Barlow Twins: Self-Supervised Learning via Redundancy Reduction
1. Introduction
- Self-supervised learning(SSL)은 human annotation없이 데이터의 represenation을 학습하는 것을 목표로 한다.
- SSL은 supervised learning과의 차이를 빠르게 따라잡고 있다.
- SSL에 대한 성공적인 접근 방법은 입력 데이터의 distortion에 invariant한 임베딩을 학습하는 것이다. 하지만 이 접근법은 trivial constant solution이 존재한다는 문제가 있다.
- 따라서 본 논문에서는 distorted sample을 입력한 두개의 네트워크의 아웃풋 사이의 cross-correlation matrix를 identical matrix와 최대한 같아지도록 학습함으로써 위와 같은 문제를 자연스럽게 피할 수 있도록 한다.
- 이로 인해 distorted versions of sample이 embedding vector가 유사해지며, 이들 벡터의 components간의 redundancy(중복성)을 최소화한다.
- BARLOW TWINS는 개념적으로 간단하고 구현하기 쉬우며 유용한 representation을 학습한다.
2. Method
2.1. Description of Barlow Twins
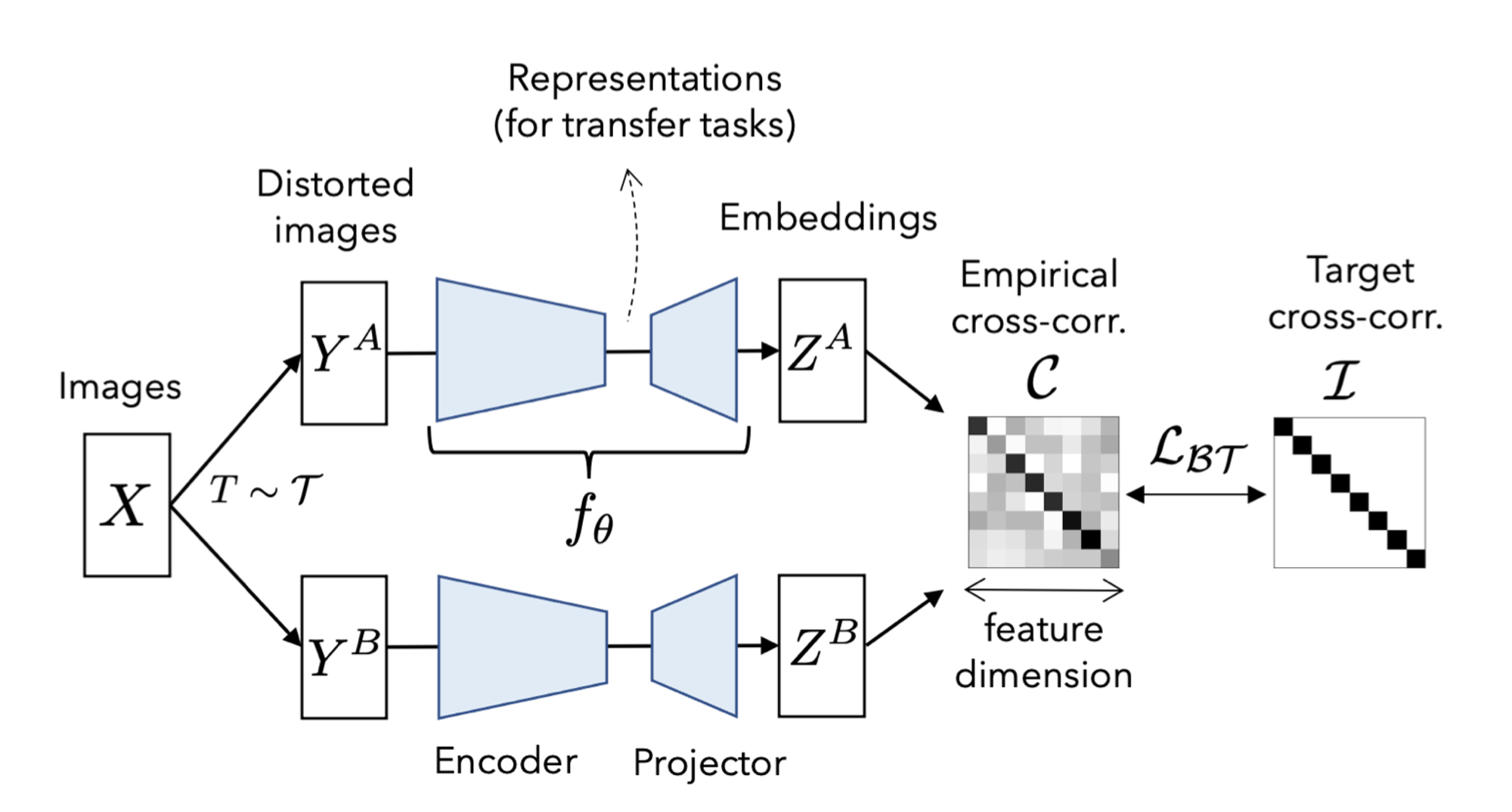
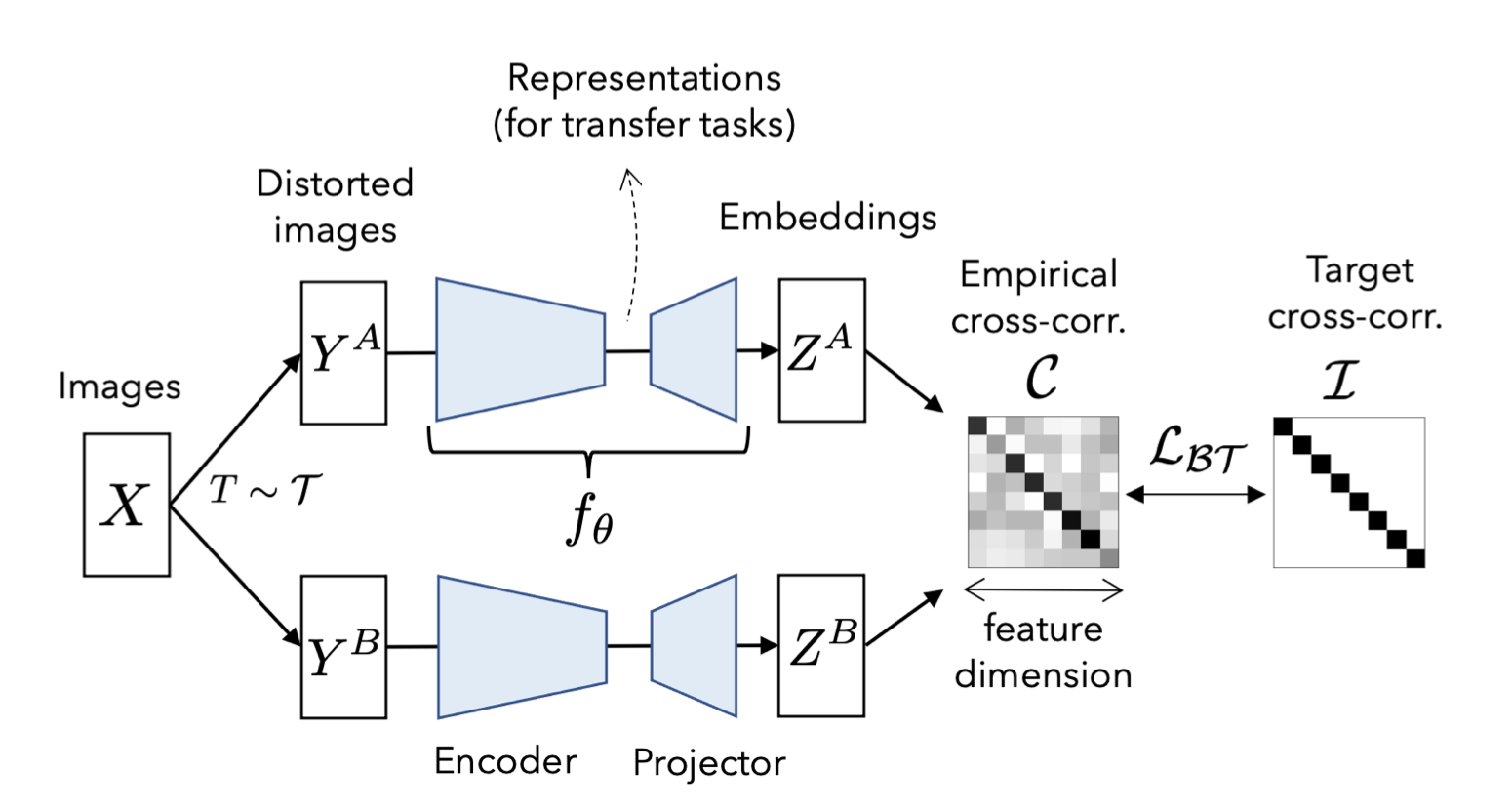
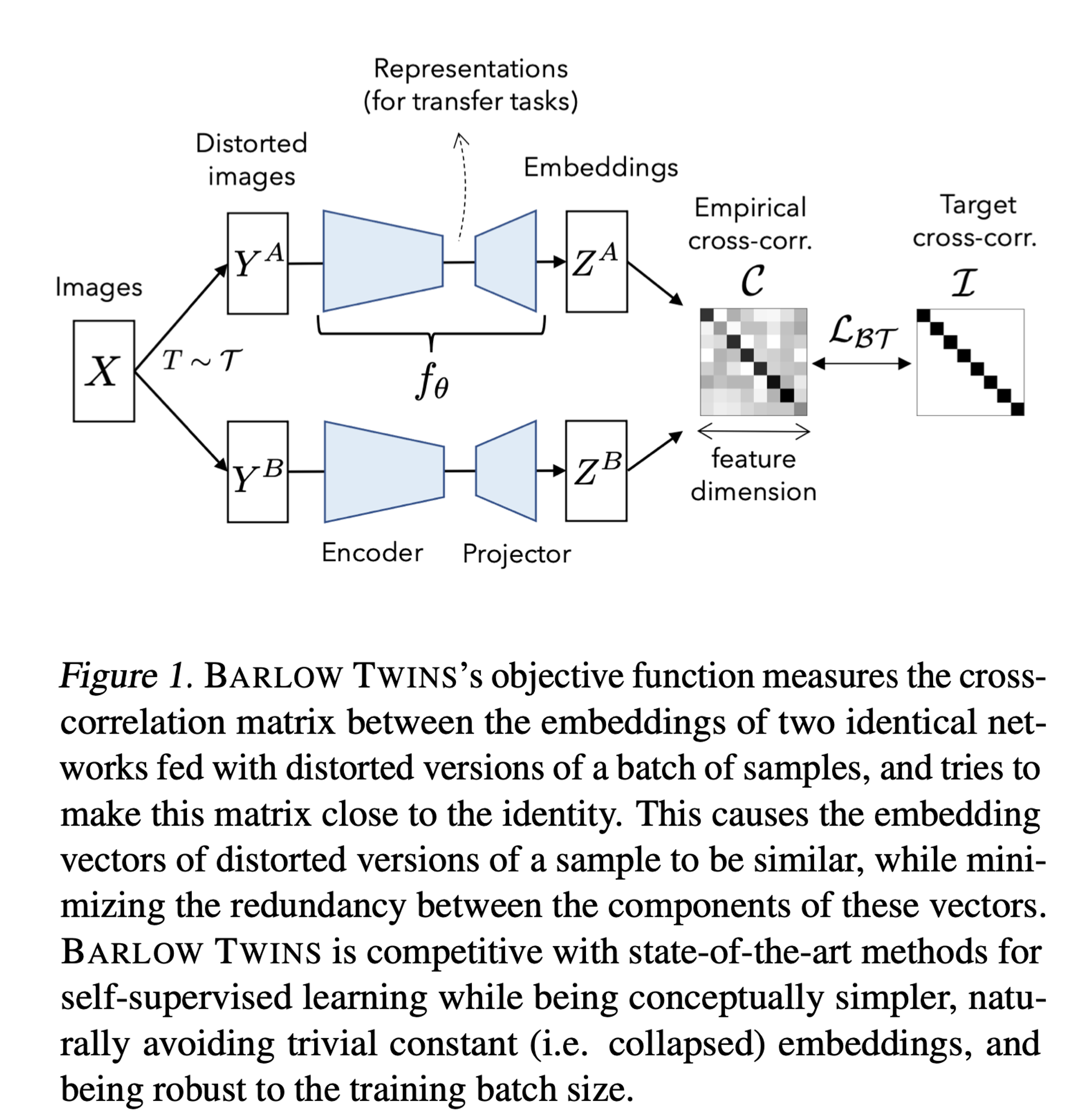
- batch 에 대해 두개의 distorted view를 생성한다.(distorted view는 data augmentation 로 얻어진다.)
