[논문리뷰 | NLP ] MASS: Masked Sequence to Sequence Pre-training for Language Generation (2019) Summary
[논문리뷰]
목록 보기
36/42
Title
- MASS: Masked Sequence to Sequence Pre-training for Language Generation (2019)

1. Introduction
1.1. 논문이 다루는 Task
- Encoder & Decoder를 jointly Pre-training 시켜 자연어 생성 Task에 적합한 모델 개발
- BERT에 영감을 받아 Encoder-Decoder 기반 언어 생성을 위한 MASS 제안
- 특히 dataset이 적은 자연어 생성 Task에서 성능 향상 Good
-> Text summarization, Neural Machine translation 등 zero/Low resource 데이터셋에 대한 작업 수행
1.2. 기존 연구 한계점
- BERT는 MLM과 NSP를 통해 양방향 Encoder를 사전학습하여 NLU Task에서 SOTA를 달성
- 하지만 NLU Task 외에 자연어 생성 Task가 있는데, 이때 BERT를 적용하는 것은 불가능
- 자연어 생성 Task를 위한 사전 훈련 방법을 설계하는 방법이 매우 중요함
-> 자연어 생성을 위해 pre-training 방법을 쓰고 싶었으나 BERT를 바로 쓸 수 없으니 문제
-> MASS 제안
2. Related Work
a. Pre-training for NLP Tasks

- BERT와 XLNet
🎈 텍스트 이해를 위해 Encoder를 Pre-training
- GPT
