딥러닝을 이용한 자연어처리 입문 7시간 완성 - 메타코드M
https://www.youtube.com/watch?v=Rf7wvs8ZbP4&ab_channel=%EB%A9%94%ED%83%80%EC%BD%94%EB%93%9CM
5회차는 attention 이론과 LSTM, seq2seq 실습입니다.
1. Attention
attention 관련 정리는 한 번 한적이 있기에 아래링크로 대체
https://velog.io/@_chominseo/SEQ2SEQ-Attention
2. 실습
단순 구조
FC layer 2개와 output layer로 이루어진 단순한 구조 먼저 만들어 보자
class ANN(nn.Module):
def __init__(self,num_output,input_size,hidden_size,device='cpu'):
super(ANN,self).__init__()
self.device = device
self.fc1 = nn.Linear(input_size,hidden_size)
self.fc2 = nn.Linear(hidden_size,hidden_size)
self.outlayer = nn.Linear(hidden_size, num_output)
def forward(self,x):
h = self.fc1(x).relu()
h = self.fc2(h).relu()
predict = self.outlayer(h)
return predictinput size -> hidden size -> hidden_size -> num_output
으로 channel수를 구성한 구조이다.
LSTM
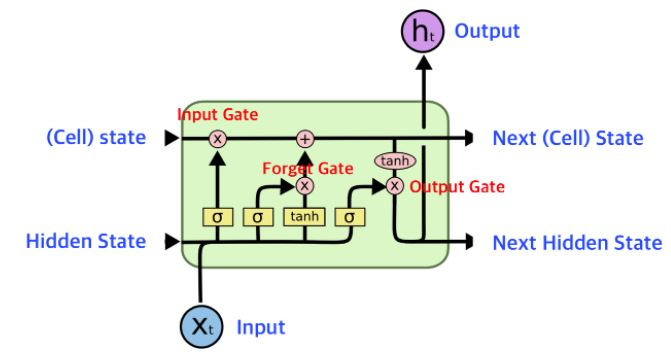
출처: https://wikidocs.net/152773
LSTM 구조를 다시 보면 input과 이전 시점의 cell state, hidden state 가 들어가
다음 LSTM block을 위한 cell state, hidden state를 만들고, output 하나를 뽑아 낸다.
class LSTM_net(nn.Module):
def __init__(self,num_output,size_vocab, dim_embed, hidden_size,linear_size,num_layers,device='cpu'):
super(LSTM_net,self).__init__()
self.device = device
self.num_output = num_output
self.hidden_size = hidden_size
self.num_layers = num_layers
self.embed = nn.Embedding(size_vocab,dim_embed)
self.lstm = nn.LSTM(input_size = dim_embed, hidden_size = hidden_size, num_layers = num_layers, dropout = 0.3, bidirectional = True)
self.fclayer = nn.Linear(hidden_size, linear_size)
self.outlayer = nn.Linear(linear_size, num_output)
def forward(self, x):
scaler = 2 if self.lstm.bidirectional == True else 1
emb = self.embed(x)
h_state = Variable(torch.zeros(self.num_layers*scaler,emb.size(0),self.hidden_size,requires_grad=True)).to(self.device)
c_state = Variable(torch.zeros(self.num_layers*scaler,emb.size(0),self.hidden_size,requires_grad=True)).to(self.device)
lstm_out,(h,c) = self.lstm(emb.transpose(1,0),(h_state,c_state))
h = h[-1]
h = self.fclayer(h).relu()
predict = self.outlayer(h)
return predictforward 함수를 기준으로 부분 부분 뜯어 보자
emb = self.embed(x)x를 input으로 생각하면 된다. x가 들어와 self.embed를 거친다.
self.embed = nn.Embedding(size_vocab,dim_embed)nn.Embedding이 등장하는데, 이건 x를 가지고 학습가능한 embedding vector를 생성해준다.
size_vocab은 전체 단어 종류, dim_embed는 embedding vector를 몇 channel로 뽑을 것인지 정해주면 된다.
즉, x 라는 문장이 들어가면 [batch, size_vocab, dim_embed] 크기의 embedding vector 가 생성된다.
