[논문리뷰 | NLP ] ALBERT: A Lite BERT for Self-supervised Learning of Language Representations (2020) Summary
[논문리뷰]
목록 보기
40/42
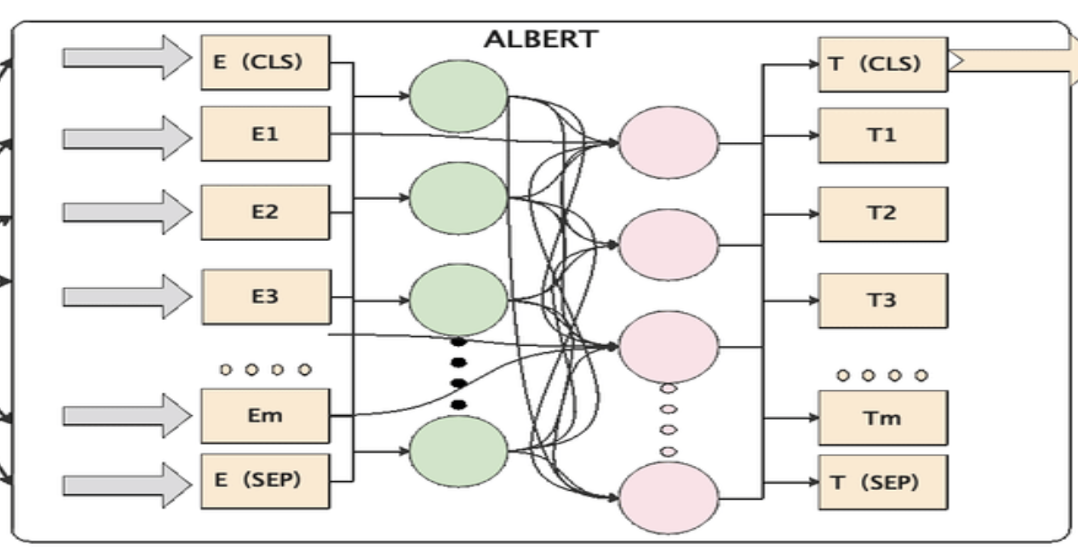
(Youtube) NLP 논문 리뷰📎 ALBERT(2019) : A Lite BERT for Self-supervised Learning of Language Representations 를 참고해주세요!!!!
Title
- ALBERT: A Lite BERT for Self-supervised Learning of Language Representations (2020)

1. Introduction
1.1. 논문이 다루는 Task
모델의 경량화-> 모델 크기 증가를 막는 Memory Limitation 극복
1.2. 기존 연구 한계점
- Pre-training 시 모델의 크기가 커지면 성능이 향상되지만, 메모리 제한 & 연산 시간 증가
