
1. Abstract
- Current OODD benchmarks :
- 한 데이터셋을 ID로, 나머지 데이터셋을 OOD로 특정.
- ID와 OOD 사이에 same semantic이 존재할 수 있다는 점을 고려하지 않음.
- Unrealistic
- Semantically coherent out-of-distribution detection(SC-OOD)
- 기존 방법론들의 성능이 매우 저하됨.
- Unsupervised dual grouping(UDG)
- Unlabeled data를 통한 unsupervised learning으로 semantic knowledge 학습 가능
- ID classification, OOD detection 성능 향상
2. Motivation & Introduction
Drawbacks of deep learning
- Test data distribution에 covariate shift가 있을때 성능이 매우 감소함
- Semantic shift가 있는 데이터여도(training class에 속하지 않을 수 있는) 과하게 특정 클래스로 분류하는 경향이 있음
→ 이러한 결함은 모델의 신뢰도를 심각하게 감소시키고 real world application에 적용할 수 없게 만듦.
Out-of-distribution(OOD) detection
→ 위의 결함을 해결하기 위해 OOD detection을 통해 covariate shift 혹은 semantic shifts가 존재하는 test sample을 구별하여 ID에 대해 학습된 모델이 신뢰할 수 없는 예측을 생성하지 못하게 하는 것을 목표로 함.
🚫 하지만, 현재의 OOD detection benchmarks에는 결함 존재- 서로 다른 데이터 셋이 서로 다른 data distribution을 나타낸다는 가정 하에, 현재의 benchmarks는 일반적으로 하나의 데이터셋을 ID로 정의하고 다른 모든 데이터를 OOD로 정의함.
- 하지만 서로 다른 데이터셋 간에 semantic을 공유하고 있다는 문제점이 존재함.

- Tiny-ImageNet의 15% 정도가 CIFAR-10의 ID cateories와 같은 semantics를 공유함.
- ex) Tiny-ImageNe은 6가지의 강아지 품종을 포함하는데, 이는 CIFAR-10의 'dog' 클래스와 매칭.
- 이런 경우에 dataset-dependent OOD (DD-OOD) benchmark
에서의 완벽한 성능은, 모델이 inherent semantic을 무시하면서 데이터 소스 간에 무시할 수 있는 covariate shift로 인한 low-level의 차이에 overfit하고 있음을 나타냄.
Semantically coherent out-of-distribution detection (SC-OOD)
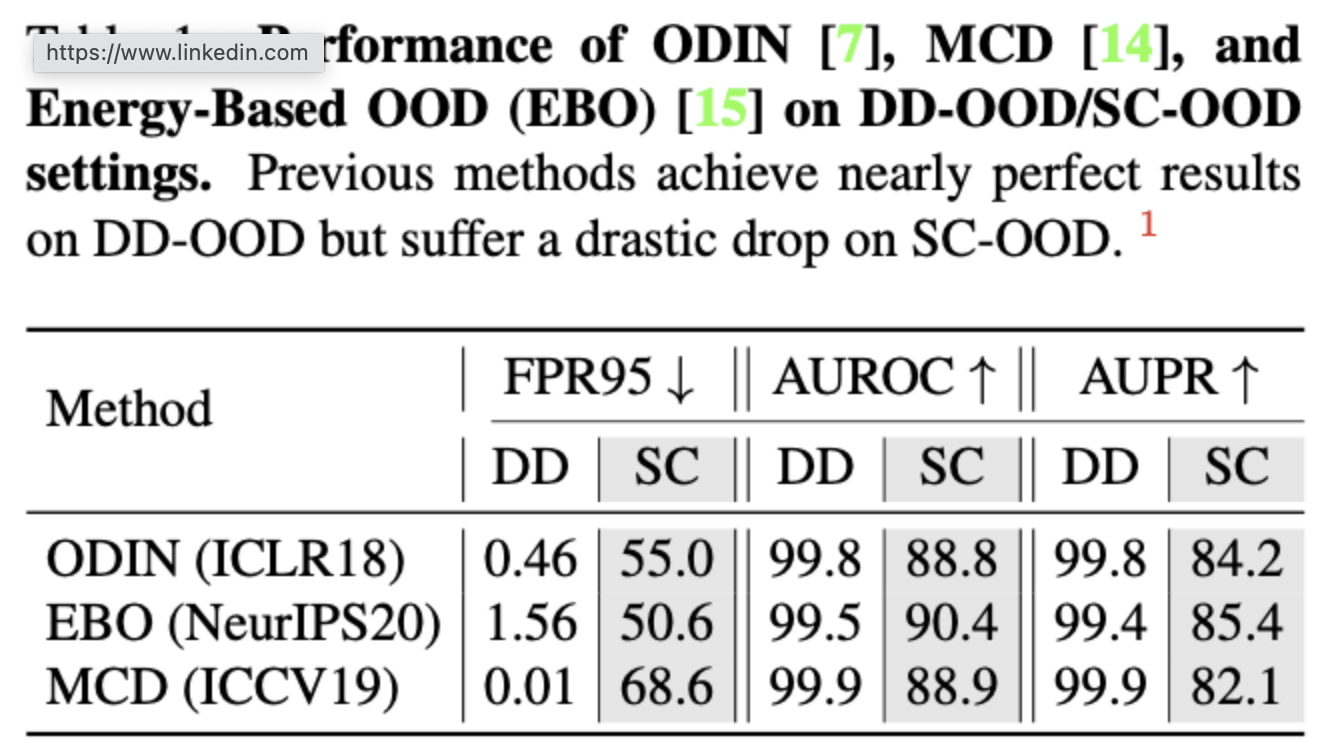
- Figure1-b처럼 ID/OOD set을 semantic 기반으로 재구성하여 실제 이미지에 초점을 맞추는 SC-OOD benchmarks를 설계함.