다음
h_state = Variable(torch.zeros(self.num_layers*scaler,emb.size(0),self.hidden_size,requires_grad=True)).to(self.device)
c_state = Variable(torch.zeros(self.num_layers*scaler,emb.size(0),self.hidden_size,requires_grad=True)).to(self.device)LSTM이 만들어내는 hidden state와 cell state들을 일단 0으로 다 초기화 해 준다.
shape은 [num_layers, batch, hidden_size]
num_layers: LSTM block을 몇 번 쌓을 건지
hidden_size: LSTM 안에서 돌아가는 channel 수
scaler는 bidirectional 하게 할지 고려하는 부분이니 양방향으로 간다면 기존의 2배가 필요해서 scaler를 곱해준다.
다음
lstm_out,(h,c) = self.lstm(emb.transpose(1,0),(h_state,c_state))LSTM에 input에서 얻은 embedding vector와 hidden state, cell state를 지정해 돌려준다.
이때 emb.transpose 부분에서 기존 shape이 [batch, size_vocab, dim_embed] 였던 emb를 [size_vocab, batch, dim_embed] 로 바꿔 넣어줘야 한다. (--batch size가 두번째에 오게)
다음
h = h[-1]
h = self.fclayer(h).relu()
predict = self.outlayer(h)
return predictclassification task에서 필요한 부분은 마지막 h 또는 c 만 있으면 되기 때문에 마지막 h만 FC layer에 넣고, outlayer에 넣어 class 갯수만큼의 channel 수로 만들어 준다.
전처리
토큰화, 정제/추출, 정수인코딩 까지 해주자.
Padding
각 문장별로 포함된 토큰 수가 다 제각각이기 때문에 가장 긴 문장 기준으로 나머지 문장에 Padding을 추가해 주자.
maxlen = 100
rowdata = []
for w in text_encoded:
if len(w)>=maxlen:
rowdata.append(w[:maxlen])
else:
rowdata.append(np.pad(w,(0,maxlen),'constant',constant_values=0)[:maxlen])
text_padded = np.concatenate(rowdata,axis=0).reshape(-1,maxlen)
print(text_padded.shape)근데 가장 긴 문장이 너무 길어서 100 토큰만 봐도 판단할 수 있으리라 생각하여 최대 길이를 100으로 하고, 긴 문장은 잘라주고,
짧은 문장은 np.pad 함수를 활용해 <pad> 의 토큰 값을 0으로 늘려 주자.
Dataset, DataLoader
from torch.utils.data import DataLoader, random_split
from torch import LongTensor as LT
from torch import FloatTensor as FT
class Generate_Dataset(torch.utils.data.Dataset):
def __init__(self,xdata,ydata,device='cpu'):
self.x_data = xdata
self.y_data = ydata
self.device = device
def __len__(self):
return len(self.x_data)
def __getitem__(self,idx):
x = LT(self.x_data[idx]).to(self.device)
y = LT(self.y_data[idx]).to(self.device)
return x,yx에 문장, y에 분류 문제 라벨값을 넣어 LongTensor 형태로 반환하는 class를 정의하자.
vision 할 때는 cv2로 이미지 열어 그냥 tensor로 만들어 반환했는데 단어는 정수 인코딩을 했기 때문에 int형을 쓸 때 쓰는 Longtensor로 지정해 반환한다.
dataset = Generate_Dataset(text_padded,text_label.reshape([-1,1]))
train_dataset,test_dataset = random_split(dataset,[int(len(dataset)*0.8),int(len(dataset)*0.2)])
train_loader = DataLoader(train_dataset,batch_size=256,shuffle=True)
test_loader = DataLoader(test_dataset,batch_size=500,shuffle=False)dataset, data loader를 정의해 주자.
