1 탐색적 데이터 분석 개요
1.1 탐색적 데이터 분석(EDA)
- EDA(Exploratory Data Analysis)라고 함
- 수집한 데이터를 분석하기 전에 그래프나 통계적인 방법을 이용하여 다양한 각도에서 데이터의 특징을 파악하고 자료를 직관적으로 바라보는 분석 방법
- EDA를 통하여 데이터전처리, 피쳐 엔지니어링 방향을 확보할 수 있음
1.2 EDA 프로세스
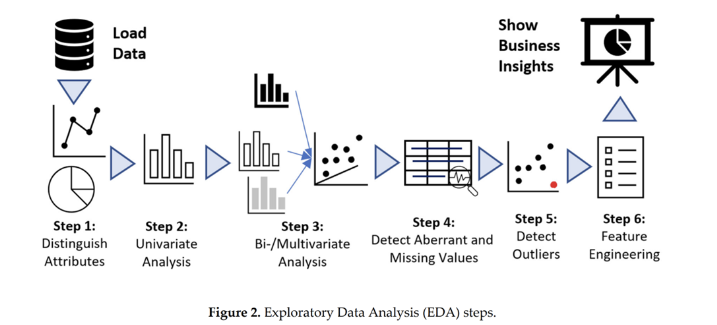
- Step1 : 데이터의 속성(변수, feature) 확인하기
- Step2 : 각 피쳐별 단변량 데이터 분석
- Step3 : 피쳐간 상관관계 분석
- Step4 : 결측치 처리하기
- Step5 : 이상치 처리하기
- Step6 : 피쳐 엔지니어링을 통한 피쳐 선택, 추가, 삭제하기
1.3 변수 분석
단변량 분석
- 변수 하나에 대하여 기술통계량(descriptive statistics) 확인
- 대표값 : 데이터의 평균, 중위수, 최빈수
- 산포 : 표준편차, 분산, 범위, 사분위수
- 분포 : 왜도, 첨도
- 기타 : 신뢰구간, 데이터의 정규성
- 히스토그램이나 Boxplot을 사용 -> 평균, 최빈값, 중간값 등과 함께 각 변수들의 분포를 확인
- 범주형 변수의 경우 Boxplot을 사용하여 빈도 수 분포를 체크
이변량 분석
- 변수 2개간의 관계를 분석
- 상관관계 분석(correlation analysis) : 두 개 이상의 변수 사이에 존재하는 상호 연관성의 존재 여부와 연관성의 강도를 측정하여 분석
