[논문 리뷰 | RC] Hybrid Recommender Systems - A Systematic Literature Review (2019) Summary
[논문리뷰]
Title
- Hybrid Recommender Systems - A Systematic Literature Review (2019)

Abstract
- 하이브리드 추천 시스템은 두 가지 이상의 추천 전략을 서로 다른 방식으로 결합하여 상호 보완적인 이점을 활용한다.
- 이 논문은 2009-2019년까지의 약 10년 간의 하이브리드 추천 시스템의 최신 기술을 제시한다.
- 대부분의 연구는 협업 필터링과 다른 기술을 적절히 가중치를 주는 방식으로 결합하는 경우가 많다.
- 콜드 스타트와 데이터 희소성은 추천 시스템에서의 가장 큰 문제점이며, 영화 dataset은 여전히 많이 사용되고 있다.
- contextualizing recommendations와 parallel hybrid algorithms, 대규모 dataset 처리 등 다양한 하이브리드 추천 방식을 소개한다.
1. Introduction
- 추천시스템이란 사용자에게 항목 및 기타 추천 가능한 개체에 대한 제안을 제공하는 데 사용되는 소프트웨어 도구 및 기술로 정의된다.
- 또한, 비즈니스의 수익 증대를 위한 영업 도우미 역할도 하며 상품과 서비스를 검색하는 데 도움을 준다.
- 2006년부터 2011년까지 conputer science와 information systems conferences 논문집과 저널에 발표된 330편의 논문을 검토했고, 하이브리드 추천 시스템이 검토한 문헌의 약 14.5%에서 연구 대상이 된 것으로 나타났다.
- 기술적으로, Content-Based Filtering (CBF), Collaborative Filtering (CF), Demographic Filtering (DF), Knowledge-Based Filtering (KBF) 등이 있다.
1) Collaborative Filtering (CF)
- 협업필터링이라고 하며, 과거에 비슷한 취향을 가졌던 사람들이 미래에도 비슷한 취향을 가질 것이라는 것이 CF의 기본 가정이다.
- 평점 또는 사용사 생성 피드백을 사용하여 사용자 그룹 간의 취향 공통점을 파악한 뒤 사용자 간 유사성을 기반으로 추천해준다.
- 하지만 cold-start(신규 사용자)와 gray sheep(취향 클러스터에 속하지 않는 사용자)와 같은 문제점이 있다.
2) Content-Based Filtering (CBF)
- 콘텐츠필터링이라고 하며, 과거에 특정 속성을 가진 아이템을 좋아했던 사람들이 미래에도 같은 종류의 아이템을 좋아할 것이라는 것이 CBF의 기본 가정이다.
- 아이템 features를 사용하여 아이템과 유저 프로필과 비교하고 추천해준다.
- 사용자가 단 한 번도 특정 키워드가 있는 아이템을 이용한 적이 없다면 그런 아이템을 추천하지 않는다. 즉, 다양성이 줄어든다는 단점이 있다.
- CF와 마찬가지로 CBF도 cold-start(신규 사용자) 문제를 겪는다.
3) Demographic Filtering (DF)
- 인구 통계학적 필터링이라고 하며, 연령, 성별, 학력 등과 같은 인구통계학적 데이터를 사용하여 사용자 범주를 식별한다.
- 평점을 사용하지 않기 때문에 cold-start 문제가 발생하지 않는다.
- 현재 온라인 개인정보 보호법으로 인해 데이터를 구하기 어려운 문제점이 있다.
- 독단적으로 사용되지 않고, 다른 추천기법과 결합돼서 사용된다.
4) Knowledge-Based Filtering (KBF)
- 지식 기반 필터링이라고 하며, 사용자와 아이템에 대한 지식을 사용하여 어떤 아이템이 사용자의 요구 사항을 충족하는지 추론하고 그에 따라 추천한다.
- 특수한 유형의 constraint-based 추천기법으로 거의 구매하지 않는 복잡한 품목(ex. 자동차 or 주택)을 추천할 수 있고 사용자에게 중요한 제약 조건(가격)을 나타낼 수 있다.
- 사용자 - 시스템 상호작용 데이터가 거의 존재하지 않기 때문에(왜냐면 사람들은 집을 계속 구매하지 않기 때문) CF or CBF를 사용할 수 없다.
2. Methodology

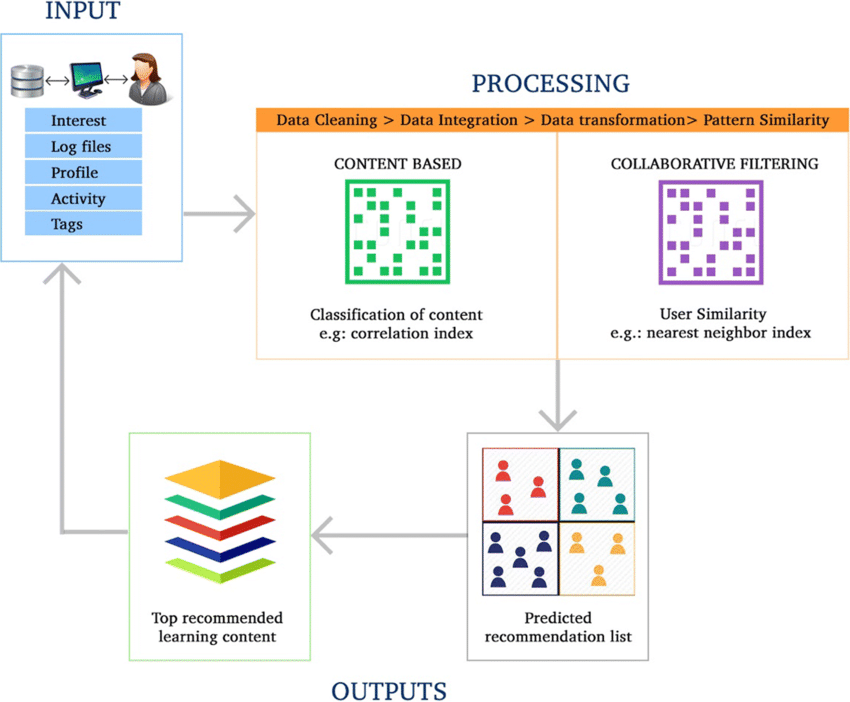
- 이 챕터에서는 방법론, 정의된 목표와 연구 질문, 논문 선정 및 품질 평가 프로세스를 간략하게 요약하였다.
- 위의 그림의 순서와 같이 설명하고자 한다.
2.1 Research questions search string and digital sources
문헌 검토의 주요 목표는 하이브리드 추천시스템에 대해 이해하는 것이다. 이를 위해 다음과 같은 연구 질문을 정의하였다.
- RQ1
: 하이브리드 추천 시스템을 다루는 가장 관련성이 높은 연구는 무엇인가?
- RQ2
: 이 분야의 연구자들은 어떤 문제와 도전에 직면해 있나?
- RQ3a
: 하이브리드 추천시스템에는 어떤 데이터 마이닝 및 머신러닝 기술이 사용되나?
- RQ3b
: 어떤 추천 기법이 결합되며 어떤 문제를 해결하나?
- RQ4
: Burke의 분류법에 따라 어떤 하이브리드화 클래스가 사용되나?
- RQ5
: 하이브리드 추천은 어떤 도메인에 적용되나?
- RQ6a
: 평가에는 어떤 방법론이 사용되고 어떤 지표를 사용하나?
- RQ6b
: 어떤 추천시스템 특성을 평가하고 어떤 지표를 사용하나?
- RQ6c
: 하이브리드 추천시스템 훈련 및 테스트에는 어떤 데이터 셋이 사용되나?
- RQ7
: 향후 연구에 가장 유망한 방향은?
2.2 Selection of papers
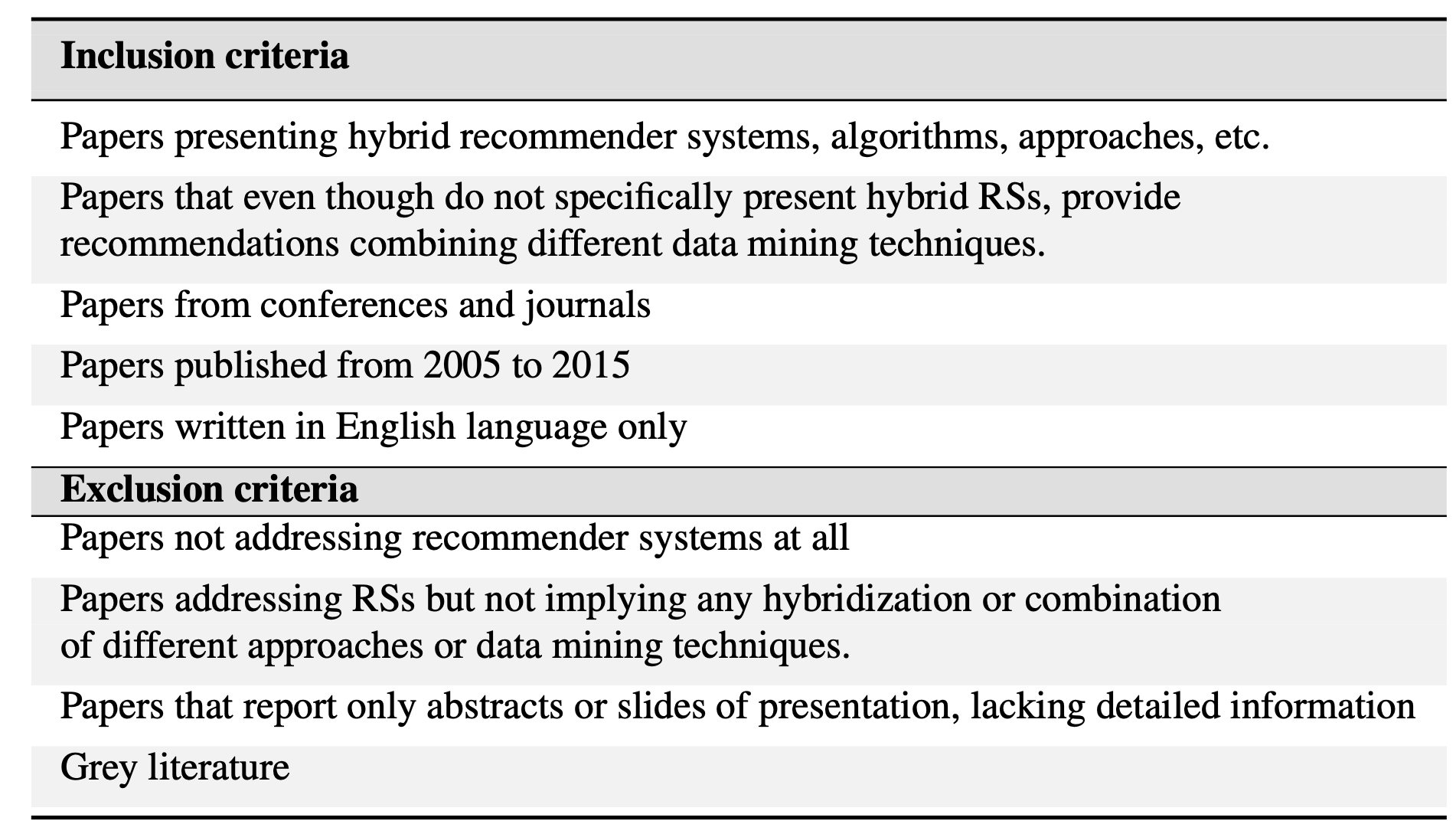
- 위와 같이 포함 / 제외 기준에 따라 논문을 선택하였다.
