다중로지스틱회귀 실습
1. 타이타닉 데이터 실습
1) 데이터 생성 및 라이브러리 설치
2) X변수 선정
- y(Survived) : 상망
- X(수치형) : Fare
- X(범주형) : Pclass(좌석등급), Sex
3) 결과값 도출 과정 함수화
4) 범주형 데이터 수치화
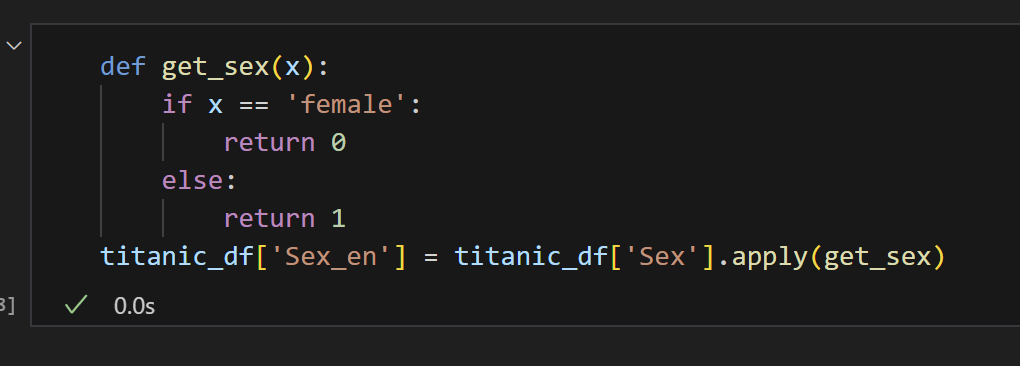