- 이 경우 ID는 의미적으로 일관되고 OOD와 다름.
- 이전의 OOD detection 방법론들은 SC-OOD benchmarks에서 큰 성능 저하가 있음.
Unsupervised dual grouping (UDG)
- SC-OOD benchmarks에 효과적인 방법론을 위해 OutlierExposure(OE) 사용.
- OE는 unlabeled set이 purely OOD 이지만, 본 연구에서의 unlabeled set은 ID 샘플의 일부를 포함함.
- 강력한 이미지 크롤러는 수백만개의 unlabeled data를 모을 수 있지만, 정제하는데 비용이 많이 드는 ID 샘플을 가지고 있을 수 밖에 없기 때문에 이러한 세팅이 realistic setting.
- UDG는 unsupervised deep clustering task를 이용하여 unlabeled data를 탐색함으로써 모델의 semantic expression 능력을 향상 시키고, grouping information 또한 unlabeled set에서 ID와 OOD를 분리 할 수 있음.
- Unlabeled set에서 분리된 ID는 classifier 학습을 위해 다른 ID 샘플들과 같이 학습되고, OOD는 OE방법론과 같이 uniform posterior distribution을 생성하도록 학습함으로써 ID와 OOD 성능을 향상 시킴.
Contributions
- 현재 OOD detection benchmarks의 문제점을 지적하고 redesign함.
- 현실적인 unlabeled data를 이용한 간결한 framework를 제안하고, unsupervised 방식으로 모델의 semantic knowledge를 향상시키고, ID 분류와 OOD detection을 동시에 강화함.
- State-of-the-art 성능을 달성함.
3. Approach
3.1 Problem Statement
-
Training set :
-
Testing set :
-
In-distribution :
-
Subscript : labeled
-
: fully-labeled training set
-
Out-distribution :
Closed-world assuption : training and test data are from in-distribution
의 샘플은 의 라벨인 knwon classes 에 속함.
realistic setting : test data가 out-distribution의 unknown classes를 포함.
and
학습된 모델은 를 로 정확히 분류하면서도 의 ood samples도 인식해야함.
이를 위해 unlabeled dataset 도입.
real-world에서 는 와 의 mixture임.
- Goal : training set 로 classifier를 학습하고, 모델이 를 reject하면서도 를 정확히 분류하는 것.