- 각각의 distorted view인 와 두개의 배치는 에 공급되어 각각 와 를 생성한다. 이때 와 는 batch dimension으로 mean-centered 되어있다고 가정한다.(mean이 0)
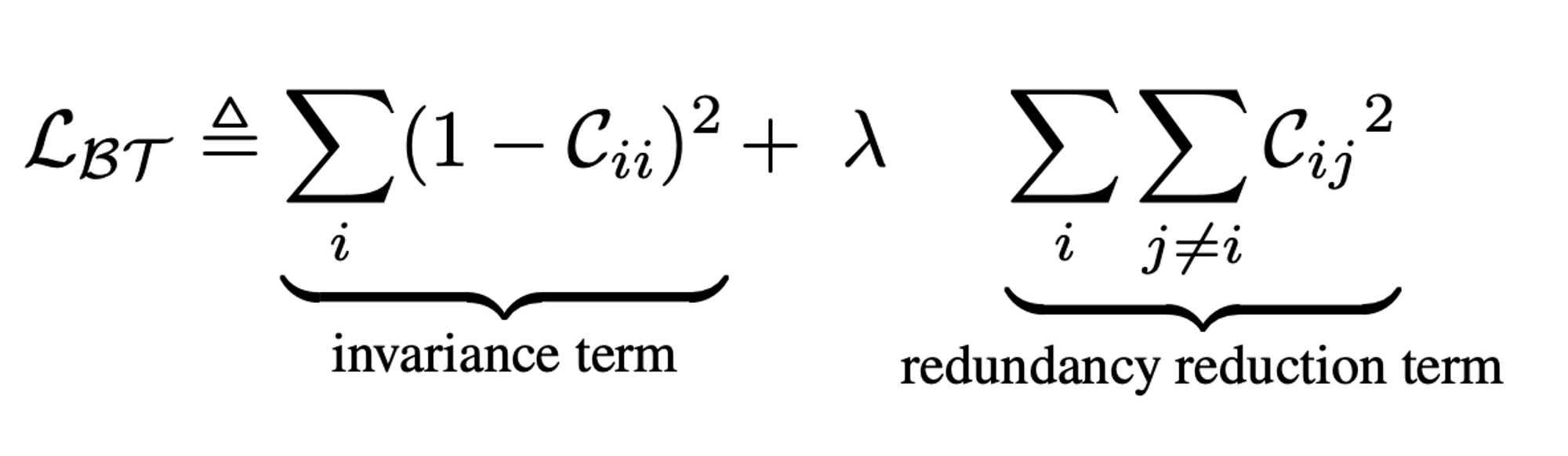
: 두개의 identical network에서 나온 아웃풋 사이에서 계산된 cross-correlation matrix.(square matrix with size dimensionality of the network's output)
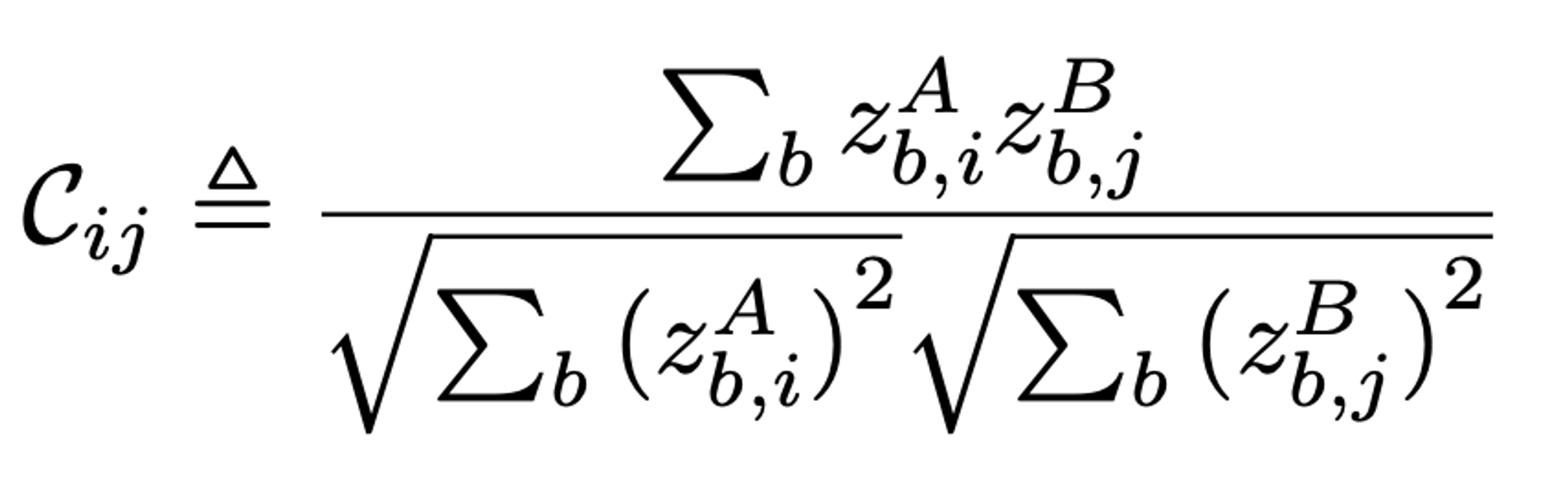
- 직관적으로, invariance term은 cross-correlation matrix의 diagonal elements를 1과 같도록 함으로써 distortion에 invariant한 embedding을 만든다.
- redundancy reduction term은, cross-correlation matrixd의 off-diagonal elements를 0과 같도록 함으로써 embedding의 different vector components를 decorrelate하게 한다.
- 이 decorrelation은 output unit들 사이의 redundancy(중복성)을 감소시켜, output unit들이 샘플에 대한 non-redundant information을 포함하도록 한다.
- Barlow Twins의 objective function은 기존의 SSL 방법론과 유사하다.(ex. redundancy term은 INFONCE objective의 contrastive term과 유사함)
- 하지만 INFONCE-based methods와 비교해서 중요한 차이점이 있다.
- Barlow Twins는 대량의 negative sample이 필요하지 않기 때문에 작은 배치에서 잘 작동할 수 있다.
- Barlow Twins는 high-dimensional embedding으로부터 benefit을 얻는다. 또는, redundancy reduction term은 임베딩에 대한 soft-whitening 제약으로 볼 수 있다.

2.2. Implementation Details
Image augmentations
- Transformations : random cropping, resizing to 224 * 224, horizontal flipping, color jittering, converting to grayscale, Gaussian blurring, and solarization
- cropping and resizing은 항상 적용하고, 나머지 5개는 랜덤한 확률에 의해 적용된다.
- BYOL에서의 augmentation parameter와 동일하다.
