
📍 용어정리
✔︎ CPU burst
: CPU 연산이 실행되는 시간
✔︎ I/O burst
: I/O 연산이 실행되는 시간
➠ 모든 process는 이 두개가 반복
➠ CPU가 먼저 시작, 끝날 때도 CPU로 끝남
★ 짧은 CPU burst가 짧게, 자주 일어나는 ➠ I/O bound Job
★ CPU burst가 길게 이어지는 ➠ CPU bound Job
Ready queue 형태 (ready queue를 어떻게 구현할것인가)
- FIFO queue
- priority queue (ex. 사용자 등급을 결정해서 사용자 등급이 높은 순서대로 처리)
- tree
- unordered list → linked list (수시로 일어나고 크기의 제한이 없을 때)
이런 종류가 있다 정도로만 기억하기 ~
📍 CPU scheduling의 결정 시점 (4가지)
✅ CPU scheduling은 무엇을 관리하는 것인가?
: CPU schdeuling = short term scheduling 이기 때문에, ready, run, wait, terminate의 4단계의 전환이 일어나는 경우를 관리해야 하는 것.
1. running → waiting 상태
상황
- I/O 연산을 만나거나 어떤 상황을 기다릴 때
2. running → ready
상황
- interrupt 발생
- time sharing에서 time slice(=시간 주기) 종료
- 대부분 interrupt나 time sharing
- CPU를 양도 할 것이냐 말 것이냐에 따라 non-preemptive/preemptive가 갈림
3. waiting → ready
상황
- I/O 완료
4. process 종료
-
주로 3번은 선택적으로 일어남
-
1,2,4에 의해 preemptive
-
1,4에 의해서만 scheduling 되는 방식 = non-preemptive
- 분명히 종료되어야 하는 시점은 확실함.
-
여러개의 process (ready queue에 있는)가 있을 때 어떻게 scheduling해줄것인가?
📍 non-preemptive (리소스 선정 방식)
📍 preemptive scheduling
: 리소스(CPU)를 중간에 양도할 수 있는 방식
✔︎ preemptive: 어떤 리소스를 다 끝내지 않았더라도 어떤 정책으로 양보할 수 있는 것
- time sharing system에 적용
- data consistancy(일관성) 유지를 위한 cost 필요 → synchronizatin과 연결지어보기
- b/c. 논리적이 아니라 물리적으로 멈추게 됨
- kernel data의 inconsitency 방지 대책 필요
- critical section: 끝날때까지 방해하지 못하도록
- kernel이 한 process를 위한 자료를 변경하고 있음 → 이 와중에 process가 선택 됨 → 읽고 쓸 때 data는 결정되지 않은 data가 됨 → 이것에 대한 대책이 필요
- data 변경 중 time sharing으로 바뀌어버리면 문제가 발생
- real time system에 부적합하다
- b/c. real time이라는 게 반응성이 좋아야 하기 때문
- 종료 시점이 중요
✔︎ dispatcher: ready 상태에서 running 상태로 전환하는 과정 (-er니까 바꿔주는 애)
- ready → running으로 넘어가는 과정은, CPU의 결정사항이 아님. dispatcher이 해줌.
- dispatcher latency: dispatching에 필요한 잠복시간 (전환시간)
- context switching 하는 시간
- user mode로 전환
- context switching이 끝나면 mode 바꿔서
- 수행위치로 jump
- process state에서 process를 ready→running 상태로 바꿔주는 것
- CPU scheduler가 선택한 process에게 CPU 제어권을 넘겨주는.
⊕ os의 모든 작업은 kernel mode에서 이루어짐.
☑︎ context switching
: 저장하고 나서, 새로운 Process의 시작을 Load하는 과정
📍 scheduling criteria
: 스케줄링의 척도 → 무엇을 잘하기 위해서?, 무엇을 개선 시키기 위해서? 를 고려.
✅ maximize
1. CPU utilization
- CPU를 놀지 않게 하기 위해서
2. throughput
: 처리량
- 일정 시간동안 완료된 process 수
- 정해진 시간동안 작업 많이 하자 !
✅ minimize
1. turn around type (총 처리시간)
- submission(도착 시점) ~ completion = 도착해서 프로그램이 완전히 끝날때까지 걸리는 시간.