3.2 Framework
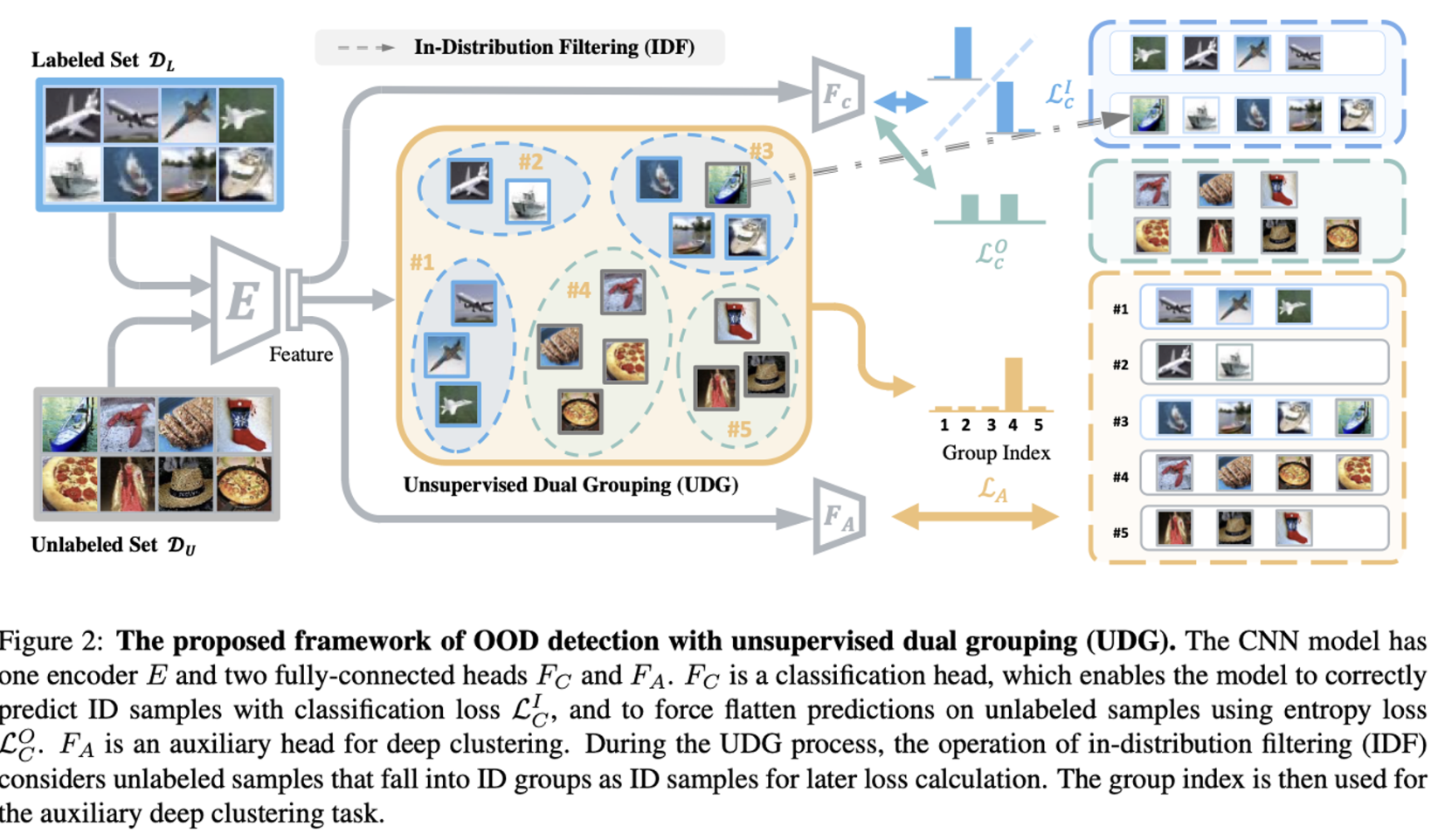
Main Task : Classification and Entropy Loss
Encoder with learnable parameter
Classification head with with learnable parameter
- Cross-entropy loss using for ID classification
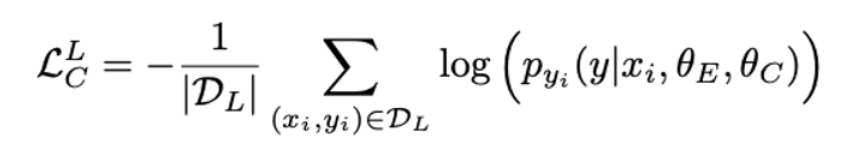
- Cross-entropy loss using to produce a uniform posterior distribution
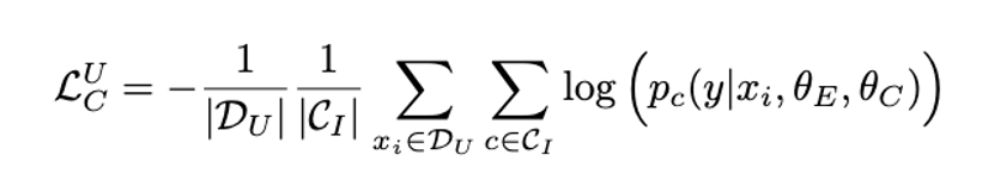
Unsupervised Dual Grouping (UDG)
- 이상적으로는, unlabeled datset에 있는 ID sample은 uniform posterior distribution으로 학습되는게 아니라 ID 데이터와 같이 학습되어야하고 unlabeled ood sample만 uniform distribution으로 학습되어야 함.
- Deep clustering을 통해 unlabeled data knowledge exploration
Basic Operations
- 매 에폭에 전체 training set 를 개의 그룹으로 나눔.
