[논문리뷰 | Anomaly] Unsupervised Anomaly Detection with Generative Adversarial Networks to Guide Marker Discovery (2017) Summary
[논문리뷰]
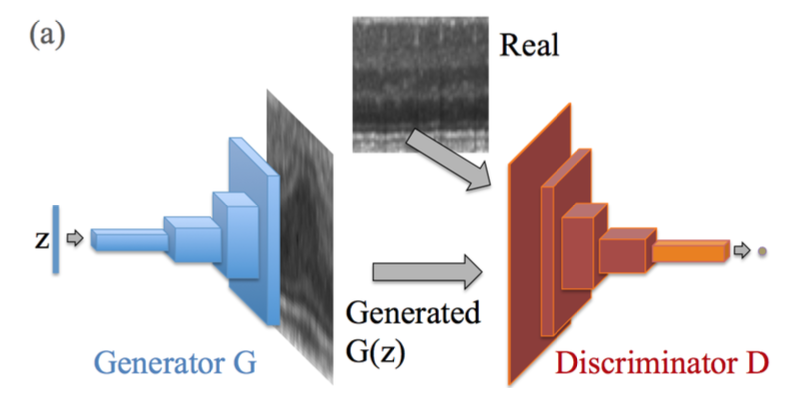
Title
- Unsupervised Anomaly Detection with Generative Adversarial Networks to Guide Marker Discovery
- AnoGAN

이 논문 리뷰는 DSBA(김창엽) 논문 리뷰를 참고하여 작성하였습니다.
Abstract
- 질병 경과, 치료 모니터링과 관련된 이미징 마커를 포착하는 모델을 얻는 것은 도전적임.
🤜 탐지 자동화를 목적으로 하기 때문에 Label이 있는 많은 data를 사용함.
🤜 Label 확보를 위해서는 굉장히 많은 노력이 필요하고, 모델 성능은 알려진 마커에 한정됨.
- 대부분의 모델은 알려진 마커의 주석이 달린 예제를 기반으로 하며, 이를 자동화하기 위해 설계됨.
- 이미징 데이터의 이상치를 마커의 후보로 식별하기 위해 비지도 학습으로 수행
- AnoGAN을 제안함
🤜 정상이 갖는 구조를 나타내는 manifold를 학습 (DCGAN 구조 학습)
🤜 이미지 공간에서 잠재 공간으로의 매핑을 기반으로 한 새로운 이상치 점수 체계를 동반함.
-> 어떤 이미지가 새로 들어왔을 때, 이미지에 해당하는 잠재 공간에서의 좌표를 찾고 그 좌표로부터 이미지를 생성하게 됨. 그 후 실제 이미지와 좌표로부터 만들어진 이미지의 차이를 계산해서 이상치 점수를 계산함
- 적용된 모델은 이상치를 Labeling하고, 이미지 패치가 학습한 분포에 피팅하는 정도를 나타내는 스코어 및 적합성을 제공함.
- 망막의 OCT 영상 실험 결과, 접근법이 망막 액체나 고반사성 초점을 포함하는 이상한 이미지를 올바르게 식별함.
1. Introduction
- 의료 이미징 데이터에서 질병 마커의 탐지와 정량화는 진단, 질병 진행 & 치료 반응 모니터링에 있어서 매우 중요함.
- 이미 알려진 마커의 vocabularly에 의존하는 것은 이미징 데이터의 더 풍부한 관련 정보의 사용을 제한함.
🤜 기존 지도 학습 한계
🤜 많은 정보가 포함된 영상 데이터를 활용하는 데 한계
🤜 알고 있는 질병에 대해서만 탐지를 할 수 있고, 모르는 질병에 대해서는 탐지 못하는 한계
- 이 연구에서는 대규모 이미징 데이터에서 비지도 학습을 통해 관련된 이상치를 식별할 수 있음을 보여줌.

- 위의 그림은 비지도 학습을 통해 정상 구조가 갖는 형태와 관련된 "Generation Model"을 만듬.
🤜 Generator, Discriminator 활용
- 기존 연구에 비해서 Image Space -> Latent Space로 Mapping하는 방법 개선
- Training Data(Normal Data)를 학습해서 피팅되지 않는 Data(AbNormal Data)를 탐지함.
- 이는 학습 중에 사용하는 Normal Data 분포에 피팅되지 않는 Test Data를 식별하는 작업이라고 볼 수 있음.
🤜 기존에는 feature space의 관측값에서 Local Densitty를 기반으로 outlier 여부를 결정했었음.
2. Related work
2.1. Carrera et al. (2015)


📌 Convolution Sparse Model을 활용하여 텍스쳐 영상에서 Anomaly Detection 하기 위해서 "dictionary of filter"를 학습함
- 왼쪽 그림의 정상 이미지에서 많이 나타나는 Filter를 학습해서 dictionary 형태로 만듬.