- 변수의 유형에 따라 적절한 시각화 및 분석 방법을 적용(ex) 산점도)
다변량 분석
- 범주형 변수가 하나 이상 포함되어 있는 경우에는 변수를 범주에 따라 분리한 후 분석 방법에 따라 분석함
- 모두 연속형 변수일때 -> 연속형 변수를 Feature engineering을 통해 범주형 변수로 변환한 후 분석, 혹은 3차원 그래프를 그려서 시각적으로 확인
1.4 그래프 분석
- 데이터의 종류에 따라 적절한 그래프를 선택해야함
- 다양한 그래프를 통하여 피쳐들의 특성을 파악하는것이 중요함
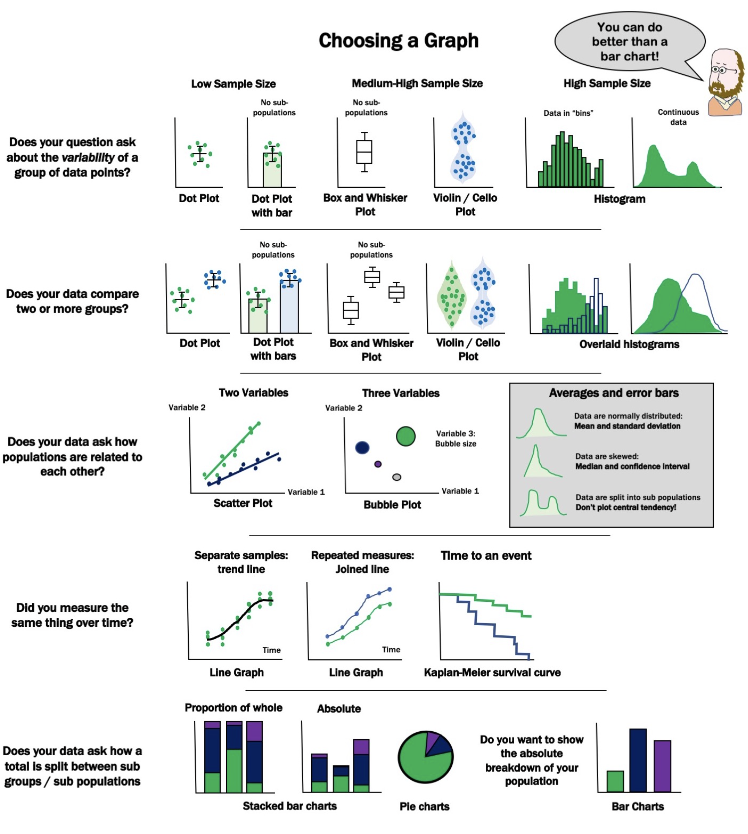
(출처:https://lantsandlaminins.com/writing-guides/choosing-a-graph-type/)
2 데이터 프로파일링
2.1 데이터 프로파일링
프로파일링(profiling)
- 어떤 개인의 심리적, 행동적 특성을 분석함으로써 특정 상황이나 영역에서의 행동을 예상하는 것
- 사회인구학적 특성을 포함한 여러 변수에 의해 특정한 하위 그룹으로 분류하는 것
데이터 프로파일링이란?
- EDA(탐색적 데이터 분석)를 수행하는 것
- 데이터 내 값의 분포, 변수 간의 관계, NULL과 같은 결측값(missing value) 존재 유무 등을 분석
2.2 데이터 프로파일링의 단계
2.2-1 메타데이터 수집 및 분석