- t번째 에폭에서, 인코더 (denoted as )가 전체 training sample의 feature를 뽑아서 feature set 를 구성.
- k-means clustering을 사용하여 grouping
- 는 모든 샘플의 group index를 복원하고 는 t번째 에폭에서의 샘플 의 group index를 나타냄.
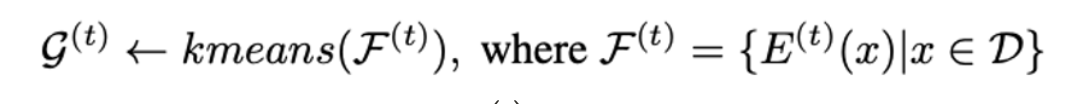
- 모든 샘플은 K개의 그룹중 하나에 속해야한다. 는 t번째 에폭에서 k번째 그룹에 속하는 모든 샘플의 집합을 나타냄.
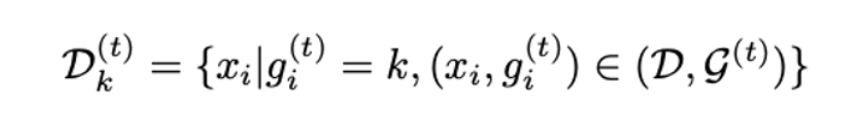
In-Distribution Filtering (IDF) with UDG
- 경험적으로, labeled class가 우위를 차지하는 그룹의 경우 그룹의 unlabeled data는 해당 카테고리에 속할 가능성이 큼.
- 그룹 에 대해, t 에폭에서 클래스 c에 속하는 샘플의 비율을 보이기 위해 group purity 를 정의함.
- 는 클래스 c의 모든 labeled samples
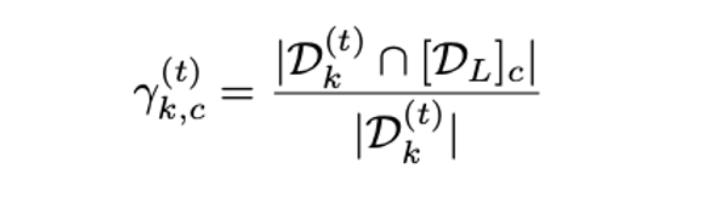
- group purity가 준비되면 IDF operator는 threshold 를 넘는 group purity를 가진 그룹의 모든 unlabeled sample을 그룹의 과반수와 동일한 label로 labeled set에 반환함.
- 매 에폭마다 labeled set은 , unlabeled set은 로 업데이트됨.
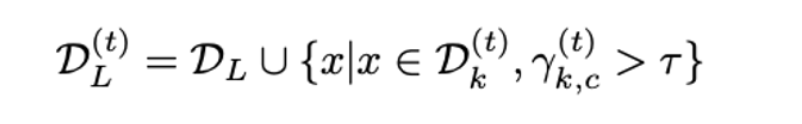
- Classification loss and entopy loss
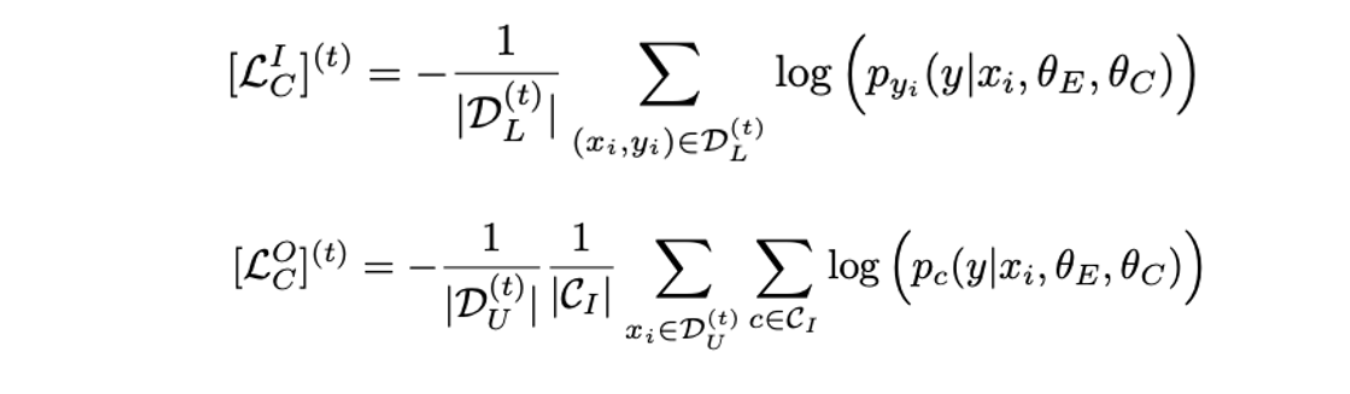
Auxiliary Task for UDG
- Unlabeled set의 knowledge를 완전히 사용하기 위해 auxiliary task 수행.
