딥러닝을 이용한 자연어처리 입문 7시간 완성 - 메타코드M
https://www.youtube.com/watch?v=Rf7wvs8ZbP4&ab_channel=%EB%A9%94%ED%83%80%EC%BD%94%EB%93%9CM
4회차 RNN, LSTM,GRU, seq2seq, 1DCNN, Bi-LSTM
언어의 시계열 특성을 살린 인코더 구조를 알아보자
목차
1. RNN 원리 및 구조
2. LSTM, GRU
3. Seq2seq
4. 1D CNN
5. Bi-LSTM
1. RNN 원리 및 구조
약자를 풀어 쓰면 Recurrent Neural Network (RNN)이다.
여기서 recurrent 라는 말이 왜 붙었는지가 중요하다.
우선 배경 지식으로
First-Order system 은 현재 시간의 상태가 이전 시간의 상태와 관련이 있는 system이다.
수식으로 표현하면 로 쓸 수 있다. 즉, t시점의 상태가 t-1시점의 함수로 표현 가능하다.
( 하나 더 가서 현재 시점이 앞의 두 시점과 관련 있다면, 는 second order system이다. )
여기까지는 현재에 추가적인 입력 없이 초기 값 ()만 있으면 이후 모든 시점을 계산할 수 있었다. (Autonomous system)
현재 입력()가 주어지는 경우를 수식으로 쓰면
로 쓸 수 있다. 이제 곧 알아볼 RNN의 형태이다.
근데 t시점의 상태를 표현한 가 관측 가능하냐 하면 관측 가능한 부분도 있고, 그렇지 않은 부분도 있다.
주식을 예로 들면, 관측 가능한 부분으로는 이전 시점의 주가, 금리, 비슷한 회사의 주가 등이 있을테고, 관측 불가능한 부분은 사람들 투자 심리, 분위기 같은게 있을 수 있다.
관측 가능한 상태만 모은 것을 출력 로 표현하고, 수식으로는
로 의 함수로 표현할 수 있다.
이제 RNN의 구조를 보면
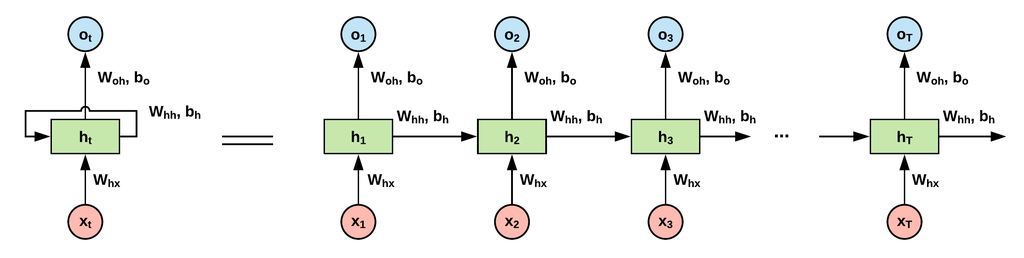
출처: https://velog.io/@yuns_u/%EC%88%9C%ED%99%98-%EC%8B%A0%EA%B2%BD%EB%A7%9DRNN-Recurrent-Neural-Network
위 그림에서는 입력()을 , 각 시점의 상태()를 , 출력()를 로 쓰고 있음을 참고하자
가장 왼쪽부분을 보면 가 모델에 들어가고, 출력이 다시 모델로 또 들어가는 화살표가 있다. 이거 때문에 recurrent 라는 단어가 붙었고, 이런 구조를 self feedback 이라고 부른다.
등호 오른쪽이 구조를 풀어서 그린 설명이다. parameter로는
입력-상태 사이의 ,
Self feedback의 ,
상태-출력의 로 총 5개가 필요하고, 수식으로 보면
t 시점의 상태인 로
이전 시점의 상태, 현재의 입력 에 대한 식으로 표현 할 수 있고,
t 시점의 출력은 로
현재의 상태 에 대한 식으로 표현 할 수 있다.