- 2005년부터 2015년까지 발표한 논문이며 컨퍼런스 및 저널의 논문이고, 하이브리드 추천 시스템을 다루는 논문만을 선택하였다.
- 단일 추천 전략을 다루는 논문을 제외하고 혼합 or 결합된 추천시스템을 제시하는 논문을 선택하였다.
2.3 Quality assessment
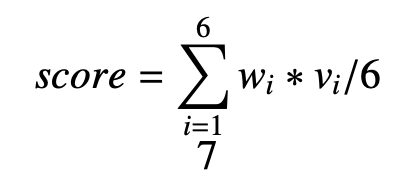
- 품질 평가 및 점수에 관한 내용이며 위의 수식을 사용하여 가중치를 부여하기로 한다.
2.4 Data extraction
- 논문 메타데이터(저자, 제목, 연도 등) 와 콘텐츠 데이터(문제, 응용 분야 등 연구 질문에 답하는 데 중요함)를 모두 수집하였다.
2.5 Synthesis
- 합성 단계에서는 주제별 합성을 위해 Cruzes와 Dyba 방법론을 따랐다.
3. Results
- 이 챕터에서는 위에서 정의한 연구 질문에 답하기 위해 연구에서 찾은 결과를 제시한다. 하나하나 자세하게 설명해보겠다.
3.1 RQ1: Included studies
- 주제: 하이브리드 추천 시스템을 다루는 가장 관련성이 높은 연구는 무엇인가?
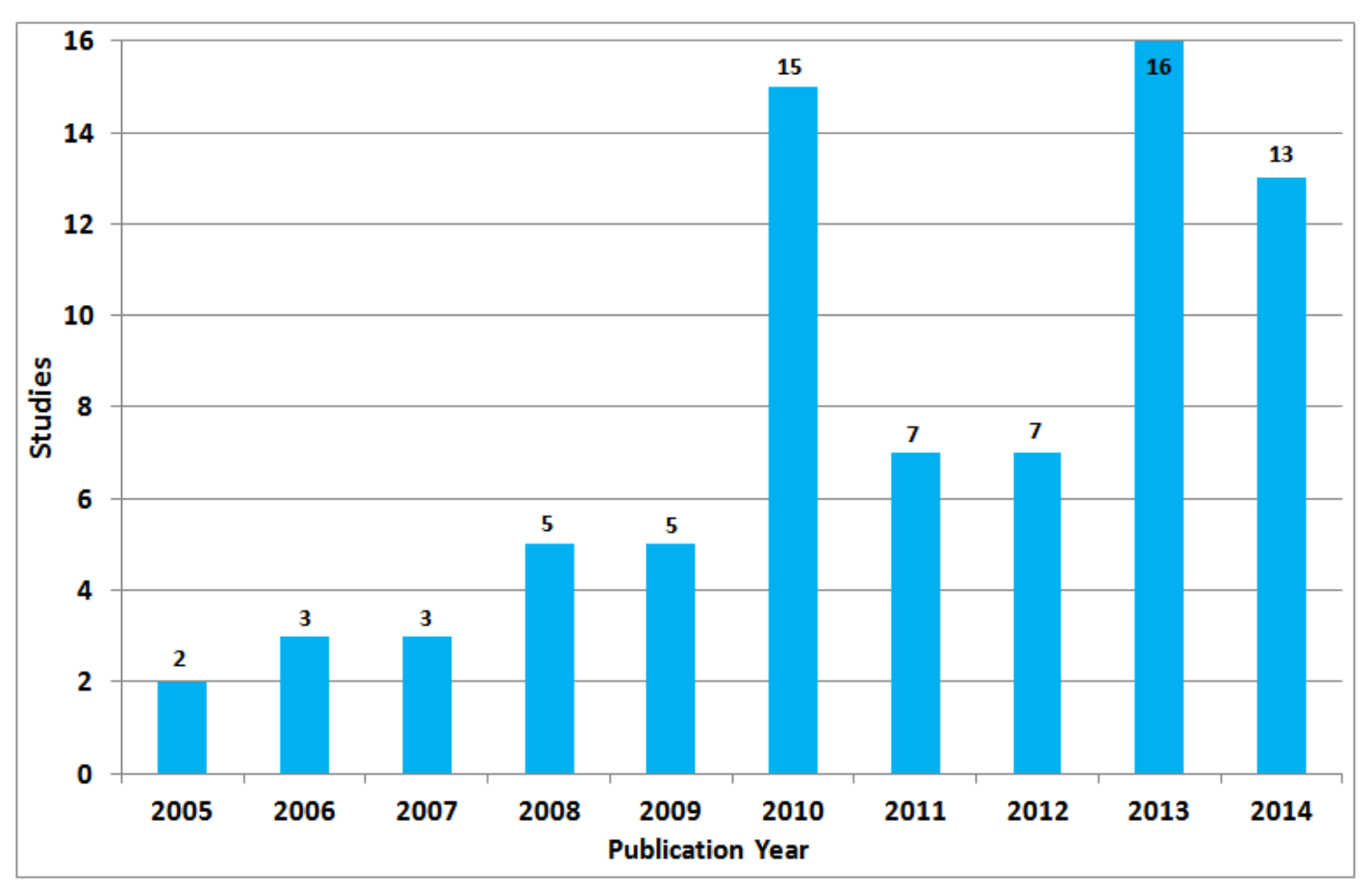
- 위의 논문들은 2005년부터 2015년까지 학회 발표 자료 및 저널에 기재되어 있는 것들을 시각화한 것이다.
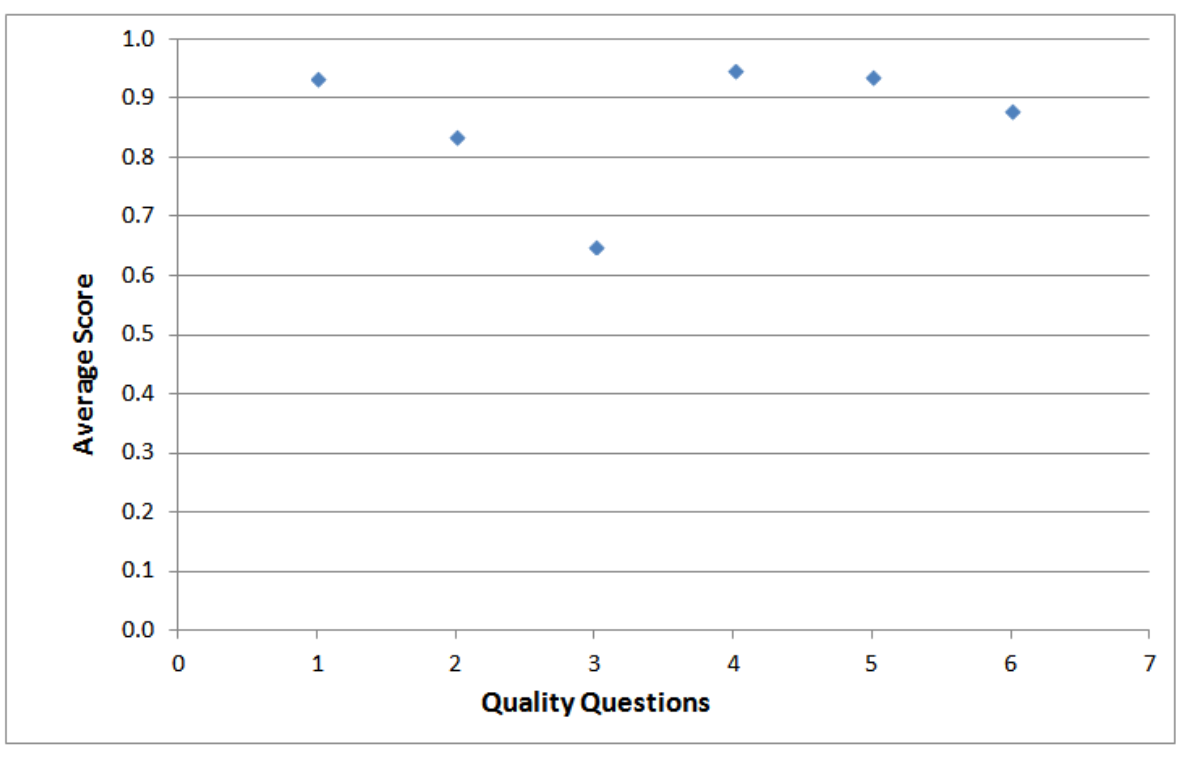
- 주로 QQ4(연구에서 제안된 시스템의 구성 요소 또는 아키텍처를 설명했습니까?) 라는 질문이 평균 점수가 0.947로 가장 높았다.