- Learned semantics는 모델의 성능, 특히 ID classification에 도움이 될 것.
- 같은 그룹에 있는 샘플을 같은 카테고리로 분류하도록 학습하는 Deep clustering 기법 사용.
- 샘플이 속하는 그룹으로 분류하는 fc auxiliary head with learnable parameter 를 학습시킴.
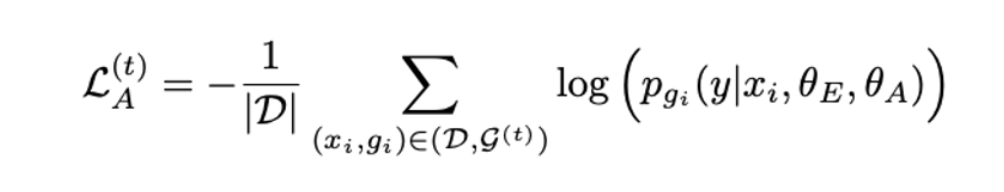
3.3 Training and Testing Process
- Training
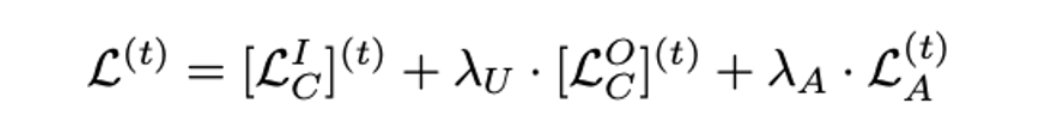
- Testing
- backbone encoder 와 classification head 만 사용.
- maximum prediction이 pre-defined threshold 를 넘을 때만 in-distribution prediction. otherwise, OOD 샘플로 간주
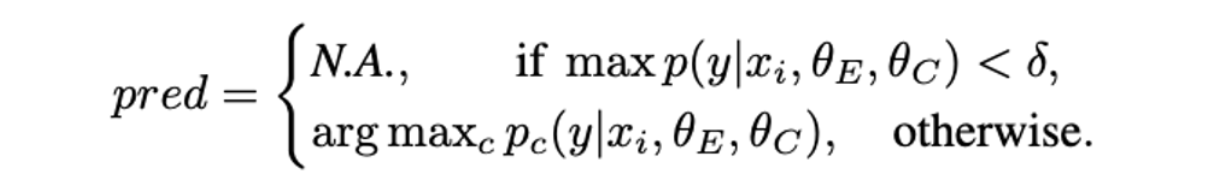
4. SC-OOD Benchmarks
- In-distribution : CIFAR-10/100
- OOD datasets : Texture, SVHN, Tiny-ImageNet, LSUN, Places365
- 와 re-split

- OOD 데이터셋에서 ID 클래스를 선택하고, 선택된 클래스 내의 모든 이미지를 ID samples로 표시
- 다른 OOD 카테고리의 이미지에도 ID의 semantic이 포함되어 있기 때문에 fine-grained filtering
4.1 Benchmark for CIFAR-10
- CIFAR-10 : 50,000 training samples and 10,000 testing samples from 10 object classes
- Test set
- 모든 CIFAR-10 test set 10,000 as
- 모든 Texture set 5,640개 as
- 모든 SVHN test set 26,032개 as
- 모든 CIFAR-100 test set 10,000개 as
- Tiny-ImageNet test set의 200클래스 10,000개 이미지 중 1,207개는 8,793개는
- LSUN test set 10,000개 이미지 중 2개 9,998개는