- Memory Limitation
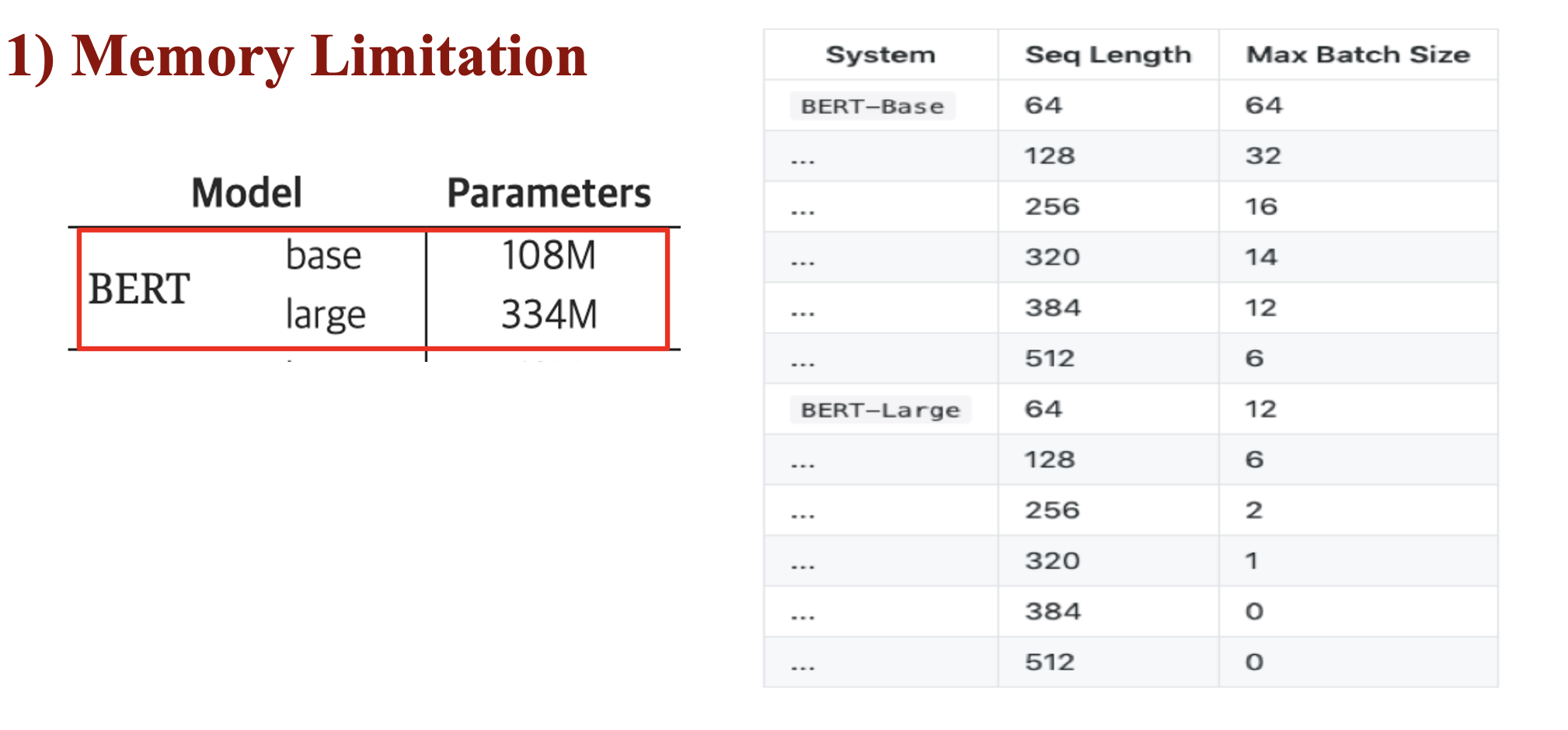
- Training Time

- GPT3 or BERT 등의 모델은 수억개의 달하는 파라미터를 사용하기 때문에 OOM(Out-Of Memory) 문제를 자주 직면함
- 분산 학습을 통해 해결하려고 해도, 분산된 장비간의 통신과정에서 학습속도가 저하되기 때문에, 문제가 있음
2. Related Work
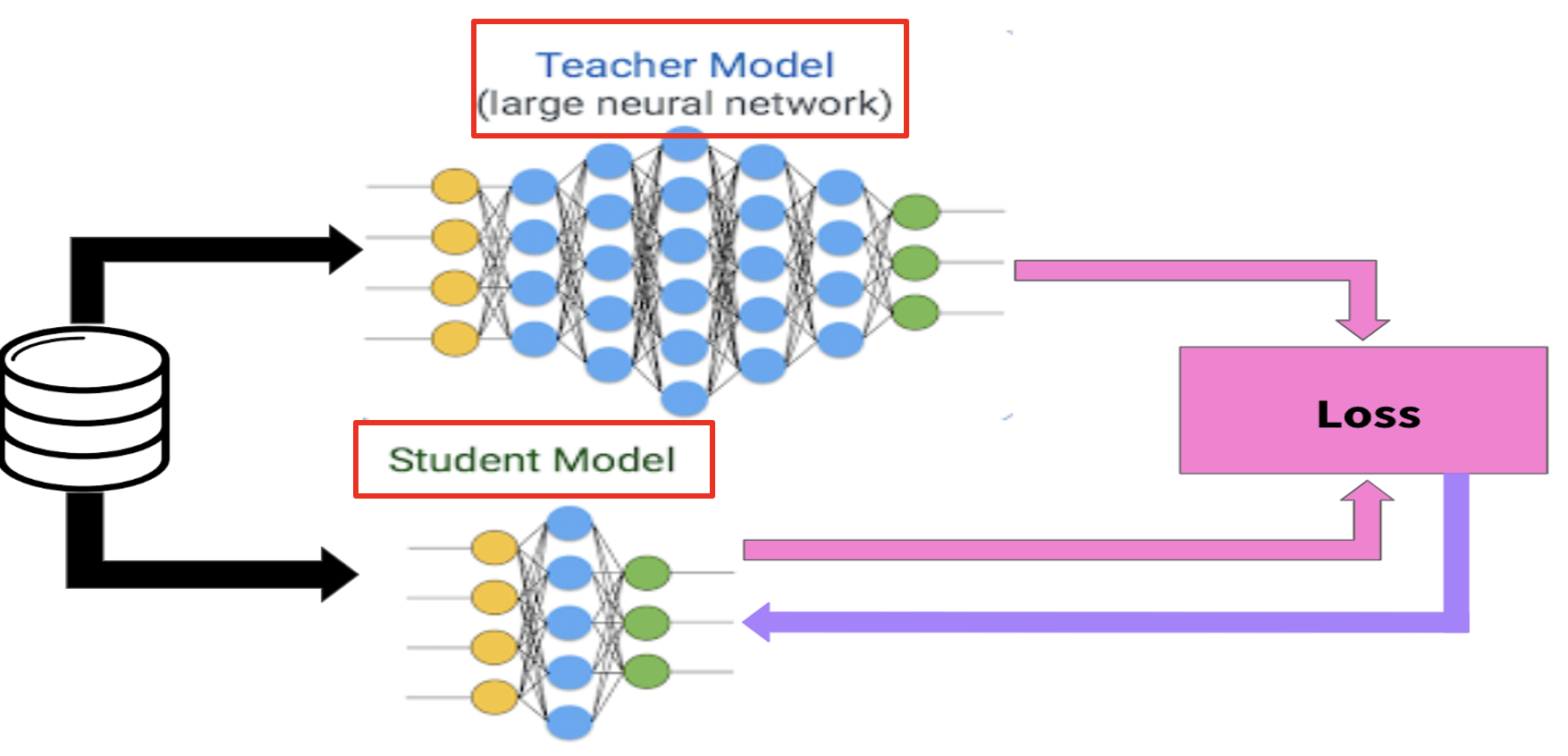
-
BERT를 기반으로 한 모델의 변형은 다양한 NLP Task에서 좋은 성능을 보임.
-
모델의 성능을 높이기 위해서는 거대한 모델을 꼭 사용해야 할까??
- 거대한 모델을 사용해 먼저 훈련을 수행한 뒤, 더 작은 모델로 미리 학습하는 모델 등장
🎈 Teacher-Student Network
🎈 미리 잘 학습된 큰 네트워크의 지식을 실제로 사용하고자 하는 작은 네트워크에게 전달하는 증류(Distillation) 하는 것이 일반적인 관행이 됨
3. 제안 방법론
3.1. Main Idea