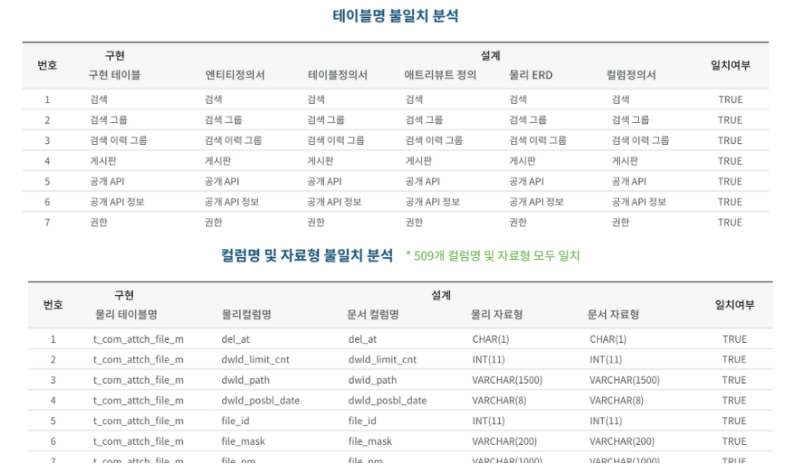
- 실제 운영중인 데이터베이스의 테이블명, 컬럼명, 제약조건 등의 정보를 분석
- 테이블 정의서, 컬럼 정의서와 같은 데이터 관리 문서의 정보 분석
- 추출된 테이블 및 컬럼에 대한 메타데이터와 데이터 관리 문서를 매핑하여 불일치 사항을 분석
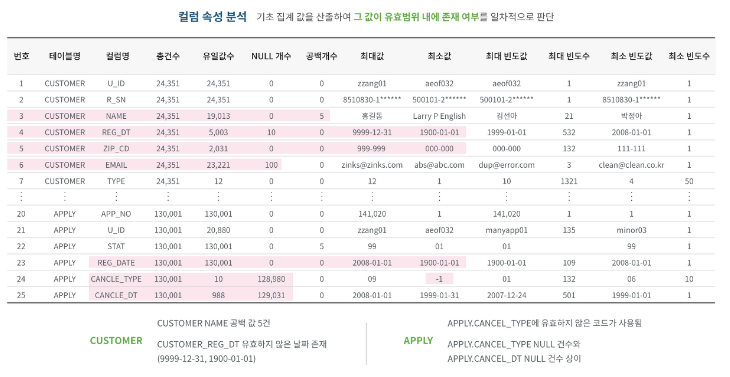
2.2-2 컬럼 속성 분석
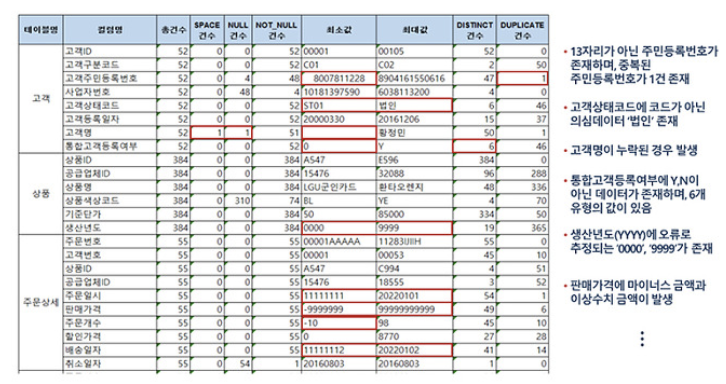
- 대상 컬럼의 비유효한 값을 확인
- 컬럼의 총 건수, 유일값 수, NULL값 수, 공백값 수, 최댓값, 최솟값, 최대빈도, 최소빈도 등 기초 집계값을 산출하여 값이 유효한 범위 내에 있는지 판단
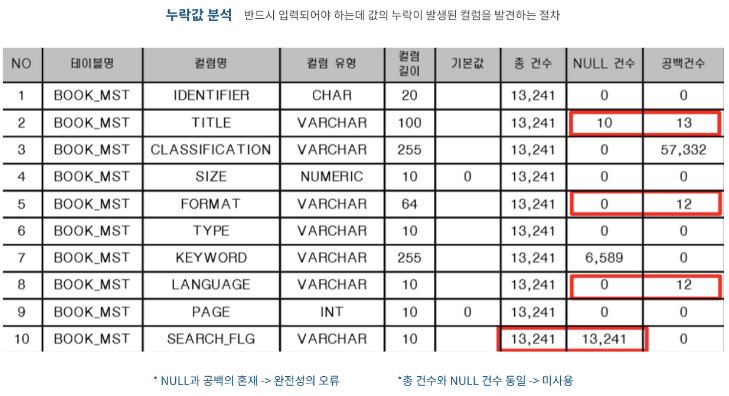
2.2-3 결측치 분석
- 반드시 입력되어야 하는데 누락이 발생한 컬럼을 발견하는 절차
- 결측치에는 NULL값, 공백값 또는 숫자 0 등이 해당
- NULL 허용 컬럼일지라도 NULL과 공백이 섞여있는 경우와 총 건수와 NULL건수가 같아 미사용으로 추정되는 컬럼을 발견하는 일도 포함
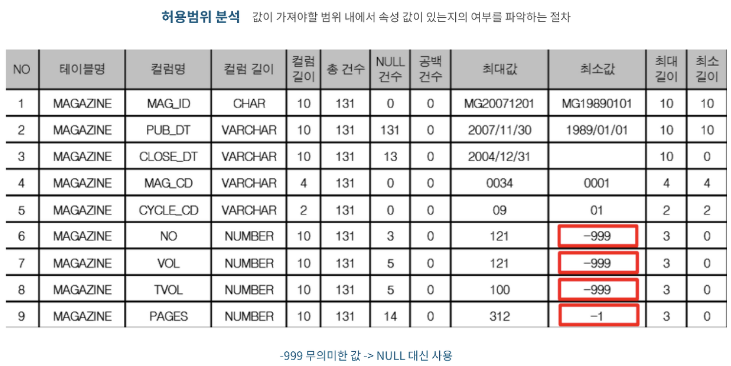
2.2-4 허용범위 분석
- 값이 가져야 할 범위 내에 그 값이 있는지를 파악하는 절차
- 허용범위는 해당 속성의 도메인 유형에 따라 정해짐