🎈 언어 모델링을 위해 Decoder를 Pre-training
- 이전 모델들
🎈 Encoder, Attention, Decoder를 함께 X
b. Encoder - Attention - Decoder
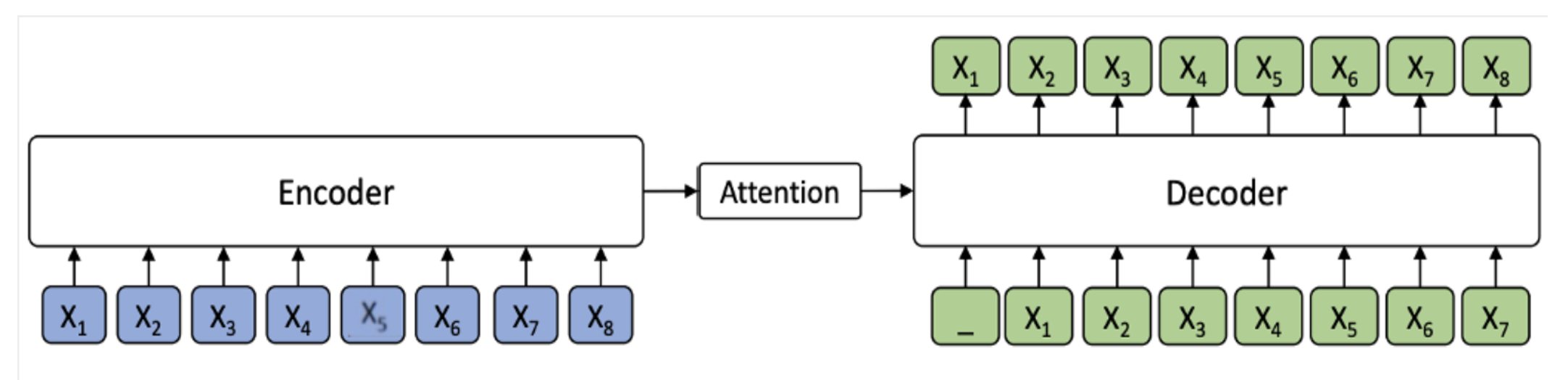
- 자연어 생성 Task는 Encoder – Attention – Decoder 구조의 모델 사용
🎈 Seq2seq learning framework 기반
- Encoder는 Source sequence X를 input으로 받은 후, 이를 hidden representations sequence로 변형
🎈 Source Sentence를 읽고 representation 생성
- Decoder는 Encoder로부터 hidden representations sequence를 전달 받아 Target Sequence Y를 생성
Source 표현과 이전 tokens가 주어진 경우 각 대상 토큰의 조건부 확률을 추정
🎈 이때 Attention Mechanism이 학습한 Input에 대한 정보를 함께 참고 Encoder
c. BERT vs MASS
(1) BERT는 텍스트의 문맥을 이해 적합 <-> MASS는 자연어 생성 Task에 적합
(2) BERT는 Masked Language Model 사용 <-> MASS는 Masked Sequence to Sequence 사용
(3) BERT는 감정분석, 문장 분류 분야 <-> MASS는 번역, 요약 등 언어 생성 분야
3. 제안 방법론
3.1. Main Idea
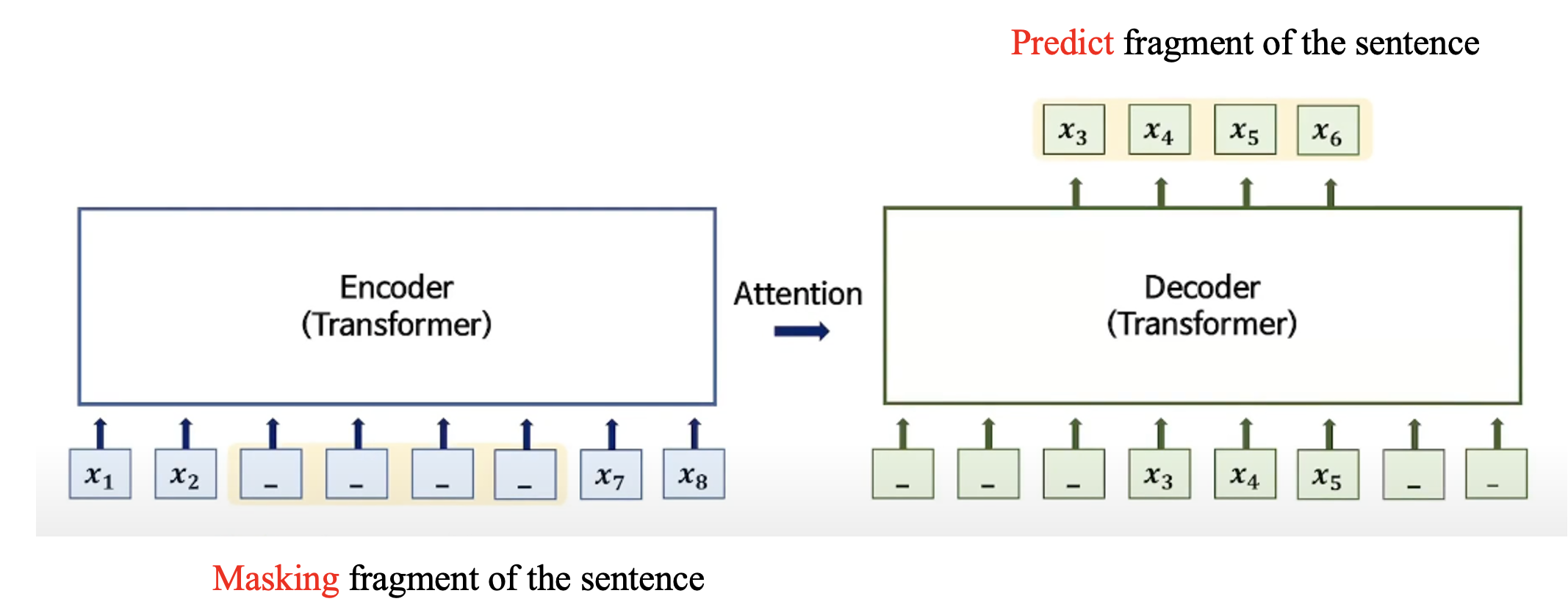
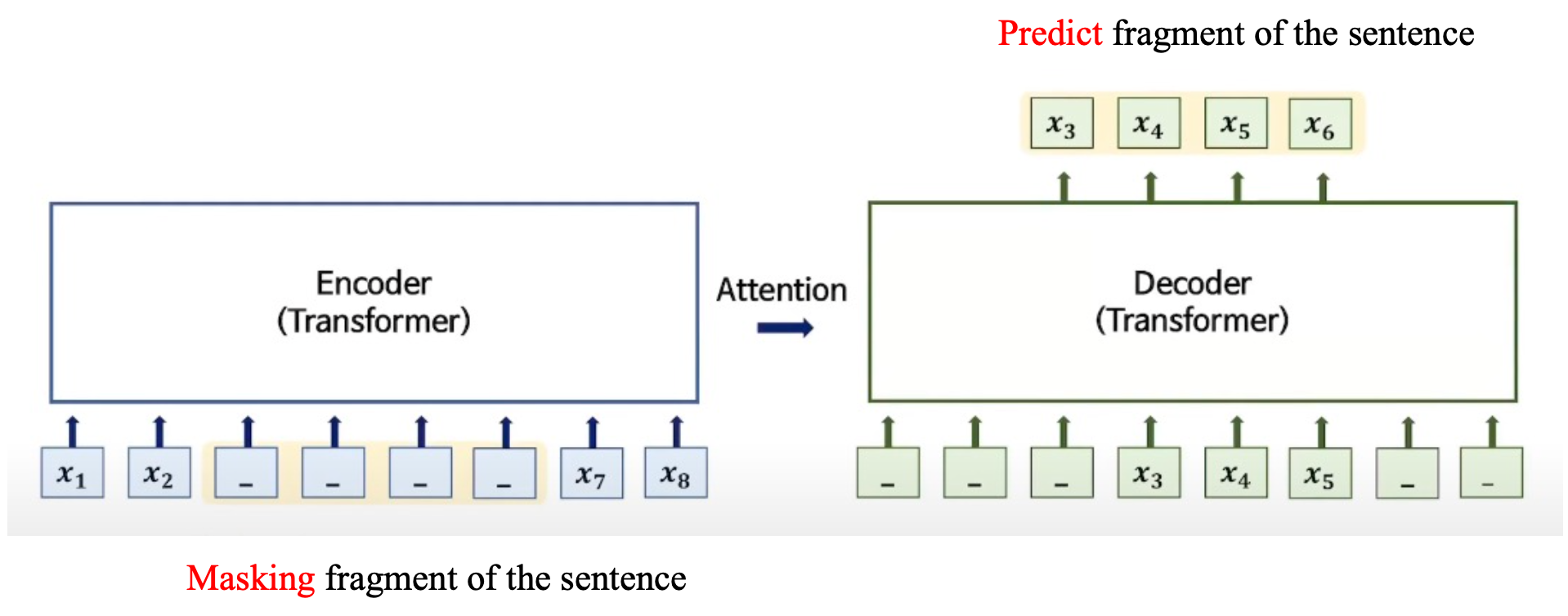