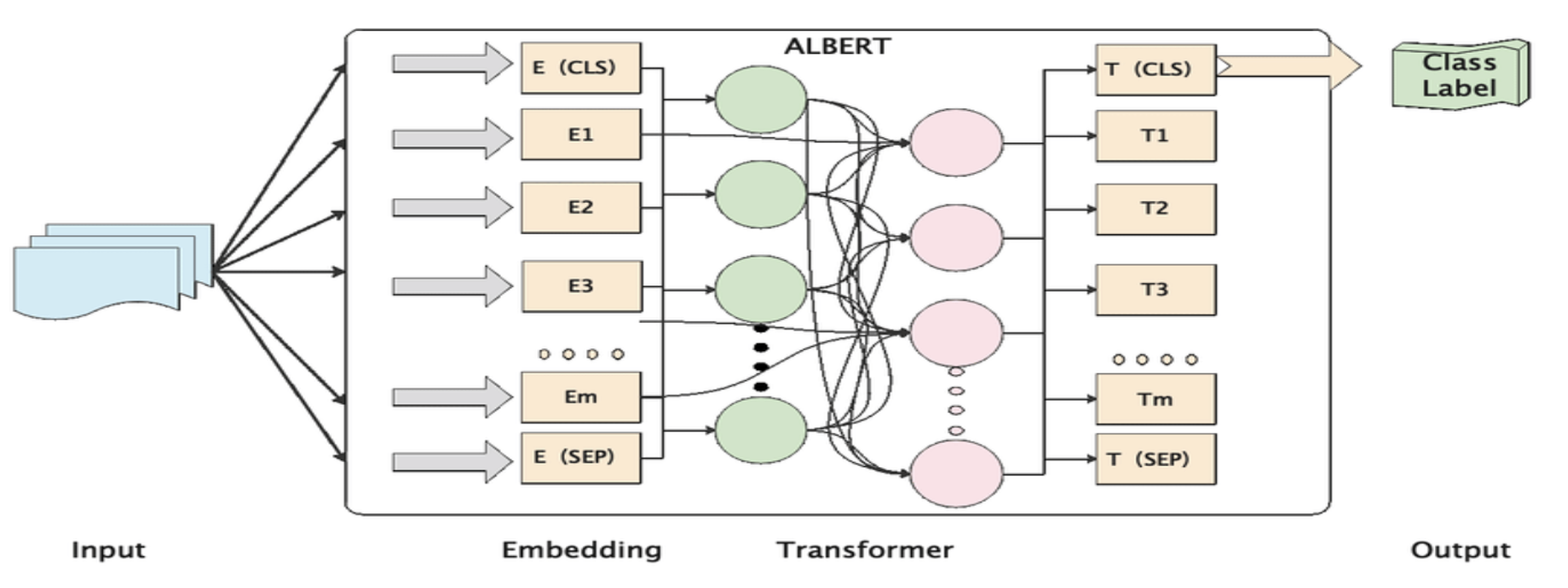
- ALBERT는 앞선 언급한 한계점을 극복하기 위해 BERT에서 모델의 크기를 줄일 수 있는 방법(2가지)과 NSP 대신 SOP 제안
3.2. Contribution
1) Factorized Embedding Parameterization

- V = Vocabulary size
- H = Hidden state dimension
- E = Word embedding dimension
- ALBERT는 embedding parameter를 factorization하여 2개의 작은 행렬로 인수분해(분리)
🎈 One-Hot vector를 H의 vector로 바로 projection 하지 않고, Embedding 크기의 저차원 vector로 거쳐 projection 진행
- O(V x H) -> O(V x E + E x H)로 줄일 수 있음
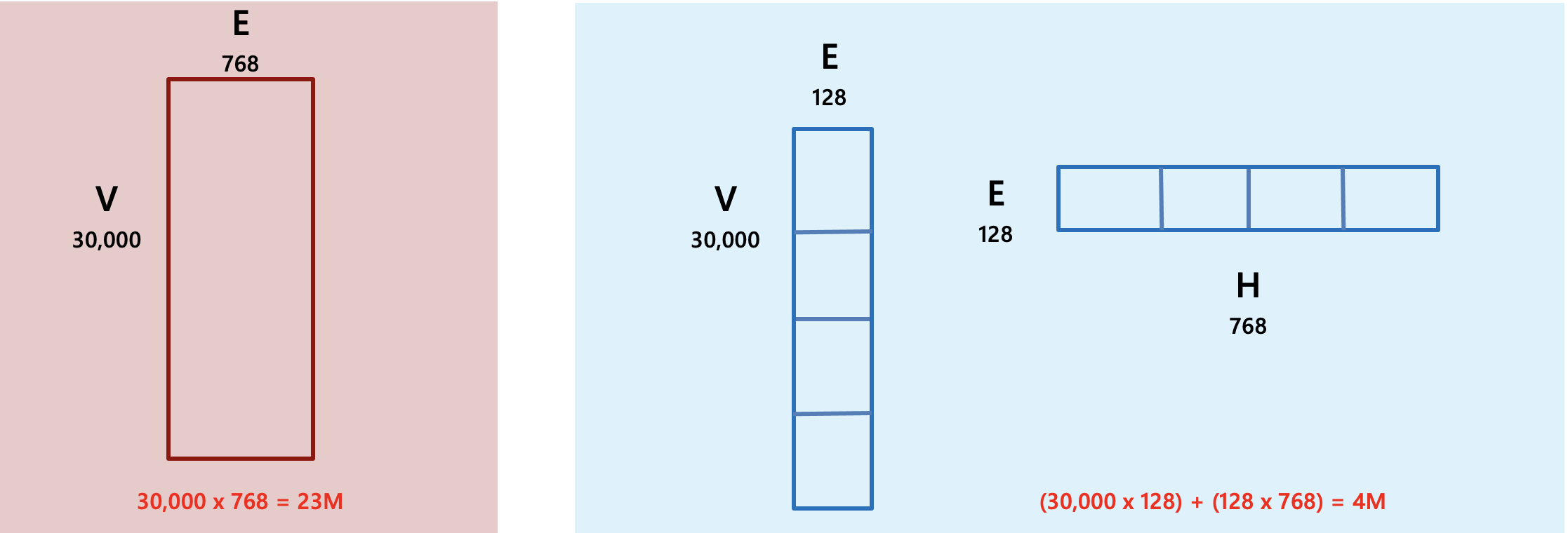
- 왼쪽은 BERT Base, 오른쪽은 ALBERT Base임