- QQ3(연구에서 추가 연구를 제안했습니까?)이 0.651로 가장 점수가 낮았다.
- 그 동안의 하이브리드 추천시스템 연구에서는 아키텍처 또는 시스템의 구성요소는 잘 설명 되었지만, 추가 연구 제안에 대해서는 잘 설명 하지 않는 것으로 보인다.
- 감히 추측해보자면, 하이브리드 추천시스템이 CF와 CBF의 결함을 잘 메꿔줬기 때문이지 않을까 싶다.
3.2 RQ2: Research problems
- 주제: 이 분야의 연구자들은 어떤 문제와 도전에 직면해 있나?

1. Cold-start
- 사용자의 성향을 알기 위해 구매 이력과 같은 정보가 필요한데, 이 정보가 없을 때 예측이 어려워지는 것을 콜드 스타트 문제라고 한다.
- 즉, 신규 사용자의 경우 시스템에 대한 선호도가 없고, 신규 아이템의 경우 해당 아이템에 대한 평점이 없으므로 추천하기 어렵다는 것이다.
2. Data sparsity
- 데이터 희소성 문제로 peer feedback에 의존하는 CF RS에 널리 퍼져 있다. 하지만 이는 해결 할 수 있는 방법이 상당히 많다.
- 교차 도메인 추천의 경우, 사용자 - 아이템 - 도메인 삼원 관계의 인수분해 모델을 사용하여 해결 가능하다.
- 사용자 - 아이템 평점을 누락된 다른 평점의 예측 변수로 처리하여 데이터 희소성을 해결 가능하다.
- 다른 사용자가 작성한 동일한 항목의 평점, 동일한 사용자가 작성한 다른 항목의 평점, 유사한 다른 사용자의 평점을 병합하여 최종 평점을 추정한다.
- CF와 Naive Bayes와 결합된 swiching way도 있다.
3. Accuracy
- 추천 정확도는 RS가 각 사용자의 항목 선호도를 정확하게 예측하는 능력을 의미한다.
- CF와 CBF를 결합하고 베이지안 네트워크 모델을 사용하여 더 나은 추천을 받을 수 있다.
- 웹 콘텐츠 RS 또한 좋은 추천을 받을 수 있다.
4. Scalability
- 확장성은 시스템이 작동하도록 설계된 사용자 및 아이템의 수와 관련된 달성하기 어려운 특성이다.
- 확장성이 뛰어나지 않으면, 수백 명의 사용자에게 수백 개의 아이템을 추천하는데 어려움이 있을 것이다.
- 해결 방법은 수정된 피어슨 상관관계 CF를 거리-경계 CBF와 결합하는 것이다. 이를 통해 각 사용자의 가장 가까운 이웃과 가장 먼 이웃을 찾아 데이터 집합을 줄여준다.
- Naive Bayer 와 SVM을 CF와 결합하여 더 나은 확장성을 가진 시스템을 구성할 수 있다.
5. Diversity
- 다양한 추천을 제공하는 것은 인기 편향성을 피하는 데 도움이 되기 때문에 매우 중요하다.
- 더 다양한 추천을 해주기 위해 K-NN의 역 이웃 모델인 K-Furthest Neighbors가 사용되고 이를 통해 다양성이 증가했다고 보고하였다.
6. Other
- 이외에도 개인화 부족, 개인 정보 보호, 노이즈 감소, 참신성 부족, 사용자 선호도 적응성 등이 있었다.
3.3 RQ3a: Data mining and machine learning techniques
- 주제: 하이브리드 추천시스템에는 어떤 데이터 마이닝 및 머신러닝 기술이 사용되나?
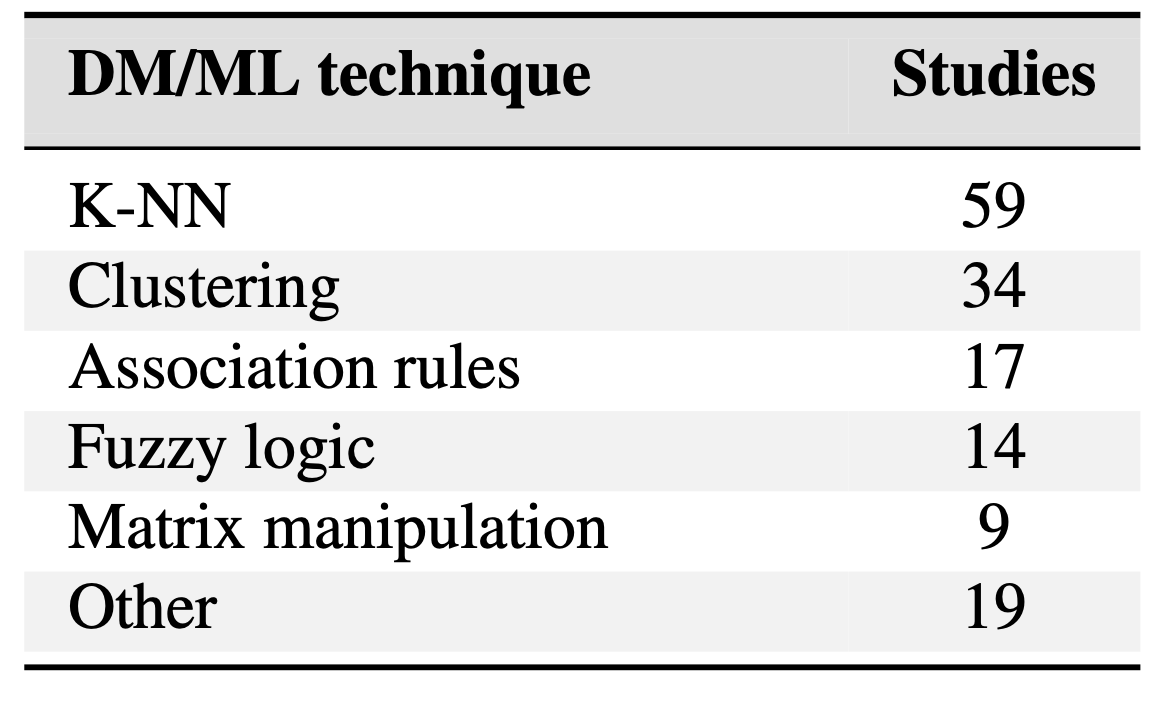
- K-NN과 Clusterin 알고리즘을 제일 많이 활용한다.
1. K-NN

- K-NN은 분류 알고리즘으로, 주로 주변을 분석하여 유사한 프로필을 가진 사용자를 찾거나 항목의 catalog을 분석하여 유사한 특성을 가진 항목을 찾는 데 사용된다.
- 데이터로부터 거리가 가까운 k개의 다른 데이터의 레이블을 참조하여 분류하는 알고리즘으로 거리를 측정할 때 유클리디안 거리 계산법을 사용한다.
- k가 너무 작을 경우 overfitting, k가 너무 클 경우 underfitting될 수 있다.
- 이 기술은 협업 필터링 RS에서 널리 사용되고 있다.