학습은 Backpropagation Through Time (BPTT)로 한다.
형태의 종류로는
many-to-many: Loss 계산시 각 시점의 출력(y)들을 모두 활용 Ex) 번역
many-to-one: 마지막 시점의 출력만 가지고 Loss 계산 Ex) 예측
one-to-many: 입력 하나만 주어진 경우 Ex) 문장 생성
가 있다.
2. LSTM, GRU
gradient flow를 제어하는 밸브 역할을 추가했다고 생각하면 된다.
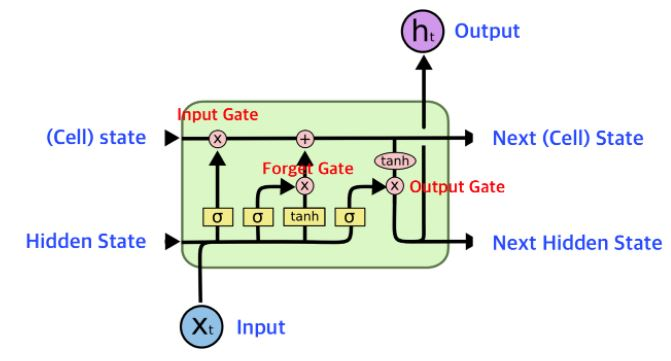
출처: https://wikidocs.net/152773
각 Gate의 역할을 간단하게만 보면
- Input Gate는 들어온 입력인 를 얼마나 사용할 지 결정한다.
- Forget Gate는 이전 시점의 상태 를 얼마나 잊을지를 결정한다.
- Input Gate와 Forget Gate를 거쳐 나온걸 섞어서 다음 cell로 보낸다.
- Output Gate가 지금까지 한걸 종합해서 output을 뽑아낸다.
GRU는 LSTM의 간단화 버전인데, GRU가 간단하니 학습시간이 짧고 그런 장점은 있겠지만 둘 중에 뭐가 더 낫다는 실험을 통해서만 알 수 있다. (기본 RNN 구조보다는 당연히 둘 다 좋다.)
3. Seq2Seq
우선 등장한 이유인 RNN의 단점:
Recurrent 구조인 만큼 시점 t가 반복될 수록 거기에 해당하는 Weight인 가 계속해서 곱해지는데, backpropagation을 할 때 (CNN에서 ResNet이 등장하기 전 CNN을 깊이 쌓을 때 발생하는 문제였던) Exploding/Vanishing gradient 문제가 발생한다.
Seq2Seq의 구조는 many-to-one + one-to-many 로 볼 수 있다.
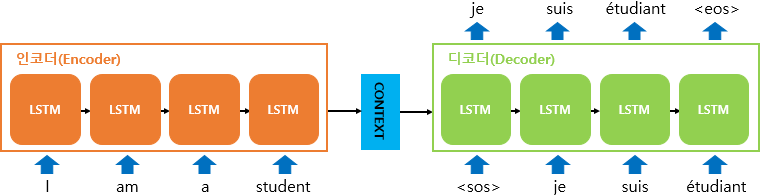
인코더: 문장을 입력해 전체에 대한 정보를 담은 Context Vector를 뽑아낸다. (초기 상태 는 랜덤하게 결정)
디코더: Context Vector를 초기 상태로 활용해 출력을 만들어 낸다. 첫 입력은 문장의 시작이라고 알려주는 <sos>를 넣어주고, 과 이전 상태를 입력으로 활용해 를 얻고, 마지막 출력으로는 문장의 끝이라는 의미인 <eos>를 내보낸다.
학습 단계에서는 분명 이전 block이 제대로된 단어를 예측했으리란 보장이 없기 때문에 Teacher force training 으로 학습한다.
설령 이 이상한 단어이더라도, 로는 정답을 넣어주는 방법이다.