- Places365 test set 36,500에서 1,305개는 35,195개는
4.2 Benchmark for CIFAR-100
- : in-distribution test set
- : out-distribution test set
- 모든 CIFAR-100 test set 10,000 as
- 모든 Texture set 5,640개 as
- 모든 SVHN test set 26,032개 as
- 모든 CIFAR-100 test set 10,000개 as
- Tiny-ImageNet test set의 200클래스 10,000개 이미지 중 2,502개는 7,498개는
- LSUN test set 10,000개 이미지 중 2,429개 7,571개는
- Places365 test set 36,500에서 2,727개는 33,773개는
5. Experiments
Implementation Details
- ResNet-18
- SGD with weight decay of 0.0005 and momentum of 0.9
- in-distribution batch 128, out-distribution batch 256
- 100epochs
- ,
5.1 Ablation Study
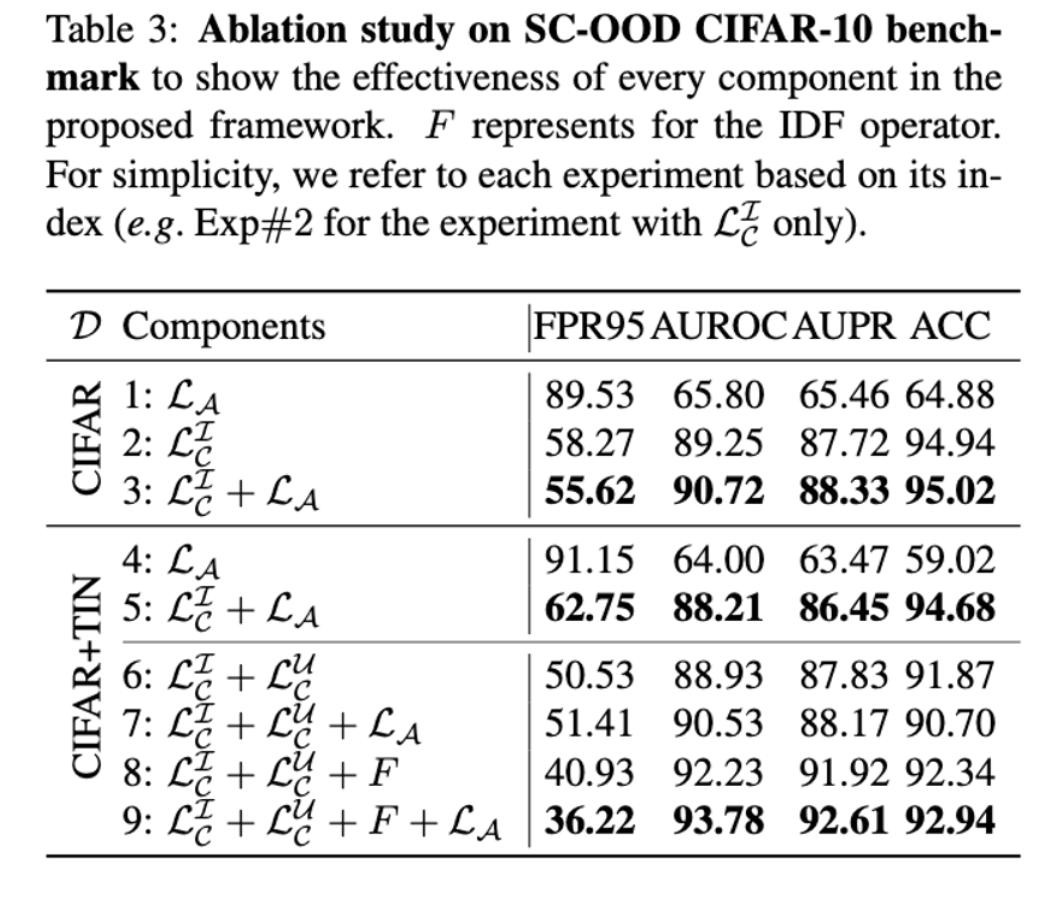
Effectiveness of Unlabeled Data
-
Exp#2(standard classification) vs Exp#6(OE)
-
OE에서 FPR 7.74% 향상
-
Unlabeled data 사용하면 OOD detection 성능이 크게 향상됨
-
ACC가 94.94%에서 91.87%로 하락
-
realistic setting을 위해 ID와 OOD가 섞인 unlabeled set을 사용했기 때문에 unlabeled ID 데이터로 인해 classification performance가 낮아짐
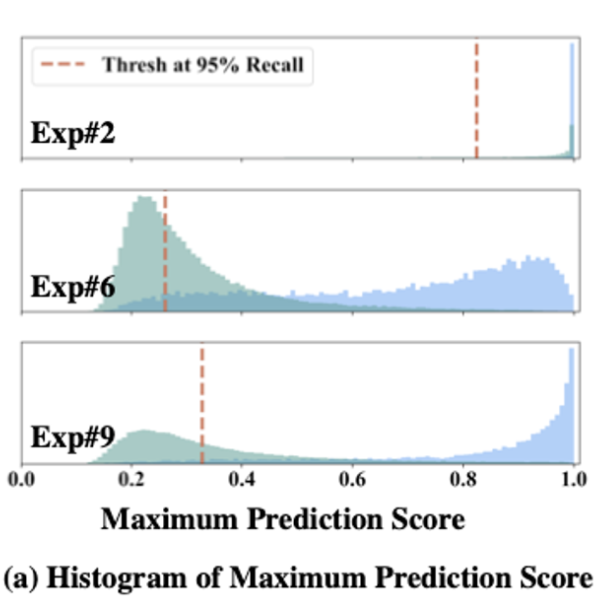
- green : out-dist, blue : in-dist
-
Analysis of Unsupervised Dual Grouping
- Exp#1 vs Exp#4
- ID/OOD를 모른채 deep clustering을 하면 ID/OOD 샘플들을 하나의 클러스터로 grouping할 가능성이 높고, 이는 OOD detection 성능에 안좋은 영향을 끼침.