2. Clustering
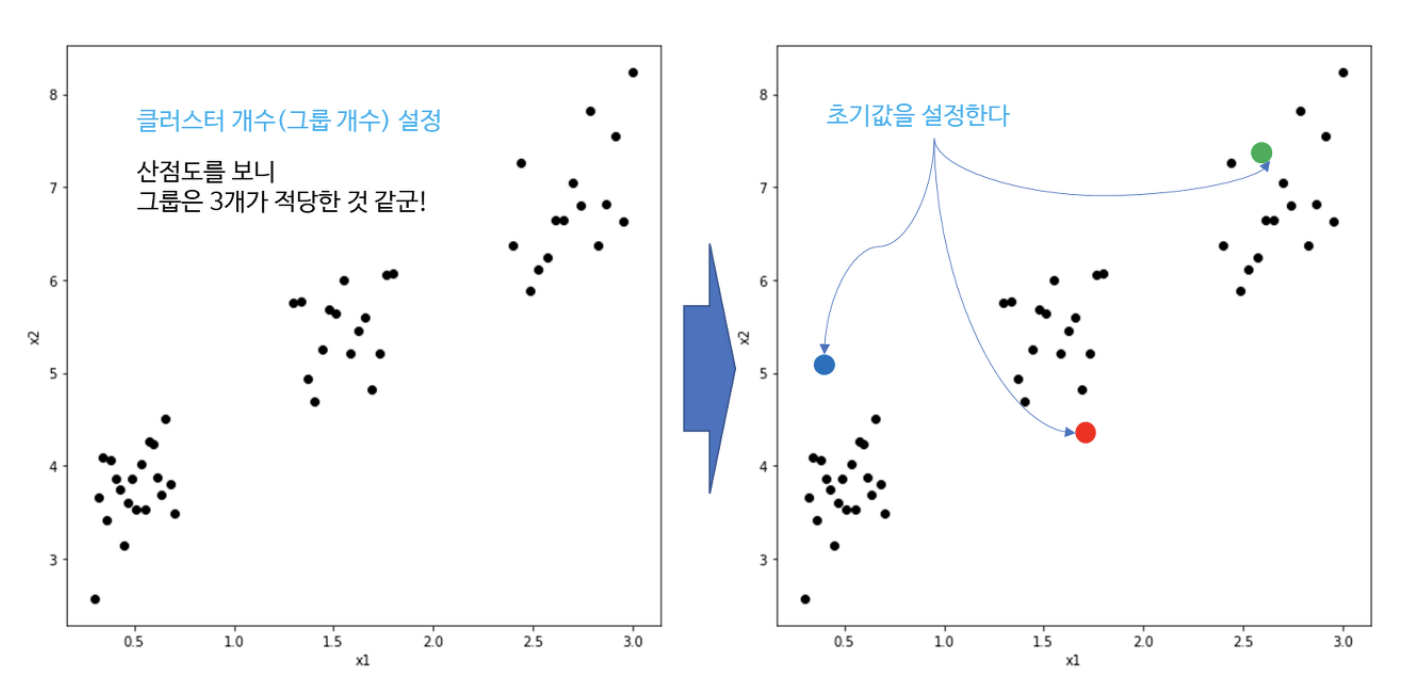
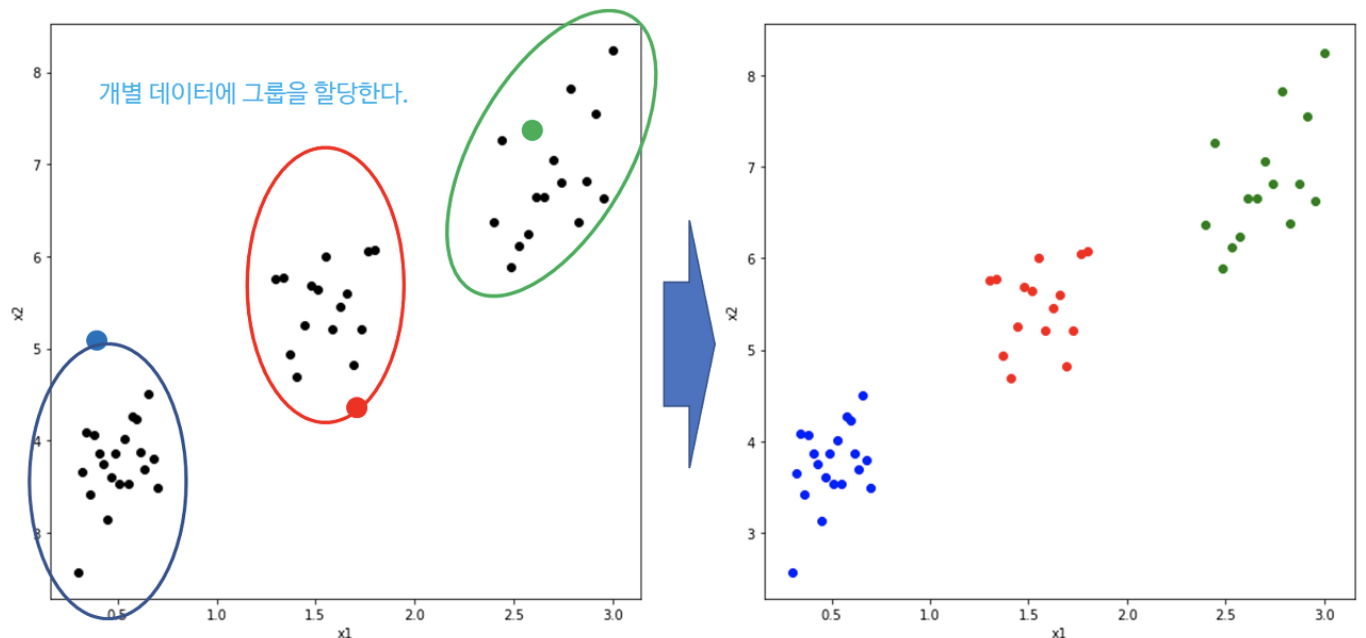
- Clustering이란 각 개체의 그룹 정보(정답)없이 유사한 특성을 가진 개체끼리 군집화하는 것을 의미한다.
- 가장 많이 사용되는 것은 K-means Clustering이다. 이는 비지도 학습 알고리즘으로 사전에 클러스터 개수 k와 초기값을 입력하면 각 데이터의 그룹을 할당해나가는 방법이다.
-
즉, 각 그룹의 초기 중심점을 업데이트하여 다시 개별 데이터의 그룹을 할당하는 과정을 반복하는 것을 의미한다.
-
반드시 클러스터 개수와 초기값을 지정해줘야 한다.
3. Association Rules
- 특정 사건이 발생했을 때 함께 빈번하게 발생하는 또 다른 사건의 규칙을 의미한다.
- 상품 구매, 조회 등 하나의 연속된 거래들 사이에서 규칙을 발견하기 위해 사용한다.
- 추천시스템에서는 "X는 Y를 좋아한다"와 같은 형식이며, 여기서 X는 시스템이 항목 Y를 추천할 수 있는 사용자이다. Y는 시스템 항목을 의미한다.
4. Fuzzy logic

- 퍼지 로직은 근사치나 주관적 값을 사용하는 규칙들을 생성함으로써 부정확함을 표현할 수 있는 규칙 기반 기술이다.
- 예시로 2개의 CF와 퍼지 추론 시스템을 가중치 방식으로 결합하여 더 나은 추천을 할 수 있었다.
- 이 시스템은 관광 분야에서 사용되며 향상된 정확도를 제공한다.
- 위 그림은 퍼지 이론을 추가한 하이브리드 학습 시스템이다. 여기서 Fuzzy Logic Controller는 Backpropagation 학습을 가지는 다층 퍼셉트론의 학습 파라미터를 알맞게 하기 위해 사용되는 것을 의미한다.
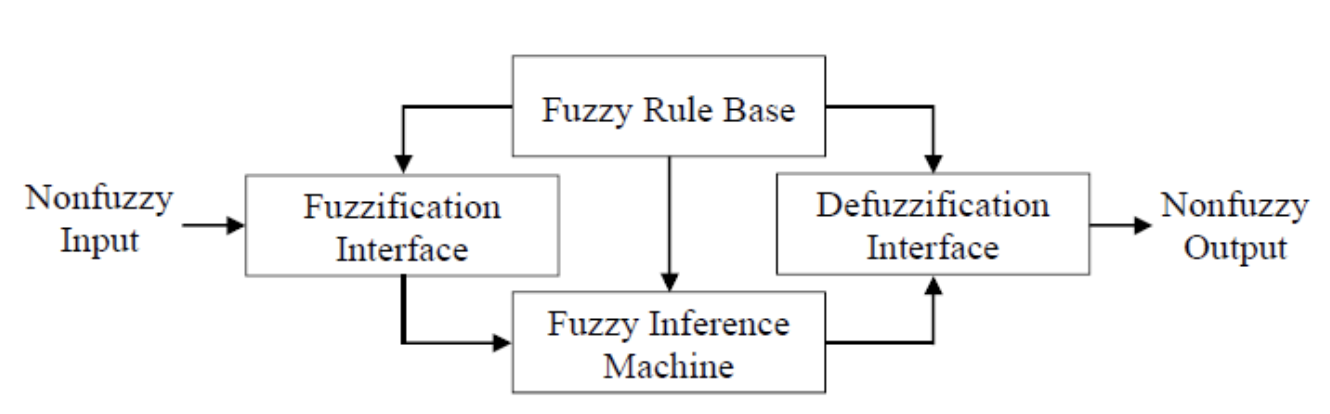
- 위의 그림은 Fuzzy Logic Controller의 구성이다.
1) Fuzzification Interface
: 입력변수의 값의 범위를 일치하는 논의 영역으로 변화시키는 Scale Mapping 담당
ex) 0.44라는 값이 입력데이터로 들어오면 이 값은 '조금 작은 값'이라는 적절한 언어의 값으로 바꿔준다.
2) Fuzzy Rule Base
: IF-THEN 형태로 쓰여진 언어적 제어 규칙의 집합
3) Fuzzy Inference Machine
: Fuzzified Input과 Fuzzy Rule로부터 규칙을 채택하는 의사 결정 논리
4) Defuzzication Interface
: 위의 3단계에서 추론된 Fuzzy control action으로부터 nonfuzzy control action을 내는 defuzzication을 진행
5. Matrix manipulation
- 특이값 분해(SVD), 잠재 디리클레 할당(LDA), 주성분 분석(PCA) 등 행렬 연산을 기반으로 하는 다양한 알고리즘 등이 있다.
6. Other
- Genetic 알고리즘, Naive Bayes, 신경망, 전문가 개념, 통계적 모델링 등도 있었다.
3.4 RQ3b: Recommendation technique combinations
- 주제: 어떤 추천 기법이 결합되며 어떤 문제를 해결하나?
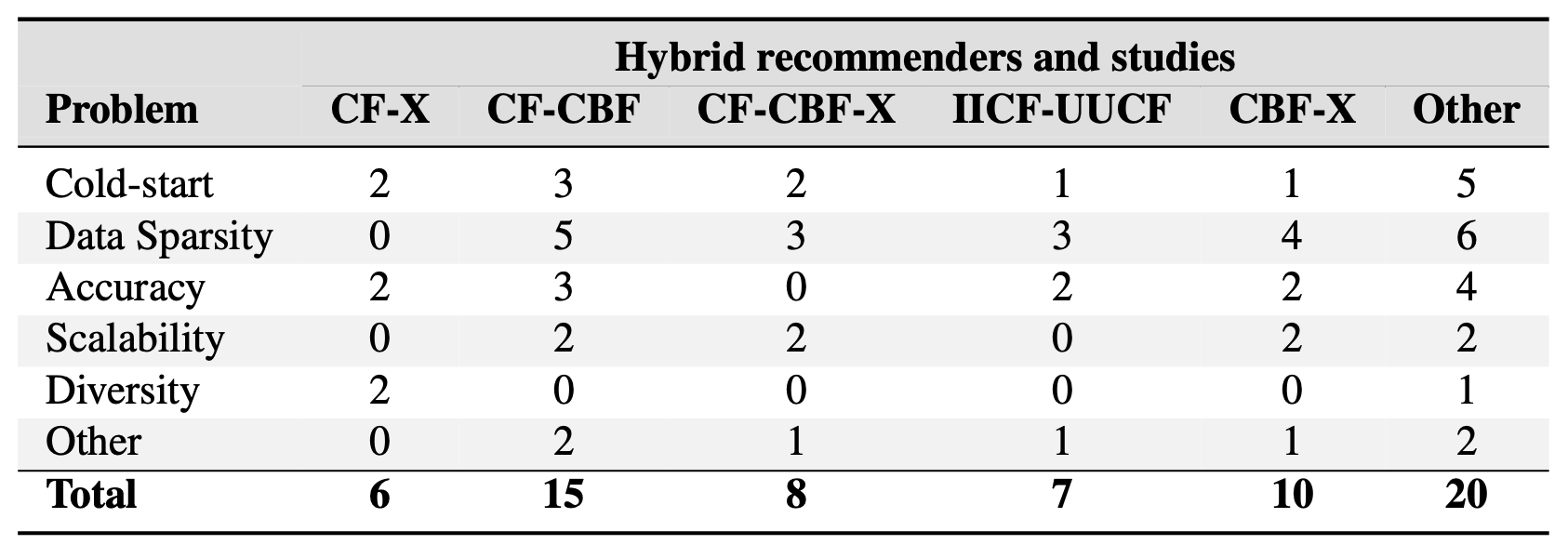
3.4.1 CF-X
- 이 솔루션은 아이템과해당 등급에 대한 사용자 선호도에 영향을 미치는 선택 기준이 몇 가지에 불과하다는 가정에 기반한다.