Architecture
- encoder : ResNet50
- projector : 3 linear layers, 각 layer에 8192개의 output units, 처음 2개의 layer에는 BN 적용
- encoder의 output : 'representations'
- projector의 output : 'embeddings'
Optimization
- 1000 epochs
- BYOL protocol
- = 0.005
- 32 V100 GPUs and takes 124 hours
3. Results
3.1 Linear and Semi-Supervised Evaluations on ImageNet
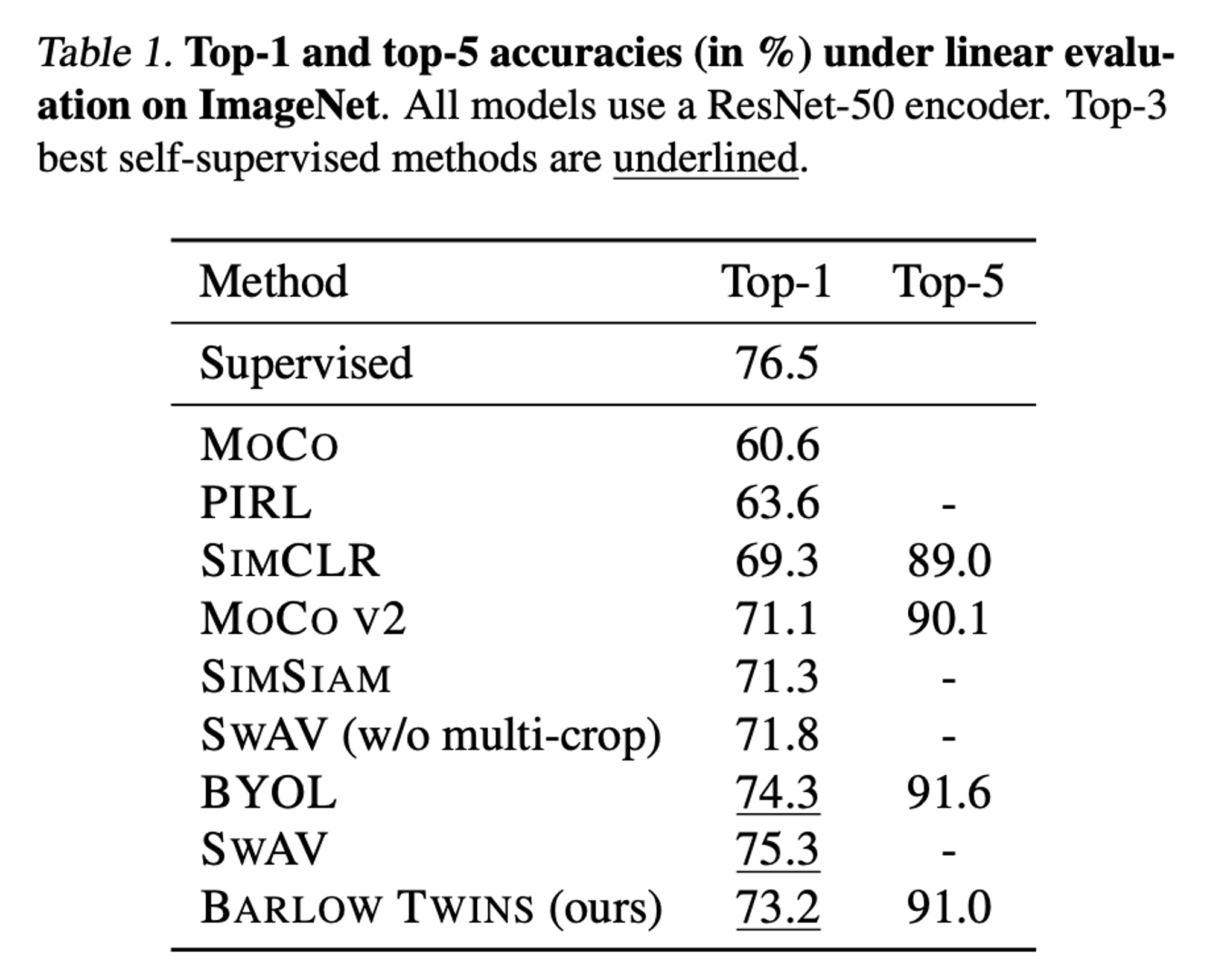
Linear evaluation on ImageNet
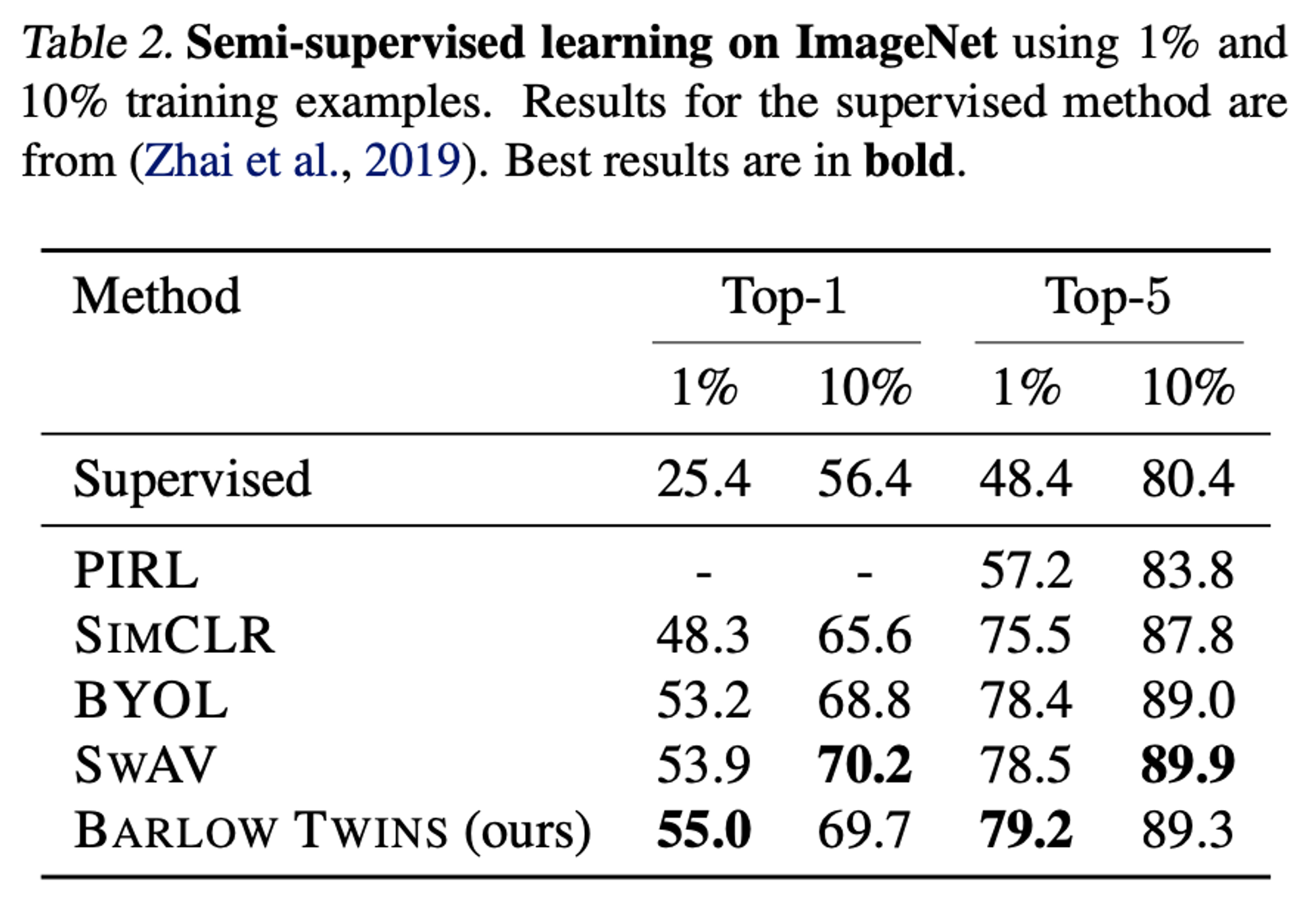
Semi-supervised training on ImageNet
3.2. Transfer to other datasets and tasks
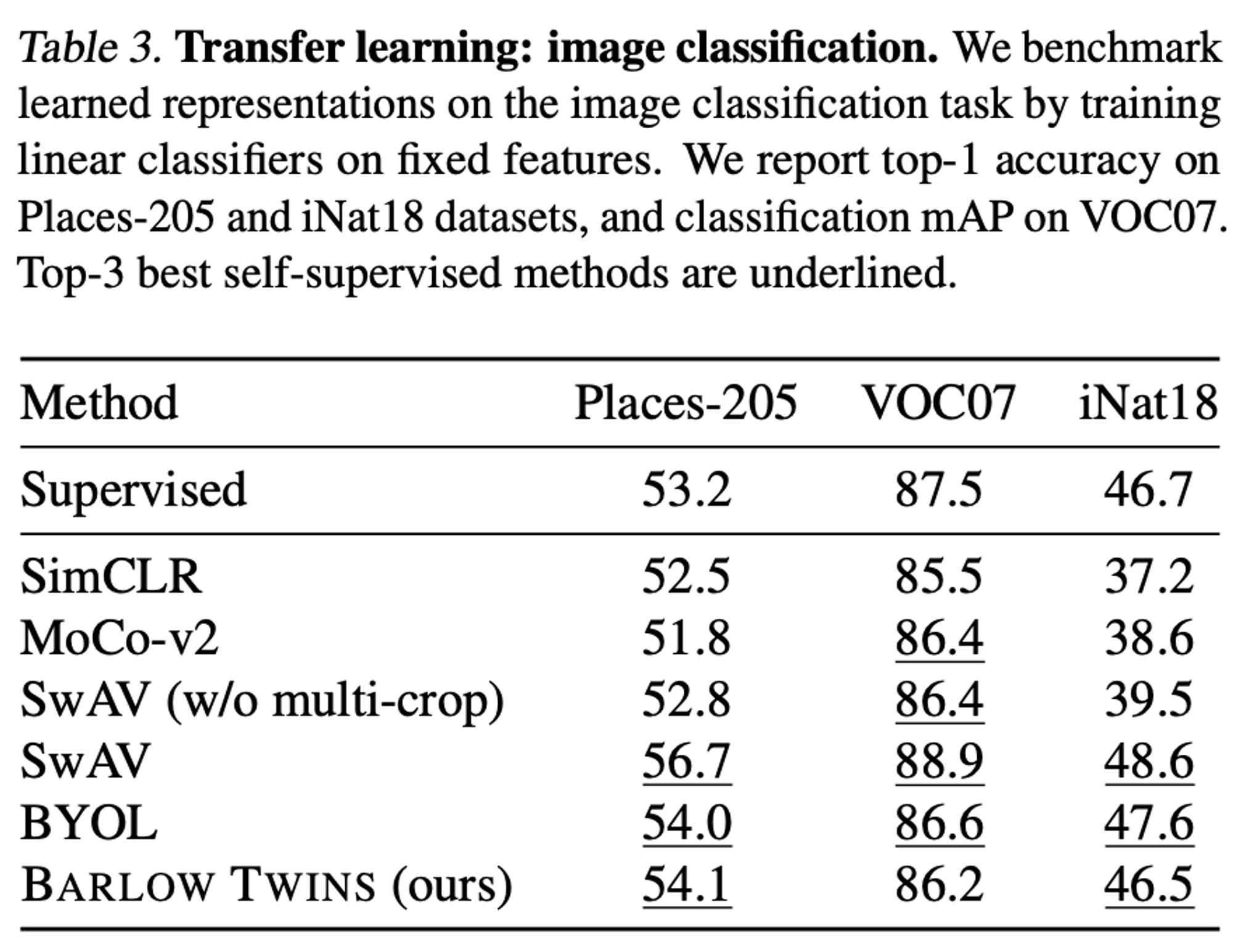
Image classification with fixed features
Places-205 : scene classification