- 모든 waiting time 포함
2. waiting time (대기시간)
: 수행할 수 있음에도 기다리는 시간
- 알고리즘에 의해 좌우될 수 있는 시간 (CPU scheduling algo.가 여러 개 있었음)
- ex. 내 차례가 안 와서 ready queue(→ CPU만 주면 수행할 수 있음)에서 기다리는 시간
3. response time (응답시간)
: 반응시간
- submission ~ first response time
- interactive system, real time system 등에서 중요
- interactive system: time sharing을 써야하는 이유
❉ CPU scheduling은 ready queue에서 대기하는 시간에만 영향을 미침.
📍 optimize
: 최적화하는 기준점을 어떻게 할 것인지에 따라 달라짐.
- average measure
- 보통, 평균 waiting time을 줄이는 방향으로 감.
- minimum measure
- maximum measure
: 상황에 따라 best는 달라진다.
❗️ 목표: average waiting time minimum
1. FCFS (first come first survice)
- non-preemptive scheduling
- 종료나 I/O 등에 의해서만 scheduling
- 단점
- convoy(=호위) effect
- 짧은 burst를 갖는 여러 개의 process가 한 개의 큰 burst의 수행 종료를 기다리는 현상 (내 앞에 큰 burst를 기다려야 함)
- CPU burtst time이 긴 process가 먼저 들어와서 그 뒤에 들어온 CPU burst time이 짧은 process들이 기다려야 함.
- 평균 waiting time이 길어짐
- convoy(=호위) effect
→ 평균 waiting time이 길어지는 것을 막고자 SJF가 나옴
2. SJF (Shortest Job First)
- convoy effect를 줄이기 위해 등장한 개념 → FCFS의 단점을 해결하기 위해 등장한 개념
- non-preemptive (시작하면 끝날때까지 놓지 X)
- 따라서, 예측값으로 scheduling을 함.
- average waiting time 감소 (이론상)
- 구현상의 어려움 있음.
- 정확한 next CPU burst를 알 수 없음 → 그래서 average waiting time이 감소하는 것을 실제로 측정하기 어려움.
- 정확한 next CPU burst는 실행을 시켜봐야 정확하게 알 수 있음.
- 그래서 이것을 예측(추정)함.
- 이전 burst의 exponential average
- tn : n-th burst → 측정값 (이전 측정값)
- τn : n-th 예측값 (이전 예측값)
- τn+1 : 𝛂*tn + (1-𝛂)τn (다음 예측값, 실제 측정값이 민감하게 변해도 예측값은 부드럽게 변함)
- 𝛂 = weight (가중치, 어느정도 반영할 것인지)
- 이전 burst의 exponential average
- 정확한 next CPU burst를 알 수 없음 → 그래서 average waiting time이 감소하는 것을 실제로 측정하기 어려움.
- 장점
- 평균 waiting time 감소
- 단점
- CPU burst time이 긴 아이들의 수행시점을 보장할 수 없기 때문에 starvation이 발생할 수 있음.
- 긴 CPU burst time을 정확히 알기 어려움 (알고리듬 상의 문제점)
- 언제 수행을 할 지 보장을 할 수 없음.
- 구현상 어려움 (알고리듬 상의 문제점)
→ SJF의 CPU burst를 계산하기 어려운 문제점을 해결하기 위해 preemptive SJF 등장
2-1. preemptive SJF = SRT
- 남은 CPU burst time을 기준으로 수행을 하겠다.
- SRT(shortest remaining time First) : 수행중일 때 남은 burst time을 비교해서 새로 들어온 애를 잡을 것인가 나를 계속 할 것인가를 판단.
- arrive time 있음
- SJF보다 빠르다. 단, context switching overhead = 0인 경우에 해당
- average waiting time이 줄어듦. (이론상)
- context switching overhead가 발생할 수 있기 때문에 위의 조건이 붙게 됨.
- 알고리듬 상 문제점
- context switching overhead가 발생 시간이 0이라는 가정이 있어야 알고리듬이 성립 됨.\
- 중간에 놓아준다 = context switching하게 되는 것
📍 Priority scheduling
: 우선순위에 따른 scheduling
- 같은 우선 순위면 먼저 온 거 먼저 수행!
- highest priority process에 CPU 할당
- equal priority process인 경우 → FCFS
- SJF도 일종의 priority scheduling이라고 볼 수 있다.