- Exp#2 vs Exp#3, Exp#3 vs Exp#5 를 보면 OOD-mixed unlabeled dataset가 있을 때 deep clustering에서 성능하락이 있음.
Effectiveness of In-Distriution Filtering
- Unlabeled set의 ID 샘플들을 학습에 추가함으로써 ID classification 성능 향상
- Unlabeled ID/OOD set에서 ID를 걸러내어 pure OOD set을 구성하고자 함.
- Exp#6 vs Exp#8에서 filtering의 효과 확인.
- Filtering을 통해 clean ID/OOD 를 얻음으로써 Exp#9에서의 auxiliary loss로 인한 benefit.
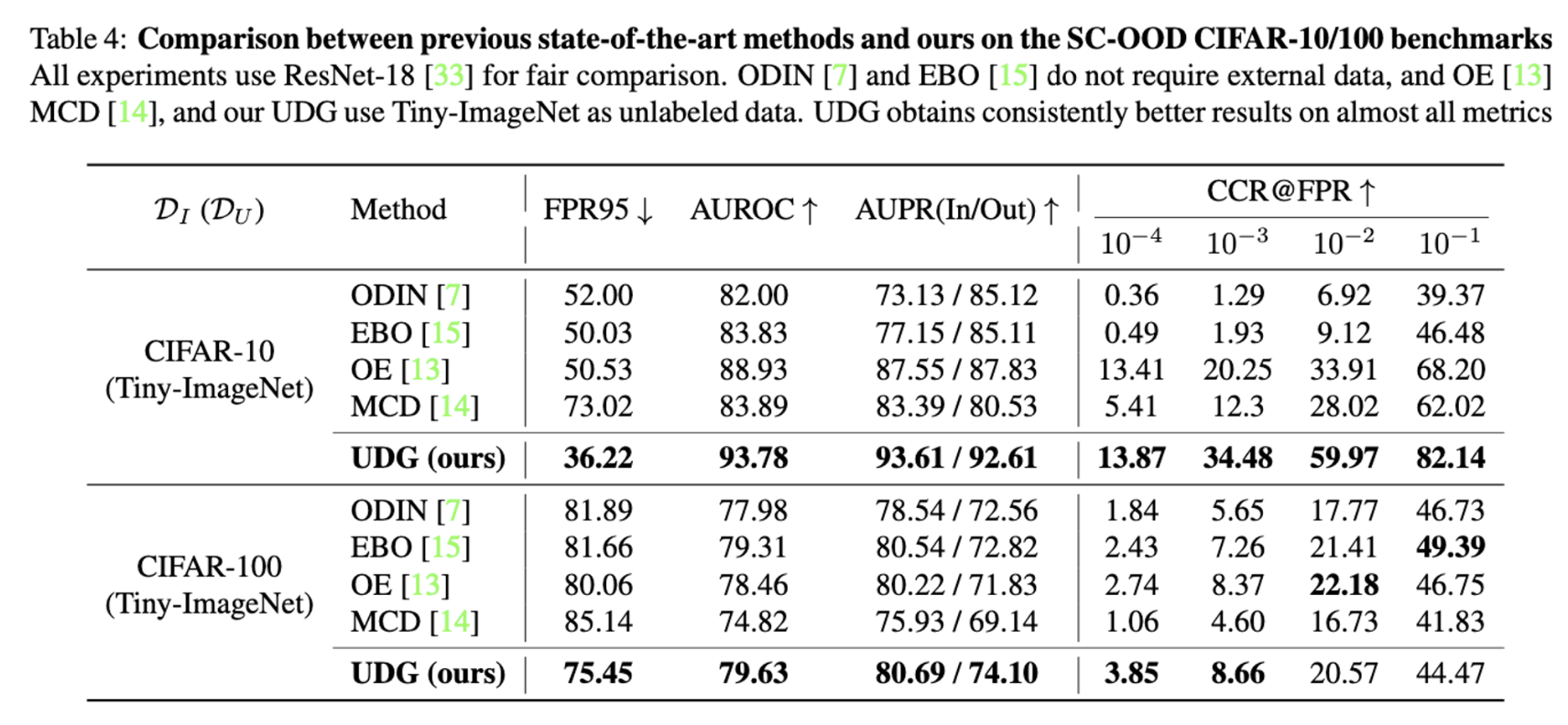
5.2 Benchmarking Results