VOC07 : multi-label image classification
iNaturalist2018 : fine-grained image classification
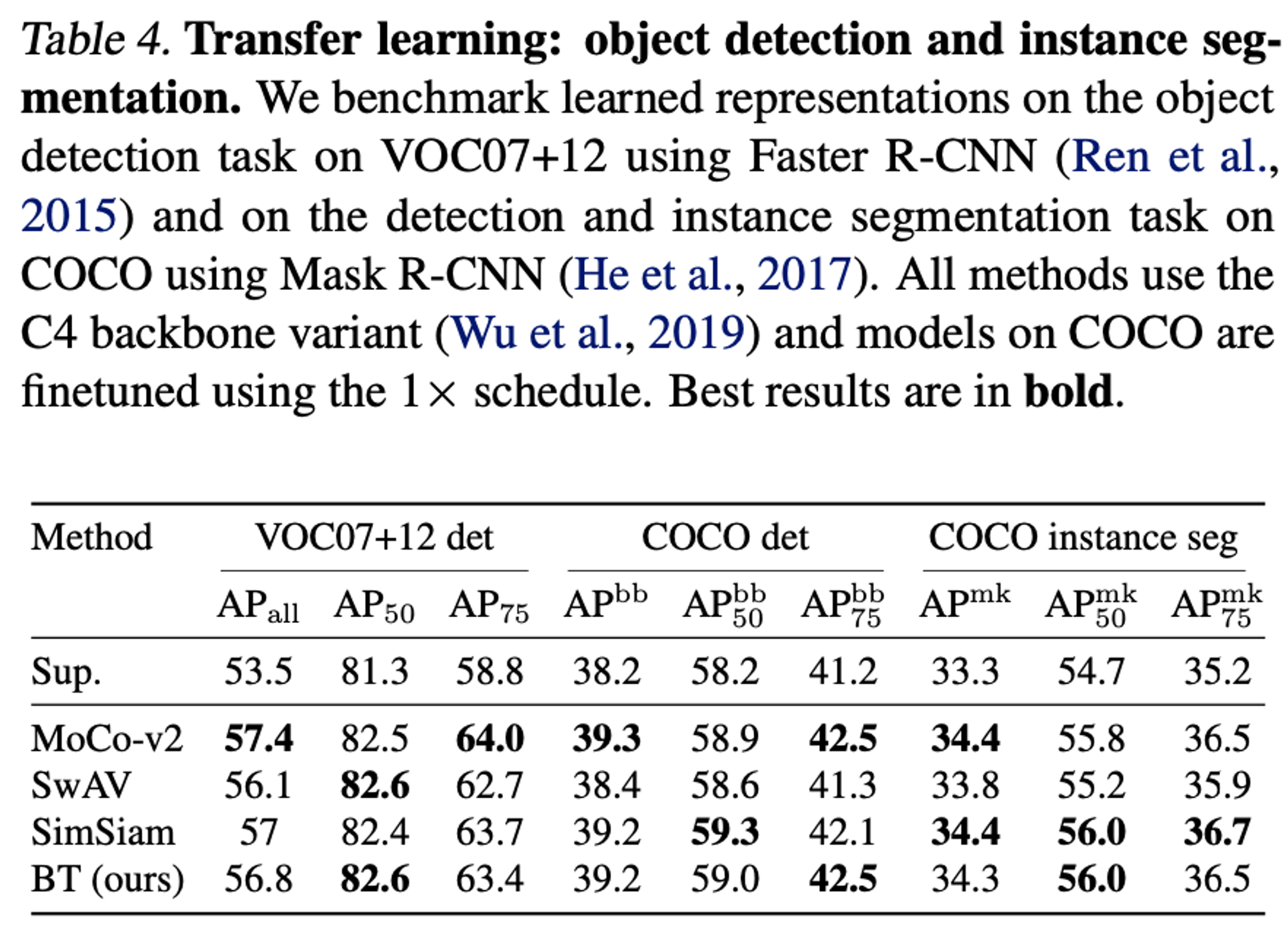
Object Detection and Instance Segmentation
4. Ablations
Loss Function Ablations
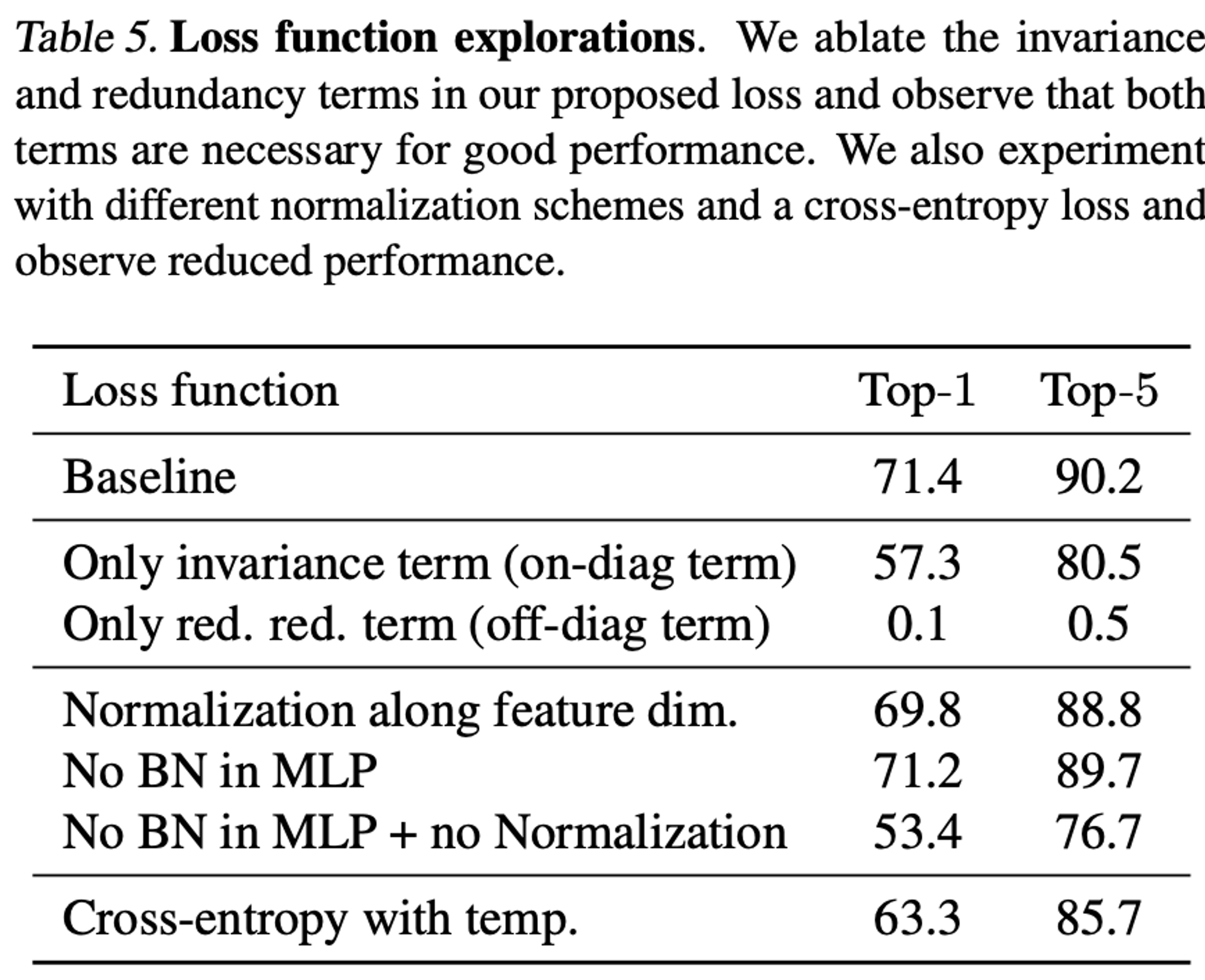
- baseline : linear evaluation on ImageNet
- Normalization along feature dim : embedding을 batch dimension으로 noramlize한 후 feature dimension으로 normalize하고 covariance matrix측정
- no BN MLP + no normalization : cross-correlation matrix 대신 cross-covariance matrix.(features ard no longer normalized along the batch dimension)
- Cross-entropy with temp : on-diagonal term과 off-diagonal term이 temperature hyper parameter과 coefficient에 의해 조절됨.