- 먼저 클러스터링을 통해 사용자가 선호하는 항목의 기준에 따라 사용자를 그룹화한 뒤, 각 클러스터 내에서 CF를 사용하여 예측하였고, 기존 CF에 비해 성능이 개선되었다.
- 또한, 성별, 나이, 직업 등과 같은 인구통계학적 데이터를 CF에 통합한다. Fuzzy logic은 이 데이터를 활용하여 사용자 간의 유사도를 계산하고, 이 유사도를 평점 기록에서 계산된 사용자 기반 유사도와 통합하는 데 사용된다.
- 총 6개의 연구에서 CF-X 조합이 발견되었고,
이때 X란 KBF, DF or DM/ML 기법을 의미한다.
3.4.2 CF-CBF
-
이는 가장 인기 있는 하이브리드 RS이며, CF와 CBF
의 추천에 가중치를 부여하여 최종 예측을 한다. -
이 솔루션은 먼저 CF를 사용하여 각 사용자의 가장 가까운 이웃을 찾고 나머지는 버려서 데이터 집합을 줄인다.
- 그 뒤 거리-경계 CBF를 사용하여 대상 사용자가 구매한 아이템의 결정 경계(decision boundary of items)를 구한다.
- 마지막으로, CF score (두 고객 간의 상관관계) 와 거리-경계 score(의사 결정 경계와 각 항목 간의 거리) 를 가중 선형 형태로 결합한다.
- 저자는 베이지안 기반 CF-CBF 하이브리드 추천시스템을 제안하는데, 각 추천 전략의 가중치가 자동으로 선택되어 문제의 특정 조건에 맞게 모델을 조정할 수 있고, 다양한 도메인에 적용 가능하다는 장점이 있다.
- 총 15개의 연구에서 CF-CBF 조합이 발견되었다.
3.4.3 CF-CBF-X
- CF, CBF 그리고 X를 결합한 추천시스템 방식으로, 이러한 종류의 추천은 소셜 네트워크(광고)에서 특히 유용하다.
- 저자의 목표는 데이터가 부족한 상황에서 좋은 추천을 제공하는 것이다.
- 먼저, CBF를 사용하여 평점과 아이템의 속성을 분석하고, 그 뒤 cascade의 두번째 단계로 CF를 호출하여 그룹 추천을 생성한다. DF는 희소 프로필(평점이 적은 사용자)의 경우 CF를 강화하는 데 사용된다.
- 총 8개의 연구에서 CF-CBF-X 조합이 발견되었고,
여기서 X는 대부분 클러스터링 기술 또는 DF(DemoGraphic filtering)를 의미한다.
3.4.4 IICF-UUCF
- Item-Item CF와 User-User CF는 이웃이 형성되는 방식에 차이가 있는 두 가지 형태의 CF 추천기이다.
- 저자는 이커머스에서 특정 도메인의 상품에 대한 사용자 리뷰와 평점을 모두 고려하는 협업 필터링 주제 모델(CFTM)이라는 하이브리드 추천 프레임워크를 제시하고 있다.
- 첫번째로, 리뷰에서 감성 분석을 수행하여 사용자 또는 아이템 유사성을 계산한다. 두번째로 IICF or UUCF(swiching)을 사용하여 평점을 예측한다.
- 총 7개의 연구에서 IICF-UUCF 조합이 발견되었다.
3.4.5 CBF-X
- 한 가지 예시로 인구통계학적 정보, 소비자 신용 데이터, TV 프로그램 선호도를 라이프스타일 지표로 선정하고 502명의 사용자를 대상으로 통계 분석을 수행하여 그 유의성을 확인하였다.
- 가장 중요한 라이프스타일 속성은 바이너리로 인코딩 되어 피어슨 상관관계를 통해 각 사용자의 이웃과 등급을 형성하는 데 사용된다.
- 완성된 행렬을 pseudoUser - item matrix라고 부른다.
-
그 뒤 원래 user-item 평가에 대한 피어슨 기반(고전적 CF) 예측에 사용되고, 상당한 성능 향상이 있었다.
-
총 10개의 연구에서 CBF-X 조합이 발견되었다.
여기서 X는 KBF와 DF or DM/ML(클러스티링 등과 같은 기술)을 의미한다.
3.4.6 Other
- 동일한 추천 전략의 조합
(ex. 각각 다른 유사성 측정값 or 튜닝 매개변수를 사용하는 CF1 - CF2)
- 소셜 커뮤니티에서 사용되는 신뢰 인식 추천, 연관 규칙 마이닝
- 신경망, 유전 아록리즘, 차원 축소, 소셜 태킹, semantic ontolo-gies, 패턴 마이닝 등
3.5 RQ4: Classes of hybridization
- 주제: Burke의 분류법에 따라 어떤 하이브리드화 클래스가 사용되나?

3.5.1 Weighted
- Soft Ensemble 또는 Hard Vote와 같은 방법으로 여러 모델의 추천 결과를 하나로 합쳐 최종 추천 아이템을 정하는 방식
ex) model 1, model 2, ... , model n에서 각각 item 1에 대한 score를 weighted ensemble한다. 이 때 각 모델의 성능에 따라 가중치를 둘 수 있다.
- 위의 그림과 같이 가중치 하이브리드가 가장 빈번히 사용되며, 가중치 선형 함수를 사용하여 각 추천기법의 출력 점수를 합산하여 추천 항목의 점수를 계산한다.
- CF와 CBF의 가중치는 사용자별로 설정되어 시스템에서 각 사용자에 대한 최적의 조합을 결정하고 'gray sheep' 문제를 완화할 수 있다.
- 저자는 소셜미디어에서 user-user, user-tag 그리고 user-item CF 관계를 결합하는 가중치 방법을 제안한다. 즉, 위의 3가지 CF 관계의 선형 조합으로 사용자에 대한 항목의 최종 평가 점수를 계산한다.
- 기존 CF와 달리 이 가중치 하이브리드 CF 추천기는 전적으로 tag를 기반으로 하며, user가 추천 항목에 대한 명시적인 평점 점수를 제공하지 않아도 된다.
- 서로 다른 가중치를 적용함으로써 간단한 방법으로 사용할 수 있다는 장점이 있고, 가중치를 쉽게 변경하여 우선순위 할당을 쉽게 조정할 수 있다.
- 가중치 하이브리드 RS는 포함된 연구 중 22개(28,9%)에서 사용되었다.
3.5.2 Feature combination
-
보유하고 있는 데이터로부터 얻을 수 있는 다양한 feature를 모두 조합하여 추천 알고리즘을 학습하고 추천하는 방식
-
한 추천기의 출력을 추가 기능 데이터로 취급하고, 새로운 확장 데이터에 대해 다른 추천자 (일반적으로 항목 기능을 광범위하게 사용하는 콘텐츠 기반)를 사용한다.
- CF-CBF의 경우, CF의 출력에만 의존하는 것이 아닌, 해당 출력은 최종 목록을 생성하는 CBF의 추가 데이터로 간주된다. 이렇게 하면 데이터의 희소성에 대한 민감도가 줄어든다.
- 예를 들어, CF-CBF 도서 추천기를 만든다고 할 때, 먼저 독자들 사이에서 CF를 적용하여 새로운 특징(선호 독서)를 생성한다.
- 두 번째 단계에서는 fuzzy c-means clustering과 type-2 fuzzy logic을 활용하여 각 사용자 유형(교사, 학생 등)의 도서 카테고리를 생성하기 위한 데이터를 얻는다.
- 마지막으로 CF의 최종 출력을 추가하여 각 사용자에게 가장 관련성이 높은 도서를 추천하기 위해 CBF를 사용한다.
3.5.3 Cascade
- 추천자는 더 낮은 우선 순위들이 더 높은 것들의 점수를 매기는 것이 단절되면서 엄격한 우선순위를 가진다.
- 단계적 추천 프로세스의 한 예시로,
먼저 한 가지 기법을 사용하여 후보 항목의 대략적인 순위를 생선한 다음 두 번째 기법을 사용하여 예비 후보 세트에서 목록을 구체화한다.
3.5.4 Switching
- 플랫폼 내 사용자 또는 서비스 상태 등 특정 상황을 고려하여 여러 추천 알고리즘의 추천 결과를 선택적으로 보여주는 방식
- Switching 하이브리드에서는 몇 가지 기준에 따라 서로 다른 추천 기술 간에 전환한다.
-
CF-CBF 접근 방식은 협업 전략이 신뢰할 수 있는 추천을 충분히 제공하지 못하는 경우에만 콘텐츠 기반 추천으로 전환할 수 있다.