- 아래 예시에서 MAGAZINE 테이블의 권, 호, 페이지 등의 컬럼은 0 이상의 값을 가져야 하지만 최솟값이 -999 등으로 이루어진 것을 봐서 NULL 대신 무의미한 값을 부여한 데이터일 가능성이 큼
- 해당값이 오류 데이터라면 NULL값을 부여해야 함
2.2-5 허용값 분석
- 해당 컬럼의 허용값 목록이나 집합에 포함되지 않는 값을 발견하는 절차
- 코드 매핑 정의서에 기술한 코드 성격의 컬럼이 분석 대상에 해당
- 아래 예시에서 등록되지 않은 코드가 포함되어 있거나 의미는 유사하나 다른 값으로 혼재된 경우를 확인가능
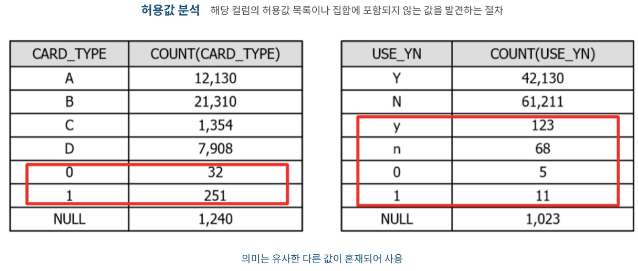
- 아래 예시에서 등록되지 않은 코드가 포함되어 있거나 의미는 유사하나 다른 값으로 혼재된 경우를 확인가능
2.2-6 패턴 분석
- 해당 컬럼의 문자열 유형을 따르지 않는 오류 유형을 발견하는 절차
- 데이터를 집계할 때 문자일 경우C, 숫자일 경우9, 공백일 경우S를 반환하는 함수를 만들어 사용
- 해당 컬럼의 데이터를 패턴화하여 SQL로 조회하면 비정상적인 형태를 보인 값을 오류로 추정할 수 있음
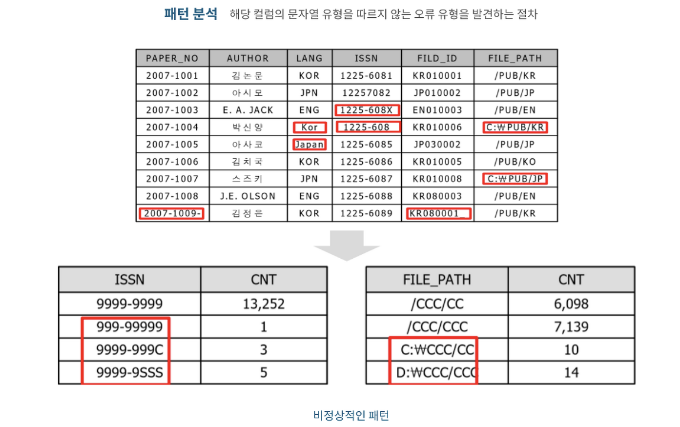
- 해당 컬럼의 데이터를 패턴화하여 SQL로 조회하면 비정상적인 형태를 보인 값을 오류로 추정할 수 있음
2.2-7 날짜 유형 분석
- 대상 컬럼이 DBMS의 DATE관련 자료형을 가지면 날짜 패턴 및 유효성 검증은 문제가 없음
- 하지만 문자형 데이터 타입에 날짜 데이터를 입력하면 아래 예시와 같은 사례가 발생할 수 있음