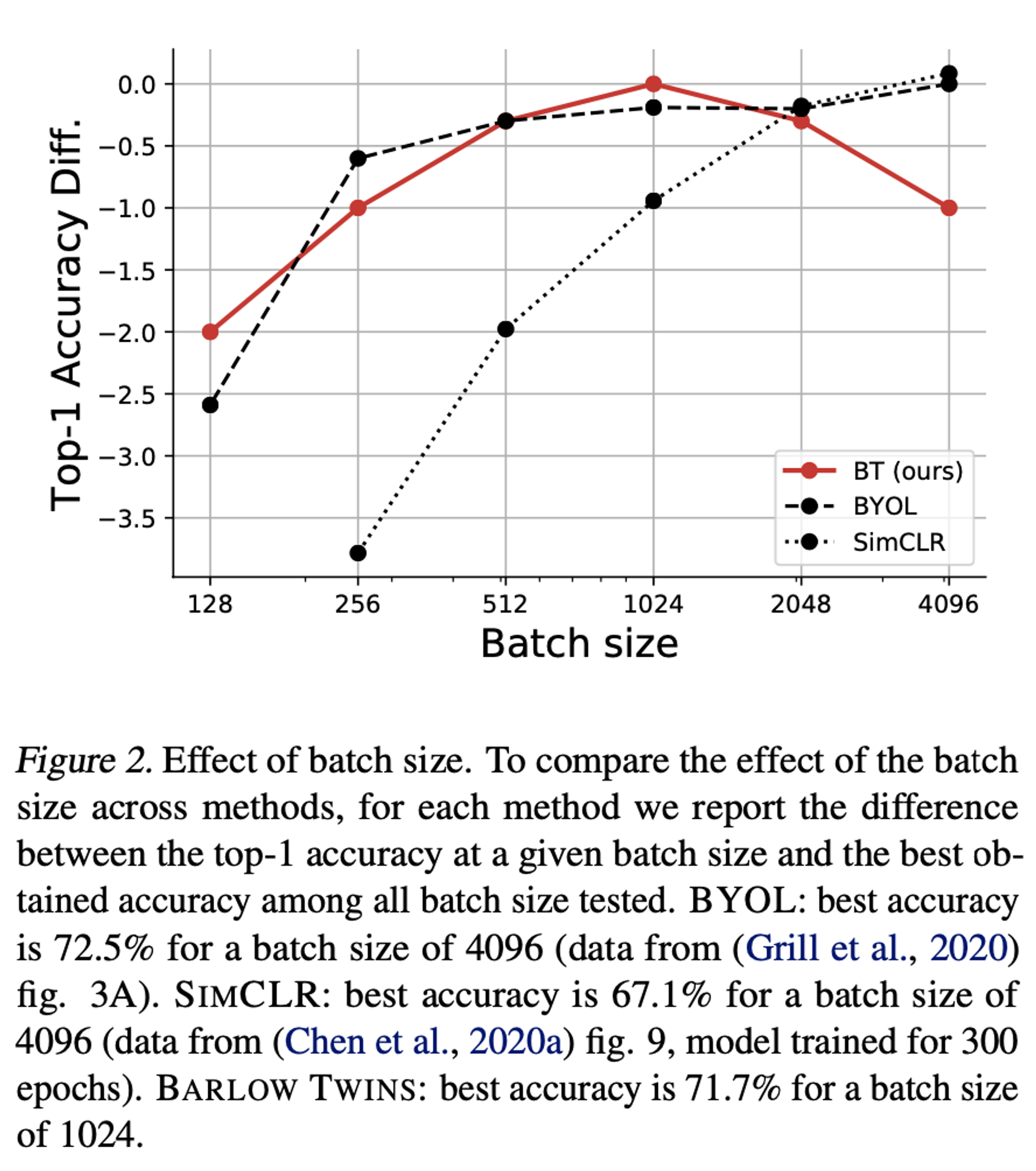
Robust to Batch Size
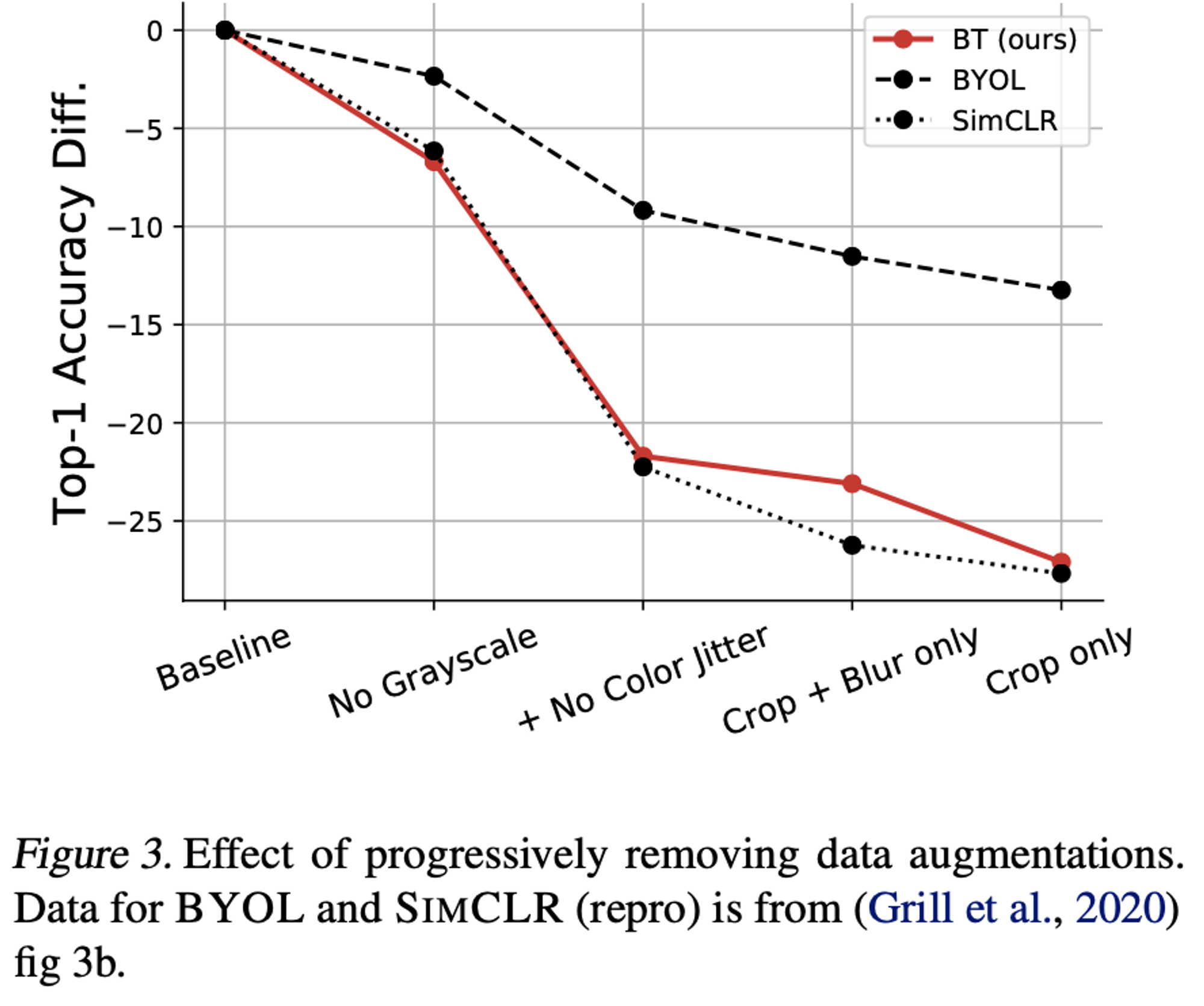
Effect of Removing Augmentation
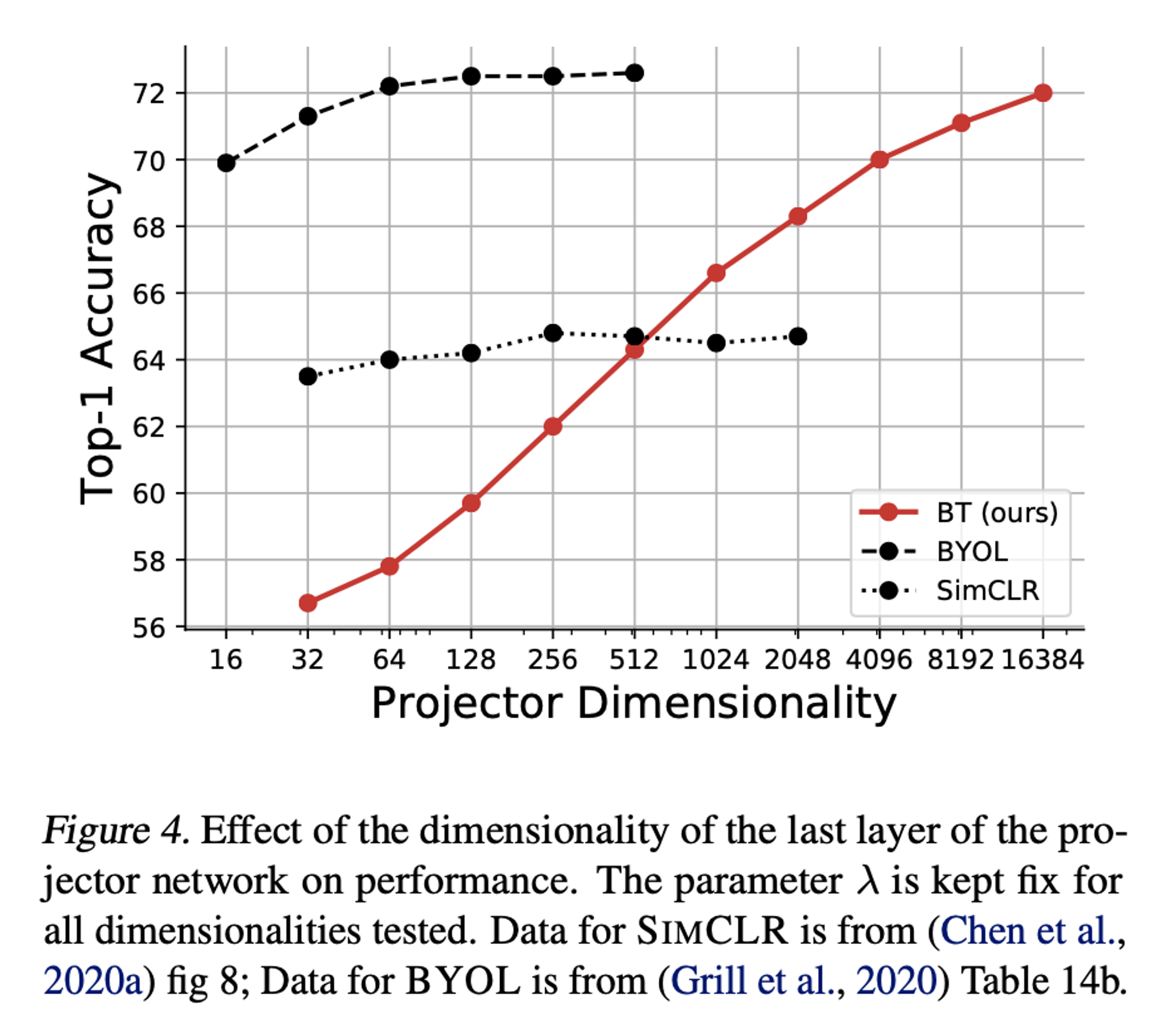
Projector Network Depth & Width
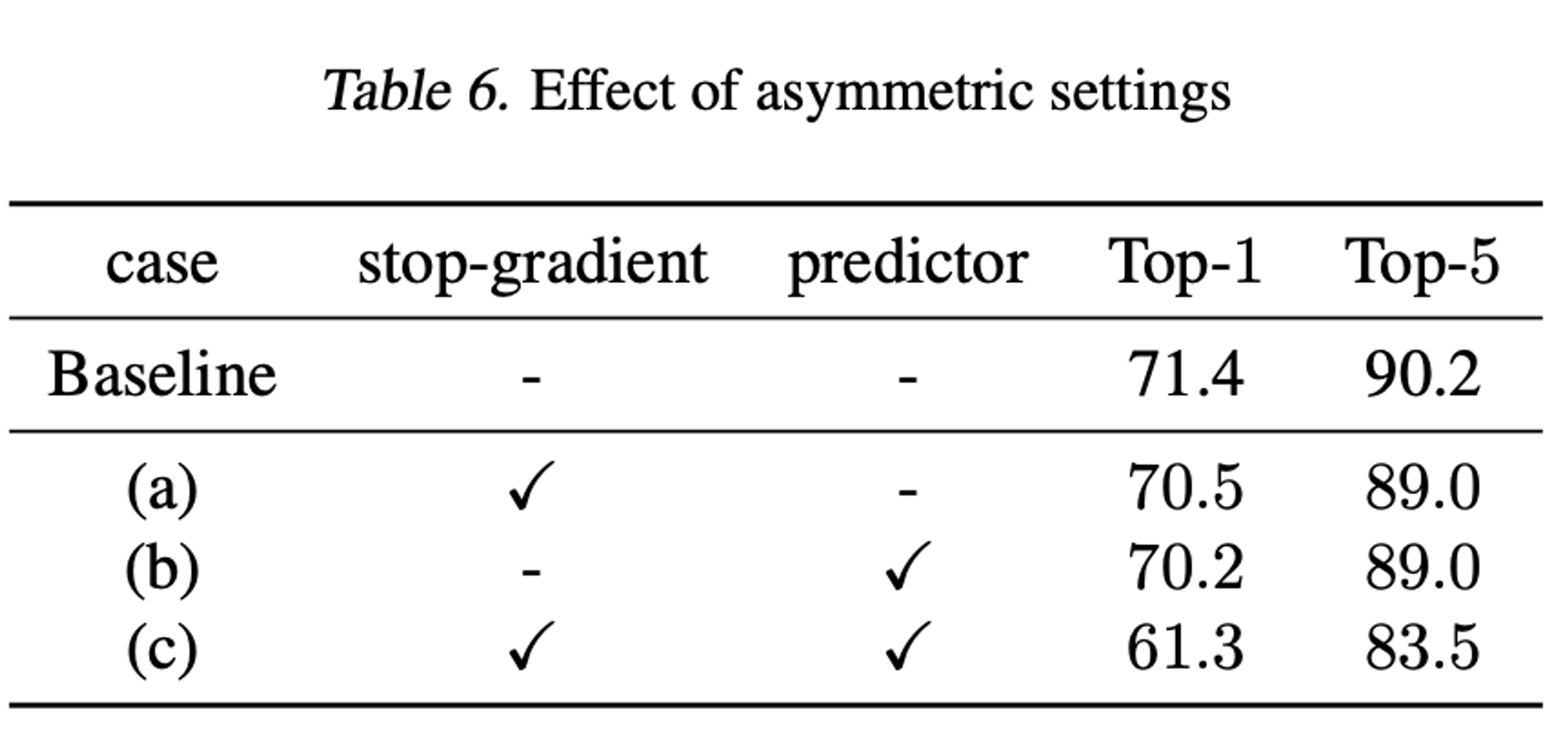