-
예를 들어, 나이브 베이즈 분류기와 item-item CF를 기반으로 하는 Switching 하이브리드 RS를 구축하는데, 각 클래스의 사후 확률이 다른 클래스의 사후 확률보다 낮으면 즉, 이 추천의 신뢰도가 낮을 경우 item-item CF 추천이 대신 사용된다.
- 이 시스템은 합성 기술의 강점과 약점에 민감하다.
3.5.5 Feature Augmentation
- 하나의 추천 기술은 하나의 특징이나 다음 기술의 입력의 한 부분이 될 특징들의 세트에 사용된다.
- 결합된 기술 중 하나를 사용하여 항목 예측 또는 분류를 생성한 다음 다른 추천 기술의 작동에 구성한다.
- Feature Augmentation은 시스템을 수정할 필요 없이 시스템(두 번째 추천자)의 성능을 개선할 수 있는 수단을 제공한다. 처리된 데이터를 보강하여 추가 기능을 추가한다.
- 예시로 추천 다양성을 높이기 위해 다차원 클러스터링과 CF를 결합한 하이브리드 방법도 있다.
3.5.6 Meta level
- 여러 추천 알고리즘을 활용할 때 첫번째 모델이 다음 모델의 input이 되면서 서로가 서로의 정보를 학습해 추천하는 방식
- 첫 번째 기법에 의해 유도된 전체 모델을 두 번째 기법에 대한 입력으로 사용하는 순서 민감형 하이브리드 RS이다.
- 일반적으로 콘텐츠 기반 추천자를 사용하여 모델을 구축한 뒤, 이 모델을 협업 추천자에 사용하여 항목을 사용자 프로필과 일치시킨다.
- 이 혼합 기법의 장점은 첫 번째 기법의 학습된 모델이 압축되어 두 번째 기법에서 더 잘 활용된다는 것이다.
- 통합 노력이 상당하고 고급 구조를 사용해야 하는 경우가 많이 있다는 단점이 있다.
3.5.7 Mixed
- 추천시스템이 적용될 플랫폼에 여러 추천 알고리즘을 활용하고, 이 때 알고리즘의 추천 결과를 모두 보여주는 방식
- 서로 다른 추천자를 동시에 조합할 수 있을 때 합리적이다. 이때 CF-CBF 혼합 하이브리드 방식을 많이 활용된다.
- 첫번째 예시 중 하나는 CBF를 사용하여 유사한 프로그램을 사용자 프로필과 연관시키고 CF를 사용하여 유사한 사용자 프로필을 함께 연관시키는 PTV system이다.
- 혼합형 하이브리드 RS는 간단하고 cold-start와 같은 문제를 극복할 수 있다. 하지만 연구에서는 그렇게 많이 사용되지 않는다.
3.6 RQ5: Application Domains
- 주제: 하이브리드 추천은 어떤 도메인에 적용되나?
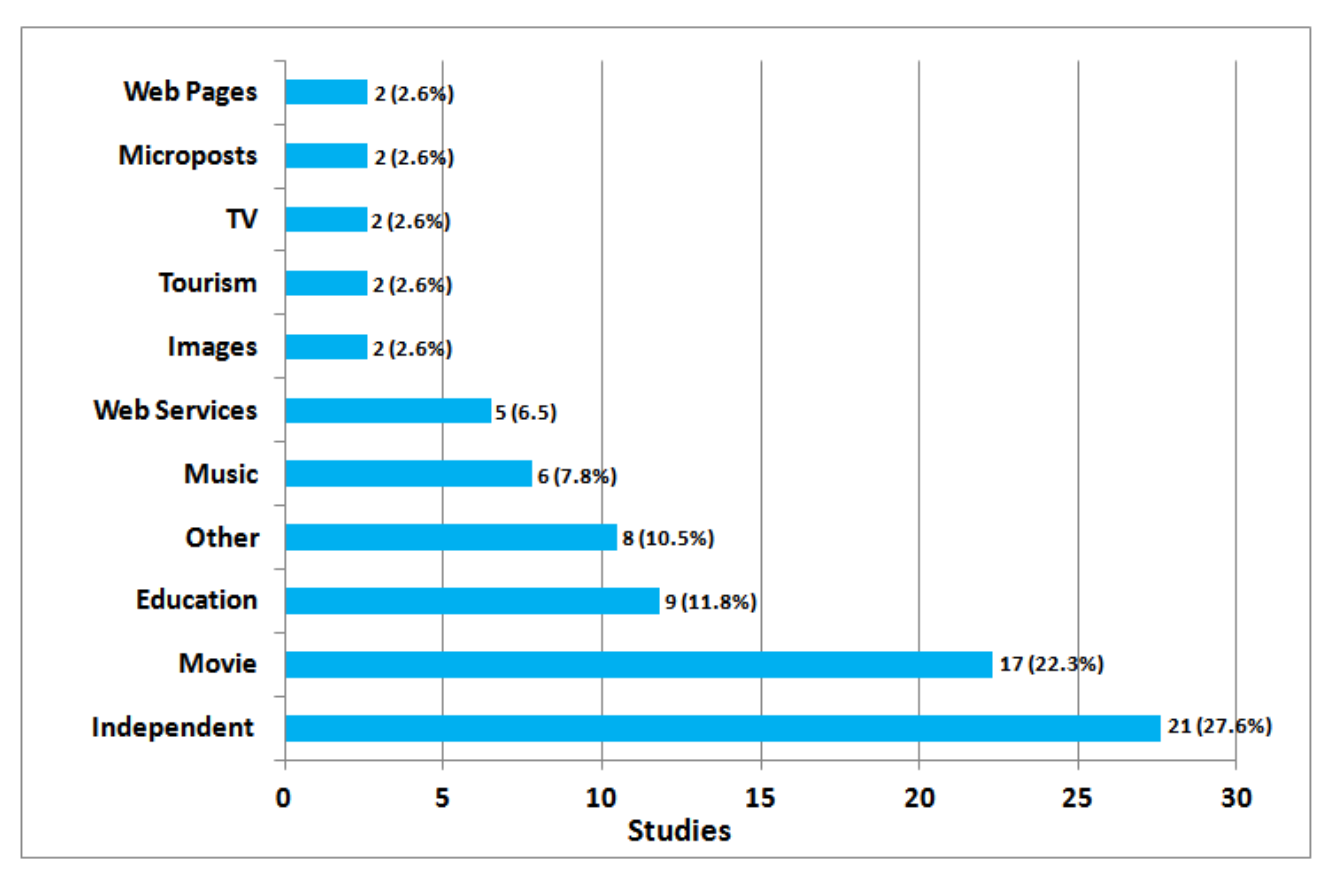
- 대부분의 연구가 도메인에 독립적인 연구임을 알 수 있다.
- 그 뒤로 영화, 교육, e-러닝, 음악 등의 연구가 적용되었다.
- 비즈니스, 음식, 뉴스, 참고 문헌 등과 같이 '기타'로 분류된 도메인은 전체 연구 수의 10.5% 미만을 차지한다.
3.7 RQ6: Evaluation
3.7.1 RQ6a: Evaluation Methodologies
- 주제: 평가에는 어떤 방법론이 사용되고 어떤 지표를 사용하나?

- 잘 알려진 유사한 방법 또는 기술과 비교를 통해 평가 하는 것이 제일 많았다. 일반적으로 CF-X or CF-CBF 하이브리드 RS는 순수 CF or CBF와 비교된다.
- 정확도 or 오차 측정은 MAE or RMSE를 사용하고, precision, recall, F1과 같은 지표도 매우 빈번하게 사용된다.
- 2번째로 설문조사는 질문 기반이며 하이브리드 추천기의 다양한 측면에 대한 사용자의 의견을 반영한다.
3.7.2 RQ6b: Characteristics and Metrics
- 주제: 어떤 추천시스템 특성을 평가하고 어떤 지표를 사용하나?