- Random하게 Input Sentence에 연속적인 Mask를 부여한 뒤 Decoder가 Predict
3.2. Contribution
- Encoder와 Decoder의 input을 다르게 함으로써 Decoder가 Encoder에 더 의존할 수 있도록 함
4. 실험 및 결과
4.1. Dataset
Model Configuration
- 6개의 Encoder, Decoder Layer를 가진 Transformer를 Base Model로 선택
Datasets
- WMT News Crawl Dataset 사용
- English, French, German, Romanian에 대해서 Pre-train 진행
Pre-Training Details
- BERT와 동일한 masking rule 채택
- Adam Optimizer 사용 / lr 0.0001 / batch size 3000
4.2. Baseline
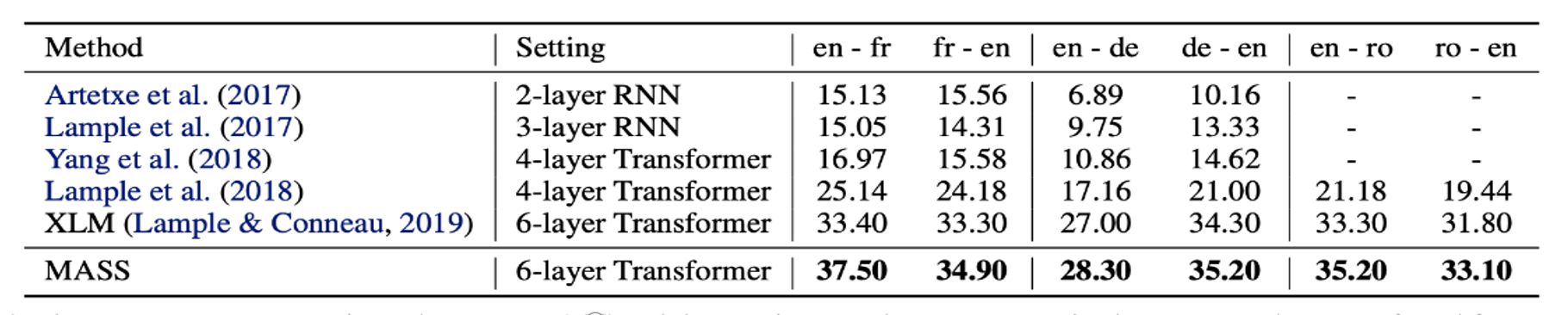
a. Results on Unsupervised NMT
b. Compared with Other Pre-training Methods
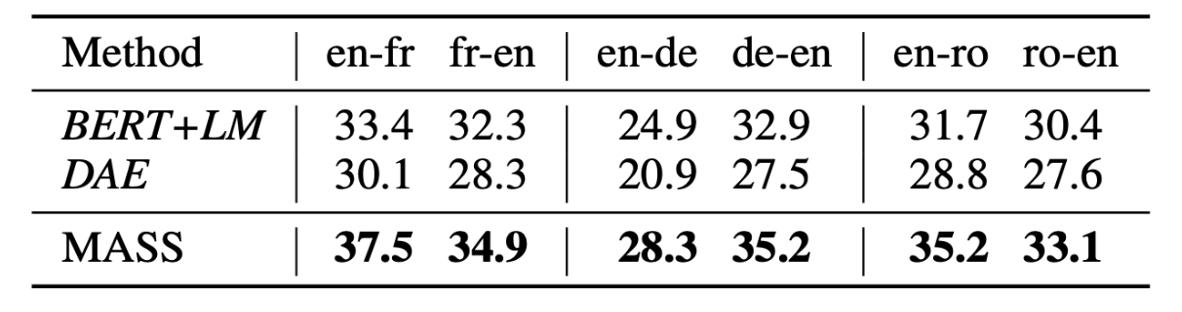
c. Experiments on Low-Resource NMT

- Bilingual dataset의 sample 크기가 10K, 100K, 1M인 경우에 대해서 각각의 언어에 대해 성능 측정
- MASS가 baseline model을 압도했고, 특히 sample의 크기가 작을수록(fine-tuning을 적게 수행할수록) 성능의 차이가 많이 차이남
