SelfReg: Self-supervised Contrastive Regularization for Domain Generalization
1. Introduction
- real-world에서는 domain shift로 인한 generalization performance 저하가 있을 수 있음.
- 이를 해결하기 위해 domain generalization에 대한 연구가 진행되고 있음.
- domain-invariant features를 추출하여 domain shift 문제를 완화시킨다.
- 최근에는 contrastive learning 기반의 domain generalization 연구가 높은 성능을 달성했다.
- negative data pair가 필요하고, 학습의 성능이 이러한 데이터의 품질과 양에 달려있다.
- 본 논문에서는 positive data pair를 사용하되, representation collapse를 피하기 위해 네트워크의 마지막 단에 projection layer를 추가한다.
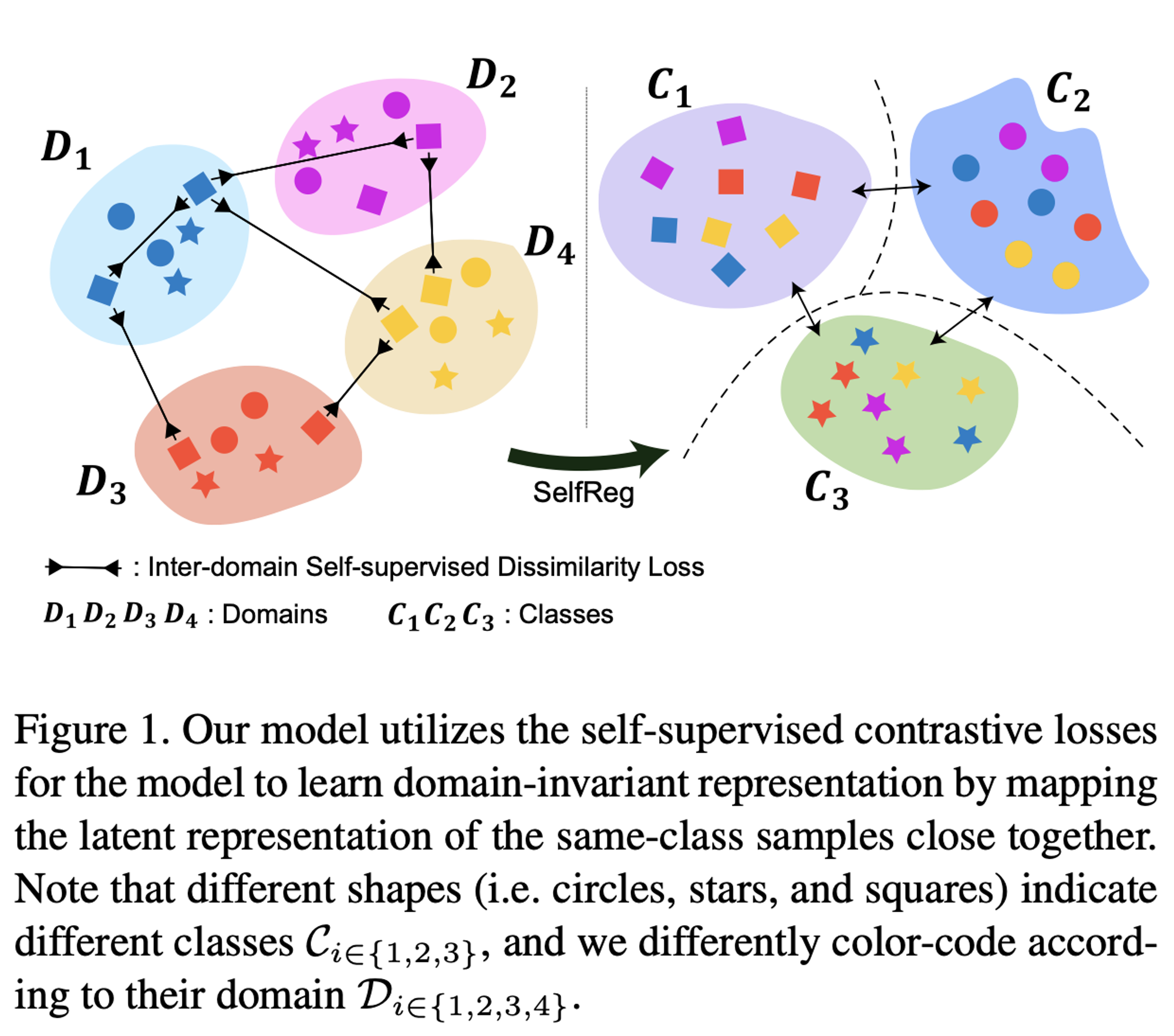
2. Method
- domain generalization의 목적은 domain-invariant representation을 학습함으로써 모델이 unseen target domain에도 generalize를 잘할 수 있도록 하는 것.