- 단점
- 우선순위가 낮으면 경쟁에서 밀려서 수행 보장 X (계속 기다려야 함)
- indefinite blocking (무한대로 blocking)
- starvation : 우선 순위가 낮은 process의 scheduling을 보장하지 못함
- 개선방안
- aging : waiting time에 따라 점차 priority를 증가시킴
- starvation을 해결하기 위한 방법
- aging : waiting time에 따라 점차 priority를 증가시킴
- 우선순위가 낮으면 경쟁에서 밀려서 수행 보장 X (계속 기다려야 함)
📍 Round-Robin (RR) scheduling
: 시간 간격을 짧은 주기로 나눠 번갈아 수행
- espectially for time sharing system (time sharin에 적합)
- FCFS + preemption (먼저 들어온 거 먼저 수행하는데 일정 시간 지나면 놓아버림)
- time sharing과 비슷한 개념
- time quantum이 끝나면 강제로 context switching이 일어남.
- 장점
- 일정 waiting이 보장됨 (자기말고 존재하는 process만큼만 기다리면 자기 차례가 오기 때문.)
- starvation이 발생하지 않음.
✔︎ time quantum (= time slice)
: 실행주기
- too small : context switching overhead가 커진다. (너무 자주 바뀌니까~)
- too large : FCFS와 유사해짐
- time sharing의 의미가 이상해짐
- time quantum 시간이 엄청 긴 상황에서 CPU time이 긴(time quantum이랑 비슷한)게 들어와도 RR 하는 의미가 없음.
✅ RR에서 process 수 = n, quantm = q라고 할 때
- 실행주기 (n*q) 이내
- b/c. quantum보다 같거나 짧은 주기가 있기 때문
- (n-1)*q 이내의 waiting을 보장
- time quantum보다 더 빨리 끝날 수 있기 때문.
- ∴ starvation이 발생 X
- -1은 자기 자신을 뺀 것.
- quantim은 context switching보다 충분히 크게 설정해야 함.
- b/c. 적거나 같으면 context switching하느라 시간 소비가 커짐.
📍 multi level queue scheduling
: 작업의 특성별로 별도의 queue로 유지 (ready queue를 여러 개 두자)
-
multi level queue
- 일정 task마다 별도의 queue가 부여가 됨
- task가 주어진 queue에서 영구적으로 처리되기 때문에 process가 queue사이에서 이동 X