- 그 후 오른쪽 그림(비정상)에서 dictionary에 해당하지 않는 부분을 검출하는 것이 목표임.
- 이상한 영역을 감지하기 위해 합성곱 희소 모델을 사용
2.2. Erfani et al. (2016)
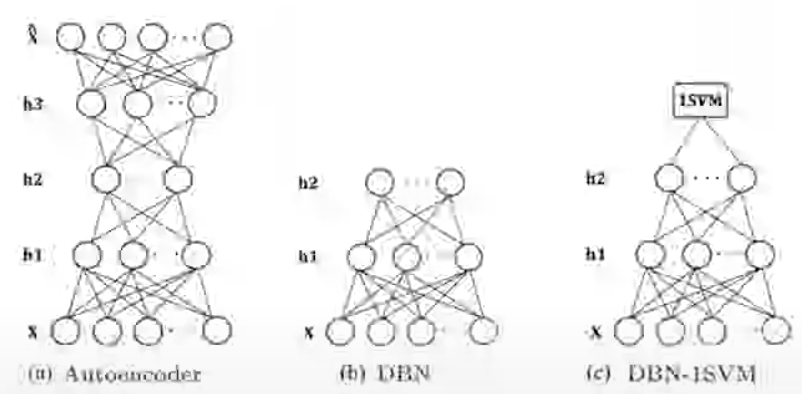
- SVM -> Deep Belief Network(DBN)에서 얻은 Feature로 학습함
- 이 연구는 SVM을 사용하는 비지도 방식의 이상치 탐지를 위한 Hybrid Model을 제안함.
기존 연구와의 차이점
- 기존 연구의 input은 1차원 or 텍스처, 의학, 합성 이미지와 비교했을 때 차원이 낮음.
2.3. GAN
- GAN은 Generative Adversarial Networks라는 의미로 현실적인 이미지를 생성하는 "생성 모델"을 학습할 수 있음.
📌 DCGAN (Deep Convolutional GAN) (2015) 이 모델의 구조를 사용해서 AnoGAN이 만들어짐.
📌 "Discrimination Loss" 개념에서 아이디어를 얻어서 Loss Function을 변형해서 사용함
📌 Feature Matching 의 개념에서 아이디어를 얻음
-> Generator가 현재의 Discriinator에서 오버피팅되지 않도록 함.
3. Model

- 이상치를 찾기 위해 GAN을 사용해서 구조적 정상을 표현하는 모델을 학습함.
- 위의 그림 중
왼쪽은 생성 모델을 학습하고, 생성한 데이터와 실제 데이터를 구분할 수 있는 판별기 를 학습
- 이 논문에서의 핵심은 "구조적 정상 범위(정상 데이터)에 대해 비지도학습 기반 Manifold(Noise 영역) 학습"임.
📌 Input Image
- 각 이미지로부터 크기가 인 개의 2D이미지 patch를 추출함
- 이미지의 다양성을 나타내는 manifold X((b)의 파란색 영역)을 unsupervised Learning 진행
📌 Test
- 새로운 Test Data에서 추출한 크기의 처음 본 이미지
- 이때 Label은 이상 탐지 성능을 평가할 때만 사용됨.
3.1. Idea
- Normal Data의 분포를 학습하는 DCGAN의 구조를 활용하여 구조적으로 정상과 이상치를 탐지하는 Model임.
-
[학습] AnoGAN은 오직 Normal Data만을 사용하여 학습함.
📌 생성자는 이를 바탕으로 정상적인 이미지를 생성하려고 학습하고, 판별자는 생성된 이미지와 실제 데이터를 구분하려고 학습함. -
[이상치 탐지] Test에서 input과 가장 유사한 이미지를 생성하는 Latent variable을 찾기
-> 만약 iput image가 이상치라면, 생성된 이미지와의 차이가 크게 나타남.
- [Anomaly Score 정의]
📌 이를 기반으로 이미지가 얼마나 정상인지 아닌지에 대한 점수를 계산함. 만약 점수가 높으면 이미지는 이상치로 간주됨.
- 이미지 공간에서 Latent Space으로의 Mapping에서 두 가지 방법을 구현함.
- AnoGAN은 의료 이미징과 같은 분야에서 정상적인 분포와 크게 다른 이상치를 탐지하는 데 많이 사용됨
3.2. Characteristic
1. Encoding with GAN for structural ranges
- 구조적 범위에 대해 GAN을 활용한 인코딩
- GAN은 생성기 와 판별기 , 두 adversarial module로 구성됨.
- 위의 수식을 확인해보면, 판별기 는 실제 or 가짜 Label을 맞추도록 학습함.
- 생성기 G는 동시에 = 를 최소화함으로써 를 속이도록 학습함.