- 본 논문에서는 같은 클래스의 샘플끼리는 가깝게, 다른 클래스의 샘플끼리는 멀게 임베딩함으로써 domain-invariant representation을 학습하는 self-supervised contrastive loss를 제안한다.
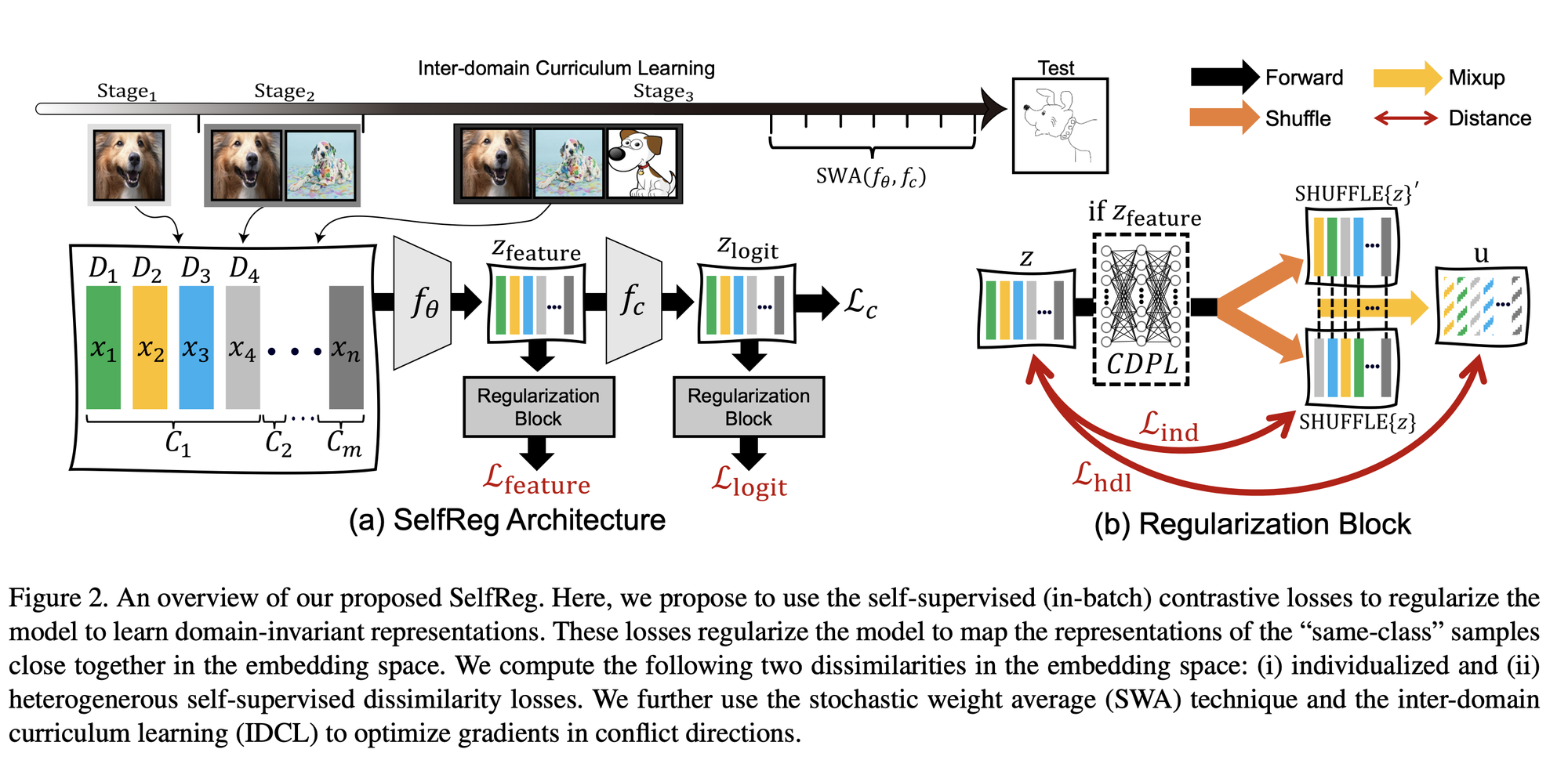
2.1. Individualized In-batch Dissimilarity Loss
Lind(z)=N1i=1∑N∣∣zic−fCDPL(zj∈[1,N]c)∣∣22
- zjc는 zic와 같은 클래스를 갖는 다른 in-batch에서 랜덤하게 선택된다.
- represenatation collapse를 피하기 위해 Class-specific Domain Perturbation Layer(fCDPL)를 추가한다.