- 한 queue에서 계속 영구적으로 처리가 됨
- 우선순위가 높은 작업들을 먼저 처리해준다는 것.
- 보통 우선순위가 낮은 queue에 대기하고 있기 때문에 starvation이 겪을 수 있음
- 우선 순위가 높은 작업들을 먼저 수행시켜주되, 우선순위가 낮은 아이들은 할당량을 구현을 받았으니까 수행이 됨. → starvation 해결!
-
fore ground: user와의 interaction이 이루어지는
- 반응성이 높아야 함 = 높은 우선순위
- 위로 갈수록
- 보통 RR
-
background : batch성을 가짐.
- 반응성이 따로 필요가 없음
- FCFS
-
each queue에는
-
priority
-
algotithm scheduling
를 별도로 구현
-
-
작업의 특성에 따라 priority 변경
✅ 구현 방법의 예
- 각 queue 간의 절대 우선순위
- 단점: starvation O
- ex. 상위 priority queue → RR / 하위 priority queue → FCFS (상위 q = 짧게, 하위 q=길게)
- queue마다 시간 분배
📍 multi-level feedback queue
- 여러 개의 queue를 두고 queue간의 process 이동을 허용
- high priority queue에는 I/O bounded process(job)가 오도록 유도
- CPU burst가 짧아서
- low priority queue에는 CPU bounded process(job)가 오도록 유도
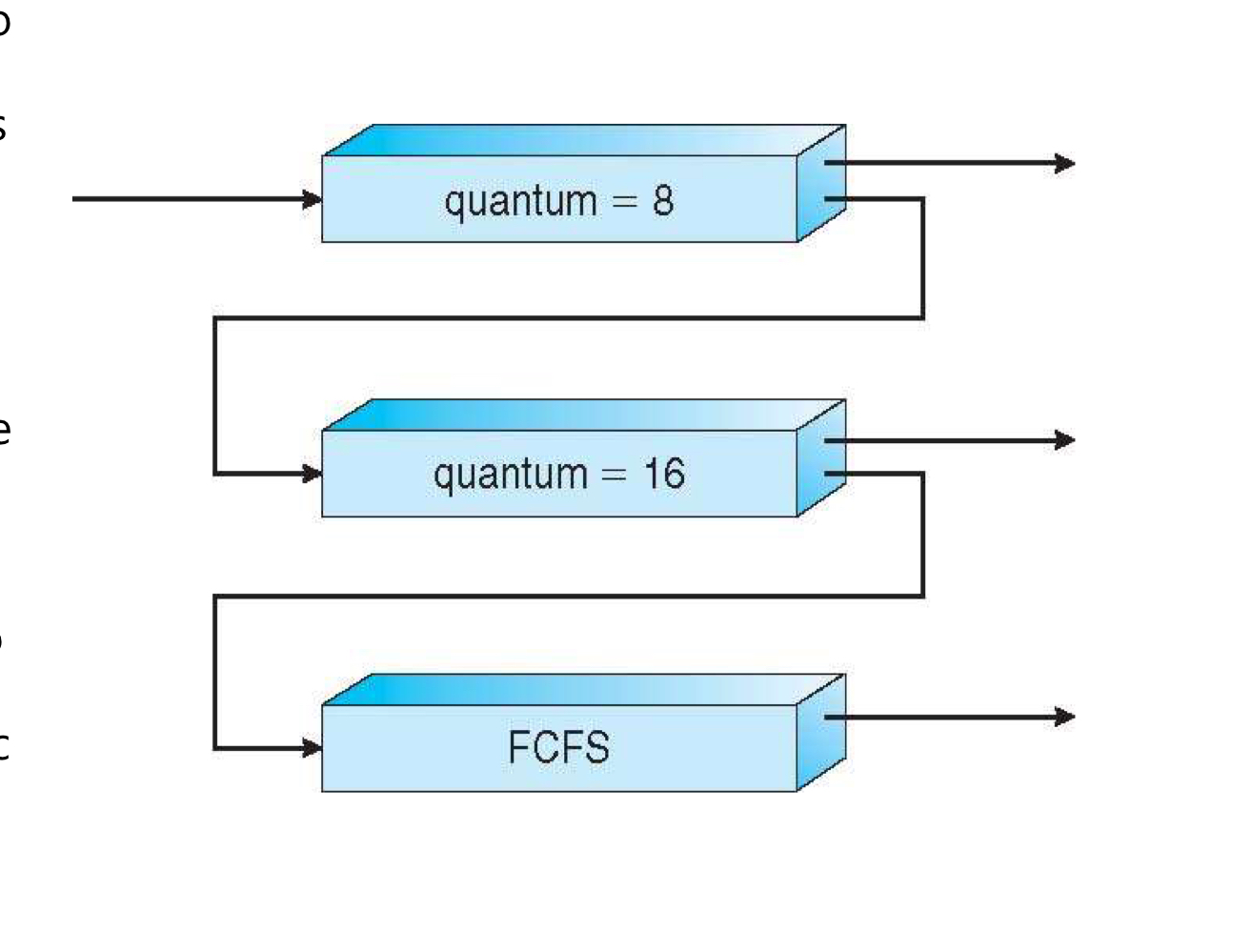
✅ algorithm 정의 내용 (고려해야 할 내용)
- queue의 수
- queue의 scheduling algorithm
- priority upgrade 방법
- priority demote 방법
- process의 queue 결정 방법
➠ 정책을 정하기 나름 (ex. I/O bounded는 priority 높게, CPU bounded는 priority 낮게)
🔥 지금부터의 내용은 CPU scheduling의 특별한 경우를 살펴볼 예정 , multi core multi CPU 고려🔥
📍thread scheduling
- many-to-many, many-to-one는 LWP(=thread)에서 지원을 함.
- thread libraury가 LWP에 있는 애들을 thread scheduling을 해줌 → thread libraury 할 때 배운 내용
- PCS: process 내에서 scheduling 경쟁이 발생
- 동일한 process 내에서 경쟁을 하는 경우
- 근데 얘네는 실제로 실행되고 있는 것이 아님.
- SCS: 사용가능한 CPU에 의해서 사용이 된다.