- 이는 V=30000 및 E=768이 있는 BERT 기반의 워드 임베딩에서 약 23M으로 전체 파라미터 108M의 21%를 차지하여 상당히 큰 부분을 차지
- 인수분해 임베딩 매개변수화 후 매개변수 수는 O(V×E+E×H)로 결정
- 이는 V=30000, E=128, H=768을 기준으로 약 4M으로 기존 방식의 약 1/6 수준으로 볼 수 있음
2) Cross-Layer Parameter Sharing

- Transformer Layer 간 같은 Parameter를 공유하며 사용하는 것을 의미
🎈 ALBERT에서는 Layer의 모든 Parameter를 공유
🎈 Attention, FFN 등의 모든 Parameter를 Layer 간 공유
🎈 Layer 수가 늘어나더라도 Parameter 수가 늘어나지 않음
- 이는 Universal Transformer와 같음
🎈 Transformer의 각 Layer의 output이 다시 Input으로 들어가는 형태
🎈 이를 Recursive Transformer라고 부름
- 위의 그림의 왼쪽은 Transformer Encoder, 오른쪽은 Universal Transformer임
🎈 기존의 BERT는 Transformer Block을 1~12번 거쳤음
🎈 ALBERT에서는 이와 같은 효과를 누리기 위해 단 하나의 Transformer Block을 12번 거침
🎈 하나의 Layer가 여러층의 Layer의 기능을 모두 할 수 있도록 학습될 것을 기대

3) Sentence Order Prediction

- 기존의 BERT는 문장과 문장이 서로 연속된 문장인지 맞추는 NSP 사용
- ALBERT에서는 2개의 문장의 순서를 맞추는 Sentence Order Prediction(SOP) 사용
🎈 Negative Example -> 앞, 뒤 문장의 순서를 바꾸어서 구성
🎈 문장 사이의 순서를 self-supervised loss를 통해 학습시켜 문장 간의 coherence을 효율적으로 학습
🎈 Topic이라도 문장 간 순서를 고려하므로 discourse level coherence를 반영
4. 실험 및 결과
4.1. Dataset