2.2. Heterogeneous In-batch Dissimilarity Loss
- ui = fCDPL(zic)
- two-domain Mixup을 적용함으로써 서로 다른 도메인에대한 interpolated latent representation zˉi를 얻음.
uˉic=γuic+(1−γ)uj∈[1,N]c
Lhdl(z)=N1i=1∑N∣∣zic−uˉic∣∣22
- ujc는 uic와 같은 클래스를 갖도록 랜덤하게 선택된다.
2.3. Features and Logit-level Self-supervised Contrastive Losses
LSelfReg=λfeatureLfeature+λlogitLlogit
- LSelfReg이 초기 training이후에 dominant해져서 gradient imbalance로 인해 학습을 방해함.
- 이를 해결하기 위해 gradient stabilization technique인 loss clipping과, stochastic weights averaging(SWA), inter-domain curriculum learning(IDCL)을 적용한다.
Loss Function
L=Lc+LSelfReg
3. Proof-of-Concept Experiments
3.1. Implementation and Evaluation Details
- ImageNet pretrained Res18모델 30에폭 학습.
- λfeature = 0.3, λlogit=1.0
- Class-specific Domain Perturbation Layer(fCDPL)은 2-layer MLP, hidden units는 1024
Dataset
- PACS benchmark(Photo, Art painting, Cartoon, Sketch)
- train-valid split 9:1
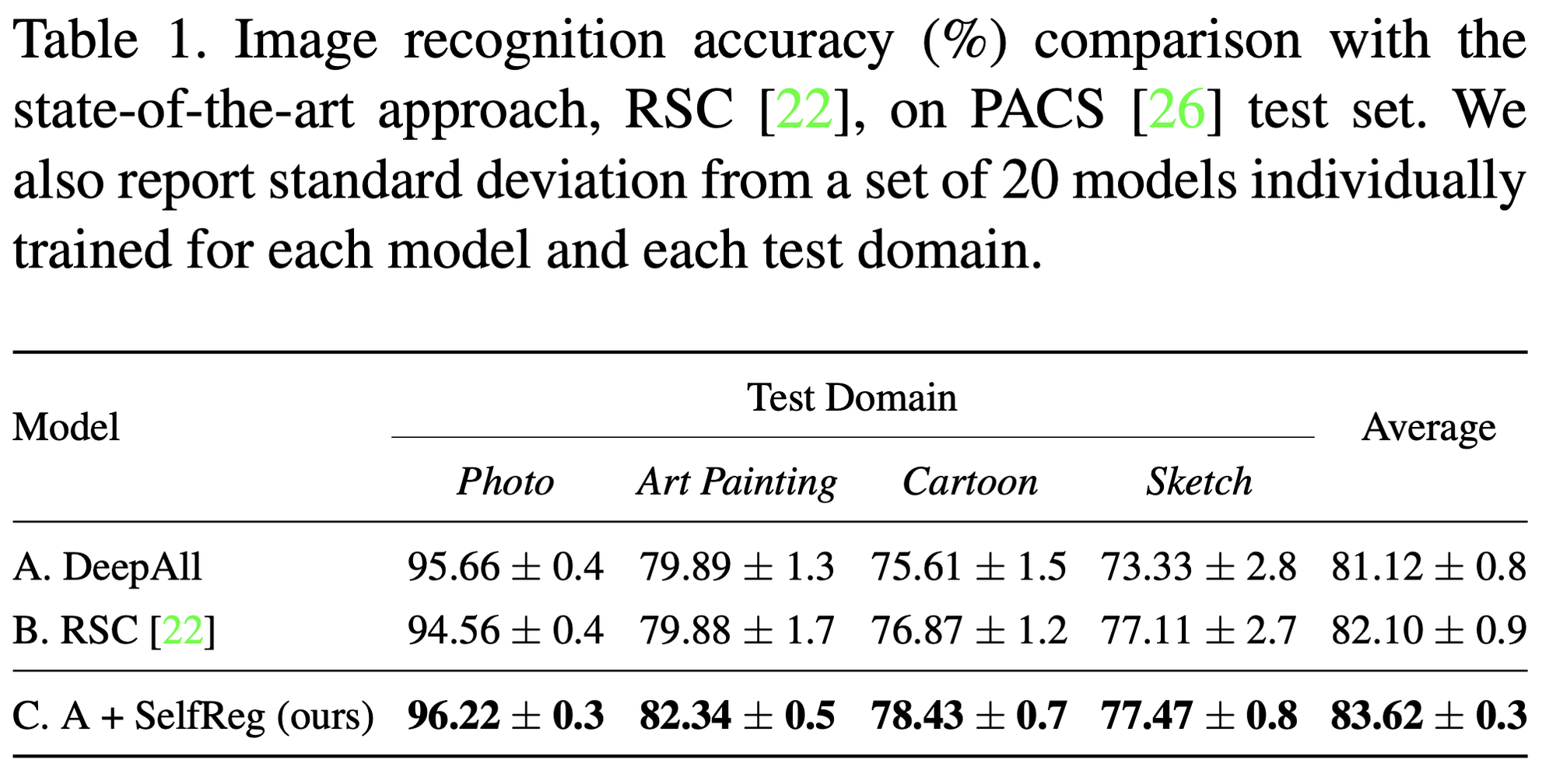
- sota method, Representation Self-Challenging(RSC)은 학습중에 dominant feature를 반복적으로 버리고 최종 판단을 위해 네트워크가 나머지 feature를 사용하도록 한다.
