
Hash Table
- 내부적으로 배열을 사용해 데이터를 저장해 빠른 검색속도를 가진 자료구조
- 특정 값을검색하는데 데이터의 고유한 인덱스로 접근하기 때문에 평균적인 경우(Collision이 일어나지 않는 경우)
O(1)의 시간 복잡도를 갖는다. - 이해를 위해 다음 사진을 참고하자.
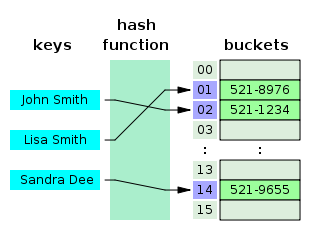
Hash Funtion
- '특별한 알고리즘'를 이용해 데이터의 고유한 인덱스를 Hash Code로 변환하는데 이 '특별한 알고리즘'을 Hash Method, Hash Function이라고 한다.
- 어설픈 Hash Function을 사용하면 동일한 Hash Code가 생성될 수 있는데 이것을 Collision(충돌)이라고 한다.
- 그럼 좋은 Hash Function은 어떤 조건을 가지고 있을까?
- key의 일부분이 아니라 전체를 이용해 Hash 값을 만들어낸다.
- key가 어떤 특성을 가지고 있는지에 따라 달라진다.
- Collision을 최소화하는 방향으로 설계되며, 발생했을때 어떻게 대응할 것인지도 중요하다.
- Collision이 많아질수록
O(1)에 해당하던 접근(Search)의 시간 복잡도가O(n)에 가까워진다.
Collision의 해결
Open Address (개방 주소법)
- Collision이 발생하면 다른 Hash Bucket에 데이터를 추가한다.
- Hash Bucket(Hash Slot): 데이터를 저장하는 공간를 가리키는 용어
- 다른 Hash Bucket를 찾는 방법은 크게 3가지로 다음과 같다.
- Linear Probing: 순차적으로 다음 Hash Bucket을 탐색해 비어있는 공간을 찾는다.
- Quadratic Probing: n^2칸씩(1, 4, 9, ...) 뛰어넘어 Hash Bucket을 탐색해 비어있는 공간을 찾는다.
- Double Hashing Probing: 또 다른 2차 Hash Function을 이용해 새로운 주소를 할당하는데, Linear와 Quadratic에 비해 연산량이 많아진다.
Separate Chaining (분리 연결법)
- 일반적으로 개방 주소법에 비해 빠르다.
- Collision이 일어나지 않도록 해시 보조 함수를 사용한다.
- Java 7에서 이 방식을 이용해 Hash Map을 제공한다.
- 두 가지 구현 방식이 존재하는데 다음과 같다.
- Linked List: 각각의 버킷을 연결 리스트로 만들어 Collision이 발생하면 해당 리스트에 추가한다.
- Tree: 각각의 버킷을 트리로 만들어 Collision이 발생하면 해당 리스트에 추가한다.
- 두 가지 방식중 하나를 택하는 기준은 저장되는 데이터의 개수로 6과 8이 그 기준이다. (적을 때 Linked List, 많을 때 Tree)
- 7이 없는 이유는 Linked List와 Tree로의 변환이 빈번하게 일어나는 것을 막기 위함이다. (6개일때 하나가 추가되면 아직 Linked List 유지, 8개일때 하나가 삭제되면 아직 Tree 유지)
두 방식의 비교
- 두 방식 모두 Worst Case에서의 시간 복잡도는
O(M)이다. - Open Address 방식이 Separate Chaining 방식에 비해 데이터 캐시 효율이 높다. 따라서 데이터의 개수가 충분히 적은 경우 Open Address 방식의 성능이 더 좋다.
- Separate Cheining 방식이 Open Address 방식에 비해 테이블 확장이 느리게 일어난다.
테이블 확장
- Hash Table에서 데이터의 개수가 일정수준을 넘어가게 되면 테이블의 크기를 2배로 늘리게 되는데 이를 테이블 확장이라고 한다.
- 일정수준은 테이블의 75%에 해당하며 이 0.75를 Load Factor라고 부른다.

I Will be Relaxed Person