- 전체 system 안에서 경쟁
- 여기까지 와야 kernel level에서 CPU core를 할당 받아서 실제 실행이 되는 것
✅ user level thread
: 사용자가 느끼는 것. thread로 지원되는 것은 아님. 그러나 one-to-one, many-to-many의 차이에 따라 달라짐
- OS 입장에서 직접적으로 scheduling 해주는 애가 아님.
- thread libraury가 운영
- kernel을 인지하지 못할수도 있음
✅ kernel level thread
: OS가 직접적으로 scheduling
📍 multi processor scheduling
: multi CPU schediling
✅ multiple processor
: CPU가 여러 개
- load sharing 가능 : 큰 task들을 쪼개서 여러 개의 CPU로 나눈 다음에 각각 수행하다가 하나로 합침.
- = 병렬수행
- multi processor scheduling을 하면서 가능해진 점.
- scheduling은 복잡해짐 (어려워짐)
- b/c. 내가 관리해야 할 애들이 많아짐.
✅ homogeneous 한 경우를 고려 (우리 강의에서는)
: 각 CPU가 여러개인데 이 CPU는 같은 종류가 여러 개 있는 것으로 가정
- homogeneous: 모든 CPU가 동일 성질을 가지고 있다
-
process를 골고루 수행할 수 있다. (process 종류가 여러 개.)
→ 여러 개 CPU 중에 하나가 가용상태가 되면 그 process는 queue에 있는 어떠한 process라도 수행시켜줄 수 있음.
→ process를 골고루 분배해서 실행하기 편해짐 → 전체 성능이 좋아짐.
-
- 즉, available processor는 queue에 있는 어떤 process도 수행 가능
- 왜 고려할까?
- 여러 개의 CPU가 있을 때 한 개가 available한 상태가 되면, 어느 queue에 대기하고 있는 process들을 수행해 줄 수 있음!
cf.
- CPU가 다르다 = 하드웨어 구조가 다르다
- CPU가 같다 = 같은 compiler에서 돌리면 돌아간다
✔︎ load sharing
: 여러 개의 CPU가 사용 가능해지면 병렬 실행이 가능해짐 → 여러 개의 CPU가 같은 작업을 분담해서 담당하는 것
- 처리 속도가 빨라짐
- 장점
- 하나의 CPU에 문제가 생겨도 전체가 멈추지 않음.
- 단점
- 일꾼이 많아지는 것이기 때문에 scheduling은 어려워짐.
✅ scheduling 형식
1. asymmetric multipeocessing (비대칭형)
: CPU 중에 한 개의 processor가 scheduling에 관한 모든 실행을 담당
- 나머지는 user code만 실행 (수행만 해주겠다)
- 장점
- simple (b/c. scheduling을 한 CPU에서만 생각하면 됨)
- 한 개의 processor만이 system data를 access하므로 data sharing 문제가 단순해짐
- 문제점
- scheduling 해주는 것(master server)에 문제가 생기면 전체에 문제가 생김.
- master server가 전체 system에 영향을 준다. (요즘에는 이런 거 안 씀)
2. symmetric multi-processing (SMP, 대칭형) - 2가지 경우
-
각 processor가 스스로 scheduling 함. (각 CPU마다 scheduling을 다르게 함)
-
문제
- common data의 structure에 대한 access 문제 (수정 할 때 중복되거나 누락 될 수 있음) b/c. 하나의 data의 여러 개 ready queue가 연결되어 있기 때문
- cf. critical section
- common data의 structure에 대한 access 문제 (수정 할 때 중복되거나 누락 될 수 있음) b/c. 하나의 data의 여러 개 ready queue가 연결되어 있기 때문
-
schedule대상의 thread를 관리하기 위한 기법 - 대칭형 multi-processing 방법 2가지
-
각 processor마다 ready queue를 구성
- 단점
- 먼저 온 process의 우선 실행 보장 X
- ex. 대형마트 계산대 줄 (여러 개의 CPU에 ready queue가 여러 개 있는 경우)
- 각 queue가 개별적이기 때문에 접근을 할 수 없는 경우가 발생 → load balancing이 생성한 이유
- 장점
- processor마다 개인 queue를 가지고 있기 때문에 병목 현상이 일어날 일은 없음.
- cache memory(보조 기억장치)를 더 효율적으로 사용할 수 있음.
