로지스틱회귀 실습
1. 자주쓰는 함수
sklearn.linear_model.LogisticRegression: 로지스틱회귀 모델 클래스- 속성
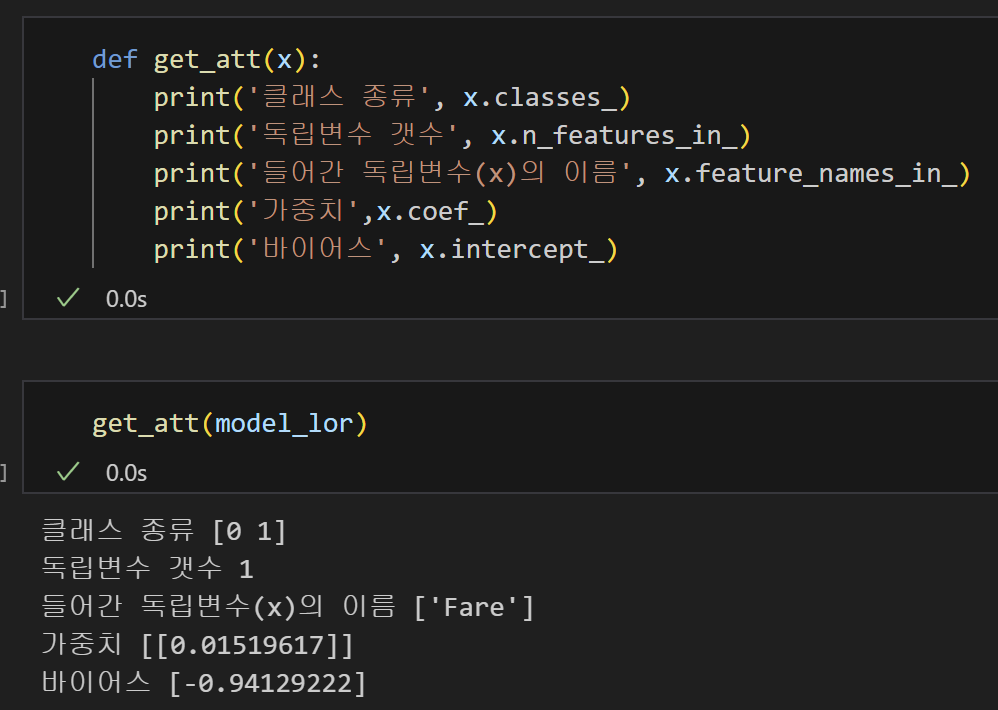
classes_: 클래스(Y)의 종류n_features_in_: 들어간 독립변수(X) 개수feature_names_in_: 들어간 독립변수(X)의 이름coef_: 가중치intercept_: 바이어스
- 메소드