Breaking Symmetry
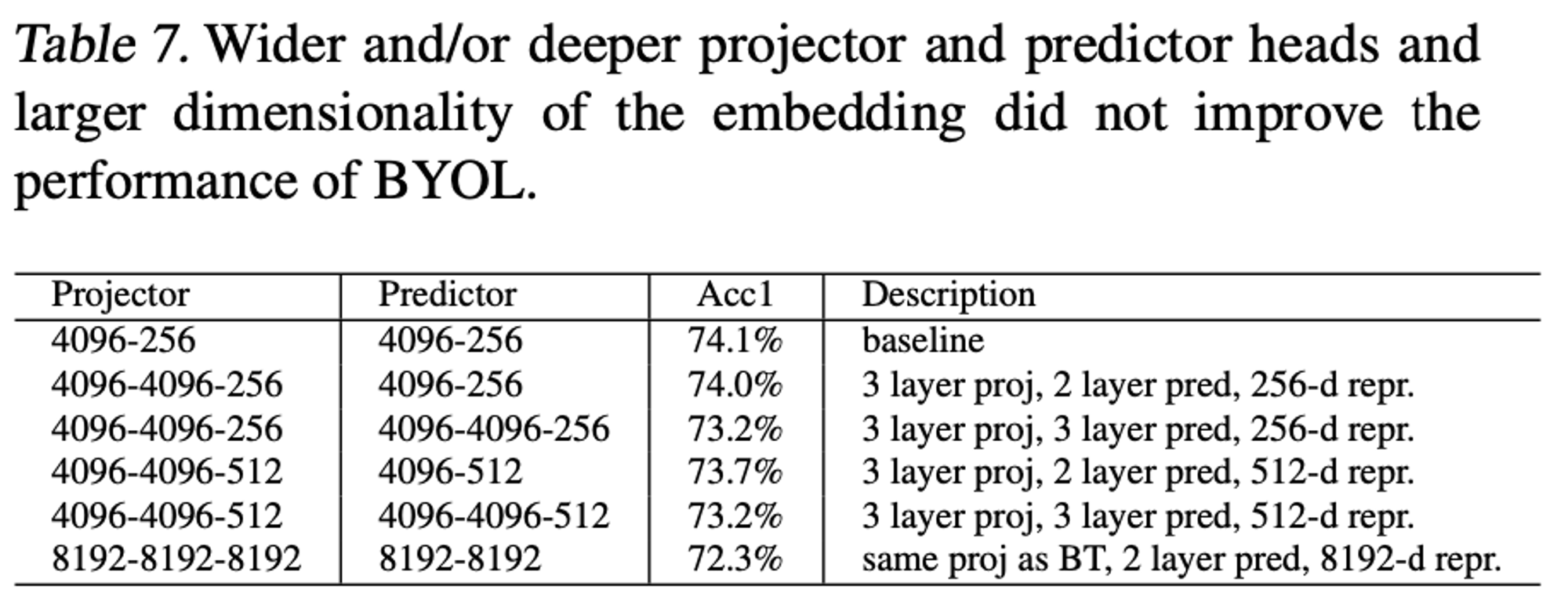
BYOL with a larger projector/predictor/embedding
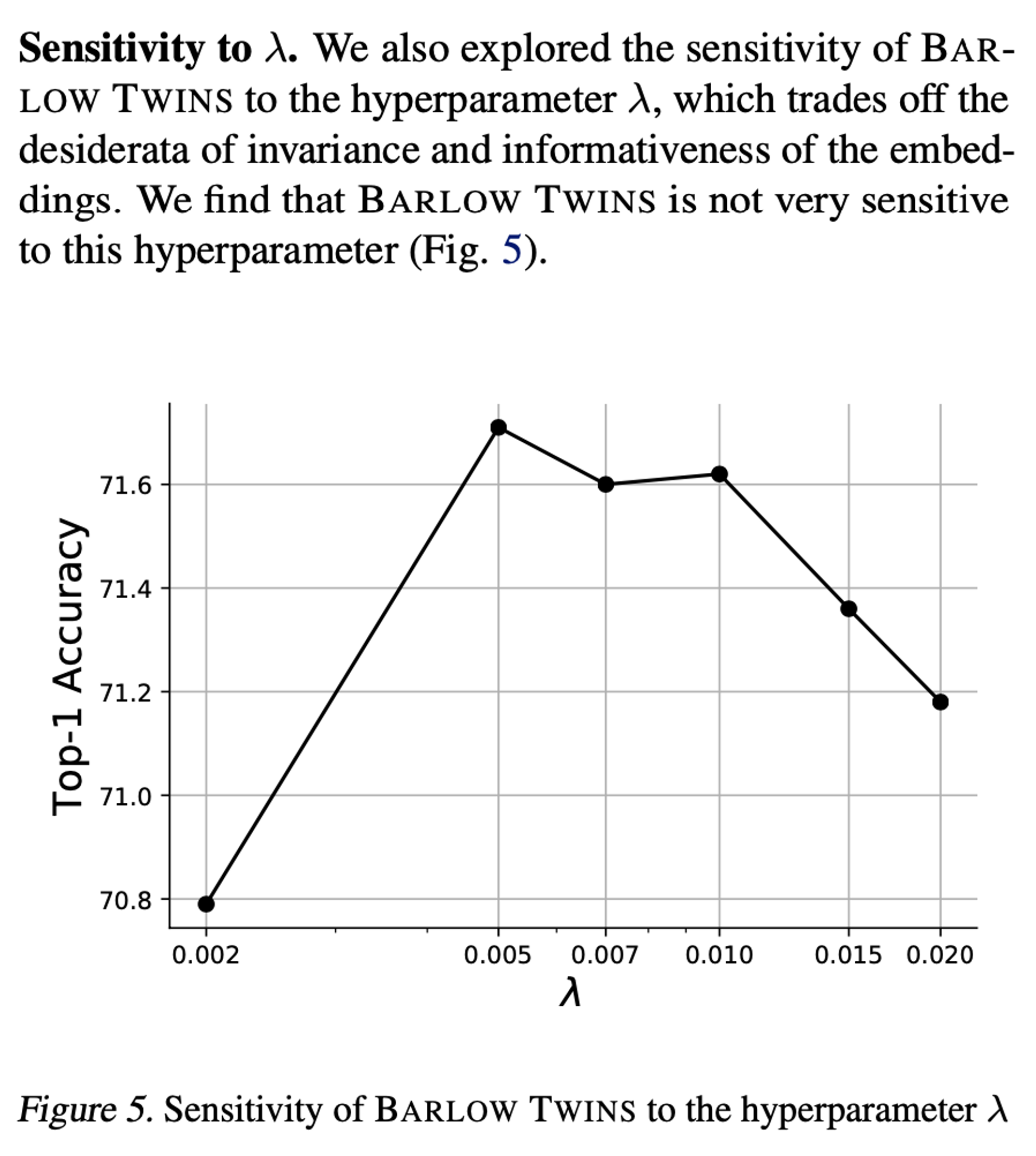
Sensitivity to
5. Discussion
5.1. Comparison with Prior Art
infoNCE
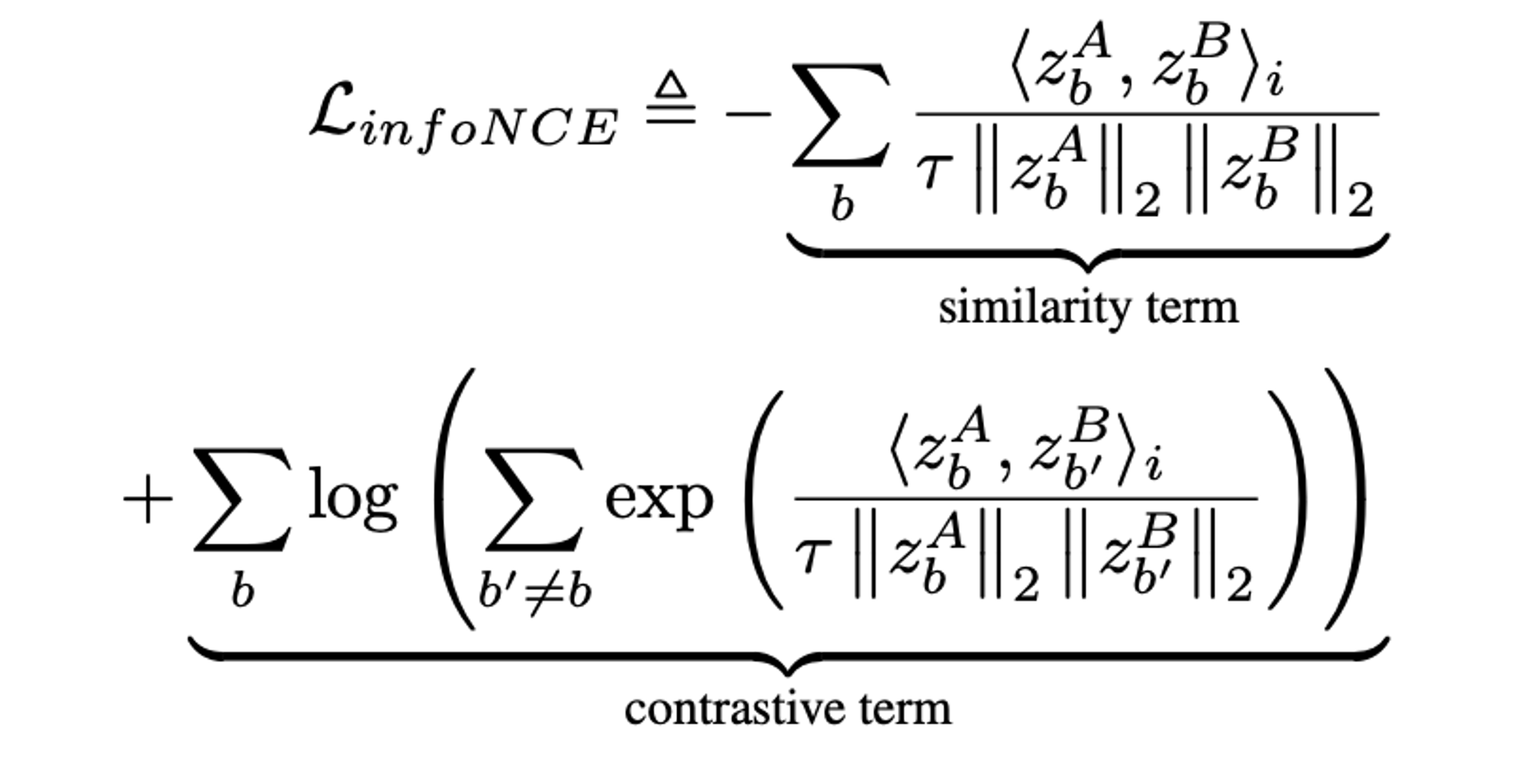