- 각 processor마다 자신만의 ready queue가 있고, 그 queue에 동일한 성질을 가진 processor들이 있다. 이 processor들이 필요한 data들이 비슷하다. 그래서 cache memory가 더 많이 왔다갔다 해야된다.✔︎ load balancing
: multi-processor에서 모든 CPU가 fully 활용되도록 work load를 분배
-
전부다 균등한 양의 process를 실행 할 수 있도록.
-
각 processor마다 ready queue를 구성 할 때 적용됨.
: CPU의 task양을 balance있게 조절해주겠다. (부하량이 다르기 때문)
-
가장 자연스럽게 구현하는 법
- 한 개의 common ready queue (ex. 은행 창구)를 갖는다면 자연스럽게 이루어짐 ↔ process aaffinity
- 그러나 SMP (symetrix multi processing) 대부분 system은 common queue가 아니라 각각의 queue를 갖는 형태임 → load balancing이 필요
-
방식/형식
-
1) push migration: 각 processor의 load를 주기적으로 check하고 imbalance가 발견되면 process를 옮김
- 상대가 적고 내가 많으면 push한다.
-
2) pull migration: ideal processor(쉬고 있는 processor)가 스스로 busy processor의 waiting task를 가져와 실행
- 놀고 있는 processor가 직접 당겨오는 !➠ 이 둘은 상호 배타적이지 않아도 괜춘.
-
-
장점
- 작업처리 속도 향상
- CPU의 성능을 균형있게 유지할 수 잇음✔︎ processor affinity (친화성)
: processor의 친화성
: multi processor에서 process가 동일 processor에서 실행되도록 하는 개념
-
(b/c. cache memory가 있다면 process를 변경할때 cache memory를 계속 변경해야 하는데, 이때 Overhead가 발생해서 느려진다. → 그런데 processor affinity에서는 줄어들 수 있기 때문에 사용.)
: SMP에서 제공
-
CPU 잡고 수행하다가 놓고, 다시 잡을 때 이전에 사용한 CPU를 사용하도록
-
필요성: cache memory 사용 시 process를 바꾸면 cache 내용을 재구성하는 overhead
-
형식
- soft affinity: 가급적 동일 CPU에서 실행 되도록 하되, 반드시 보장하지는 않음
- 지나친 불균형이 생길 수 있음.
- hard affinity: 동일한 CPU에서 실행되도록 ! 엄격하게 적용 (무조건 너가 할일은 너가 해!)
- soft affinity: 가급적 동일 CPU에서 실행 되도록 하되, 반드시 보장하지는 않음
-
단점
- 실행 가능한 CPU가 있음에도 해당 CPU를 사용하지 않을 수도 있음 → hard의 경우
- 한 개의 common ready queue를 구성
- 단점
- critical section이 발생할 수 있다.
- 두 개의 processor가 하나의 process에 접근할 수 있다.
- 중복, 누락이 발생할 수 있음.
- b/c. 하나의 queue에 여러 개의 process가 접근하기 때문.
- 경쟁 조건이 생길 수 있음. → 중복 + 누락 조건을 방지하기 위함 (= locking)
- 문제 : 병목 가능성이 있음. (b/c. ready queue는 하나이기 때문.
- 단점
-
✔︎ non-uniform memory access (NUMA)
- 특성을 갖는 architecture에서 processor마다 자신이 fast access가 가능한 memory process를 실행하도록
- 단점
- 노는 CPU 발생
- 필요한 이유
- NUMA 특성을 갖는 architecture에서 processor마다 자신이 fast access가 가능한 memory process를 실행시킨다.
- 각 process마다 잘하는 일이 있으니 그거에 맞게 할당시키겠다.
- 이거를 수행하면 load balancing과 충돌이 됨 (NUMA는 load balancing이 가지고 있는 장점을 상쇄시켜준다)
✅ load balance vs processor affinity (친화성)
- 어느것이 좋다고 단정할 수 X
- 선택적 허용
- idle processor가 항상 process를 가져와 수행 = 자기가 할 일이 없으면 무조건 가져오겠다. (idle processor 자체가 쉬는 시간이라는 의미임)
- 어느정도 이상의 imbalance가 발생한 경우에만 가져오도록 하는 방법 = idle processor가 있어도 balance가 유지되면 가져올 필요 없음.