d. Fine-Tuning on Text Summarization

- Gigaword Corpus를 fine tuing data로 사용
- 10K, 100K, 1M, 3.8M의 경우에 대해서 실험
- ROUGE-1, ROUGE-2, ROUGE-L에 대한 F1 score로 성능 측정
- 데이터셋이 적은 경우에 대해서 성능차이 큼
e. Study of Different K
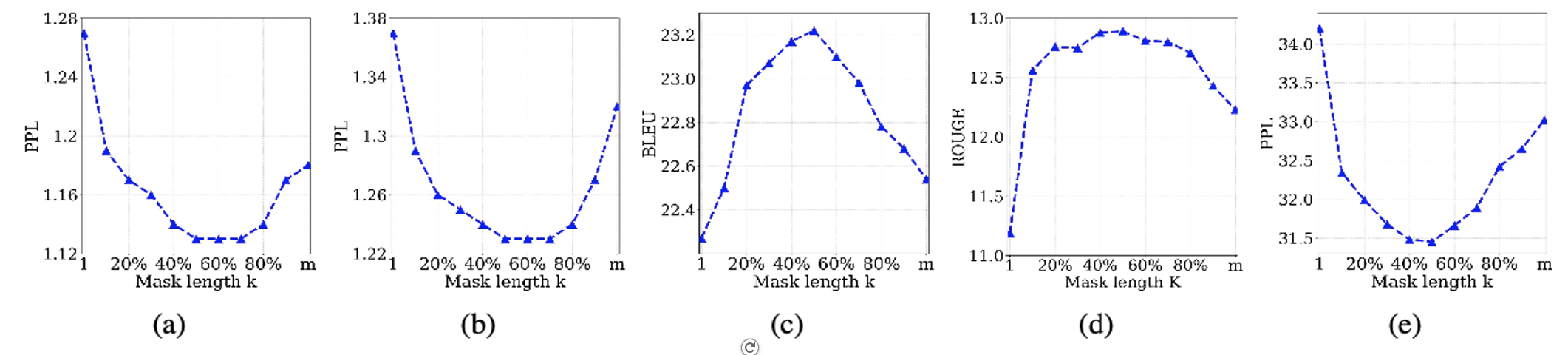
- K의 값 변화에 따른 Score들을 측정함
- K가 mask의 50%인 구간에서 가장 좋은 수치
- K값 감소 -> masking 감소 -> Encoder Input 변형 감소 -> Decoder Input 감소
-> Encoder 의존도 증가
- K값 증가 -> masking 증가 -> Encoder Input 변형 증가 -> Decoder Input 증가
-> Decoder 의존도 증가
4.3. 결과
- MASS는 Seq2seq 기반의 다양한 Language Generation Task에서 좋은 성능을 기록
- MASS가 BERT와 XLNet에서 좋은 성능을 기록한 NLU Task에서도 좋은 성능을 보일 것인지 차후 실험해볼 예정
- MASS 모델이 Image와 Video와 같은 다른 도메인에서 Seq2seq 기반의 생성 Task를 수행해낼 수 있을지에 대한 추가 실험 진행 예정
4.4. 결론 (배운점)
- Encoder에 Random하게 연속적인 Mask를 부여한 뒤 Decoder에서 Predict하는 방식이 자연어 생성 Task에 적합하다는 것을 알게 됨.
📚 References

AI 전문가가 되기 위해 [a-zA-Z]까지 정리하는 거나입니다 😊