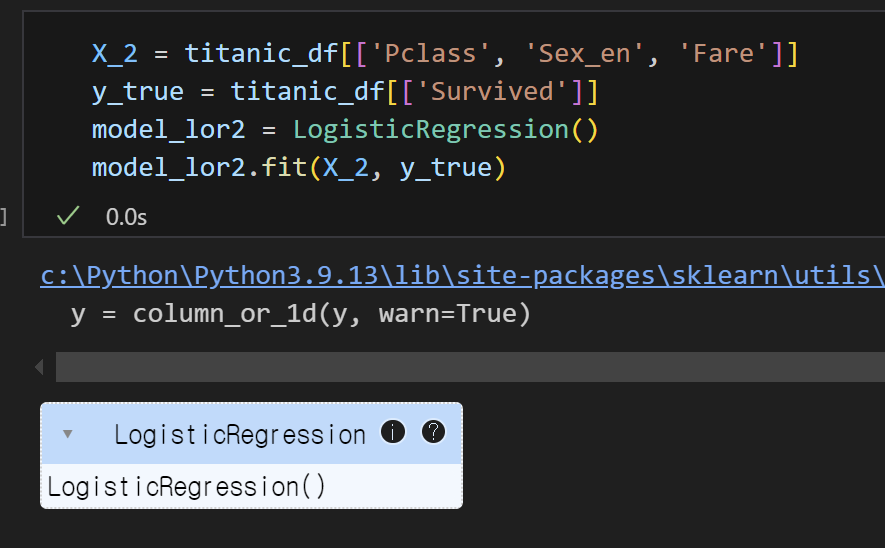
5) 로지스틱회귀모델 불러오고, 데이터 훈련하기
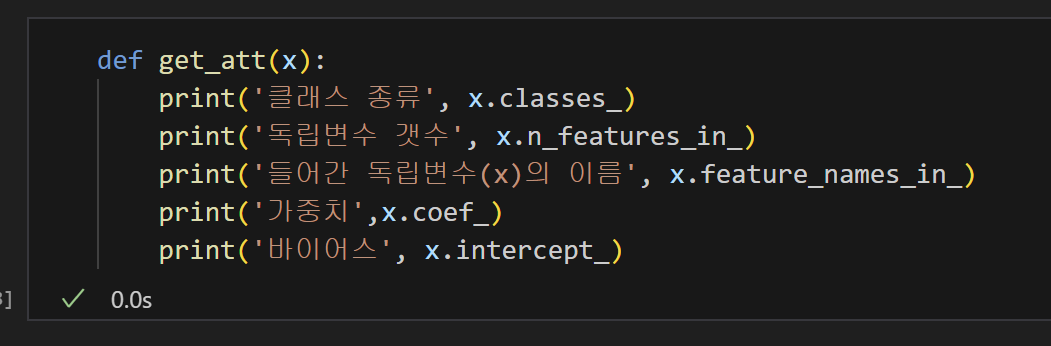
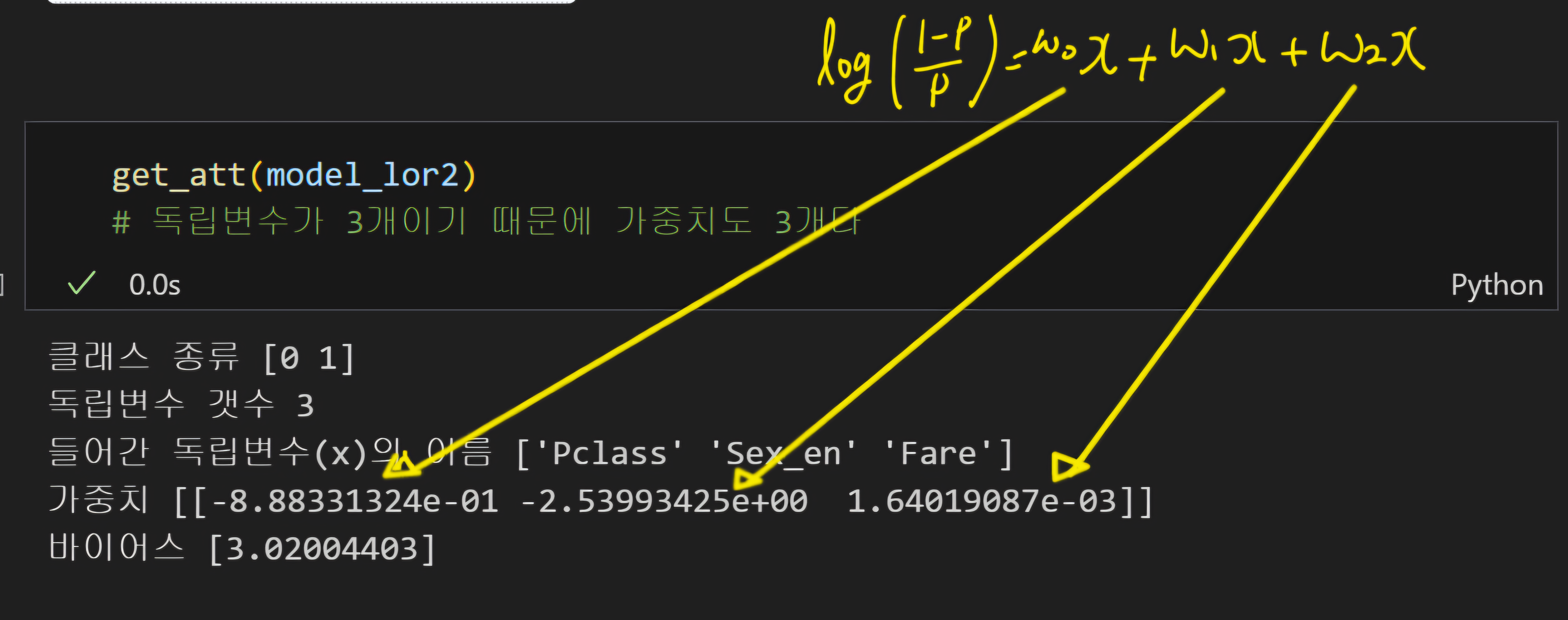
6) 가중치, 바이어스, 변수 확인
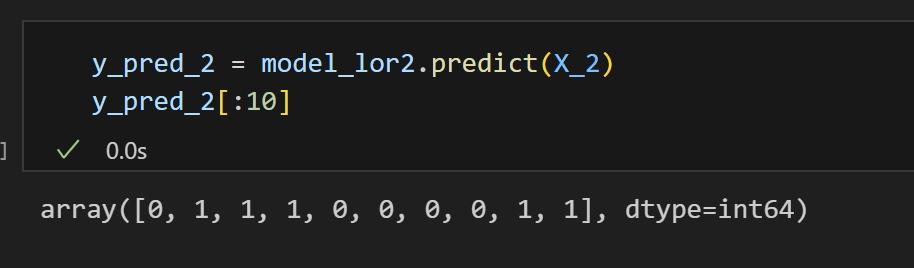