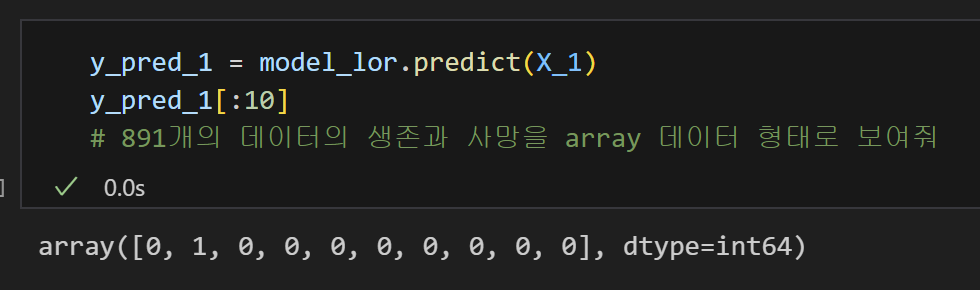
fit: 데이터 학습predict: 데이터 예측predict_proba: 데이터가 Y = 1일 확률을 예측
- 속성
sklearn.metrics.accuracy: 정확도sklearn.metrics.f1_socre: f1_score
2. 타이타닉 실습
1) 데이터 생성 및 라이브러리 설치
2) X변수 선정
- 숫자
- Age, Sibsp, Parch, Fare
- 범주형