📌 생성기는 실제 이미지를 생성하도록 향상 시키는 역할
📌 판별기는 실제 이미지와 생성한 이미지를 정확히 구분하도록 학습하는 역할
2. Mapping New Images to the Latent Space
- 새로운 이미지를 잠재 공간에 매핑함.
- 이는 새로운 이미지를 그 이미지의 핵심 특성을 포착하는 저차원의 벡터로 변환하는 과정을 의미함.
- AnoGAN은 매핑 과정을 최적화하는 방법을 제안하여, 주어진 이미지가 얼마나 "정상적"인지를 판단하는 데 사용함.
- 경쟁 학습이 완료되면 생성기는 잠재 공간 표현 에 해당하는 (정상) 이미지 x로의 매핑을 학습함.
- 이미지 가 주어졌을 때, 실제와 유사하고 Manifold X에 위치하도록 하는, 이미지 에 해당하는 잠재 공간의 점 z를 찾고자 함.
- (실제 이미지)와 (생성된 이미지)의 유사도는 Query Image가 생성기 G 학습에 사용한 데이터의 분포를 얼마나 따르냐에 달려있음.
- 가장 유사한 이미지 를 얻기 위해 잠재 공간 안에 있는 위치 를 최적화 진행
3. Loss Function
Residual Loss
- 생성한 이미지 와 Query 이미지 사이의 시각적 유사도를 제어
- 만약 생성기 G와 잠재공간으로의 Mapping이 완벽하면, residual loss는 0이 됨.
Discrimination Loss
- 생성한 이미지 가 학습한 Manifold X에 위치하도록 제한
- Traning Data 분포를 따르도록 학습하는 단계
- Feature Matching에 기반한 Discrimination Loss 개선
- 이를 계산할 때 discriminator가 scalar 값을 주는 게 아닌 richer intermediate feature representation을 사용
📌 정리
- Feature Representation의 풍부한 정보 사용
- discriinator를 분류기 사용 X, fature extractor 개념으로 사용
- Latent Space Mapping을 위해, Loss는 Residual Loss와 Descriminator Loss의 가중합으로 계산
- z와 coefficient만 backpropagation을 통해 조정되고 학습된 파라미터들은 고정됨.
4. Detection of Anomalies
- Anomaly socre는 매핑 손실 함수로부터 바로 유도 가능
4. Experiments
Dataset
- 의학 고해상도 SD-OCT Dataset
Evaluation
- 모델이 사실적인 이미지를 생성할 수 있는가?
- 접근법의 이상치 탐지 정확도를 정량적 평가
(Anomaly score, ROC curve로 성능 측정)
4.1. Results
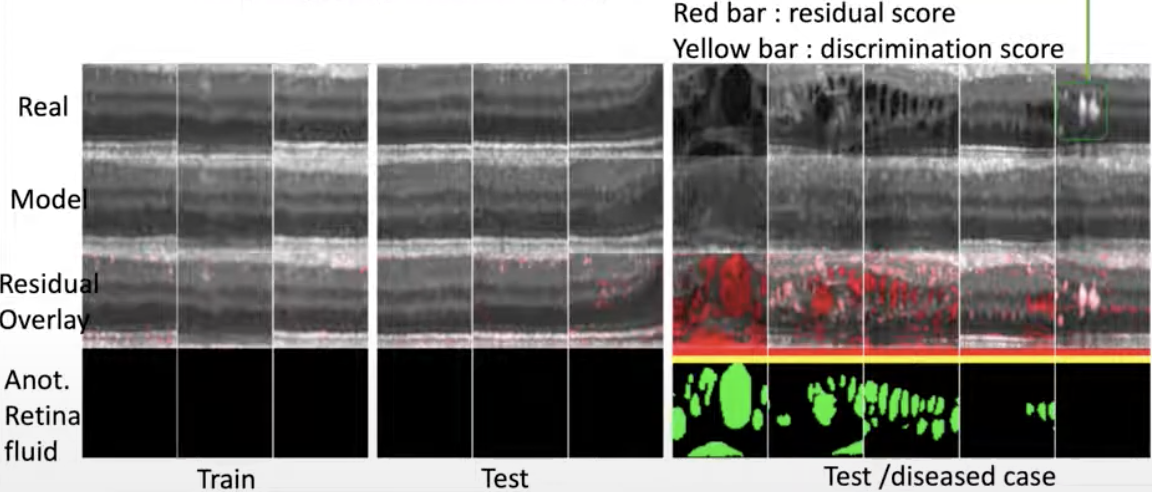
모델이 사실적인 이미지를 생성할 수 있는가?
- 매핑을 통해 잠재 표현으로부터 실제와 비슷한 의료 영상 두번째 행을 생성함.