7) 예측 컬럼 생성
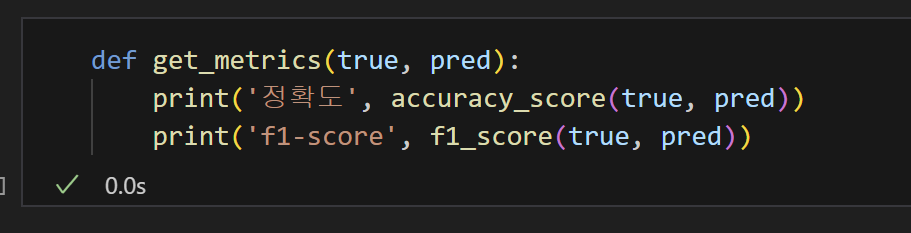
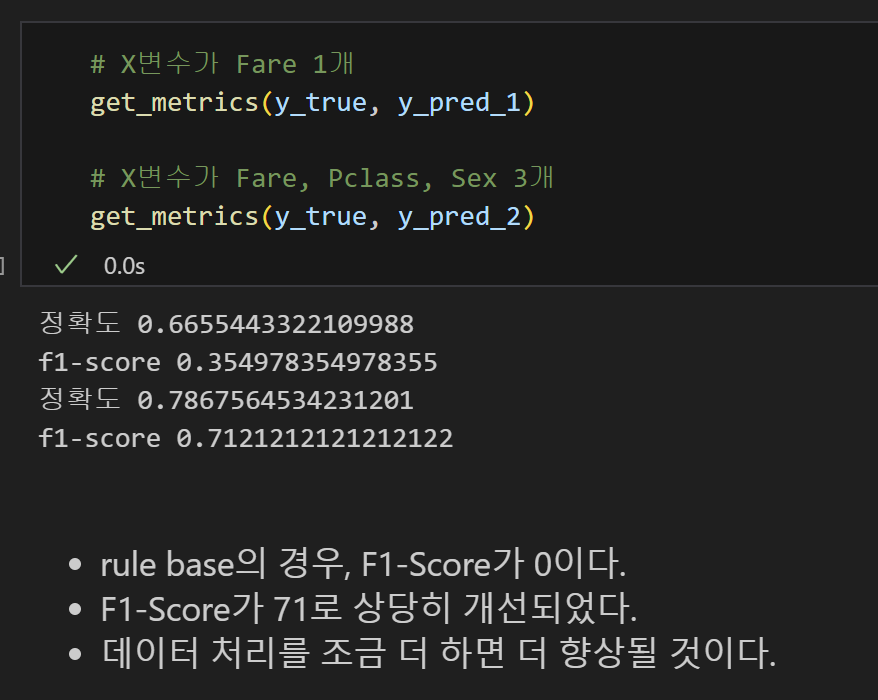
8) 평가 : Accuracy, F1-Score
- 단순선형회귀분석 모델에 비해 다중선형회귀분석 모델은 정확도와 F1-Score가 크게 향상되었다.