Training Data (16GB)
- Book Corpus, Wikipedia -> BERT와 같음
Datasets
- GLUE 9 tasks / SQUAD 1.1., 2.0 / RACE
Batch size
- 4096
Steps
- 125,000 Steps
GPU
- TPU v3
4.2. Baseline
a. Memory Limitation & Training Time
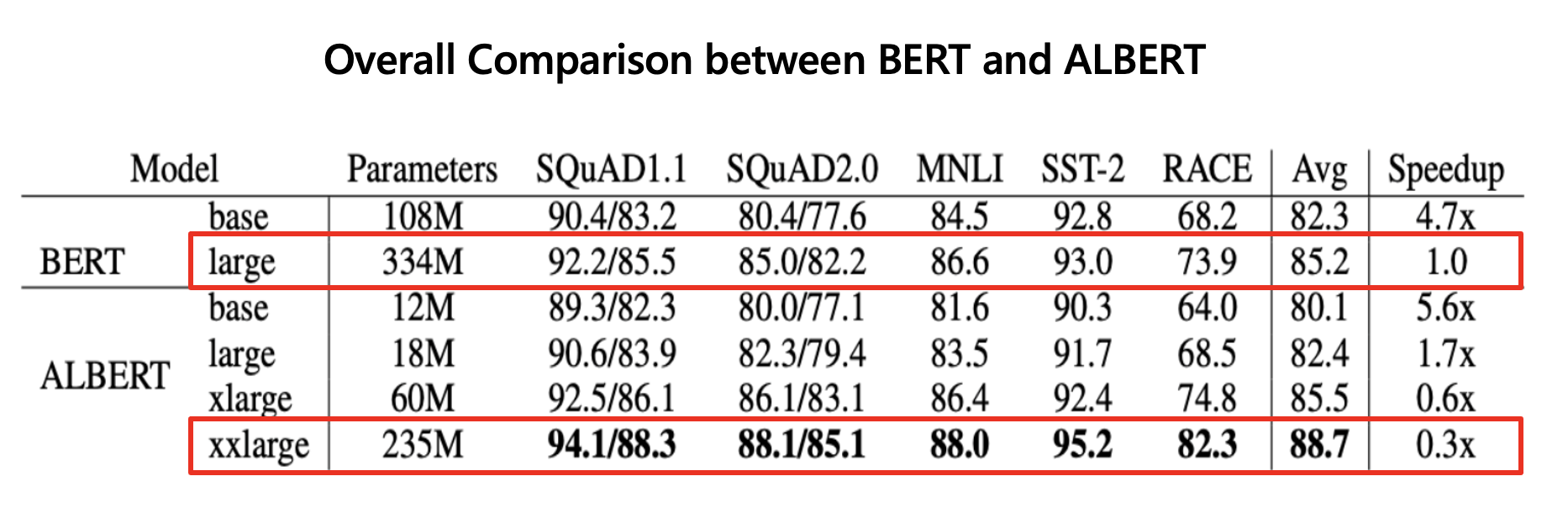
- 위의 표와 같이 BERT보다 ALBERT가 훨씬 적은 파라미터를 사용하는 것을 확인할 수 있음
- ALBERT는 BERT와 같은 Layer 수, Hidden size에서 모델의 크기가 훨씬 작음
- layer 수, Hidden size가 같을 때 ALBERT는 BERT 보다 학습 속도가 훨씬 빠름
b. Factorized Embedding Parameterization
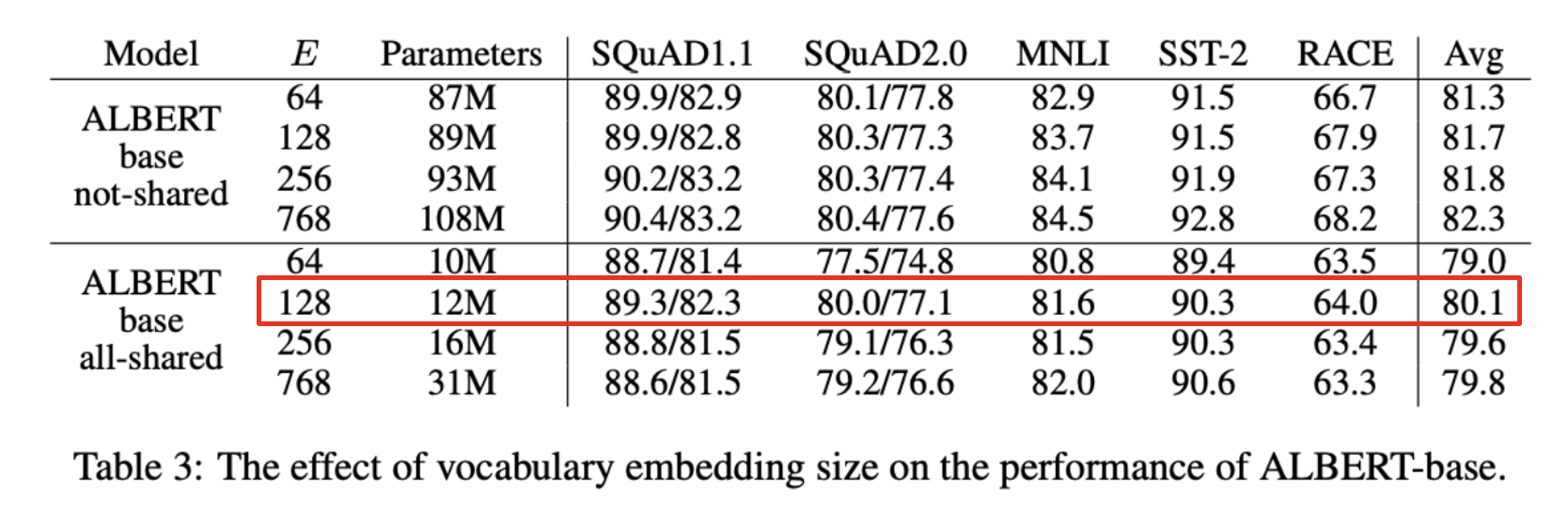
- Downstream Task에서 embedding size를 변경하며 ALBERT의 성능을 확인함