- idle processor가 항상 process를 가져와 수행 = 자기가 할 일이 없으면 무조건 가져오겠다. (idle processor 자체가 쉬는 시간이라는 의미임)
📍 multi-core processor
- 한 개의 computer에서 한 개의 chip에 여러 개의 processor core를 둔다 (실행할 수 있는 CPU가 여러개)
- 각 processor가 개별 chip에 구성되는 system에 비해, 속도가 빠르고 전력소모가 적다
✅ 문제: memory stall
: process(CPU)가 memory를 access할 때 실제 data access가 가능해질때까지 일정 시간이 소요됨
(ex. cache miss등의 해결)
- 문제 발생 이유
- scheudling이 복잡해지기 때문
- 개선
- 각 core 당 여러 개의 H/W thread를 가지는 형태로 개발 → 한 thread가 memory를 waiting하는 동안 core는 다른 thread로 전환하여 수행
- 효과
- OS는 실제 CPU는 하나지만 여러 개 CPU처럼 인식을 함
- 병렬!
📍 virtualization
: 사람이 느끼는 것 (가상의 시스템)
- 한 개 CPU를 갖는 system에서 S/W적으로 multo-processor처럼 동작하게 하는 경우
📍 1️⃣ Real time CPU scheduling
✔︎ soft real-time system
- 가능한 빠른 응답
- = 중요한, 실시간으로 응답해야 하는 process가 있으면 다른 것보다 높은 우선순위만 보장해주겠다.
- ex. 계산기
✔︎ hard real-time system
-
dead line 이전에 수행됨을 보장
-
엄격한 규칙에 의해 이 시간 안에 안 되면 문제가 생김.
-
ex. 자율주행 자동차
-
latency(잠복) 최소화 해야함.
- event latency
- event가 발생한 시점부터 survice가 이루어질때까지 시간
- real time system의 성능에 영향을 주는 두 가지 latency
-
interrupt latency: interrupt가 발생했을 때 handling 하는 시간.
: interrunpt가 발생했을 때 survice하기 위해 준비하는 latency.
- interrupt 처리하는 시간 분류 ① handling time → latency ② survice time
- ISR - ppt 참고하기
- interrupt 처리하는 시간 분류 ① handling time → latency ② survice time
-
dispatch latency
☑︎ dispatcher: ready → running으로 넘어가게 해주는 것.
: 한 process를 다른 process로 바꾸는데 걸리는 latency
: 어떤 프로그램이 실질적으로 실행되기까지 걸리는 latency
- 전체적인 길이가 길어서 성능에 영향을 줌.
- context switching에서 발생하는 Overhead와 dispatch latency
- context switching 발생 시점
- interrupt가 발생했을 때 → interrupt latency + Dispatch latency 발생
- CPU burst가 끝났을 때 (I/O) → Dispatch latenct만 있음. + context switching overhead가 발생을 함 (=서로 다르다는 것)
- context switching 발생 시점
- Dispatchlatency vs Context switching
- Dispatch : ready에서 running으로 넘어가게 해주는 것.
- context switching : 현재 실행중인 process의 상태를 PCB에 저장하고 저장하고 다음에 실행할 process를 불러오는 과정, dispatch latency가 되려는 과정!
- dispatch를 하기 위해서 context switching을 하는 것
-
- event latency
✅ real time scheduling은 어떻게 해야 하는가?
- soft (=가능한 빨리) → latency 최소화
- hard → deadline 내 수행 보장
- latency minimize 예 (soft real time)
-
kernel data를 update할 때 (공유 data를 업데이트 할 때) interrupt를 disable 시키면 critical section은 해결되는데, interrupt latency에 영향을 준다.
→ interrupt latency를 disable 시키는 시간을 최소화 (= interrupt latency를 최소화 하는 방법)
= kernel data 업데이트 할 때 interrupt를 disable 시킴 = 전체를 disable시키지 말고, 중요한 부분만 disable 시키자.
-
- dispatch latency 최소화 (soft real time)
-
process와 resource를 pre-emption 시킴
→ preemptive하게 만든다 = 어떤 것을 강하게 만들기 위해서는 다른 것을 놓을 수 있어야 한다.) - non preemptive를 preemptive로 바꾸면 됨.ex. priority based scheduling
: high priority process가 CPU를 요청하면 preempted되도록
- high priority process가 들어오는 것만으로도 low priority를 놓게 만듦.
- soft real time을 service하기 위한 정도의 기능밖에 수행을 못함.