- 이는 패턴 검증을 통하여 쉽게 검증할 수 있음
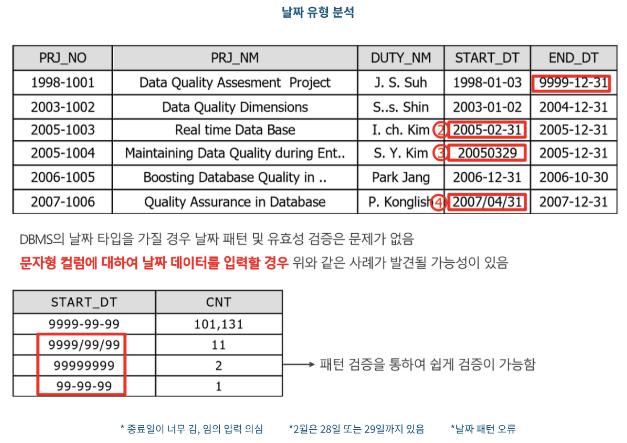
2.2-8 유일값 분석
- 업무적 의미에서 유일해야 하는 컬럼에 중복이 발생하였는지를 파악하는 절차
- DBMS의 제약조건으로 PK(Primary Key)가 설정된 컬럼이나 UNIQUE가 설정된 컬럼은 문제없음
- 아래 예시처럼 CUSTOMER테이블의 EMAIL컬럼은 PK컬럼이 아니지만, 업무적으로 고객의 이메일은 유일해야 하는 경우 최대 빈도를 통하여 중복된 데이터를 확인할 수 있음
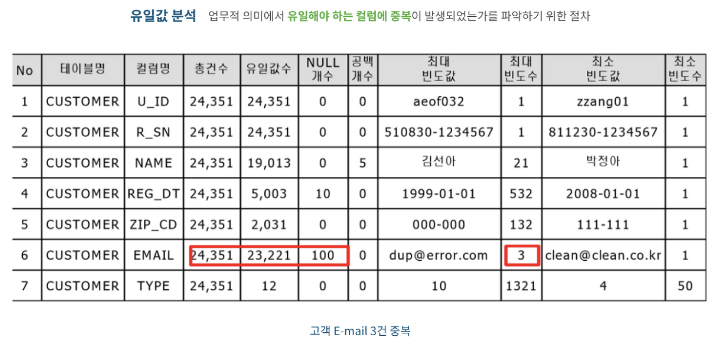
- 아래 예시처럼 CUSTOMER테이블의 EMAIL컬럼은 PK컬럼이 아니지만, 업무적으로 고객의 이메일은 유일해야 하는 경우 최대 빈도를 통하여 중복된 데이터를 확인할 수 있음
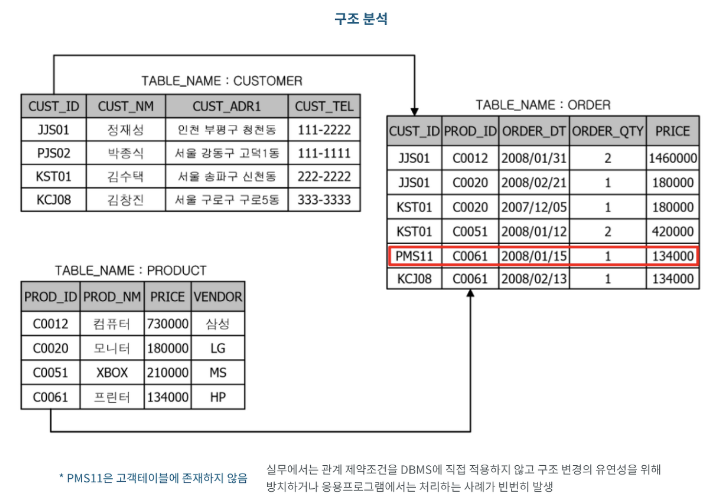
2.2-9 구조 분석
- 구조 결함으로 인해 일관되지 못한 데이터를 발견하는 분석 기법
- 아래 예시에 ORDER테이블에 CUSTOMER테이블에는 존재하지 않는 데이터가 존재하여 데이터의 일관성이 없는 오류 데이터가 발생
- ERD(Entity Relationship Diagram)등 설계 시에는 관계를 설정해두고 실제 데이터베이스에는 제약조건을 적용하지 않고 개발하는 경우 이러한 사례가 빈번하게 발생

나의 기록장