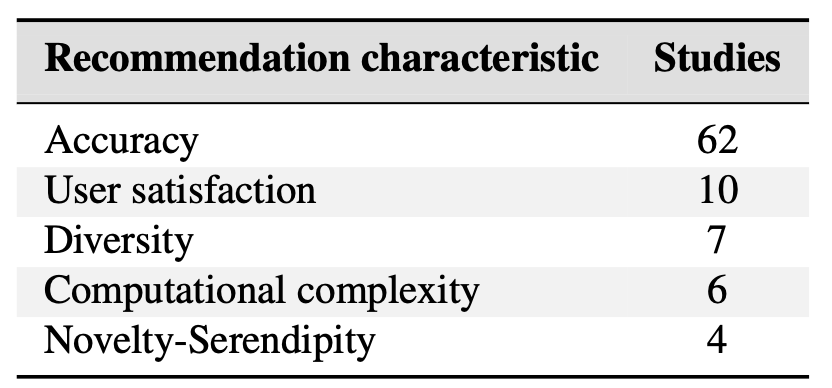
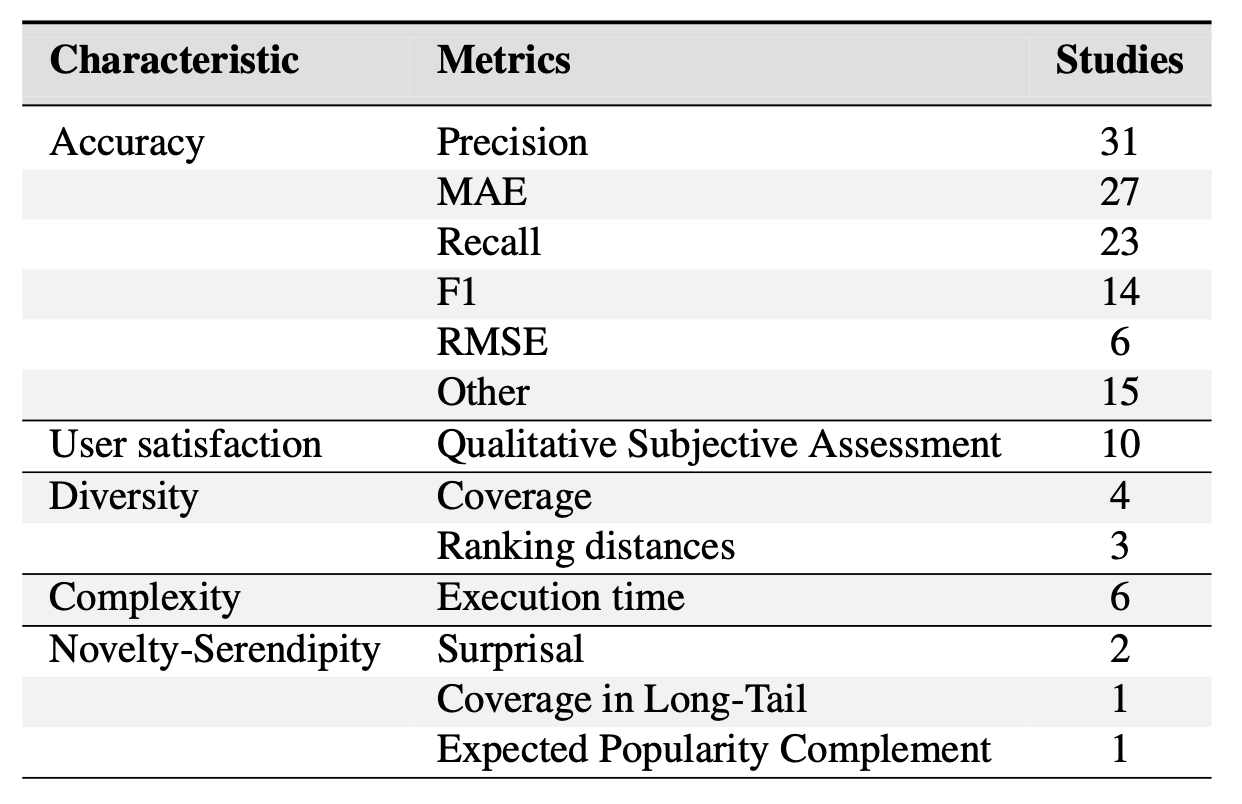
- 정확도는 주로 Precision(31), Recall(23), F1(14) 등으로 측정된다. 그리고 MAE와 RMSE는 각각 27개, 6개 연구에서 발견되었다.
3.7.3 RQ6c: Datasets
- 주제: 하이브리드 추천시스템 훈련 및 테스트에는 어떤 데이터 셋이 사용되나?
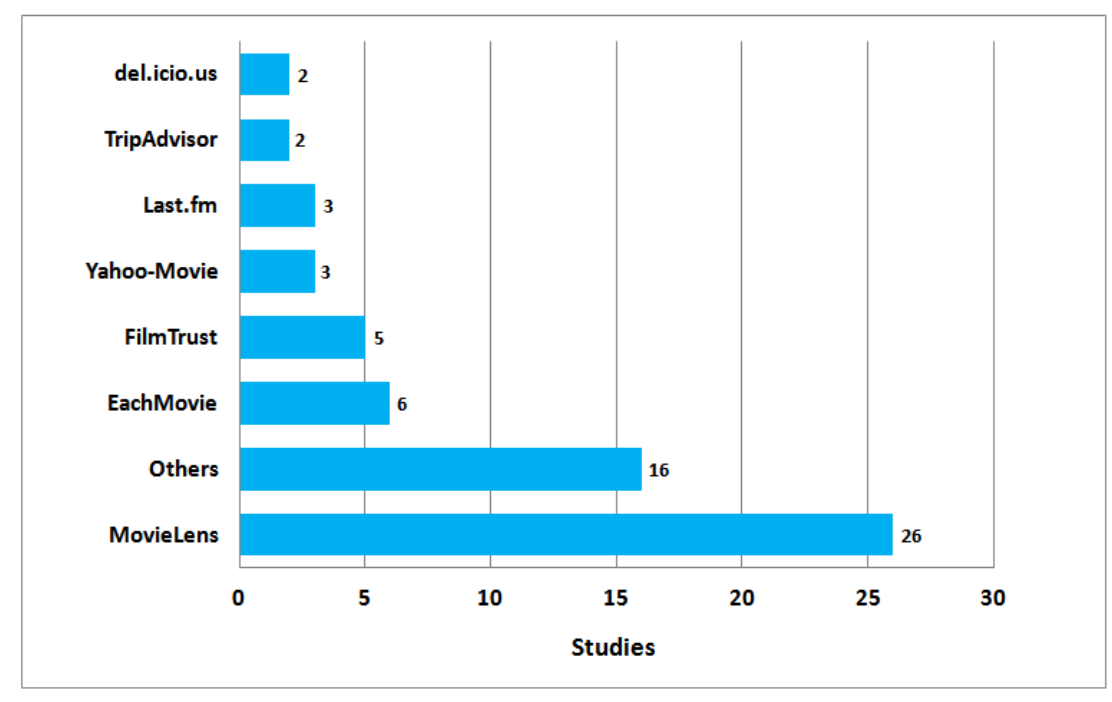
- 적어도 하나의 데이터셋을 사용하는 55개의 연구가 있고, 21개의 연구에서는 데이터셋을 전혀 사용하지 않았다. 그리고 합성 데이터를 사용하거나 사용자 설문조사 또는 기타 기법에 의존하는 경우도 있었다.
- MovieLens는 영화 분야에서 가장 많이 사용되는 공개 데이터 셋 중 하나이며 26개의 연구에서 사용되었다.
3.8 RQ7: Future work
- 주제: 향후 연구에 가장 유망한 방향은?
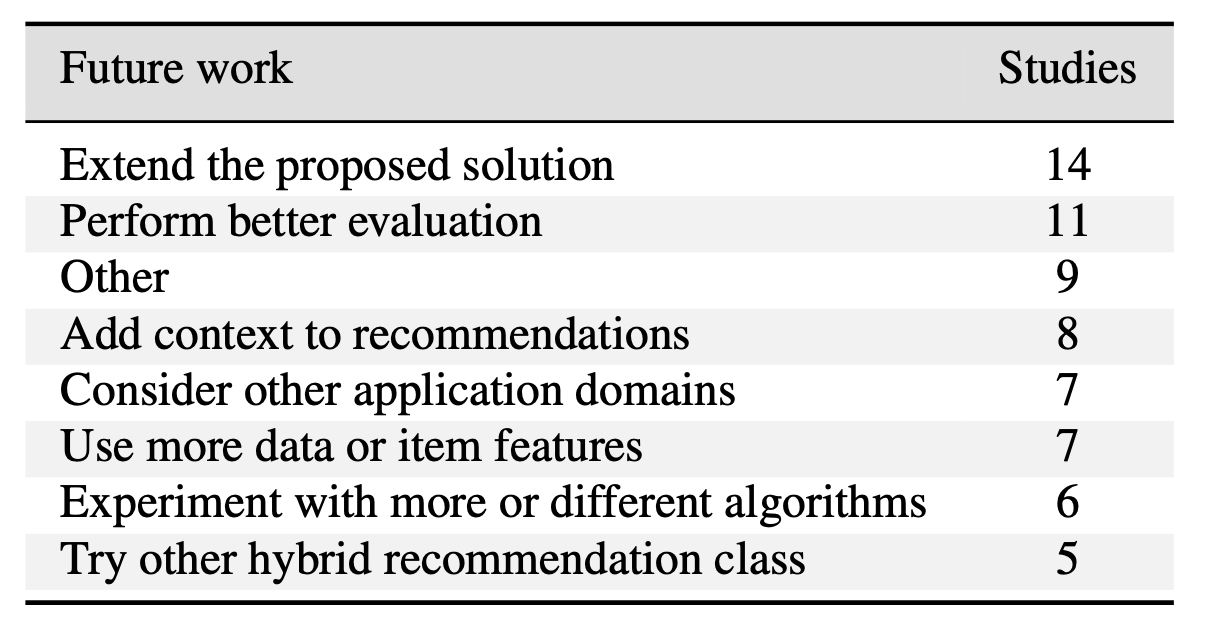
- 첫번째로 Extend the proposed solution 은 많은 사람들이 공통적으로 언급하는 제안이다. 성능 개선, 기능 확장 등을 위해 시스템에 통합할 수 있는 여러 구성 요소를 식별하고자 제안한다. 아마 성능 개선이 제일 크지 않을까 싶다.
- 두번째로 많이 나온 것은 Perform better evaluation 는 추천 시스템 평가하는 것이 어렵고 가장 적절한 기술이나 알고리즘을 찾기 어렵다는 내용이다.
