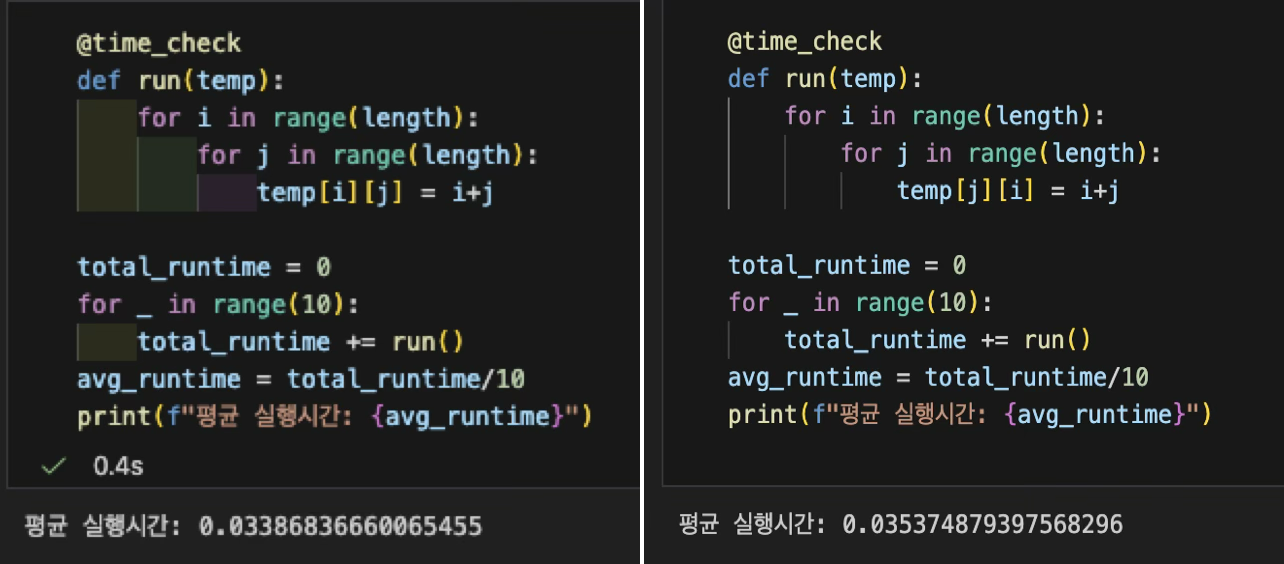
행 기준 순회가 조금 더 빠르지만 차이가 크지는 않다.
아래 결과는 크기의 리스트를 순회할 때의 연산 속도 차이이다.
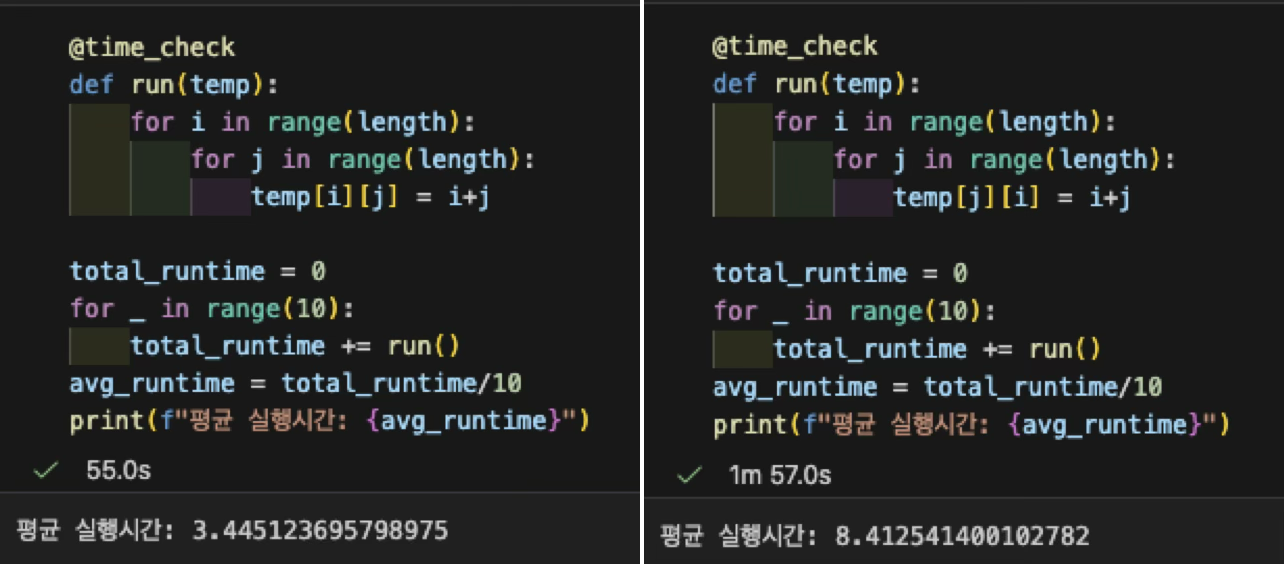
이번에는 약 5초의 차이가 발생했다.
위 실험 결과를 통해, 행 기준 순회가 열 기준 순회에 비해 빠르다는 것을 알 수 있는데, 이는 CPU 캐시의 공간 지역성(spatial locality) 때문이다. CPU는 메모리를 읽을 때 해당 주소만 불러오는 것이 아니라, 그 주변 구간까지 함께 가져온다. 이후 연산에서 이때 가져온 메모리를 접근하게 되면 캐시에서 이미 가져온 값을 읽을 수 있게 되며, 이를 공간 지역성이라고 한다.
그렇다면 이 공간 지역성이라는 것이 왜 이번 실험에 영향을 미쳤는지 알아보겠다.
앞서 파이썬 리스트는 내부적으로 객체 주소들을 원소로 하는 C 포인터 배열을 사용한다고 하였다. 같은 리스트 객체의 원소(정확히는 해당 원소를 가리키는 포인터)들은 메모리에서 인접한 위치에 있다는 것이다.