모델 정의 및 학습
lstm_net = LSTM_net(num_output=2, size_vocab=5000,
dim_embed=64,hidden_size=64, linear_size=64,num_layers=2)
optimizer = torch.optim.Adam(lstm_net.parameters(),lr = 0.01)앞에서 만든 LSTM 모델을 정의하자. size vocab에 내가 쓴 tokenizer가 정수 인코딩 할 때 최대로 쓴 숫자(--unique한 token 수)보다 크게 써야한다.
optimizer는 adam을 썼다.
from tqdm import tqdm
def train(train_loader):
for epoch in range(10):
epoch_loss = 0
for x,y in tqdm(train_loader):
predict = lstm_net(x)
loss = torch.nn.functional.cross_entropy(predict,y.ravel())
optimizer.zero_grad()
loss.backward()
optimizer.step()
epoch_loss+=loss.item()
print(f'train epoch {epoch+1} loss: {epoch_loss:6f}')tqdm이 퍼센트, 남은시간을 알려줘서 좋다. 한 에폭마다 평균 loss값을 찍게 해 놨다.
loss function으로 cross entropy를 사용 했다.
여기서 y.ravel()이 등장한다. 1차원으로 평평하게 펴주는 함수이다.
예를 들어,
[[1,2],[3,4]] 인걸 [1,2,3,4] 로 만들어주는 함수이다.
100%|██████████| 32/32 [00:12<00:00, 2.47it/s]
train epoch 1 loss: 22.009017
100%|██████████| 32/32 [00:15<00:00, 2.08it/s]
train epoch 2 loss: 20.640763
100%|██████████| 32/32 [00:15<00:00, 2.13it/s]
train epoch 3 loss: 18.696785
100%|██████████| 32/32 [00:14<00:00, 2.14it/s]
train epoch 4 loss: 16.637502
100%|██████████| 32/32 [00:14<00:00, 2.14it/s]
train epoch 5 loss: 15.229966
100%|██████████| 32/32 [00:14<00:00, 2.18it/s]
train epoch 6 loss: 14.672411
100%|██████████| 32/32 [00:14<00:00, 2.17it/s]
train epoch 7 loss: 14.386816
100%|██████████| 32/32 [00:14<00:00, 2.15it/s]
train epoch 8 loss: 14.013005
100%|██████████| 32/32 [00:15<00:00, 2.13it/s]
train epoch 9 loss: 13.750575
100%|██████████| 32/32 [00:14<00:00, 2.19it/s]
train epoch 10 loss: 13.491799요런식으로 찍힌다.
Test
def test(test_loader):
score = 0
cnt = 0
for x,y in tqdm(test_loader):
predict = lstm_net(x).argmax(1).detach().numpy()
answer = y.ravel().detach().numpy()
for i in range(len(predict)):
cnt+=1
if predict[i]==answer[i]:
score+=1
print(f'test score: {score/cnt*100:6f}%')마지막 열심히 학습시켰으니 점수를 확인해 보자
전체 갯수에서 정답인거만 카운트해 accuracy를 찍는다.
100%|██████████| 4/4 [00:01<00:00, 2.42it/s]test score: 69.600000%70점 정도 나온다.
seq2seq
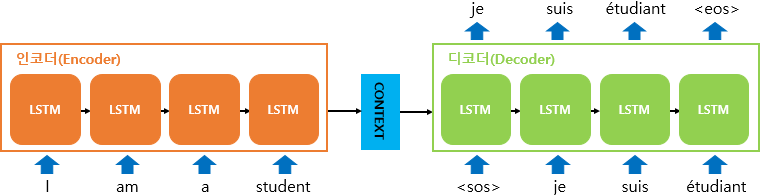
seq2seq는 encoder - decoder로 이루어진 구조고, 각각 안에는 LSTM들이 쌓여있는 형태다.
위 그림처럼 번역 task를 한다고 가정하자.
Encoder
class seq_Encoder(nn.Module):
def __init__(self, vocab_size, dim_embed,hidden_size,num_layers,dropout):
super().__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
self.embed = nn.Embedding(vocab_size, dim_embed)
self.lstm = nn.LSTM(dim_embed, hidden_size, num_layers, dropout = dropout)
self.dropout = nn.Dropout(dropout)
def forward(self,src):
outputs,(hidden,cell) = self.lstm(self.dropout(self.embed(src)))
return hidden,cellEncoder는 문장 전체를 input_data로 받아 LSTM을 통과 시킨다.
앞에서 했던 LSTM network에서 끝에 FC layer만 뺀 것과 같은 형태를 보인다.