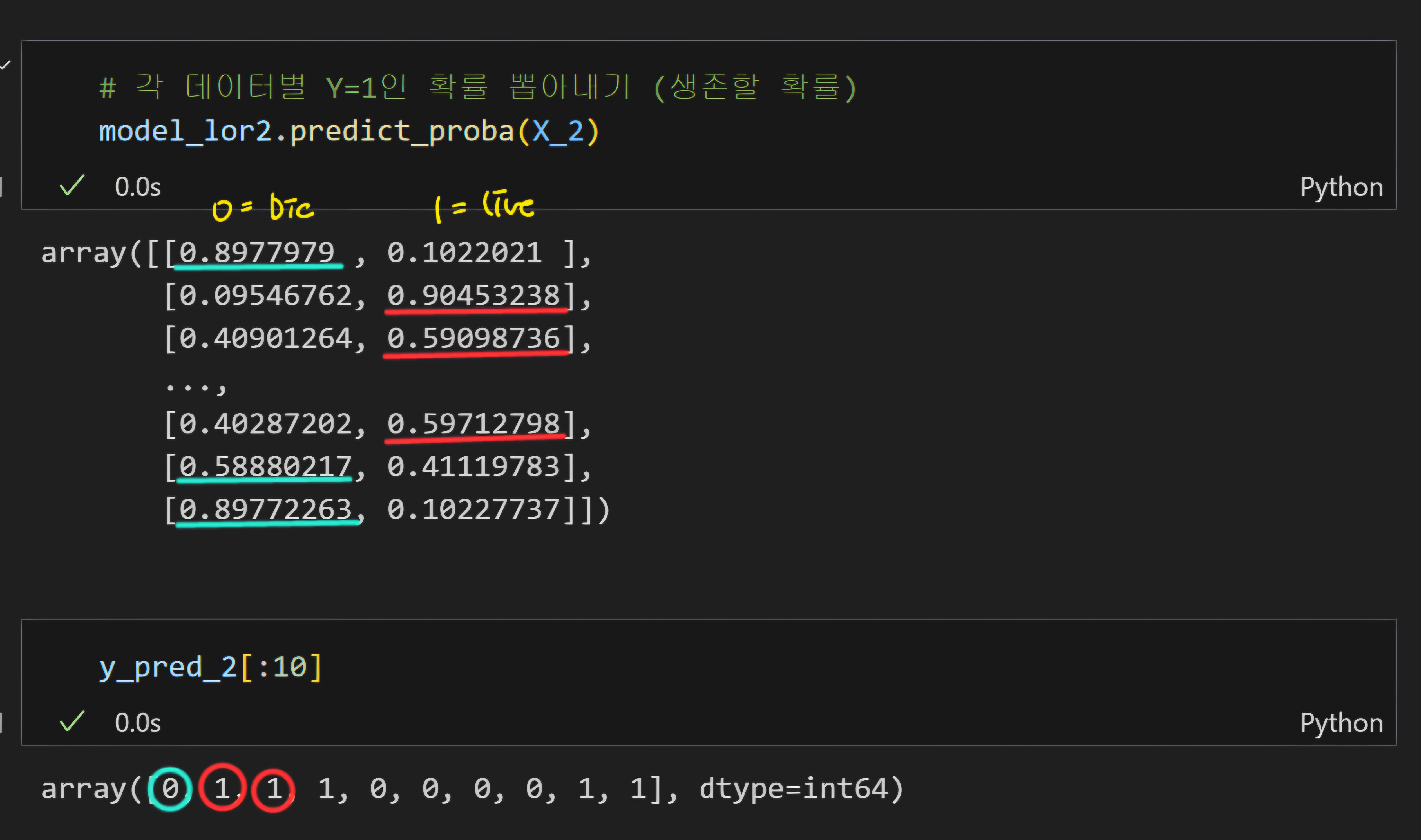
9) 부가설명
predict_proba(): 각 데이터의 모든 변수에 대한 확률 예측

First time, Last time, Every time.