
파이썬의 여러 자료구조
파이썬에는 여러 자료구조가 있다. 대표적으로 가장 많이 사용하는 List, Dict부터 이보다는 덜 쓰이지만 그래도 자주 쓰이는 Set과 Tuple 등도 있다.
List는 여러 데이터를 순서를 유지한 채 선형적으로 모아놓을 때, Dict는 해시맵 구조로 Key:Value 구조로 데이터를 관리해야 할 때, Set은 중복을 허용하지 않고 순서가 상관 없는 값들을 저장할 때 쓴다. 그리고 Tuple도 여러 데이터를 순서를 유지한 채 선형적으로 모아놓을 때 사용한다.
위 설명을 보고 의문점이 하나 생길 것이다. List와 Tuple 모두 순서성을 가지는 데이터들을 저장해놓는 선형 자료구조라면 왜 각각 따로 존재할까?
이번 글에서는 비슷하지만, 다른 List와 Tuple에 대해 알아보겠다.
List와 Tuple에 대해 좀 더 알아보자
그렇다면 이번에는 여러 자료구조들 중 List와 Tuple에 대해 자세히 알아보겠다.
List와 Tuple의 공통점
가장 먼저 선언하는 방식에 대해 알아보자.
선언의 경우 아래와 같이 해당 자료구조 안에 포함시킬 값을 넣고 선언해 주면 된다.
이때, List는 []로 Tuple은 ()로 값을 감싸주는 것 말고는 선언 방식은 동일하다.
이번에는 값을 가져오는 방식을 보자.
아래와 같이 List와 Tuple 모두 인덱스를 통해 값들을 순회할 수 있다.
기본적으로 순서성을 유지한 채, 선형적으로 관리되는 자료구조라는 점에서 둘이 유사하다는 것을 알 수 있다.
List와 Tuple의 차이점
위에서 둘의 공통점에 대해 알아보았으니, 이번에는 차이점에 대해 알아보겠다.
일단 가장 큰 특징은 List는 가변이지만, Tuple은 불변이라는 점이다.
아래 코드는 List와 Tuple에 각각 새로운 원소를 추가하는 과정이다.
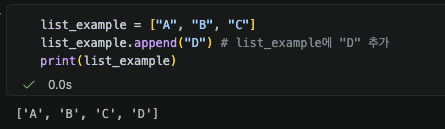
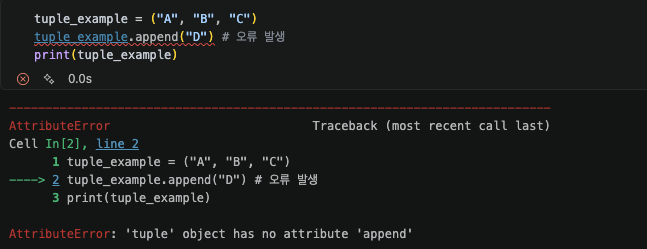
List는 append를 통해 원소를 추가할 수 있지만, Tuple은 append라는 메서드 자체가 없어 오류가 발생한다. Tuple은 add 같은 다른 명칭으로 존재하지 않는가 생각할 수 있지만, Tuple은 List의 append에 해당하는 메서드 자체가 존재하지 않는다.
List는 객체가 생성된 이후에도 원소를 추가하거나 제거할 수 있지만, Tuple은 한 번 객체가 생성되고 나면 그런 행위가 불가능하다.
이번에는 기존 원소에 들어있는 값을 바꿔보겠다.
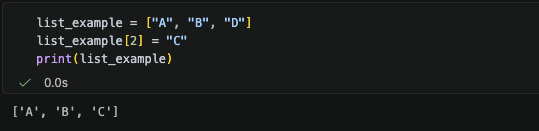
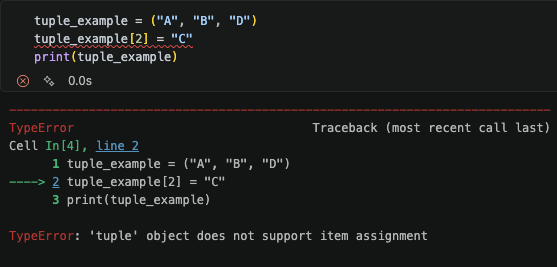
List에서는 기존 원소에 들어있는 값에 새로운 값을 대입하여, 내용을 수정할 수 있다. 하지만 Tuple의 경우에는 'tuple' object does not support item assignment라는 오류를 반환한다.
위의 결과에서 List와 달리 Tuple은 한 번 생성하고 나면 수정할 수 없다는 것을 보았다.
그렇다면 좀 더 깊이 들어가서 Python에서 두 자료구조의 관리 방식의 차이를 알아보겠다.
이 부분은 아래에서 좀 더 자세히 알아보자.