- Pclass, Sex, Cabin, Embarked
- X변수 1개, y변수(Survived)
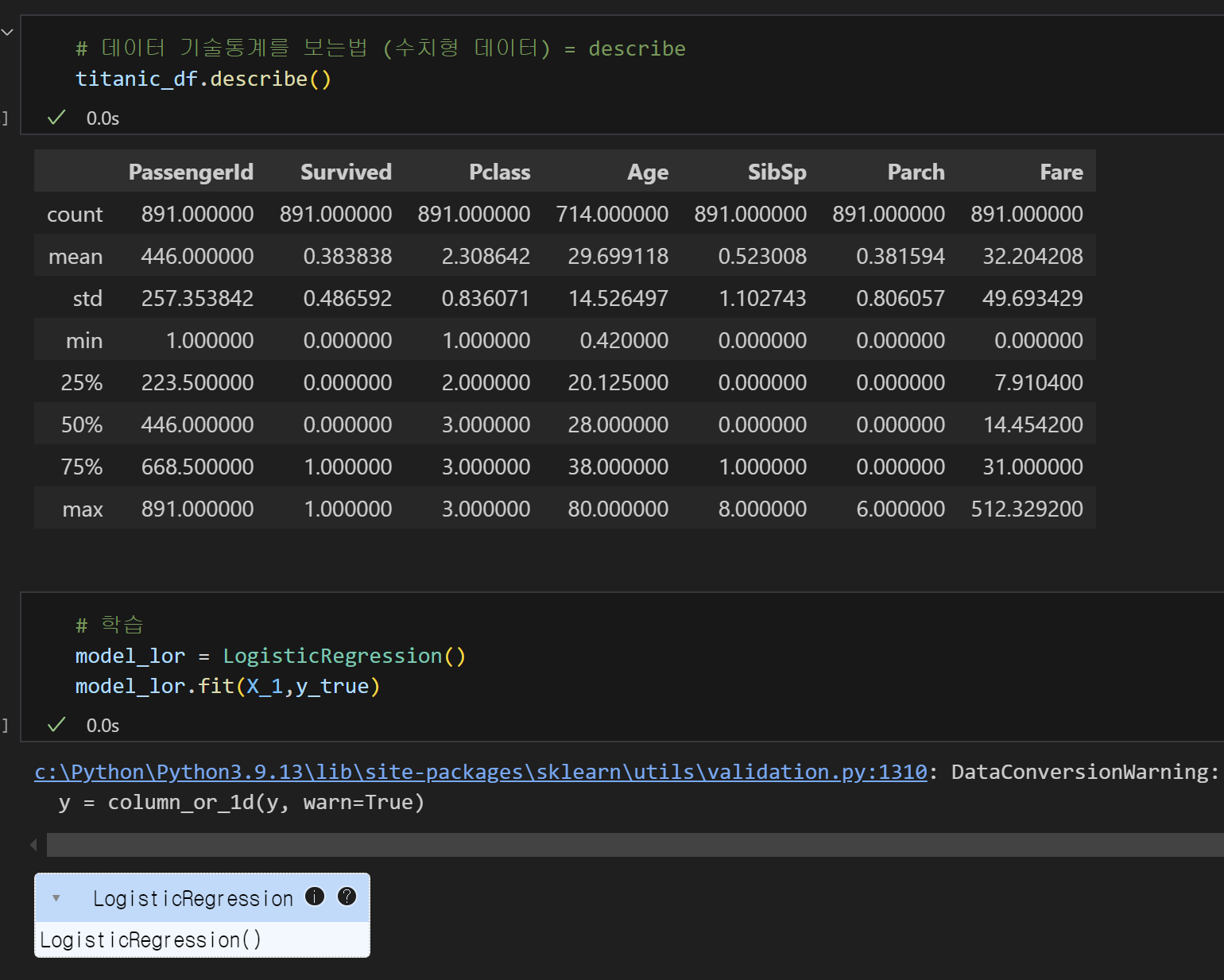
3) 로지스틱회귀모델 불러오고, 데이터 훈련하기
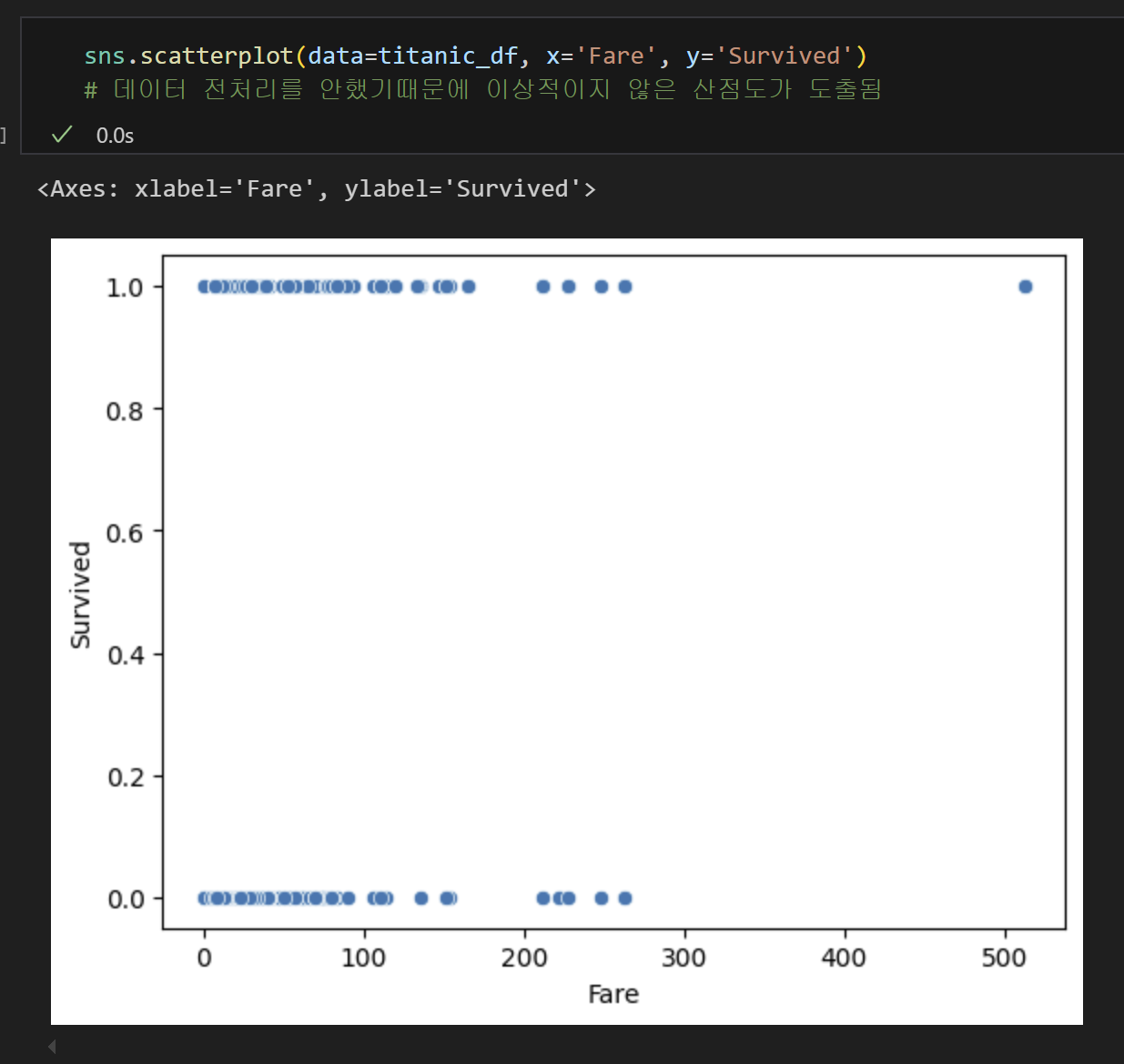
4) 산점도 확인
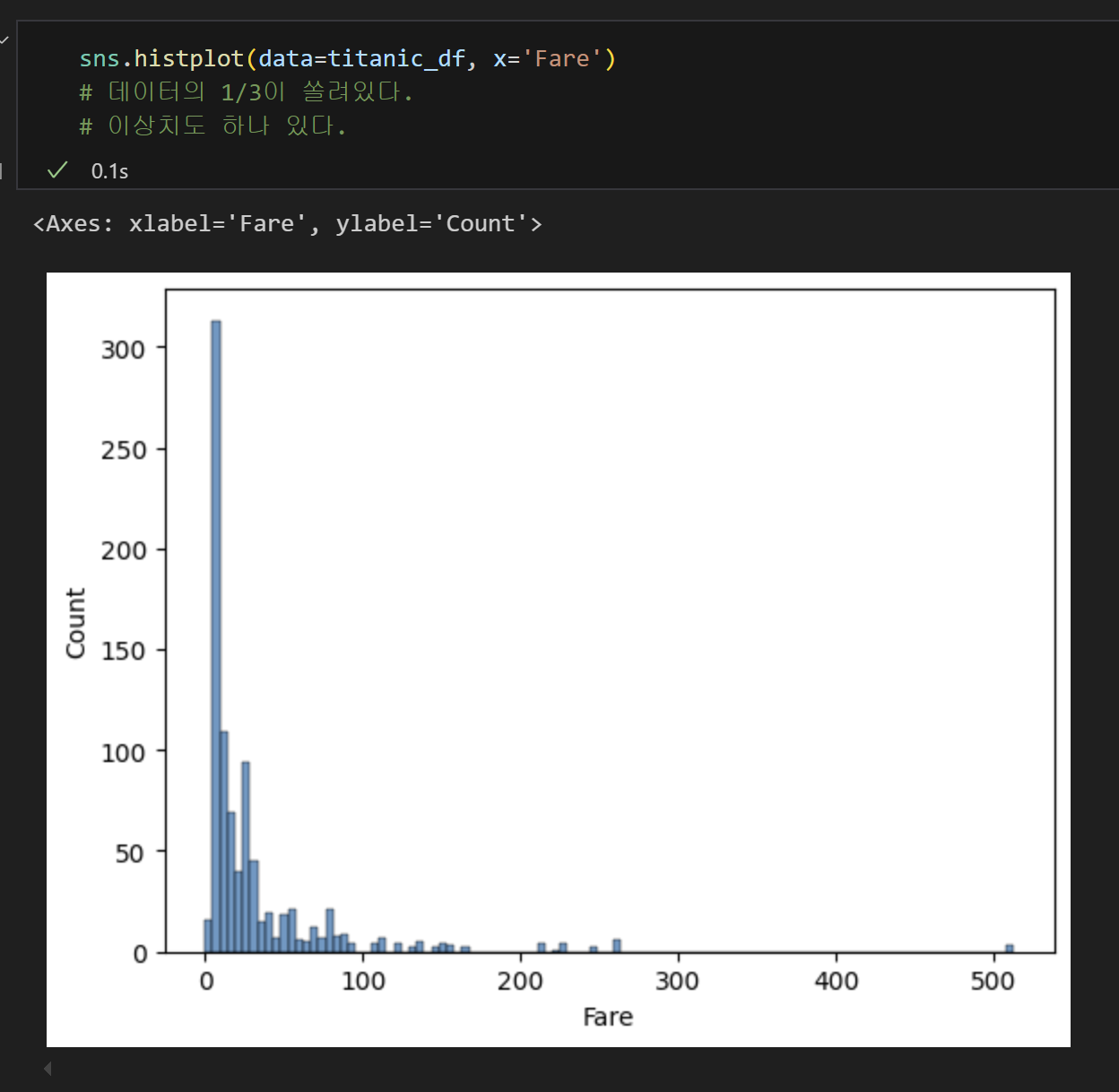