- hard real time을 service하기 위해서는 추가적인 알고리즘이 더 필요함
-
✅ hard real-time system → priority based scheduling으로 해결 못하는 것을 해결하기 위함
- deadline 내 수행보장
- admission-control algorithm : 정시 완료(deadline 안에 수행 될 수 있는지)를 보장할 수 있는가를 판단하여 admit or reject
- hard real time system을 보장하기 위해 나온 것.
- process 실행시간, 실행주기, dead line을 알아야 함
✅ Rate-monotonic scheduling algorithm (= admission-control algorithm 중 하나)
: 주기적인 task들은 preemption 가능한 정적인 우선순위 정책을 가지고 사용된다.
: deadline을 보장하기 위해서 사용
-
rate : 주기
-
monotonic : 일관된
-
periodic tasks using static priority policy with preemption
- static: 환경, 사전에 확정돼서 변하지 X
- preemption: 주기적으로
-
수행중인 lower priority process는 어떤 higher priority process가 실행 가능한 상태가 되면, preempted 됨
- 자기보다 높은 게 오면 즉시 바꾸는
- priority scheduling algorithm을 생각하면 됨!
➠ 이 두개의 환경을 전제로 함.
- 우선순위 정하는 방법
- 각 task는 실행 주기값에 반비례하여 우선순위 결정.
- 각 task는 실행 주기값에 따라 우선 순위를 정하는데, 실행주기 값에 반비례하여 priority 결정 ➠ 실행주기가 짧은 process → high prioroty
- 각 process에 대하여 실행주기, CPU burst (⊕ dead line)를 알고 있어야 함.
- 필기 예시 참고하기 ❗️
- example 2: worst case에 대한 나용
- 한계: CPU 이용률의 한계가 존재한다.
📍 2️⃣ Earliest-Deadling scheduling
: deadline이 높은 것을 우선순위로 준다 (priority를 주기에 따라서 주는 것 X)
ex. 마감 시간이 얼마 남지 않은 과제부터 우선 시작한다.
- priority를 동적으로 assign
- b/c. 주기가 아니라 burst이기 때문에 중간 상황에 의해 deadline이 달라지기 때문.
- deadline이 더 가까운 process가 high priority를 갖는다 (ex. 마감시간이 급한 과제부터 해결)
- deadline이 언제인지 알려줘야 scheduling을 할 수 있음.
- 100% CPU utilization 고려 가능 → 이론적으로 가능하나 실제로 불가능 (b/c. context switching overhead, interrupt handling overhead가 발생하기 때문→ context switch하는 걸 안 하면 됨!)
📍3️⃣ CPU scheduling algorithm evaluation
✅ criteria ex.
- maximum response time이 지정된 조건 하에서 CPU utilization 극대화
- turn-around time이 총 실행시간에 비례하도록 throughput을 극대화
- turn-around time : 작업제출 ~ 끝 시간 (전체시간)
- 비례해야 공평함을 느낌
✅ evaluation 방법
- Deterministic modeling
- a analytic evaluation
- 사전에 지정한 work load에 대하여 각 algorithm을 적용
- 장점
- simple
- fast
- 단점
- 주어진 data에 대해서만 의미를 갖는다
- queueing Model
- CPU burst, I/O burst의 분포 → 근사치 추정
- 각 queue에 대하여 arrival rates, survice rates를 알고 있다고 가정하면 system utilization, average queue length, average waiting time을 알 수 있다.
- arrival rates: ex. 평균적으로 한사람이 얼마나 받는지
- survice rates: ex. 배식시간
- simulation (모의실험)
- CPU burst time
- arrival, departure, data
- 확률 분포에 따라 data 생성 → 성능분석 (실제상황과 얼마나 유사한지가 성능을 좌우)
- implementation (구현)
- 고려사항
- cost 문제
- OS 변화가 사용자 관점과의 차이 → 사용자는 자신의 job에만 관심
- user가 변화에 적응 → test 환경과 실제 상황이 달라질 수 있음
- 고려사항
CPU Scheduling 내용 엄청 많다..
운영체제 자체가 많을 수밖에 없겠지만 정말 이번 챕터 내용은 많은 것 같다.
각각의 개념마다 장점과 단점을 잘 구분하여 알아는 것이 이번 챕터에서 가장 중요한 것 같다.