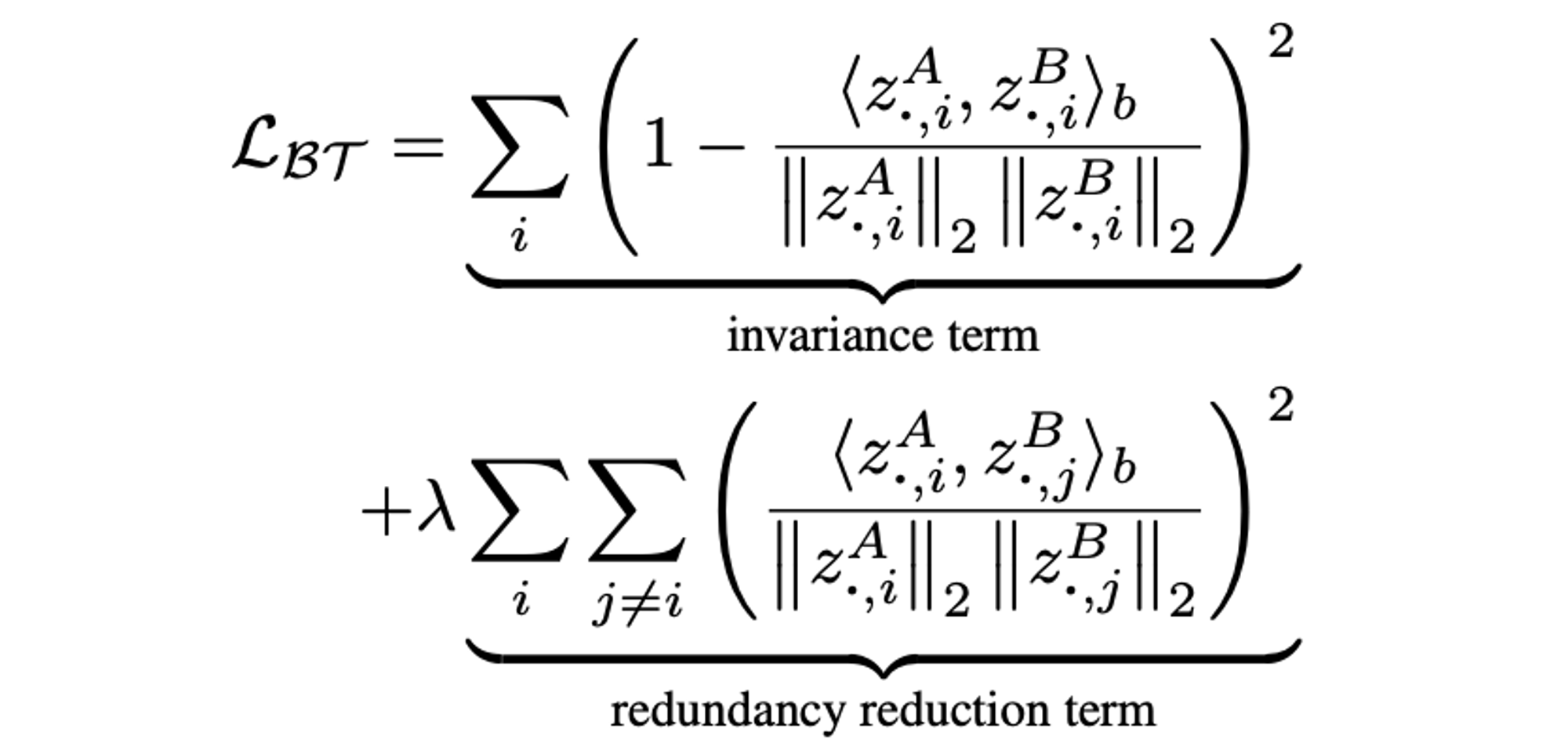
공통점
- twin network에 주어진 distortion에 invariant한 embedding을 만드는 것이 목적이다.
- embedding의 variability를 최대화하는 것을 목표로한다.
infoNCE는 pairwise distance를 계산해서 variability를 최대화하고, BT는 decorrelating을 통해 variability를 최대화한다.