- 산점도 모양이 이상적이지 않은 것은 데이터 전처리를 하지 않았기 때문이다. 히스토그램으로 X변수의 분포를 파악해보자.
5) 히스토그램 확인
6) 기술통계 확인 후, 모델 학습
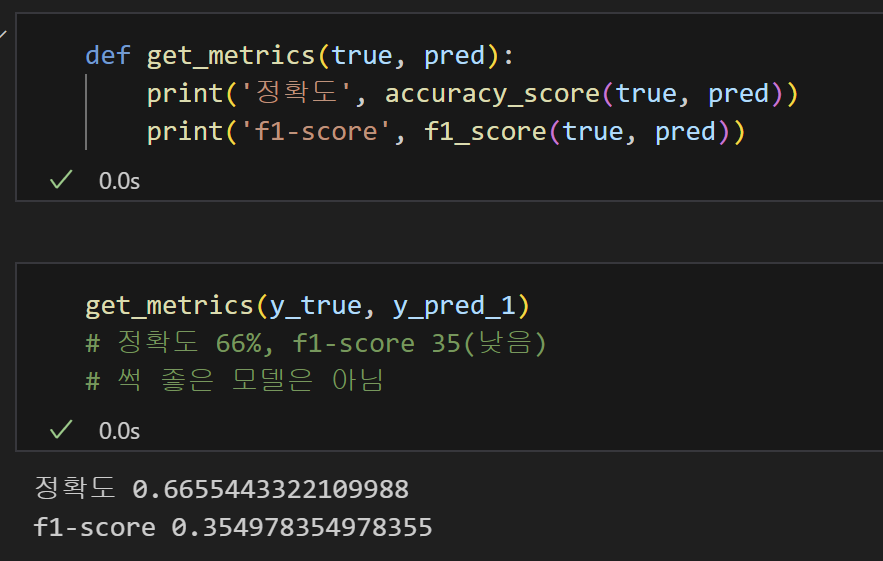
7) 매번 출력을 입력하지 않도록 함수화
8) 예측값 생성
9) 평가 : Accuracy, F-1 Score
- 매번 결과를 보여달라고 입력하지 않아도 되도록 함수화.

First time, Last time, Every time.