그래야 Context Vector를 decoder에 전달할 것이다.
Decoder
class seq_Decoder(nn.Module):
def __init__(self, output_size, dim_embed, hidden_size, num_layers, dropout):
super().__init__()
self.output_size = output_size
self.hidden_size = hidden_size
self.num_layers = num_layers
self.embed = nn.Embedding(output_size, dim_embed)
self.lstm = nn.LSTM(dim_embed,hidden_size, num_layers,dropout = dropout)
self.fclayer = nn.Linear(hidden_size, output_size)
self.dropout = nn.Dropout(dropout)
def forward(self,input_data, hidden,cell):
input_data = input_data.unsqueeze(0)
embedded = self.dropout(self.embed(input_data))
output,(hidden,cell) = self.lstm(embedded,(hidden,cell))
prediction = self.fclayer(output.squeeze(0))
return prediction, hidden, cellDecoder는 encoder가 준 context vector를 받을 것이고, 매번 단어 하나만 받아 input_data로 사용할 것이다.
decoder도 같고 encoder과 다른점은 FC layer까지 해서 Prediction에 해당하는게 다음 단어가 되어 hidden state, cell state와 같이 전달한다.
seq2seq
import random
class seq2seq(nn.Module):
def __init__(self,encoder, decoder ,device = 'cpu'):
super().__init__()
self.encoder = encoder
self.decoder = decoder
self.device = device
def forward(self,source,target,tf_ratio=0.5):
batch_size = target.shape[1]
translation_length = target.shape[0]
target_vocab_size = self.decoder.output_size
outputs = torch.zeros(translation_length, batch_size, target_vocab_size).to(self.device)
hidden,cell = self.encoder(source)
input_trans = target[0,:]
for t in range(1,translation_length):
output,hidden,cell = self.decoder(input_trans, hidden,cell)
outputs[t] = output
teacher_force = random.random()<tf_ratio
input_trans = target[t] if teacher_force else output.argmax(1)
return outputs합치는 부분이다. 하나씩 보자
outputs = torch.zeros(translation_length, batch_size, target_vocab_size)outputs에 최종 번역된 문장을 담을 예정이다. 미리 0으로 초기화해 둔다.
hidden,cell = self.encoder(source)인코더에 입력 문장을 넣고 context vector를 받는다.
input_trans = target[0,:]Decoder의 첫 입력으로 쓸 <sos>를 정의하고,
output,hidden,cell = self.decoder(input_trans, hidden,cell)Encoder가 뱉은 hidden, cell과 함께 넣어준다.
for t in range(1,translation_length):
output,hidden,cell = self.decoder(input_trans, hidden,cell)
outputs[t] = output
teacher_force = random.random()<tf_ratio
input_trans = target[t] if teacher_force else output.argmax(1)Decoder가 뱉은 hidden state, cell state, output을 받아 다시 decoder에 넣는 것을 반복하는데,
아래 두 줄 teacher force로 특정 decoder가 잘못 예측했을 때 정답으로 바꿔 넣어줄지 말지를 tf_ratio보다 크면 제대로, 아니면 틀린거 그대로 넣어주는 코드가 추가되어 있다.
모델 정의
enc = seq_Encoder(x_vocab_size,64,64,1,0.3)
dec = seq_Decoder(y_vocab_size,64,64,1,0.3)
seq_net = seq2seq(enc,dec).to('cpu')번역이면 언어마다 사용한 tokenizer가 다를테니 encoder와 decoder에 들어갈 vocab size가 달라질 테니 고려해서 정의해 주자.
그러고 학습돌려주고 하면 된다.
총정리
Transformer를 사실 기대하고 이번 회차부분을 들었는데 없었고,
attention 실습도 없었다. 다음 회차가 마지막 GPT BERT 이다보니 Transformer 얘기가 마구 나올텐데 미리 혼자서라도 해보자.
Encoder-Decoder 구조까지 해서 그래도 NLP 전체 프로세스를 모델 짜는 것 부터해서 해보니 감이 좀 잡히는 것 같다. (+ pytorch로 실습해주셔서 감사하다.)