- 파라미터를 공유하지 않는 BERT style에서는 embedding size가 클수록 모델 성능이 증가하지만, 상승폭이 크지 않음
- 파라미터를 공유한 ALBERT-style에서는 128 size가 가장 좋은 결과를 보여줌
🎈 이후 실험에서는 Embedding 128 size를 사용함
c. Cross-Layer Parameter Sharing
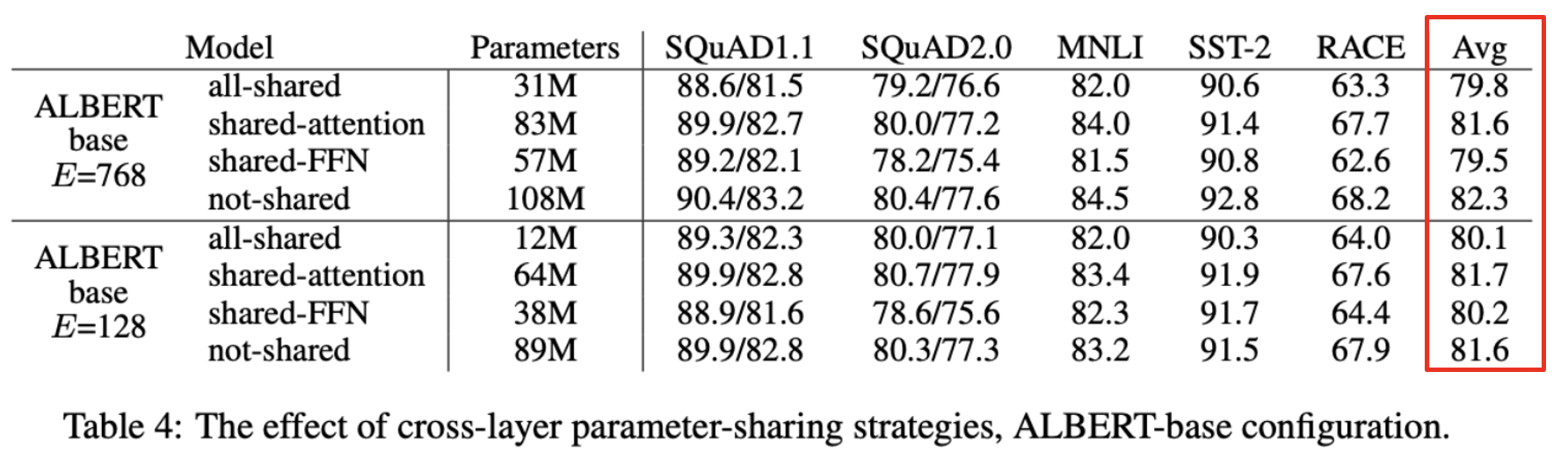
🎈 모든 Layer에서 공유
🎈 Attention parameter만 공유
🎈 FFN parameter만 공유
🎈 Not-shared
- 공유하는 파라미터가 증가할수록 전체 파라미터 수는 감소하지만 성능이 저하됨
d. Sentence Order Prediction

- SOP가 multi-sentence encoding 문제를 더 잘 해결할 수 있음을 확인함
e. What if we train for the same amount of time?

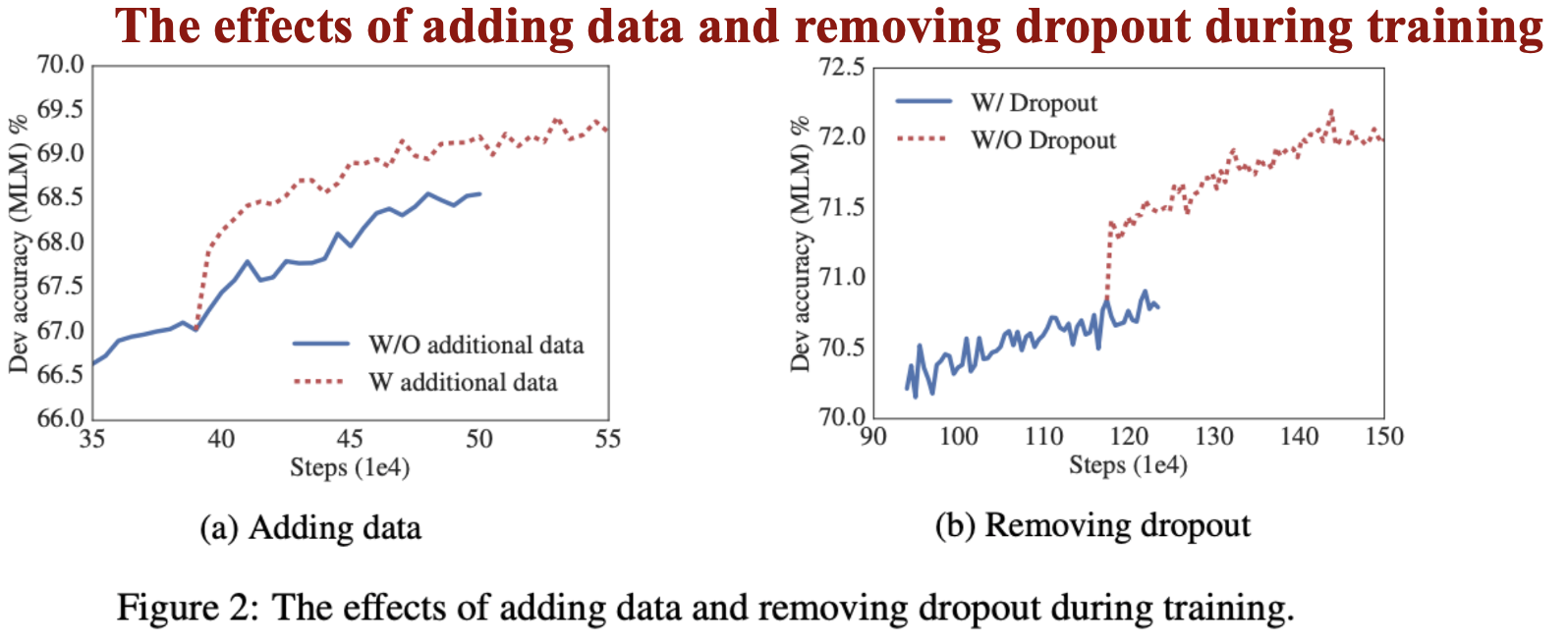