Python에서는 Tuple과 List를 어떻게 관리할까?
그렇다면 이번에는 Python에서 두 자료구조를 어떻게 관리하는 지 알아보겠다. 그리고 관리 방식에 따라 어떤 차이가 발생하는 지에 대해서도 알아보겠다.
위에서 List는 가변, Tuple은 불변이라고 하였다.
이에 따라 두 자료구조를 관리하는 방식에는 많은 차이가 존재한다.
객체 생성 과정의 차이
List는 객체를 생성한 이후에도 변경이 될 수 있다. 그런데 List에 담긴 값이 변경될 때마다, 매번 새롭게 메모리 공간을 할당받아야 한다면 성능이 저하될 것이다. 따라서 객체 선언 과정에서 미리 여유 공간을 할당해 놓는다.
CPython에서는 아래 수식에 따라 List의 메모리 크기를 산정한다.
(비트 연산에서 오른쪽으로 3칸 shift하면 기존값의 (=%)이 되므로 은 의 12.5%가 된다.)
수식을 해석해보면 객체 선언에 사용할 메모리의 공간()은 실제 필요한 메모리() + 여유 메모리 공간() + 버퍼 크기(가 9이하일 경우 3, 이상일 경우 6)의 총합이다.
예를 들어 필요한 메모리가 80이라면 이므로 이 된다.
이번에는 Tuple의 생성 방식에 대해 알아보자. Tuple은 List와 달리 객체를 생성한 이후에 변경이 불가능하다. 따라서 필요한 메모리만을 확보해 놓으면 된다.
따라서 Tuple은 같은 값을 저장하더라도 List에 비해 메모리를 덜 사용하게 된다.
아래는 같은 값을 저장하고 있는 List와 Tuple의 메모리 크기이다.
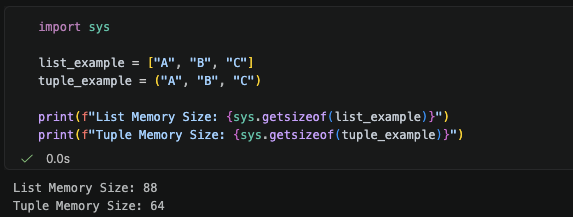
둘 다 똑같이 A, B, C라는 원소를 저장하고 있지만 List는 88 bytes, Tuple은 64 bytes를 차지한다.
Python의 List와 Tuple은 원소가 차지하는 메모리 이외에도 객체 관리를 위해 필요한 추가 메모리가 필요하므로, 위에서 본 수식과 완전히 동일하지는 않지만 List가 Tuple보다 더 많은 메모리를 차지한다는 것은 알 수 있다.
메모리 배치의 차이
두 자료구조가 메모리상에서 어떻게 배치되는지 알아보기 전에 하나 알아야 할 것이 있다.
파이썬에서 List와 Tuple은 기본적으로 원소의 값을 직접 가지고 있지 않는다. 대신 해당 원소를 가리키는 포인터들을 가지고 있다.
이 부분에 대해서는 이 글을 한 번 참고해 봐도 좋을 것 같다.
그렇다면 이제 두 자료구조의 메모리상에서의 배치에 대해 어떤 영향을 미치는지 알아보겠다.
먼저 List는 계속해서 변경이 가능하다. 그리고 변경에 대비하여 미리 메모리상의 여유 공간을 확보해 놓는다.
그런데 만약 그 여유 공간마저도 부족해서 추가 공간이 필요해지면 어떻게 될까?
메모리 재할당이 발생하고, 이 경우 List 객체의 주소는 변경되지 않지만, List 객체가 가리키는 포인터 배열의 주소는 변경된다.
이런 경우에 대비해서 List 객체는 포인터 배열의 주소를 따로 보관하고 있다. 객체와 포인터 배열은 별개의 위치에 존재하는 것이다.
하지만 Tuple은 변경될 일이 없으므로 이런 문제가 발생할 수 없다. 따라서 Tuple은 객체에서 각 원소들을 가리키는 포인터 배열을 가지고 있다.
예시를 들어보자면 아래와 같은 것이다.
List(포인터 배열의 주소를 따로 보관)
[ 헤더 | 포인터 배열 주소 ]...[ 포인터1 | 포인터2 | 포인터3 ]
Tuple(포인터 배열 자체가 연속된 메모리상에 존재)
[ 헤더 | 포인터1 | 포인터2 | 포인터3 ]따라서 List는 원소 접근 시, 객체에 접근 후 포인터 배열 주소를 통해 포인터 배열의 위치를 찾고 그곳에 접근해야 한다.
하지만 Tuple은 객체와 접근 후 필요한 포인터로 바로 접근할 수 있다.
이런 메모리 구조의 차이로 인해 캐시의 공간 지역성 측면에서 Tuple이 List보다 미세하게 효율적으로 동작할 수 있다.