- Abnormal Data의 경우, 텍스처 차이가 나타남. (3번째 행)
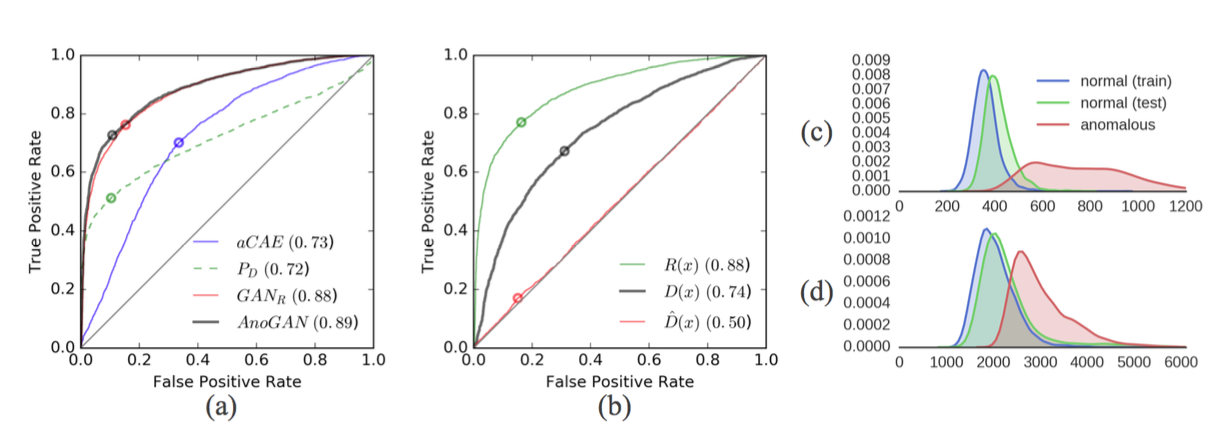
모델이 이상치를 잘 탐지할 수 있는가?
- normal data의 경우 정규 분포를 띄고, abnormal data의 경우 분포가 이상함.
다른 접근 방법이 비해 성능은?


- AnoGAN의 성능이 대체적으로 좋았음.
5. Conclusion
- 논문에서는 Deep GAN을 기반으로 한 이상치 탐지 방법을 제안함.
- Generative Model과 Discriminator를 동시에 학습
-> 훈련 데이터에는 없는 새로운 데이터에서도 이상치를 식별할 수 있음.
-> 정상을 나타내는 데이터를 비지도 방식으로 학습
-
훈련 중에는 결코 볼 수 없었던 알려진 이상치들, 예를 들면 망막 유체나 HRF와 같은 것들도 탐지할 수 있음.
-> 따라서 이 모델은 새로운 이상 병변을 발견하는 데에도 이상치를 발견할 수 있을 것으로 예상됨. -
이상치 클래스의 부분 집합을 기반으로 한 정량적 평가는 제한적이지만, 결과는 좋은 감도를 보여주며 이상치를 세분화하는 능력을 보여줌.
- 대규모로 이상치를 발견함으로써 향후 검증을 위한 마커 후보의 데이터 마이닝이 가능해짐.
- 이전의 연구와는 대조적으로, Residual Loss만을 사용하여 이미지에서 잠재 공간으로의 좋은 매핑 결과를 얻을 수 있었고, 제안한 방법으로 결과를 약간 개선시킬 수 있음.
🎯 Summary
- 저자가 뭘 해내고 싶어 했는가?
- Deep GAN을 기반으로 한 이상치 탐지 방법을 제안
- 특히 훈련 데이터에는 없는 새로운 데이터에서도 이상치를 식별할 수 있는 방법을 개발하려고 했음.
- 이 연구의 접근 방식에서 중요한 요소는 무엇인가?
- GAN을 사용하는 것.
- Generative Model과 Discriminator을 동시에 학습하여 정상 데이터만을 사용하여 모들 훈련 후에도 이상치 탐지를 할 수 있게 함.
- 이미지를 잠재 공간으로 매핑할 때 Residual Loss만을 사용하는 것
- 어느 프로젝트에 적용할 수 있는가?
- 의료 영상에서의 이상치 탐지
- 참고하고 싶은 다른 레퍼런스에는 어떤 것이 있는가?
- GAN
- DCGAN
- 느낀점은?
- 이상치 탐지 분야에 GAN을 도입하여 이상치를 찾아내는 좋은 논문이었다. 생각보다 재밌게 읽었고 역시 정리하려니까 시간이 조금 걸렸다.
- 이미지를 잠재 공간으로 매핑하는 과정의 수식을 다시 공부해봐야겠다.
- 다음 이상치 탐지 논문도 기대된다!!!
📚 References
논문
Youtube
- https://youtu.be/XutSxX-H5Xs?si=j65TIyJV55GKZVF6, 고려대학교 DSBA 연구실