f. Additional training data and dropout effects

g. The effects of adding data and removing dropout during training
h. Current State-of-the-art on NLU Tasks
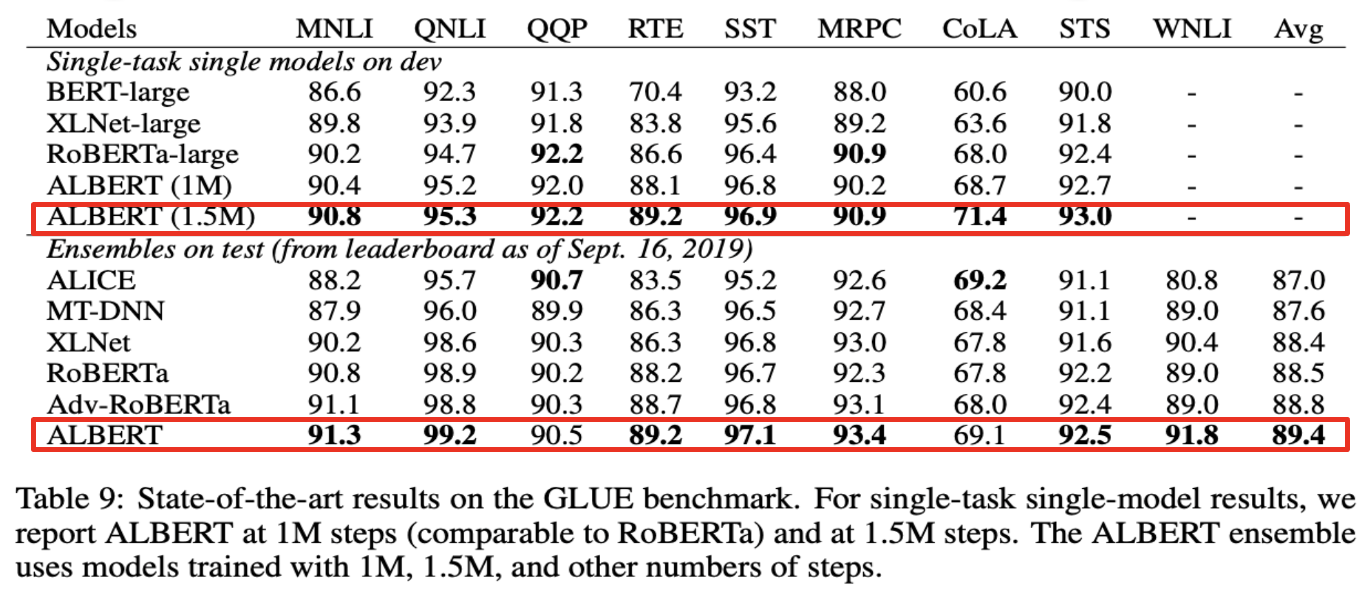
4.3. 결과
- GLUE, SQuAD, RACE Task에서 BERT보다 좋은 성능을 보임
- 모델을 경량화 함으로써, 모델 크기 증가를 막는 Memory Limitation을 극복함
4.4. 결론 (배운점)
- Cross-Layer Parameter Sharing 함으로써 Transformer의 각 Layer 간 같은 Parameter를 공유하여 사용함으로써 모델 size를 줄이는게 흥미로웠음. 하나의 Layer가 여러층의 Layer의 기능을 모두 할 수 있도록 학습 하는 점이 인상깊음.
📚 References

AI 전문가가 되기 위해 [a-zA-Z]까지 정리하는 거나입니다 😊