아래는 1부터 10000까지의 정수를 원소로 가지는 List와 Tuple을 각각 10000번씩 순회한 결과이다.
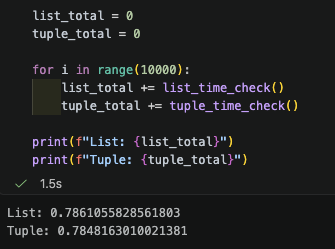
List는 약 0.7861초, Tuple은 약 0.7848초로 미세하게 Tuple이 더 빠른 것을 알 수 있다. 물론 동작 환경이나 다른 요소들에 의해 결과가 달라질 수 있겠지만 이렇게 실험을 통해 위 차이를 확인해 보았다.
그럼, List랑 Tuple는 어떤 상황에 쓰나요?
지금까지 List와 Tuple의 공통점과 차이점에 대해서 알아보았다.
그렇다면 List와 Tuple은 각각 어떤 때 써야 할까? 무조건 메모리를 덜 차지하고, 접근 속도가 빠른 Tuple의 사용을 늘려야할까?
작은 차이로도 PASS/FAIL이 나뉘기도 하고, 연산 속도나 메모리 사용량도 순위에 영향을 주는 PS 대회 같은 곳에서는 List 대신 Tuple을 써야 할 것이다. (사실 PS 준비를 할 정도라면 반드시 C++을 쓰겠지만)
그런데 PS가 아닌 개발이라면 얘기가 다를 것이다. 만약 정말 메모리와 연산 속도가 중요한 서비스를 개발한다면 성능상의 이점을 위해 Tuple을 쓰기도 하겠지만, 일반적인 개발 환경이라면 이 두 자료구조의 특성으로 인한 성능 차이가 발생할 일은 많지 않을 것이다.
사실 언제 어떤 것을 써야 한다가 정확히 정해져 있지는 않지만 내가 알기로는 일반적으로 데이터의 변경 가능성에 따라 다르다고 알고 있다.
위에서 List는 가변적이지만 Tuple은 불변이라고 하였는데 이에 따라 연산 과정에서 데이터가 바뀌어도 되는 경우 List로 바뀌어선 안 되는 경우는 Tuple로 정의하는 것이다.
user_id_and_name = ("Faker", "이상혁") # ID-유저명 매칭은 변경 불가로 튜플 자료형 사용
user_group = ["Faker"] # 유저 그룹은 유저 추가 or 삭제가 가능하니 리스트 자료형 사용위처럼 데이터의 특성에 따라 그에 맞는 자료형을 사용하는 것이다. Tuple을 사용한 경우, 해당 데이터는 변경해서는 안 된다는 것을 나타내고, List를 사용한 경우, 추후 해당 데이터의 변경 가능성을 열어놓는 것이다.
또 자료를 모아놓은 기준에 따라서도 차이를 둘 수 있다.
user_id_list = ["Doran", "Oner", "Faker", "Peyz", "Keria"] # 동일한 타입의 데이터가 가변적으로 늘어날 때
user_info = ("Doran", "최현준", "TOP") # 서로 다른 타입의 데이터가 모여 하나의 정보를 형성할 때위처럼 동일한 타입의 데이터들을 나열하고 그것이 상황에 따라 바뀔 수 있을 때는 List를 사용하고 서로 다른 타입의 데이터들이 하나로 묶여서 사용될 때는 Tuple을 사용한다.
이 외에도 Tuple은 Dictionary의 key나 Set의 원소로도 사용 가능(만약 Tuple의 원소로 List가 들어있으면 불가능)하지만 List는 불가능하다는 특성에 따라 필요한 연산에 맞춰 자료형을 사용할 수도 있다.
이 부분은 Tuple은 hashable하고 List는 unhashable하다는 특성으로 인한 차이인데, 이 부분은 추후 Dictionary나 Set에 대한 글을 작성한다면 그때 다뤄보겠다.
내가 언급한 내용 이외에도 Tuple과 List에는 많은 차이가 있고, 그에 따른 사용 시점에 대한 판단 기준도 존재할 것이다. 일단 내가 아는 것은 대충 여기까지이다.
위에서도 말했다시피 자료구조를 활용하는데 정답은 없다. 그냥 본인이 판단하여 상황에 맞는 자료구조를 사용하면 된다. 그런데 그런 판단 기준을 갖추기 위해서는 자신이 사용할 수 있는 자료구조들의 특성에 대한 이해가 필요하다. 단순히 데이터의 삽입, 삭제나 조회 방식뿐만이 아니라 메모리상에서 어떻게 관리를 하고 해당 자료구조를 사용할 때 어떤 연산 과정을 거치는지 알면 좀 더 좋은 판단을 하는 데 도움이 될 것이다.