4. Discussion
4.1 Selected Studies
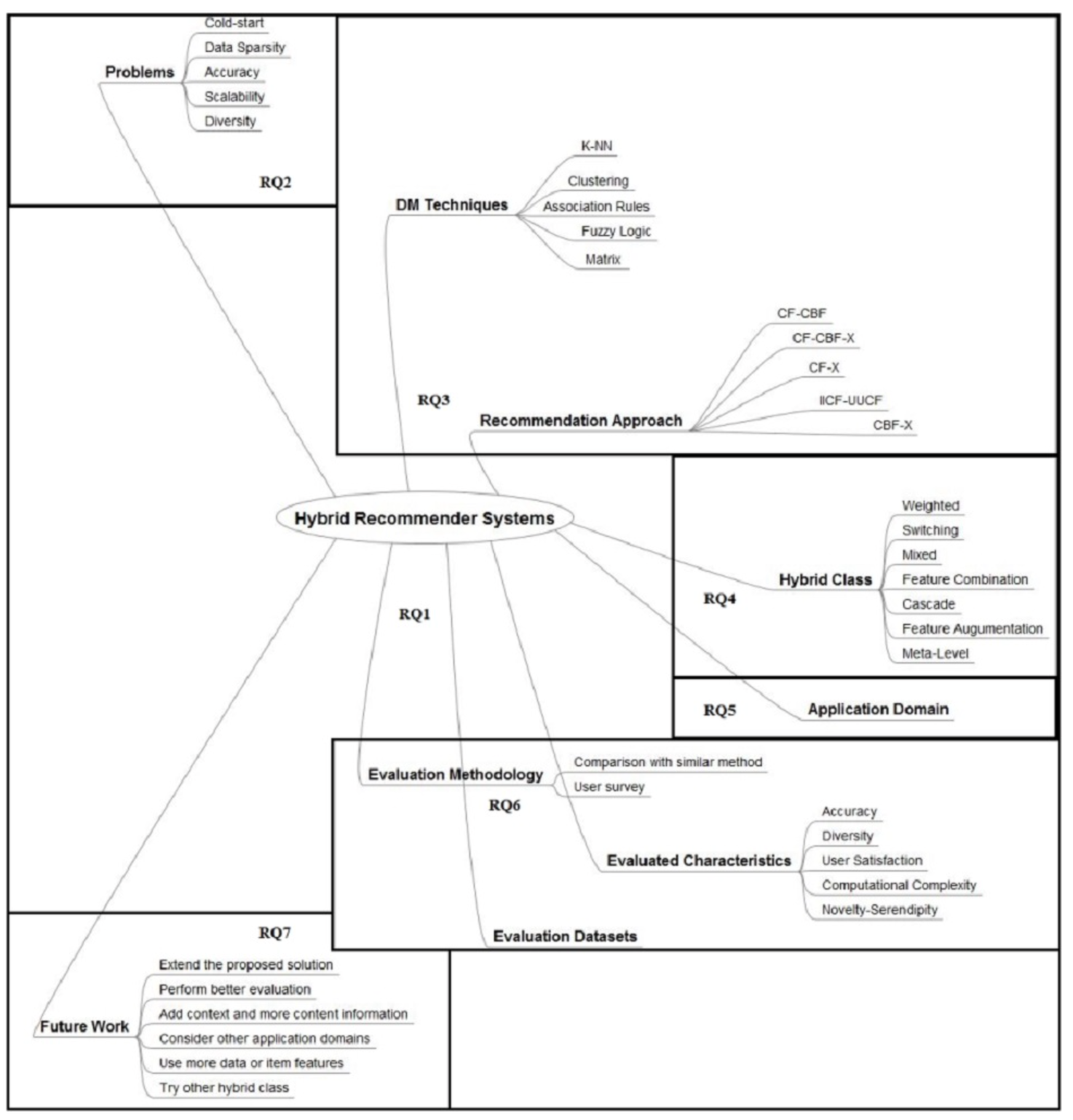
- 위의 모든 내용들을 그림으로 함축하였다. 요약본이라고 생각하면 된다.
4.2 Problems and Challanges
- Cold-start가 가장 심각한 문제였다.
- CF RS는 평점에만 의존하여 추천해주기 때문에 cold-start 영향을 가장 받았다. 하지만 하이브리드 RS는 CF or 기타 추천 기법과 연관 규칙 최소화 or 아이템에서 특징을 사용하는 기타 수학적 구조를 결합하여 평점 부족을 극복하고자 했다.
- 또한, 데이터 희소성 문제도 빈번하게 발생하는 문제였다. 이는 부족한 평가 수로 인해 추천 품질이 저하되는 것을 의미한다.
- 하이브리드 접근 방식은 여러 가지 행렬 조작 기법을 기본 추천 전략과 결합하여 해결하였고, 아이템 기능, 아이템 리뷰, 사용자 인구 통계 데이터 또는 사용자 특성을 더 많이 활용하고자 하였다.
- 정확도 -> 개선: 병렬 (가중치를 부여하거나 하이브리드 클래스를 전환하는 방식) 추천 기술을 사용
- 다양성 -> 개선: 정확도를 허용할 수 있는 수준으로 완화하면 더 높은 다양성을 얻을 수 있다.
4.3 Techniques and Combinations
- K-NN은 가장 많이 사용되는 DM기법 중 하나이며, K-NN CF 가장 성공적이고 널리 사용되는 RS 중 하나이다.
- 또한, Clustering기법도 많이 사용되며 K-means 기법을 가장 많이 사용한다.
- 연관 규칙은 사용자와 아이템 간의 빈번한 관계를 식별하는 데 사용된다. 그리고 fuzzy logicrhk matrix mapping 방법도 사용된다.
- 대부분 두 가지 추천 전략을 결합하여 사용되는데 CF-CBF가 가장 많이 사용되는 조합이다. 그리고 CF-CBF-X도 많이 사용된다.
- CF-X조합에서 X는 일반적으로 성능을 향상시키기 위해 CF에 통합되며, fuzzy logic or clustering을 나타낸다.
- IICF-UUCF는 두 가지 기본 버전의 CF를 조합한 것으로 널리 사용된다.
4.4 Hybridization classes
- 가중 하이브리드가 가장 많이 사용되며, 이는 종종 동적 방식으로 CF와 CBF를 결합하여 가중치를 부여한다.
- Cascade, Switching, Feature Augmentation, Meta Level은 거의 동일한 빈도로 사용되며 Mixed 하이브리드는 잘 사용되지 않는다.
- Weighted, Mixed, Switching 그리고 Feature Combination은 순서에 민감하지 않고, Switching CF-CBF와 Swithcing CBF-CF 사이에는 차이가 없다. 그렇기 때문에 나머지 class에 비해 연결하기 쉽다.
- Cascade, Feature Augmentation, Meta Level은 순서에 민감하다.
- Switching 하이브리드는 일반적으로 유클리드 거리, 피어슨 상관관계, 코사인 유사도 등과 같은 거리/유사도 측정에 의존하여 특정 시간에 어떤 요소를 활성화할지 결정한다.
- Feature Augmentation, Cascade, Meta Level 하이브리드는 확률적 모델링, 베이지안 네트워크 등과 같은 복잡하고 고급 수학적 프레임워크에 의존한다.
- Weighted는 가중치가 있는 가중 선형 함수에 의존한다.
4.5 Application Domains
- 많은 연구가 도메인에 독립적이다.
- 가장 많이 연구된 도메인은 영화이고, 영화 데이터는 많은 양의 데이터를 갖고 있고 공개적이다.
- 교육 또는 e-러닝 도메인도 하이브리드 RS를 많이 사용한다.
- 음악과 웹서비스에서도 많이 사용한다.
4.6 Evaluaton
- 추천시스템을 평가하는 것은 쉬운 일이 아니다.
- 평가지표는 MAE or RMSE와 같은 정확도 그리고 precision, recall, F1와 같은 정보 검색 merics를 사용한다.
- 정확도를 평가하는 데 가장 자주 사용되는 지표는 Precision, Recall, MAE이다.
4.7 Future Work
- 더 많은 알고리즘을 적용하여 확장 / 사용자 컨텍스트 및 프로필에 더 많이 적응하여 개인화 수준 확장 / 더 많은 데이터 셋 또는 항목 기능 등을 사용하여 확장 등이 향후 작업 방향이 있었다.
- 빠른 컨텍스트 변화로 인해 시간이 지남에 따라 변화하거나 진화하는 사용자 관심사에 적응하는 것은 RS에서 매우 원하는 특성이다. 이에 따라 컨텍스트를 추가하거나 항목 또는 사용자에 대한 다양한 기준을 분석할 것을 제안한다.
5. Conclusions
- 하이브리드 RS를 다루는 학술지 및 컨퍼런스에서 76개의 주요 연구를 분석하였다.
- 데이터 마이닝 및 머신러닝 기술, 결합된 추천 전략, 하이브리드화 클래스, 애플리케이션 도메인 및 데이터 셋, 평가 프로세스, 향후 연구 방향 등에 대해서도 분석하였다.
- cold-start 문제와 관련하여, 데이터 희소성과 정확성은 가장 큰 문제점이다. 연관 규칙 마이닝을 기존의 추전전략 함께 사용하거나 행렬 인수분해 기법을 통해 해결할 수 있다.
- 데이터 마이닝 기법 중에서는 협업RS에서는 K-NN이 가장 많이 사용되었고, 추천 기법 중에서는 CF가 많이 사용되었으며, 모든 종류의 문제를 해결하기 위해 다른 기법들과 결합하는 경우가 많았다.
- Burke가 제안한 분류법에 따라 다양한 하이브리드화 접근 방식을 식별하고 분류한 결과, 가중치 하이브리드가 가장 많이 반복되는 것으로 나타났다. Meta Level, Data Augmentation와 같은 다른 하이브리드화 클래스는 복잡한 수학적 구조가 필요하기 때문에 거의 사용되지 않는다.
- 무비렌즈가 주도하는 영화 데이터 셋(공개 데이터)이 가장 많이 사용되었고, 영화 도메인은 프로토타입 제작에 가장 선호되었다.
- 빅데이터 시대에 하이브리드 병렬 알고리즘으로 더 큰 데이터셋을 처리하는 것은 확장성 문제를 완화하고 더 나은 추천 품질을 제공할 수 있는 좋은 방법이다.
🎯 Summary
논문이 엄청 길었고 논문 리뷰하는 시간도 많이 걸렸다. 하지만 정말 잘 골랐다는 생각 밖에 안든다. 하이브리드 추천시스템에 대한 문제점, 특성 그리고 마이닝 기법, 평가 지표, 다양한 조합 등 많은 부분을 알 수 있었다. 논문에 쓰여진 내용을 바탕으로 공모전을 진행할 때 다양한 모델을 조합해서 성능을 올려봐야겠다.
📚 References
-
Hybrid Recommender Systems - A Systematic Literature Review논문
-
K-NN 그림:
https://velog.io/@gr8alex/KNN-%EC%95%8C%EA%B3%A0%EB%A6%AC%EC%A6%98 -
K-means 그림: https://zephyrus1111.tistory.com/179
-
Fuzzy Logisic 그림: https://adipo.tistory.com/entry/%ED%8D%BC%EC%A7%80