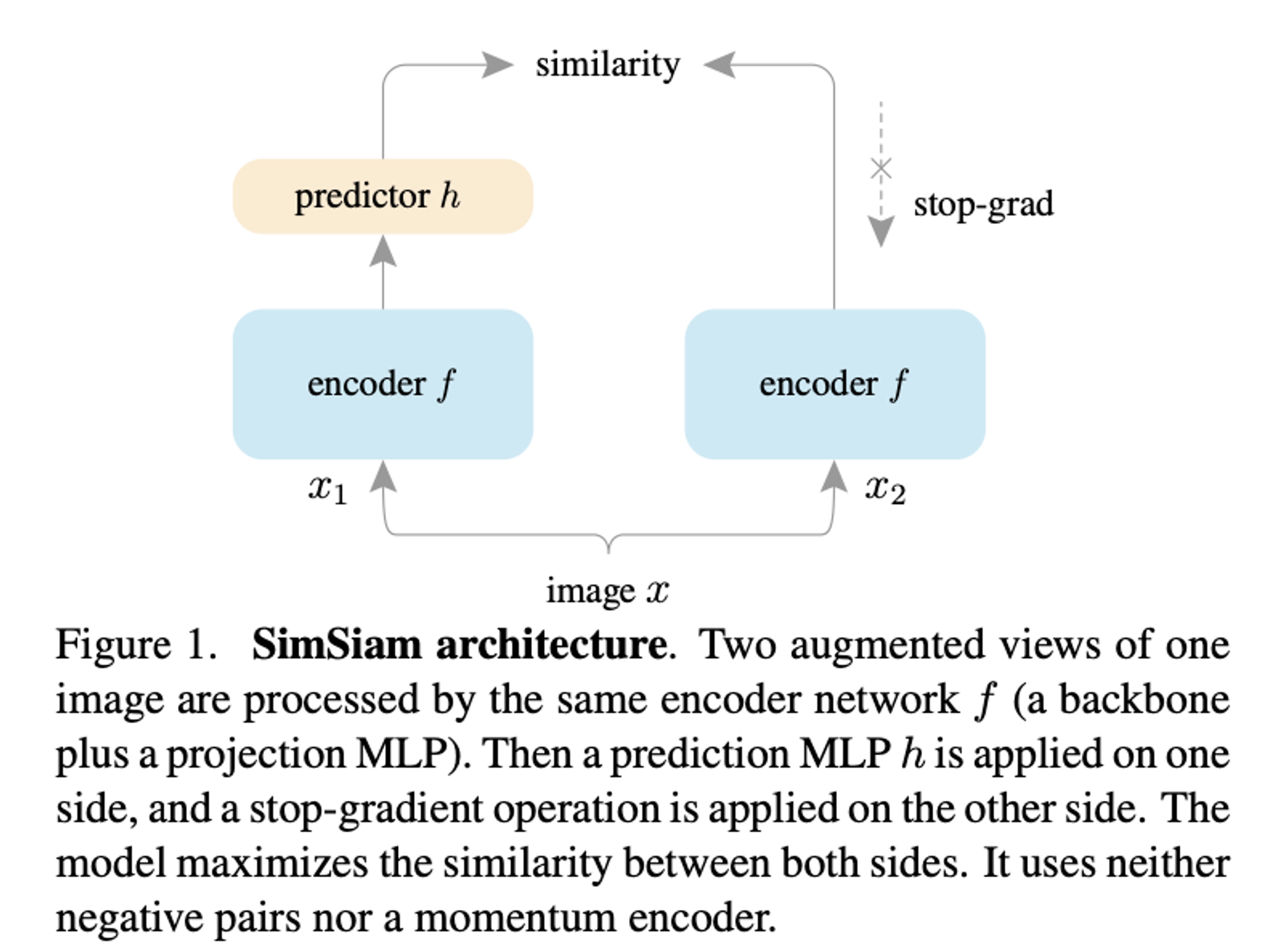
Asymmetric Twins
- SIMSIAM
- stop-gradient

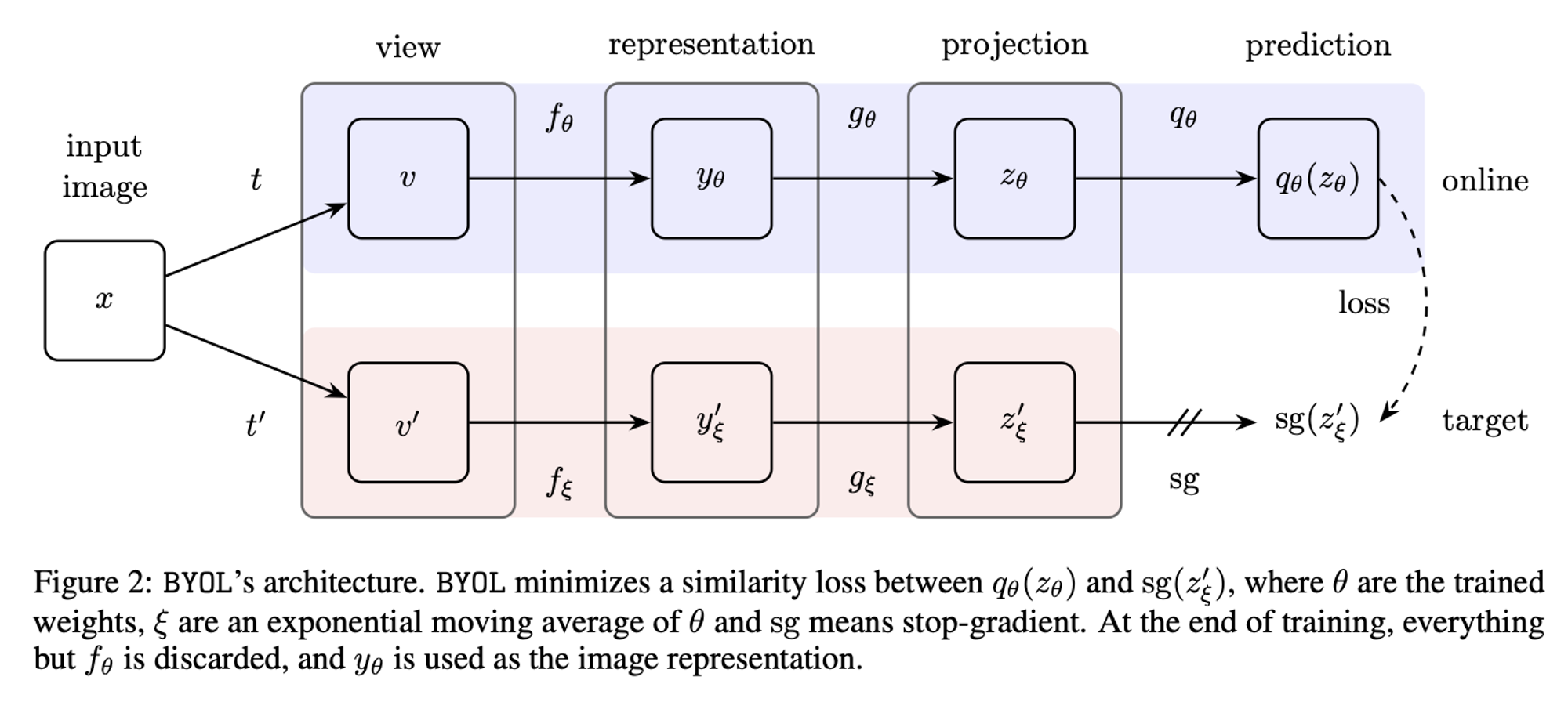
- BYOL
- moving-average
- stop-gradient
Whitening
- W-MSE
- whitening 적용 후 cosine similarity 계산
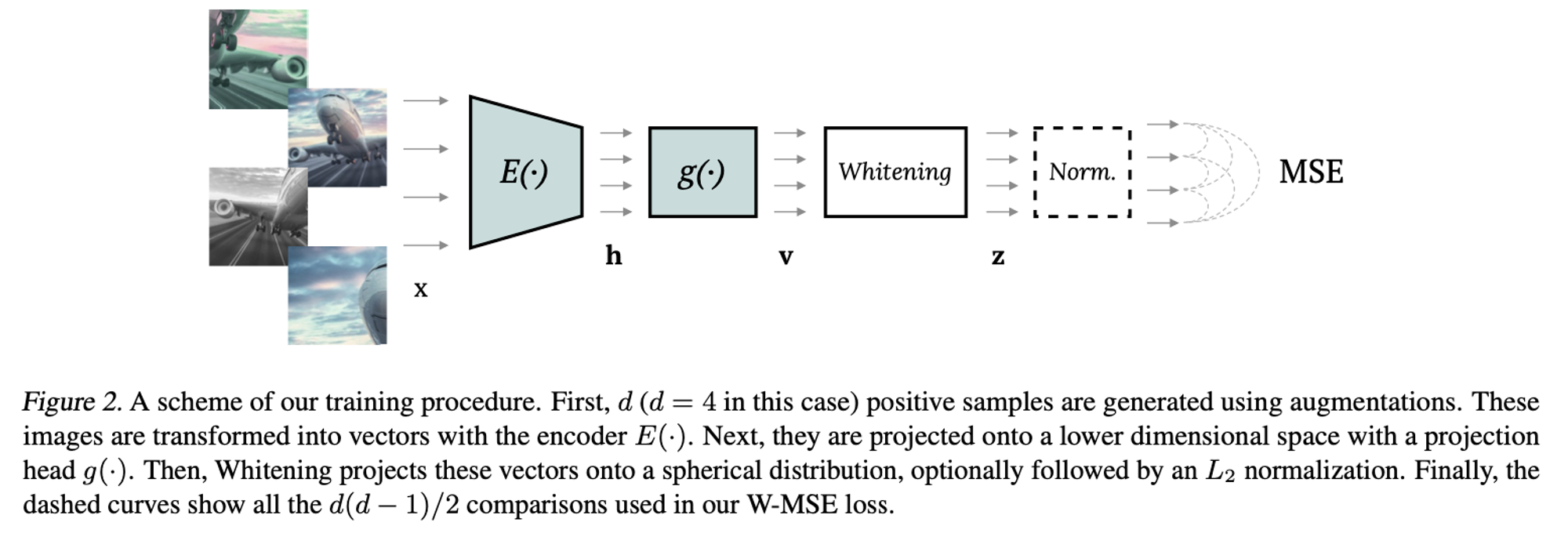

- BT의 redundancy reduction term이 whitening의 효과를 주는 soft constraint이다.
Clustering
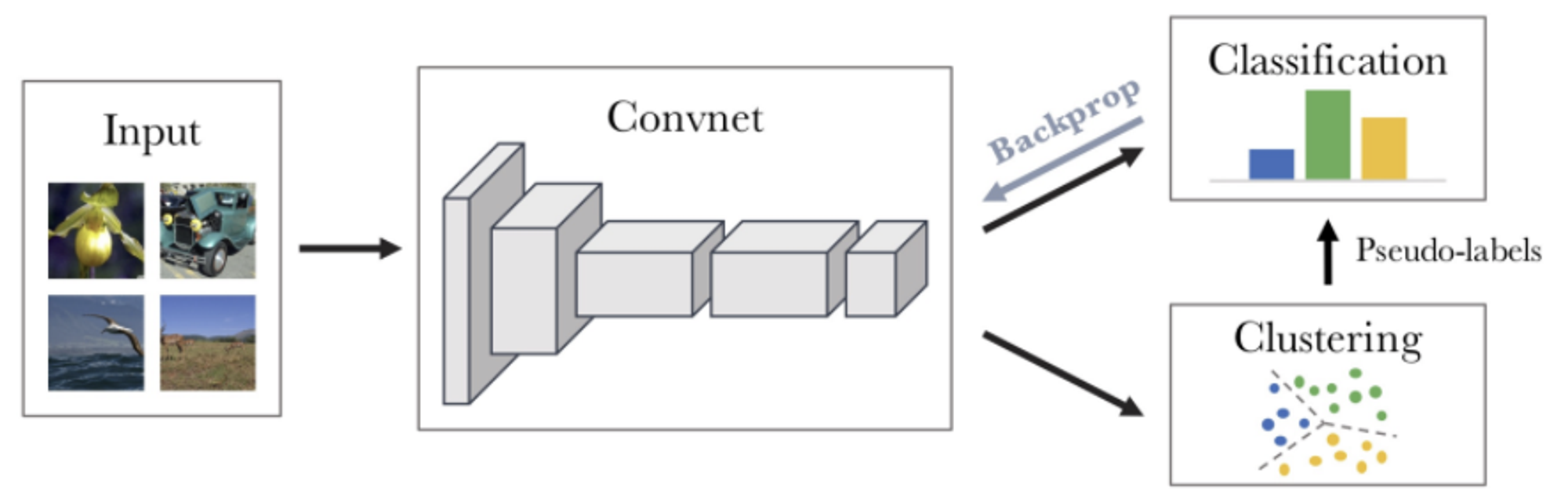
5.2. Future Directions
- twin network의 cross correlation matrix의 off-diagonal을 single network의 auto-correlation matrix로 바꿔볼 수도 있음.
- modified loss