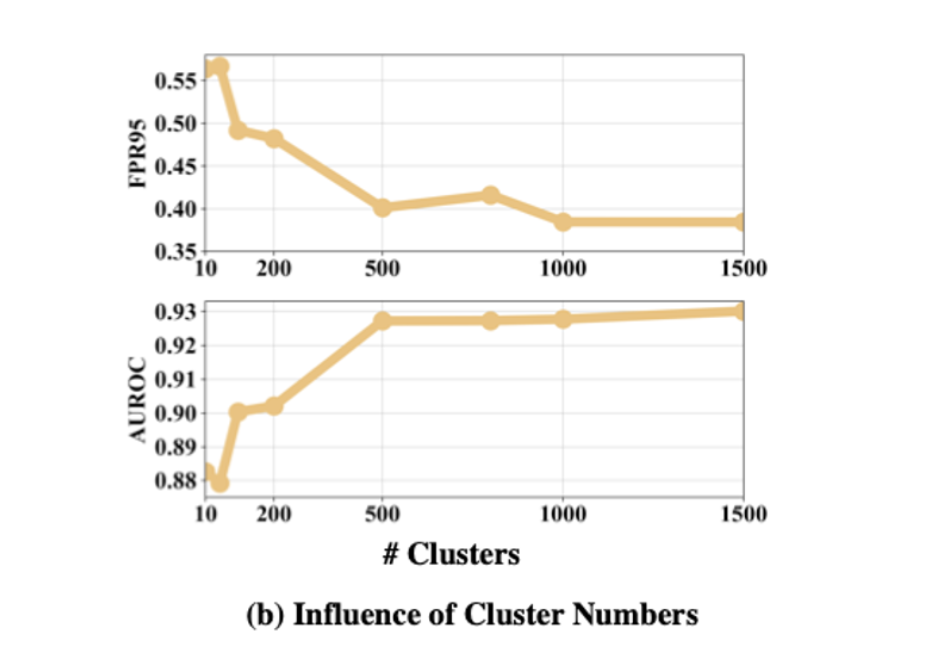
5.3 Further analysis
Influence of Cluster Numbers
The Design Choice of IDF
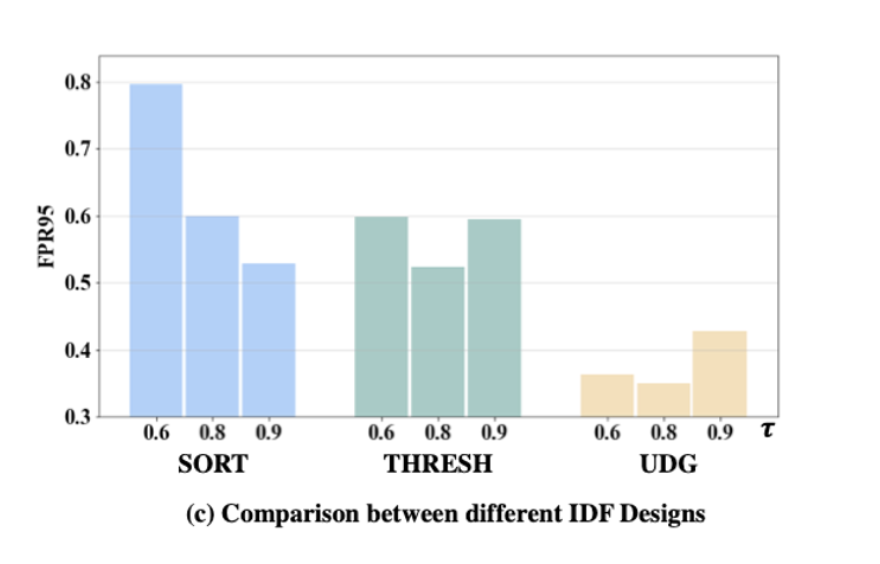
- THRESH : MSP가 threshold 를 초과할 경우 fitering
- SORT : unlabeled sample중 MSP가 top 인 샘플을 새로운 ID 샘플로 포함
- UDG : unlabeled sample을 그룹하고 ID purity가 를 초과할 경우 ID 샘플로 포함
6. Conclusion
- 현재 OOD detection 벤치마크의 문제점을 지적하고 realistic한 SC-OOD 벤치마크 디자인
- State-of-the art method UDG제안