예를 들어, 학습할 떄 그림의 두번째 block에서 je를 입력으로 받아 suis를 출력했어야 한다. 만약 suis 대신 asdf를 출력했다 하더라도 다음 block의 input으로는 정답인 suis를 넣어준다.
seq2seq도 분명 기본 RNN 구조보다 좋지만 업그레이드 버전인 Attention이 매우 효과적이다.
4. 1D-CNN
이미지의 공간 구조를 활용핸 구조인 CNN을 언어에 대입시켰다.
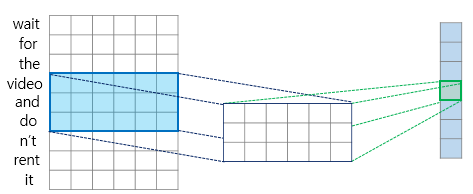
출처: https://wikidocs.net/80437
단어 임베딩을 이어 붙이고, CNN의 Kernel로 feature를 뽑아내는 구조이다.
그림상으로
입력 길이: 9, 임베딩 크기: 6, 한번에 볼 단어의 갯수: 3 이다.
아래로 내려가면서 Convolution 연산을 해 준다.
첫 CNN layer를 거치면 7x6 matrix가 나올 것이고,
그림상으론 바로 pooling을 거쳐 7x1 matrix를 뽑아냈다.
CNN layer를 더 많이 거쳐도 되고, kernel의 channel 수를 늘리는 방법으로 모델 크기를 키워 학습 시킬 수 있다.
나온 결과로 FC layer를 거쳐 분류나 회귀 문제에 활용할 수 있다.
5. Bi-LSTM
일반 RNN구조에 반대로 가는 길도 추가된 버전이라 할 수 있다. 혹은 RNN 구조 2개가 겹쳐진 버전으로 볼 수 있다.
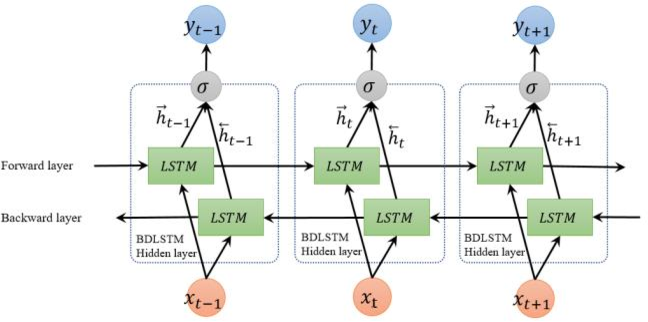
출처: https://www.gabormelli.com/RKB/Bidirectional_LSTM_%28BiLSTM%29_Training_System
예를 들어
I love ___ for always 라는 문장이 있다.
빈칸에 들어갈 단어를 예측하기 위해 앞 뒤로 I love와 for always를 활용하는게 도움이 될 것이다.
이런 식으로 예측을 하는데 (과거 입력에만 영향을 받는다는 의미인) Causality를 무시해도 되고, 미래의 입력이 도움이 되는 경우에 활용 할 수 있는 구조이다.
가 기본 버전의 2배가 필요할 것이다.
총정리
오늘 RNN은 학교 수업에서도 한번 봤기에 잔잔하게 이해할 수 있었다. 그땐 NLP 분야의 존재조차 모르고 들었었기에 이런 구조가 큰 의미가 있나 싶었는데 아는 만큼 보인다는걸 느꼈다.
CNN은 알고 있었지만 1D-CNN은 처음 봤는데, 처음엔 CNN을 NLP에 어떻게 적용하지 했는데, 약간의 억지도 없지않아 보이긴 하지만 이런 상상력이 어떤 결과가 나올지 모르기 때문에 항상 다각도로 생각해 보자.
이제 이 강의를 선택한 목적인 Attention Transformer 부분을 앞두고 있다. 가보자.