행 기준으로 순회를 할 때는 하나의 내부 리스트 객체 안에 존재하는 포인터 배열을 순차적으로 순회하는데, 인접한 메모리 구역을 계속해서 접근하기 때문에 캐시 히트율이 높아진다.
하지만 열 기준으로 순회를 할 때는, 매번 다른 리스트 객체의 C 포인터 배열에 접근을 해야한다. 그렇기 때문에 접근해야하는 메모리 구역이 인접하다는 것이 보장되지 않으므로 캐시 미스가 증가하게 된다.
이런 이유로 인해 연산 속도에 차이가 발생하게 되는 것이다.
그냥 궁금해서 알아봤습니다
이렇게 파이썬이 변수를 메모리상에서 어떻게 관리하는지 알아봤다. 그동안 파이썬 변수는 객체를 참조한다는 것 정도는 알고 있었는데, 이 글을 작성하기 위해 공부를 하다 보니 내가 잘못 알고 있던 내용들도 많다는 것을 깨달았다. 모호하게 알던 것들에 대해서 좀 더 자세히 알게 되었고, 몰랐던 것들도 많이 알게 되었다.
리스트 순회 순서에 따라 생각보다 큰 성능 차이가 난다는 것을 보고 기본기의 중요성을 많이 체감했다. 앞으로는 이런 식으로 좀 더 깊은 내용에 대해 공부를 해보아야겠다. 또 공부에 그치지 않고 이를 실무에 적용할 방법도 생각해 보면 좋을 것 같다.
ps. 해당 글에 잘못된 내용이 있을 수도 있으니 감안하여 주시기 바랍니다. 또 발견하시면 피드백 주시면 감사하겠습니다!