- 공정한 비교를 위해 모든 모델은 동일한 백본 Res18을 사용한다.
- sota method에 비해 높은 accracy, 낮은 variance 달성.
Qualitative Analysis by t-SNE
The Effect of Dissimilarity Loss
![업로드중..]()
Analysis with GradCAM
![업로드중..]()
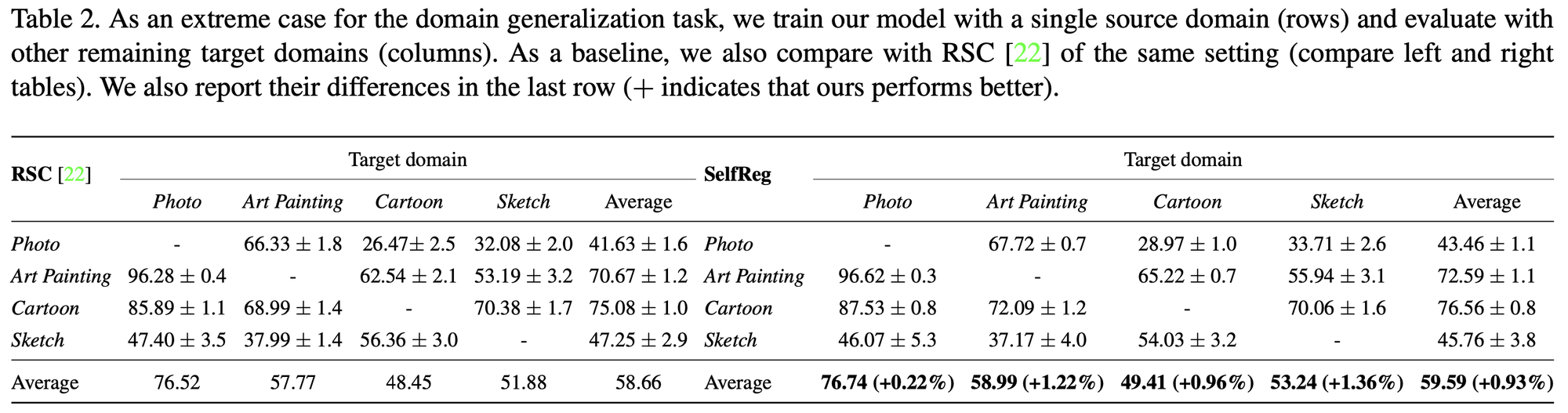
3.3. Single-source Domain Generalization
![업로드중..]()
3.4. Ablation Study
![업로드중..]()
- inter-domain curriculum learning(IDCL)
- A vs B
- 모든 target domain에 대해서 성능 향상 존재 (average accuracy 0.32%)
- stochastic weights averaging(SWA)
- B vs C
- 모든 target domain에 대해서 성능 향상 존재 (average accuracy 0.25%)
- a class-specific domain perturbation layer(CDPL)
- C vs D
- 다수의 target domain에 대해서 성능 향상 존재
- a two-domain mixup layer
- D vs E
- 다수의 target domain에 대해서 성능 향상 존재
- feature-level in-batch dissimilarity regularization
- E vs F
- 다수의 target domain에 대해서 성능 향상 존재
- logit-level in-batch dissimilarity regularization
- F vs G
- 모든 target domain에 대해서 성능 향상 존재
4. Experiments on DomainBed
- DomainBed : ColoredMNIST, RotatedMNIST, VLCS , PACS , Office- Home , and TerraIncognita , DomainNet
- Benchmark results : ERM, IRM, GroupDRO, Mixup, MLDG, CORAL, MMD, DANN, CDANN, MTL, SagNet, ARM, VREx, RSC
![업로드중..]()
5. Conclusion
- 본 논문에서는 domain generalization을 위한 새로운 regularization method인 SelfReg을 제안함.
- domain generalization에서 기존의 방법론 대비 같거나 더 높은 성능을 보임.
